




 使用Python的docx库和PIL库,通过遍历文件夹中的图片,逐个插入到不同的Word文档中,实现批量创建每份包含不同照片的Word简历。代码示例展示了如何处理图片并保存为docx文件。
使用Python的docx库和PIL库,通过遍历文件夹中的图片,逐个插入到不同的Word文档中,实现批量创建每份包含不同照片的Word简历。代码示例展示了如何处理图片并保存为docx文件。
背景需求
在测试Python docx批量导入图片的过程中,对现有的代码进行微调(办公类-08-01)20220502Python将同一文件夹下多张图片批量保存在一个word里_reasonsummer的博客-优快云博客20220502Python将同一文件夹下多张图片批量保存在一个word里 https://blog.youkuaiyun.com/reasonsummer/article/details/124538966?spm=1001.2014.3001.5502实现“Python将同一文件夹下多张图片分别保存在不同word里(每份一张)”的需求——类似于批量生成大量简历(每份的照片都不同)的效果。
https://blog.youkuaiyun.com/reasonsummer/article/details/124538966?spm=1001.2014.3001.5502实现“Python将同一文件夹下多张图片分别保存在不同word里(每份一张)”的需求——类似于批量生成大量简历(每份的照片都不同)的效果。
制作过程:
图片所在位置

代码展示:
'''
author:Linear Algebra and Geometry
https://blog.youkuaiyun.com/qq_44354520/article/details/103831685?utm_term=python%20%E5%B0%86%E5%9B%BE%E7%89%87%E5%AD%98%E5%85%A5word&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~sobaiduweb~default-3-103831685-null-null&spm=3001.4430
author:阿夏 微调代码
'''
from docx import Document
from docx.shared import Inches
import os
from PIL import Image
# 要插入的图片所在的文件夹
fold='C:\\Users\\Administrator\\Desktop\\文件名'
# os.walk(fold)没有返回值,所以这么做显然没有结果,是错的
# pics=list(os.walk(fold)[3])
# # pics.pop()
# print(pics)
# pics是图片的名字
# root是string类型, dirs和pics是list类型
for root, dirs, pics in os.walk(fold):
# a=0
for i in range(0,len(pics)):
doc=Document() # 新建 docx文件
# for i in range(0,len(pics)): # 循环从0-图片数量)
#不需要把文件后缀名去掉,后面的PIL库里的open可以直接识别出文件名后缀
# print(pics[i],'\n')
# pics[i] = os.path.splitext(pics[i])[0]
# print(pics[i], '\n')
#我前半部分的路径直接复制黏贴了,没用root和dirs
filepath = 'C:\\Users\\Administrator\\Desktop\\文件名\\'+pics[i]
# filepath = root + '\\' + str(pics[i])
i=i+1
try:
doc.add_picture(filepath,width=Inches(4),height=Inches(3))
except Exception:
pic_tmp=Image.open(filepath)
# 如果格式有问题,就用save转换成默认的jpg格式
pic_tmp.save(pic_tmp)
# 把处理后的图片放进Document变量doc中
doc.add_picture(filepath, width=Inches(4),height=Inches(3))
# 把Document变量doc保存到指定路径的docx文件中
doc.save('C:\\Users\\Administrator\\Desktop\\文件名\\{}.docx'.format(i))
#输出保存成功的标志
# print("pic", i+1, "successfully added.")
print('----已完成-----')
运行过程
生成的docx所在位置
样例展示01
样例展示25
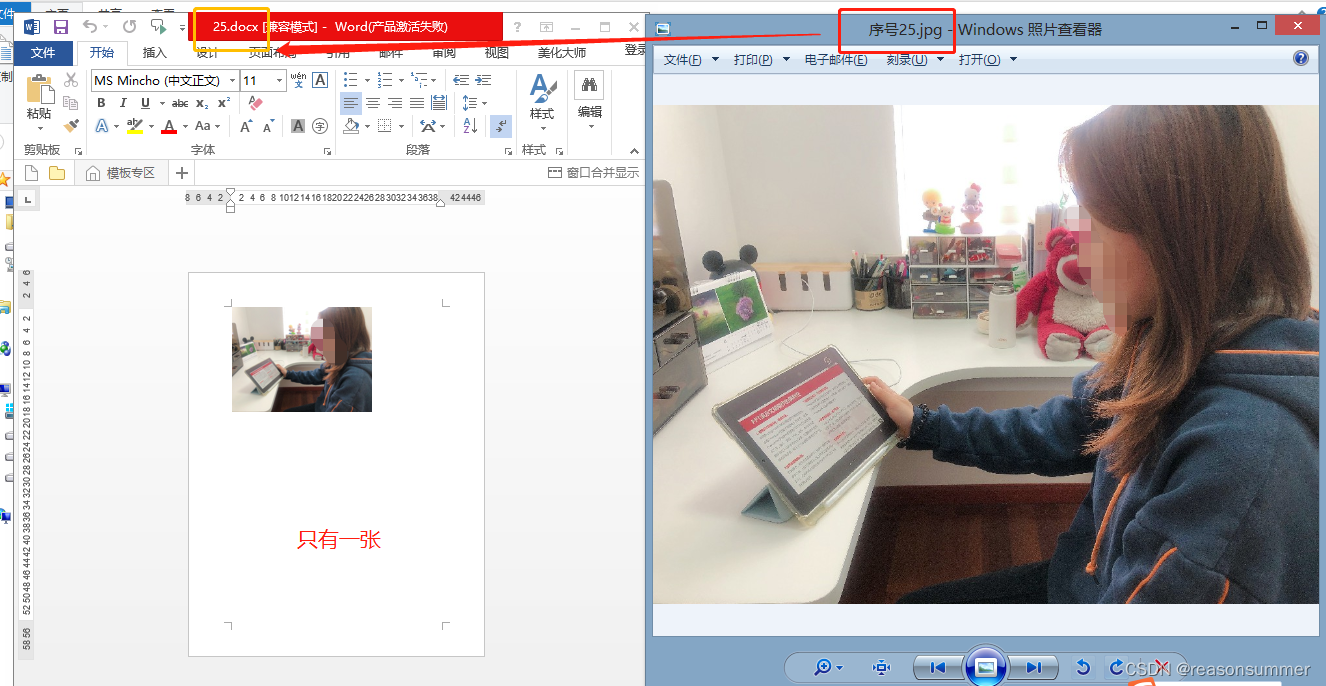
接下来继续研究,怎样套入已有的docx的表格内

















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









