




 本文介绍计算机发展历程,从电子管到超大规模集成电路时代。阐述计算机系统组成,包括硬件(CPU、存储器等)和软件(系统软件、应用软件)。还讲述了计算机层次结构、程序开发执行过程,以及性能评价方法,如用CPU执行时间、指令执行速度、基准程序等评估,同时介绍了Amdahl定律。
本文介绍计算机发展历程,从电子管到超大规模集成电路时代。阐述计算机系统组成,包括硬件(CPU、存储器等)和软件(系统软件、应用软件)。还讲述了计算机层次结构、程序开发执行过程,以及性能评价方法,如用CPU执行时间、指令执行速度、基准程序等评估,同时介绍了Amdahl定律。
- 本章主要介绍计算机的发展历程、计算机系统的基本组成、计算机系统层次结构、程序开发和执行过程,以及计算机系统的性能评价。
1.1 计算机发展简史
*1.1.1通用电子计算机的诞生
- 世界上第一台真正意义上的电子数字计算机是在1935—1939年由美国艾奥瓦州立大
学物理系副教授阿塔那索夫(John Vincent Atanasoff)和其合作者贝瑞(Clifford Berry,取名为ABC(Atanasoff-Berry Computer)。不过这台机器只是个样机 - 现在国际计算机界公认的事实是:第一台电子计算机的真正发明人是阿塔那索夫。阿塔那索夫在国际计算机界也被称为“电子计算机之父”。
- 46年诞生第1台电子计算机 ENIAC
- 体积大,重30吨,有18000多个真空管,5000次加法/s
- 十进制表示/运算,存储器由20个累加器组成,每个累加器存10位十进制数,每一位由10个真空管表示。
- 采用手动编程,通过设置开关和插拔电缆来实现。
- 自从第一台实用的通用电子计算机 ENIAC 诞生后,人类社会进入了一个崭新的电子计算和信息化时代。计算机硬件早期的发展受电子开关器件的影响极大,为此,传统上人们以元器件的更新作为计算机技术进步和划代的主要标志。
*1.1.2 元器件的更新与体系结构的发展
- 第一代:电子管计算机,真空管(电子管Vacuum Tube )1946~57年
- 其逻辑元件采用电子管,存储器件为声延迟线或磁鼓,典型逻辑结构为定点运算,采用低级编程语言(早期为机器语言,后期为汇编语言)编制程序。
- 典型代表是IAS计算机
- 冯·诺依曼机(Von Neumann Machine)
45年冯·诺依曼提出“存储程序(Stored-program)”思想。冯·诺依曼于1946年开始设计的 “存储程序” 计算机。该机被称为 IAS计算机,它是后来通用计算机的原型。- 1945年,在共同讨论的基础上,冯·诺依曼以《关于EDVAC的报告草案》为题,起草了长达101页的总结报告,发表了全新的“存储程序(stored-program)通用电子计算机方案”,宣告了现代计算机结构思想的诞生。
- “存储程序”方式的基本思想 是:必须将事先编好的程序和原始数据送入主存后才能执行程序,一旦程序被启动执行,计算机能在不需操作人员干预下自动完成逐条取出指令并执行的任务。
- 第二代计算机为晶体管计算机,晶体管 1958~64年
- 元器件:逻辑元件采用晶体管,内存由磁芯构成,外存为磁鼓与磁带存储器。
- 特点:变址、中断、浮点运算、多路存储器、I/O处理器、中央交换结构(非总线结构)
- 软件:使用高级语言,提供了系统软件。
- 代表机种:IBM 7094(scientific)、1401(business)和DEC公司的PDP-1
- 第三代计算机为集成电路计算机。SSI/MSI 1965~71年
- 元器件:逻错元件与主存储器均由集成电路(IC)实现,
- 特点:微程序控制,高速缓存(Cache),虚拟存储器,流水线等。
- 代表机种:IBM 360和DEC公司的PDP-8(大/巨型机与小型机同时发展)
- 巨型机(Supercomputer):Cray-1
- 大型机(Mainframe):IBM360系列
- 小型机(Minicomputer):DEC PDP-8
- IBM System/360系列计算机(1964)
- 引入“兼容机”(系列机)概念
- 兼容机的特征 :
- 相同的或相似的指令集
- 相同或相似的操作系统
- 更高的速度
- 更多的I/O端口数
- 更大的内存容量
- 更高的价格
- DEC PDP-8创造了小型机的概念。
主要特点:首次采用总线结构。
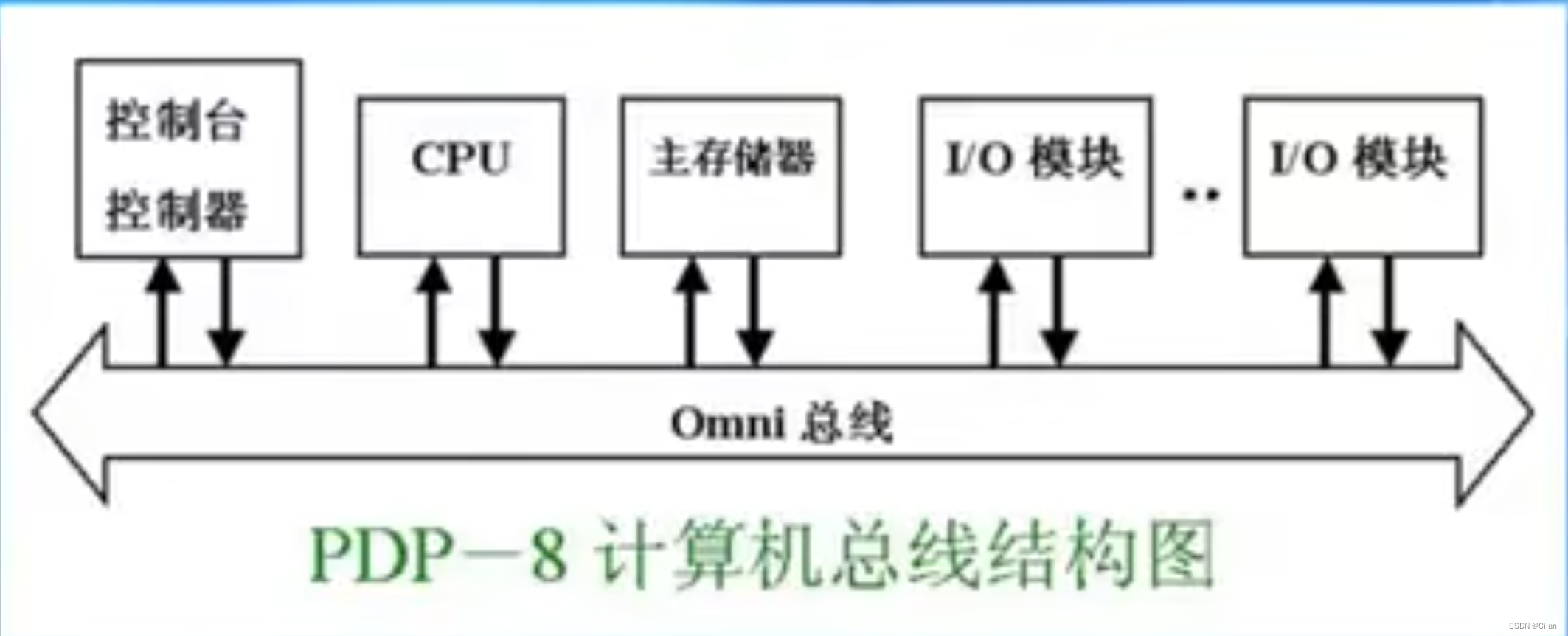
- “总线结构”的好处?
具有高度的灵活性,允许将模块插入总线以形成各种配置节省器件,可扩充性好(允许将新的符合标准的模块插入总线形成各种配置)、节省器件,体积小,价格便宜
- 第四代计算机为超大规模集成电路计算机。LSI/VLSI/ULSI 1972~至今
- 微处理器(CPU中所有元件放在一块芯片上成为可能。)和半导体存储器技术发展迅猛,微型计算机出现。使计算机以办公设备和个人电脑的方式走向普通用户。
- 半导体存储器
- 70年Fairchild公司生产出第一个相对大容量半导体存储器
- 74年位价格低于磁芯的半导体存储器出现,并快速下跌
- 从70年起,存储密度呈4倍提高(几乎是每3年)
- 微处理器
- 微处理器芯片密度不断增加,使CPU中所有元件放在一块芯片上成为可能。71年开发出第一个微处理器芯片4004。
- 特点Tinter
共享存储器,分布式存储器及大规模并行处理系统。
1.2 计算机系统的组成
-
什么是计算机?
计算机是一种能对数字化信息进行自动、高速算术和逻辑运算的通用处理装置。 -
计算机的功能
数据运算、数据存储、数据传送、控制。 -
计算机的基本部件及功能:
• 运算器(数据运算):ALU、GPRs、标志寄存器等
• 存储器(数据存储):存储阵列、地址译码器、读写控制电路
• 总线(数据传送):数据(MDR)、地址(MAR)和控制线
• 控制器(控制):对指令译码生成控制信号 -
计算机实现的所有任务都是通过执行一条一条指令完成的!
-
计算机的特点
高速:高速元件和“存储程序”工作方式带来高速性。
通用:体现在处理对象和应用领域没有限制。
准确:精度足够的算术运算带来雅确性。
智能:逻辑推理能力带智能性。
1.2.1 计算机硬件的基本组成
但目前为止,绝大部分通用计算机的基本组成仍然具有冯·诺依曼结构计算机的特征。
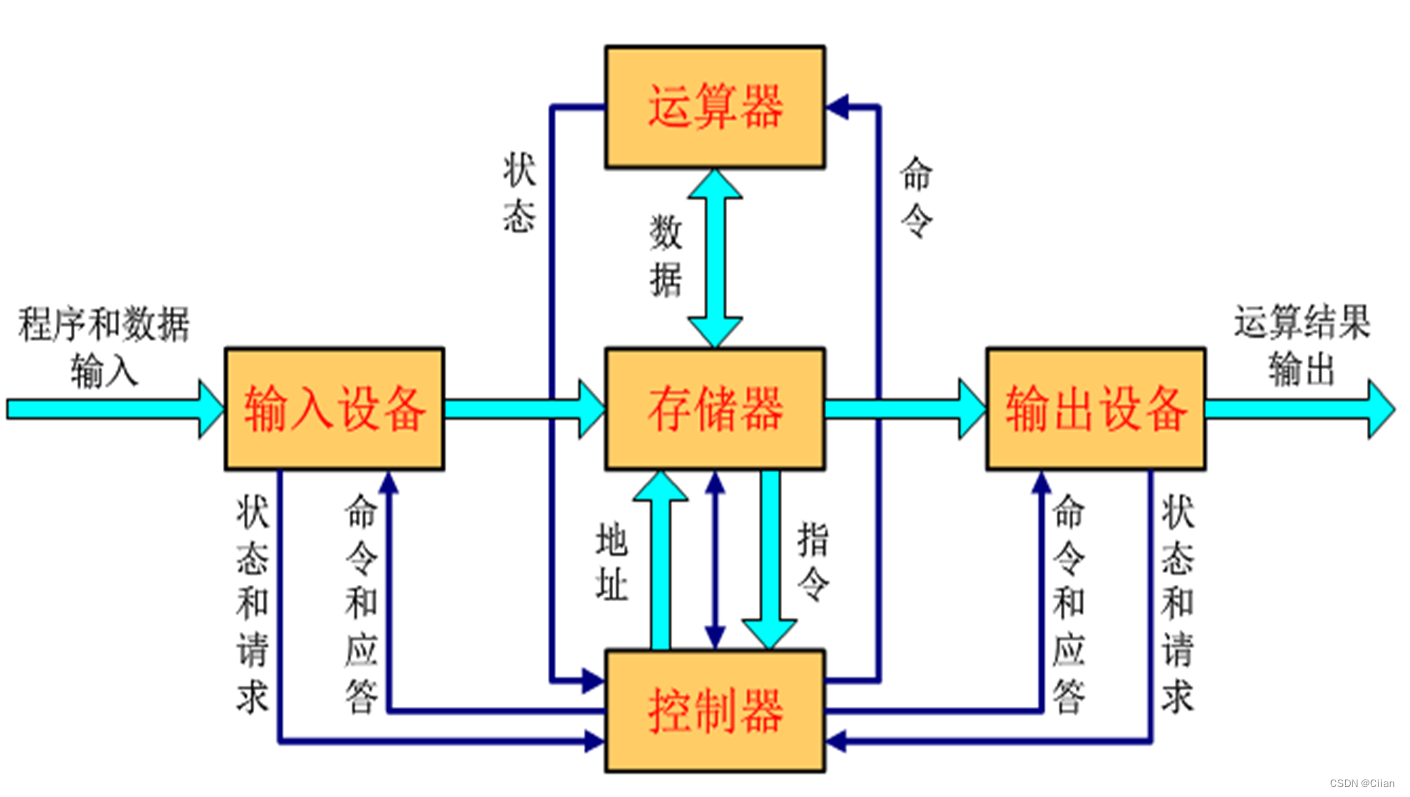
- 冯.诺依曼结构计算机模型
早期,部件之间用分散方式相连
现在,部件之间大多用总线方式相连
趋势,点对点(分散方式)高速连接 - 冯·诺依曼结构的基本思想 主要包括以下几方面。
- (1)采用“存储程序”的工作方式。
- (2)计算机由运算器、控制器、存储器、输入设备和输出设备5个基本部件组成。
- (3)存储器不仅能存放数据,而且也能存放指令,形式上数据和指令没有区别,但计算机应能区分它们;控制器应能控制指令的自动执行;运算器应能进行加、减、乘、除4种基本算术运算,并且也能进行逻辑运算和附加运算;操作人员可以通过输入/输出设备使用计算机。
- (4)计算机内部以二进制形式表示指令和数据;每条指令由操作码和地址码两部分组成。操作码指出操作类型,地址码指出操作数的地址;由一串指令组成程序。
- 现代计算机中,通常把运算器、控制器和各类寄存器等部件互连做在一个称为中央处理器(central processing unit,CPU)的芯片中。计算机硬件主要包括中央处理器、存储器、I/O控制器、外部设备和各类总线等。
1. 中央处理器
- 中央处理器简称 CPU或处理器,是整个计算机的核心部件,主要用于指令的执行。
- CPU主要包含两种基本部件:数据通路和控制器。
- 数据通路主要包含算术逻辑部件(arithmetic and logic unit,ALU)和通用寄存器等,
- ALU用来执行算术和逻辑运算等操作,通用寄存器用来暂存指令所用的操作数或执行结果。
- 控制器用来对指令进行译码,生成相应的控制信号,以控制数据通路进行正确的操作。
- 数据通路主要包含算术逻辑部件(arithmetic and logic unit,ALU)和通用寄存器等,
2. 存储器
- 存储器分为内存和外存,
- 内存包括主存储器(main memory,简称主存)和高速缓存(cache)。
- 因为早期计算机中没有高速缓存,所以一般情况下,并不区分内存和主存,两者含义相同,都是特指主存储器。
- 冯·诺依曼结构计算机采用“存储程序”的工作方式,在程序执行前,指令和数据都需事先输入到存储器中,这里的存储器就是指主存储器。
- 外存包括磁盘存储器和固态硬盘等直接和主存交换信息的存储器,以及一些用于数据备份的海量后备存储器。
- 内存包括主存储器(main memory,简称主存)和高速缓存(cache)。
3.外部设备和设备控制器
- 外部设备简称外设,也称为I/O设备,其中,I/O是输入/输出(input/output)的缩写。
- 外设通常由机械部分和电子部分组成,而且两部分通常是可以分开的,机械部分是外部设备本身,而电子部分则是控制外部设备的设备控制器。
- 外设通过设备控制器连接到主机上,各种设备控制器统称为I/O控制器、I/O接口或I/O模块。例如,键盘接口、打印机适配器、显示控制器(简称显卡)、网络控制器(简称网卡)等都是一种设备控制器。
4.总线
- 总线(bus)是传输信息的介质,用于在部件之间传输信息,CPU、主存和I/O模块通过
总线互连,在CPU和I/O模块中都内含相应的存储部件,即各类寄存器或缓存器。
一个典型的多总线计算机系统硬件结构示意图
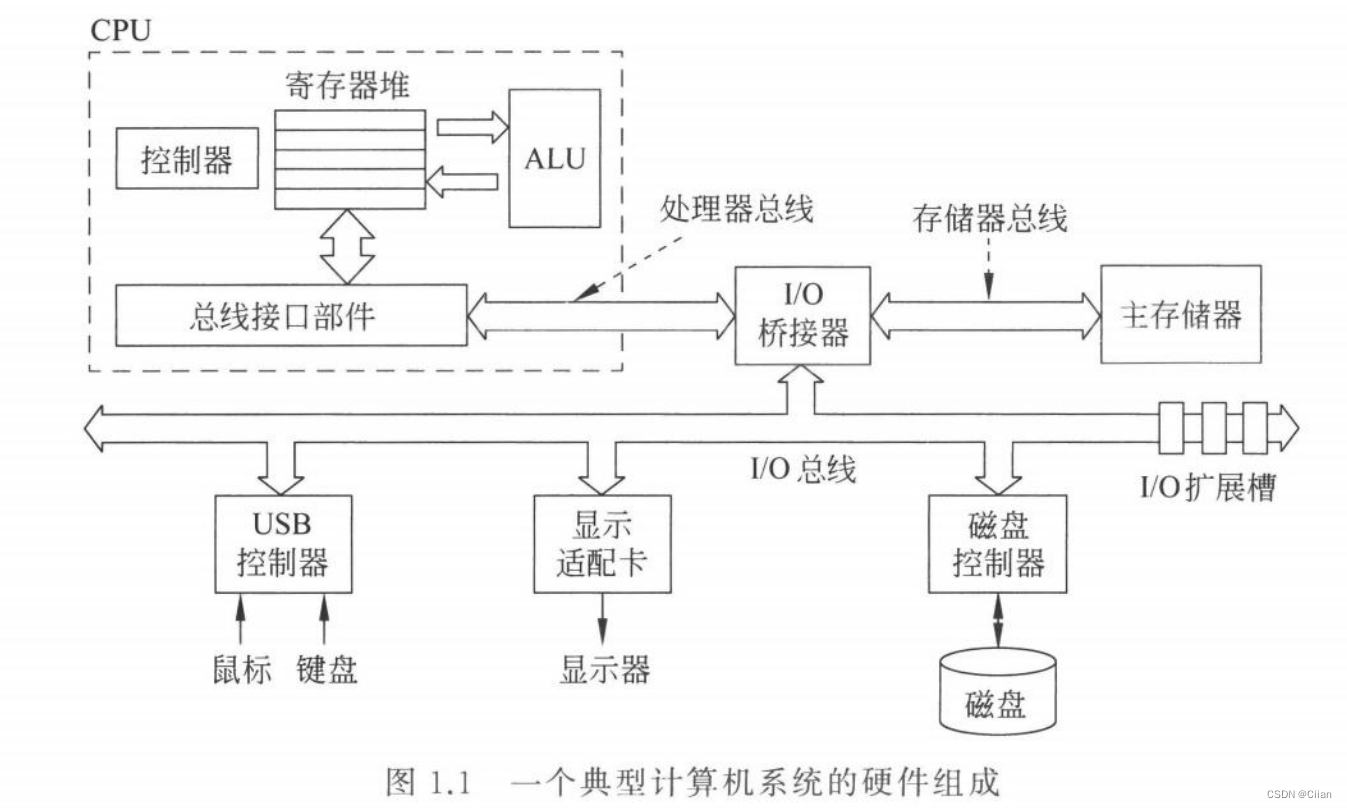
- ALU是数据处理部件,其处理的数据来自通用寄存器,运算的结果也送到通用寄存器中;磁盘和主存是存储部件,分别用于存储长期保存信息和临时保存信息;各类总线以及总线接口部件、I/O桥接器、I/O扩展槽、I/O控制器和显示适配器等都是互连部件,用于完成数据传送和缓存任务。

计算机硬件解剖的示意图,

Hardware/Software Interface(界面)
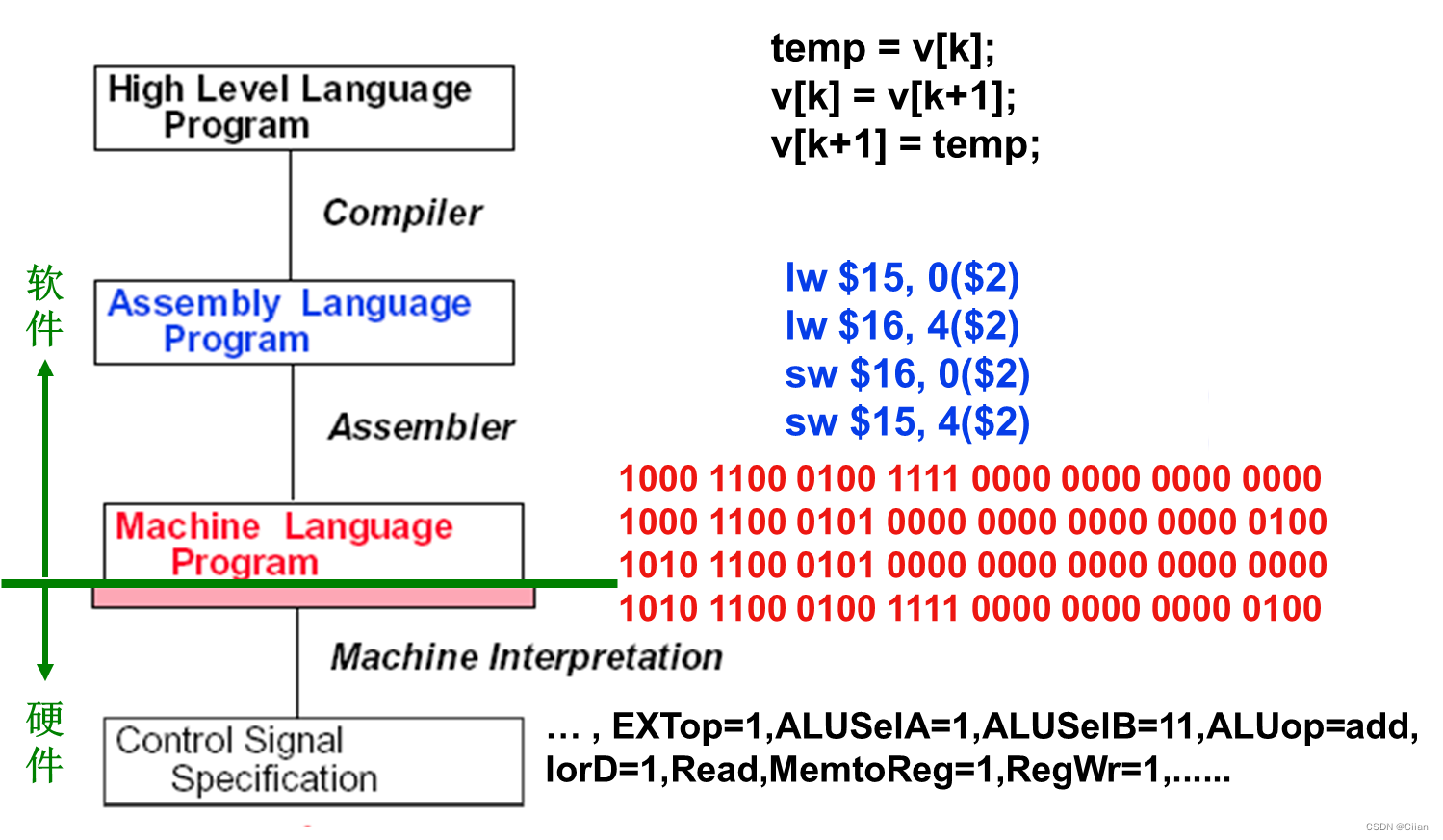
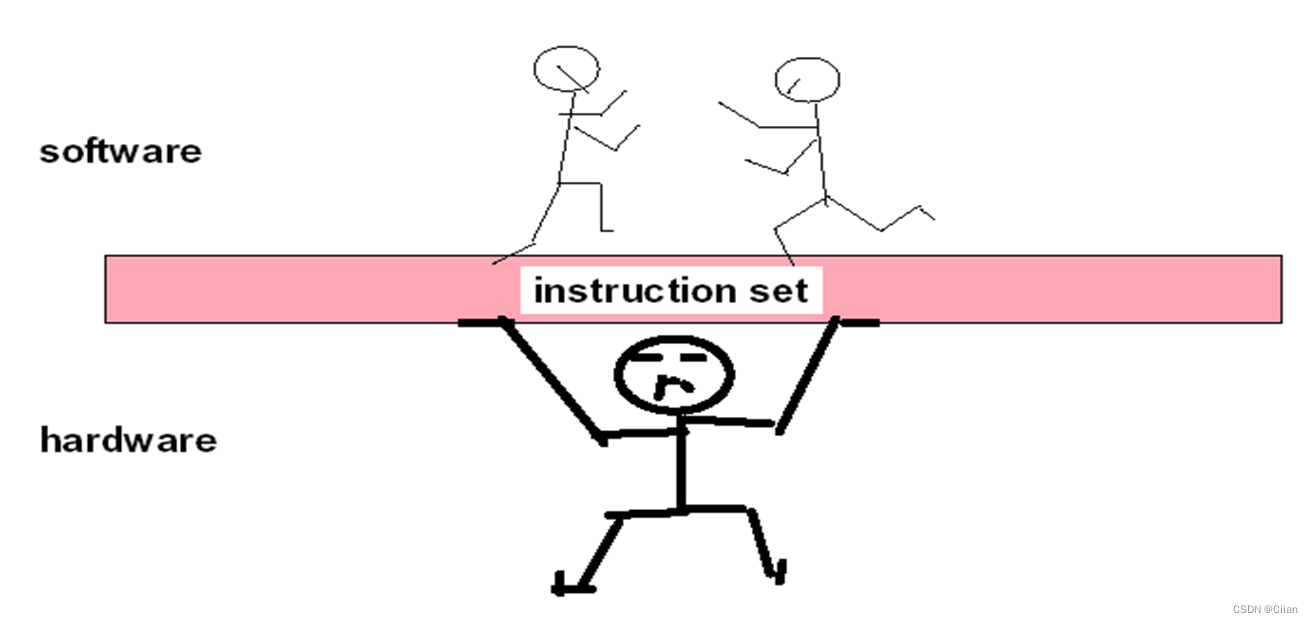
- 软件和硬件的界面: ISA(Instruction Set Architecture )指令集体系结构
- 机器语言由指令代码构成,能被硬件直接执行。
1.2.2 计算机软件
- 计算机中的操作由存储并运行在其内部的程序进行控制,这是冯·诺依曼结构计算机“存储程序”工作方式的重要特征。一般将软件分成应用软件和系统软件两大类。
- System software(系统软件) - 简化编程,并使硬件资源被有效利用,有效、安全地使用和管理计算机以及为开发和运行应用软件而提供的各种软件
- 操作系统(Operating System):管理整个计算机系统的资源,包括对它们进行调度、管理、监视和服务等,操作系统还提供计算机用户和硬件之间的人机交互界面,并提供对应用软件的支持;
- 语言处理系统:翻译程序+ Linker, Debug, etc …(源程序的编辑、转换、链接、装入和调试等功能)
- 翻译程序(Translator)有三类:
汇编程序(Assembler):汇编语言源程序→机器目标程序
编译程序(Complier):高级语言源程序→汇编/机器目标程序
解释程序(Interpreter ):将高级语言语句逐条翻译成机器指令并立即执行,不生成目标文件。
- 翻译程序(Translator)有三类:
- 其他实用程序: 如:磁盘碎片整理程序、备份程序等
- 数据库管理系统:用于建立、使用和维护数据库的软件系统。
- Application software(应用软件) - 解决具体应用问题/完成具体应用
- 各类媒体处理程序:Word/ Image/ Graphics/…
- 管理信息系统 (MIS)
- Game, …
- System software(系统软件) - 简化编程,并使硬件资源被有效利用,有效、安全地使用和管理计算机以及为开发和运行应用软件而提供的各种软件
1.3 计算机层次结构
开发和运行程序需什么支撑?
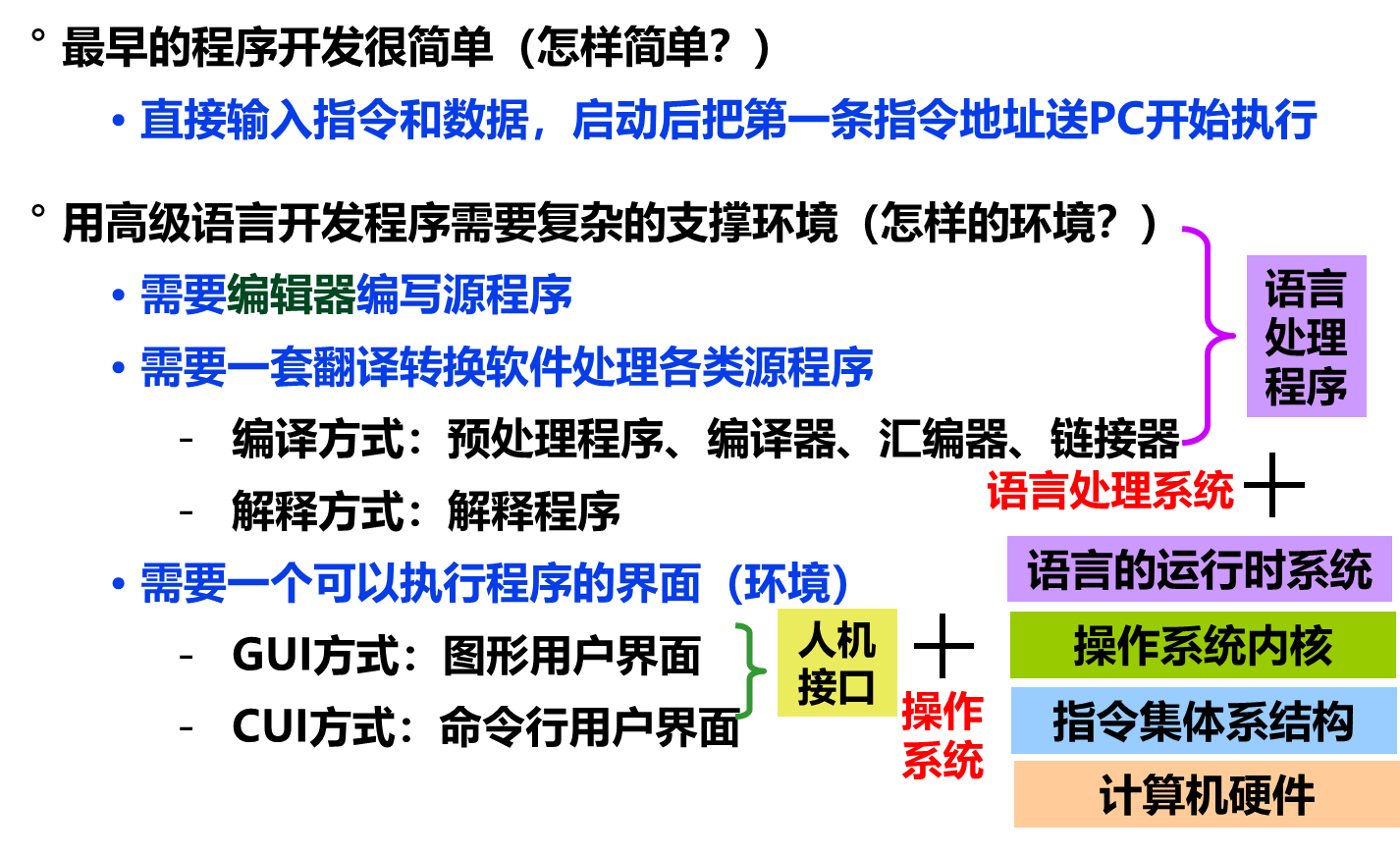
计算机系统的层次发展
-
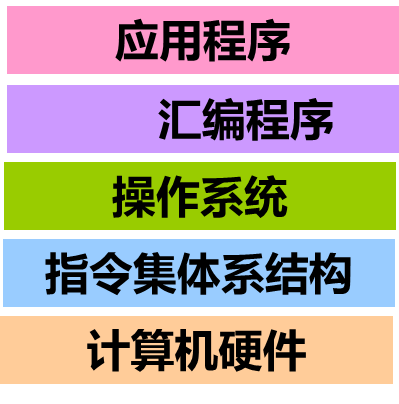
最早的计算机用机器语言编程
机器语言称为第一代程序设计语言(First generation programming language ,1GL )
-
后来用汇编语言编程
汇编语言称为第二代程序设计语言(Second generation programming language ,2GL )
-
现代计算机用高级语言编程
第三代程序设计语言(3GL)为过程式语言,编码时需要描述实现过程,即“如何做”。
第四代程序设计语言(4GL) 为非过程化语言,编码时只需说明“做什么”,不需要描述具体的算法实现细节。
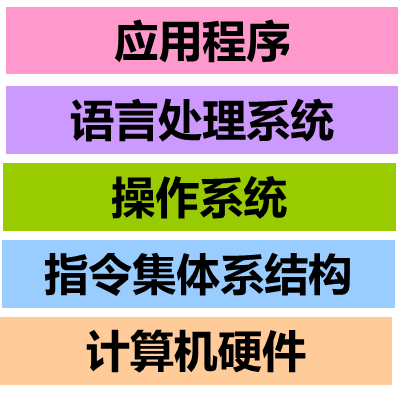
- 语言处理系统包括:各种语言处理程序(如编译、汇编、链接)、运行时系统(如库函数,调试、优化等功能)
- 操作系统包括人机交互界面、提供服务功能的内核例程
-
可以看出:语言的发展是一个不断“抽象”的过程,因而,相应的计算机系统也不断有新的层次出现
1.3.1 计算机系统抽象层的转换
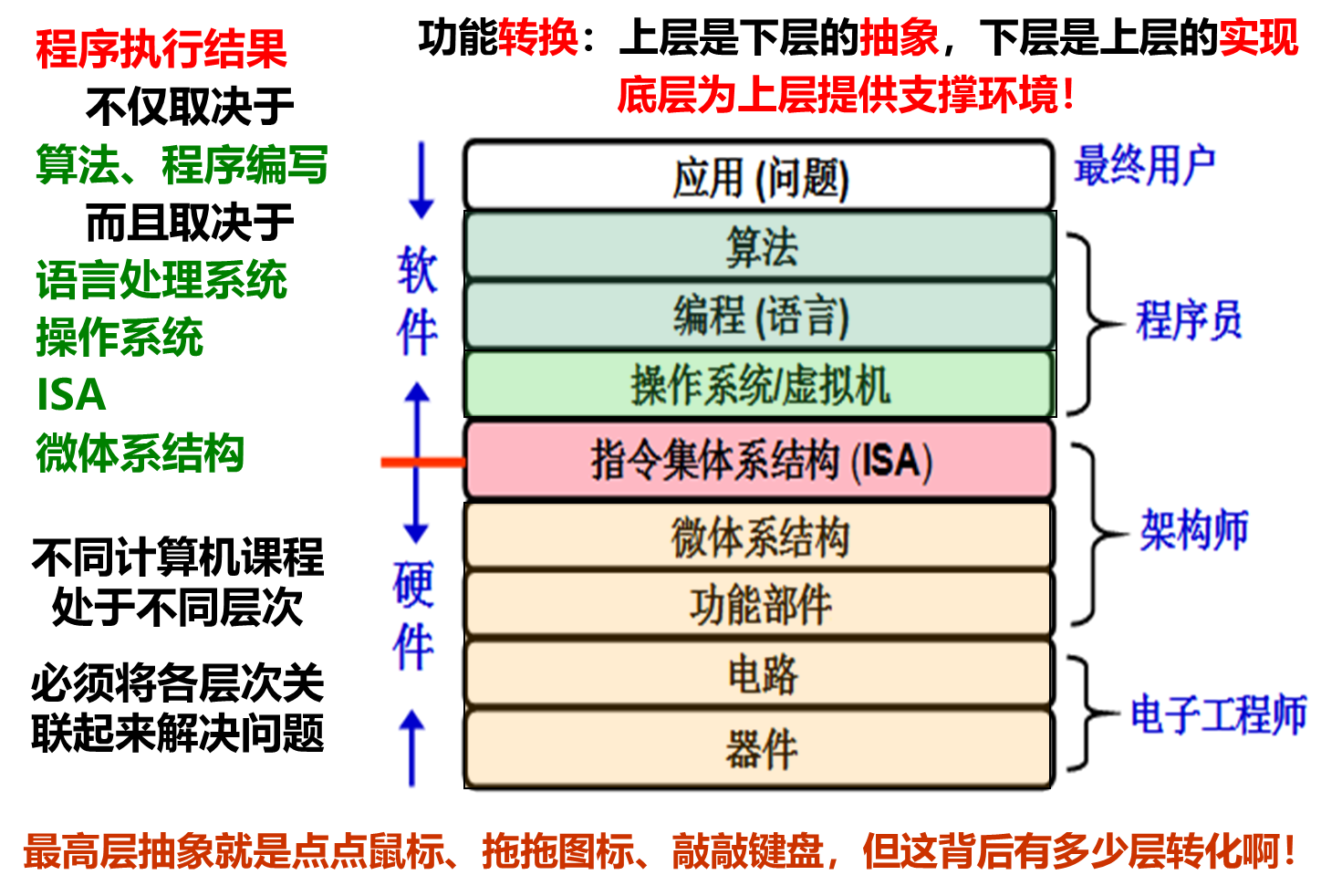
1.3.2 计算机系统的不同用户
计算机系统的层次结构

- 最终用户工作在由应用程序提供的最上面的抽象层
系统管理员工作在由操作系统提供的抽象层
应用程序员工作在由语言处理系统(主要有编译器和汇编器)的抽象层
语言处理系统建立在操作系统之上
系统程序员(实现系统软件)工作在ISA层次,必须对ISA非常了解
编译器和汇编器的目标程序由机器级代码组成
操作系统通过指令直接对硬件进行编程控制
ISA处于软件和硬件的交界面(接口) - 不同用户工作在不同层次,所看到的计算机不一样
- 中间阴影部分就是本课程主要内容,处于最核心的部分!
- ISA是最重要的层次!那么,什么是ISA呢?
指令集体系结构(ISA)
- ISA指Instruction Set Architecture,即指令集体系结构
- ISA是一种规约(Specification),它规定了如何使用硬件
- 可执行的指令的集合,包括指令格式、操作种类以及每种操作对应的操作数的相应规定;
- 指令可以接受的操作数的类型;
- 操作数所能存放的寄存器组的结构,包括每个寄存器的名称、编号、长度和用途;
- 操作数所能存放的存储空间的大小和编址方式;
- 操作数在存储空间存放时按照大端还是小端方式存放;
- 指令获取操作数的方式,即寻址方式;
- 指令执行过程的控制方式,包括程序计数器、条件码定义等。
- ISA在计算机系统中是必不可少的一个抽象层,Why?
- 没有它,软件无法使用计算机硬件!
- 没有它,一台计算机不能称为“通用计算机”
ISA和计算机组成(微结构)之间的关系

ISA是计算机组成的抽象
不同ISA规定的指令集不同,如,IA-32、MIPS、ARM等
计算机组成必须能够实现ISA规定的功能,如提供GPR、标志、运算电路等
同一种ISA可以有不同的计算机组成,如乘法指令可用ALU或乘法器实现
1.4程序开发与执行过程
1.4.1 从源程序到可执行程序
- 一个典型系统的硬件组成

PC:程序计数器;ALU:算术/逻辑单元;USB:通用串行总线
一个典型程序的转换处理过程
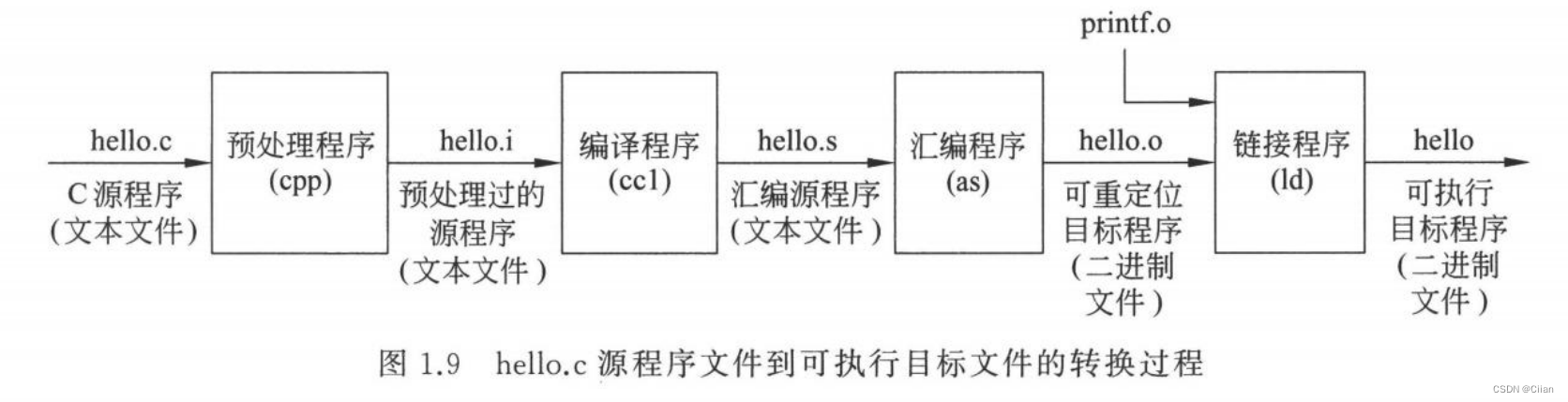
- (1)通过程序编辑软件得到hello.c文件。hello.c在计算机中以ASCII字符方式存放,

- (2)将hello.c进行预处理、编译、汇编和链接,最终生成可执行目标文件。从hello.c
到可执行目标文件hello的转换过程如图1.9所示。

1.4.2可执行文件的启动和执行
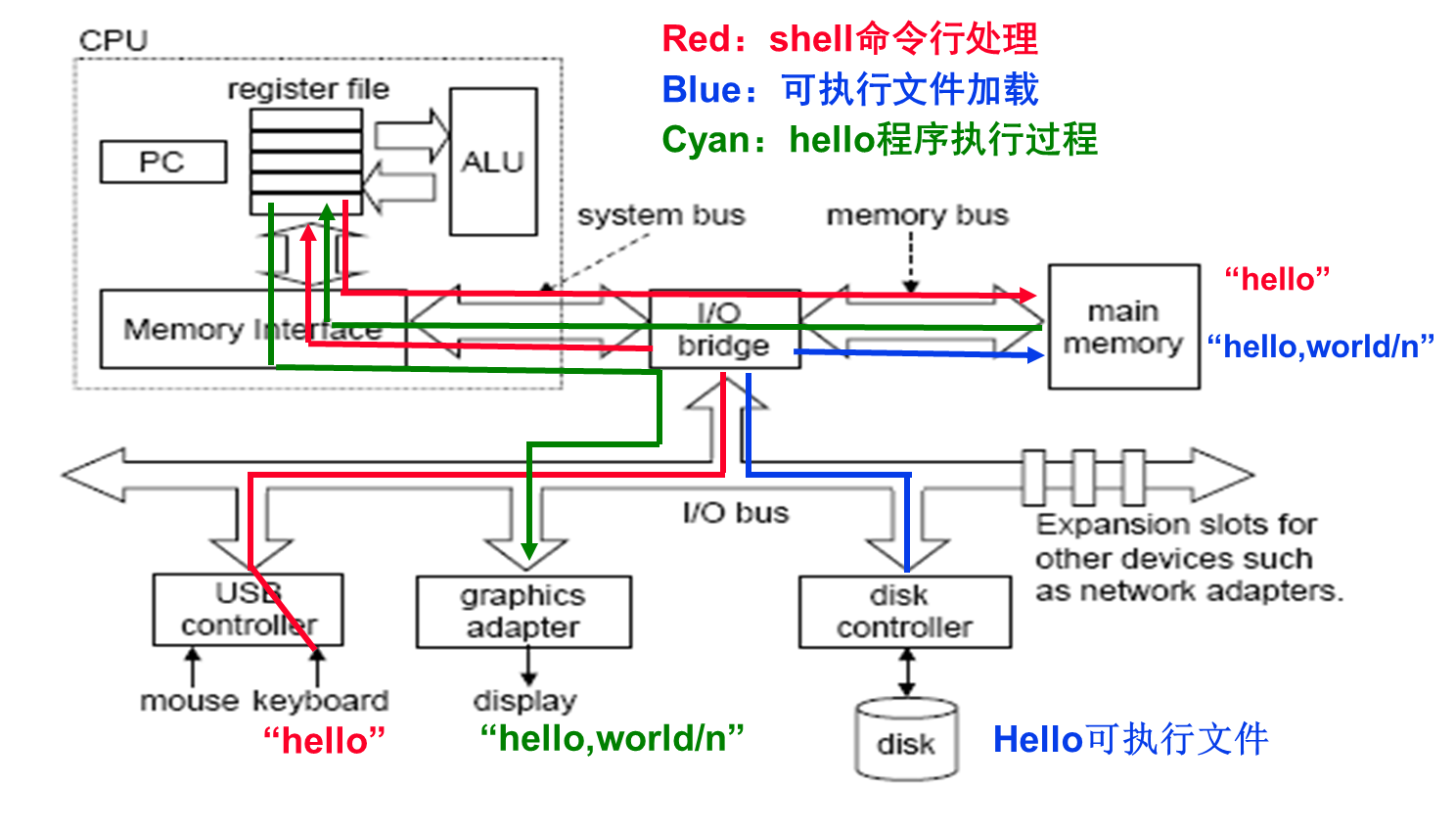
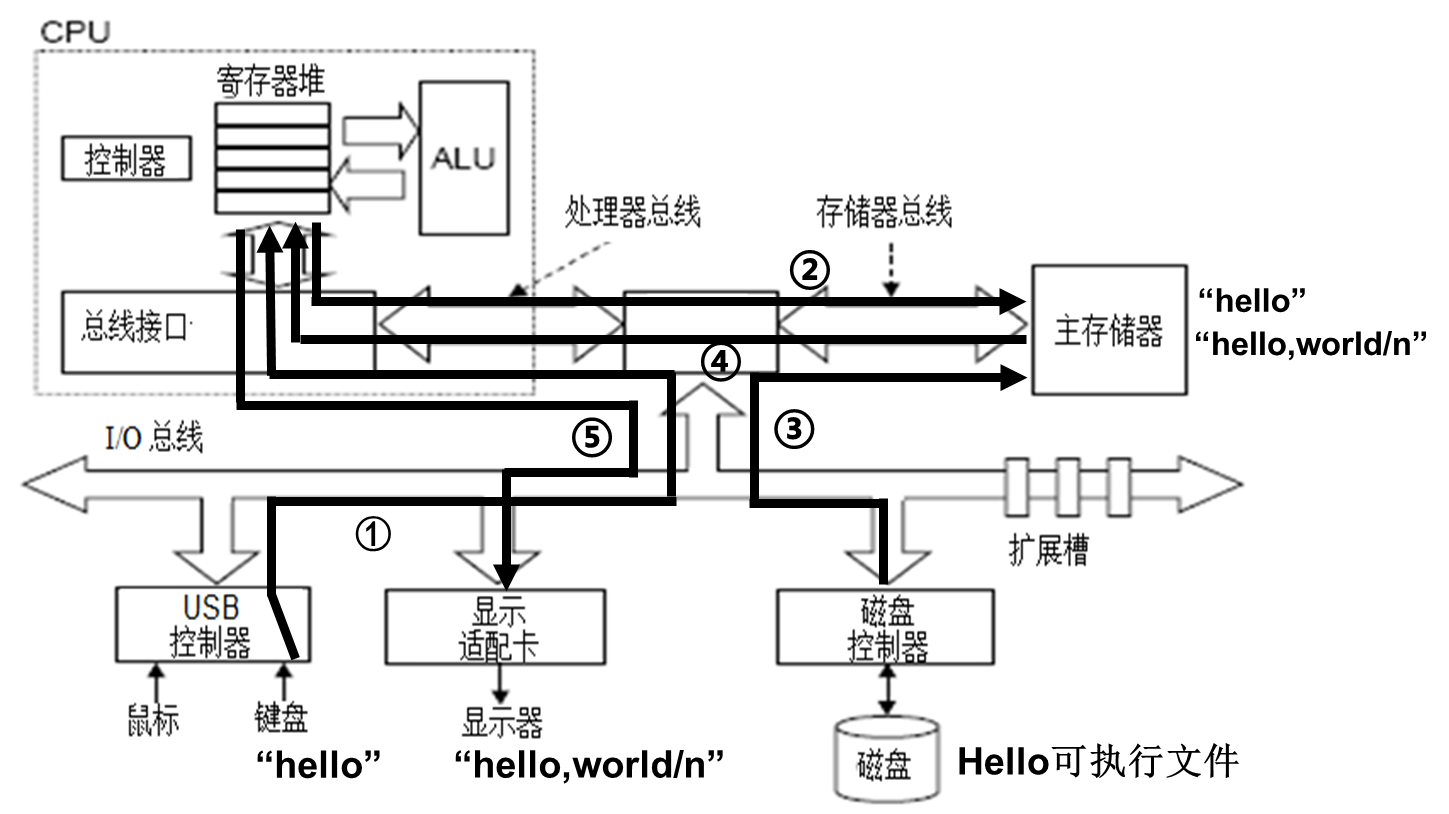
- 如图1.10所示,shell程序会将用户从键盘输入的每个字符逐一读入CPU 寄存器中
(对应线①),然后再保存到主存储器中,在主存的缓冲区形成字符串"./hello"(对应线②)。
等到接收到Enter按键时,shell将调出操作系统内核中相应的服务例程,由内核来加载磁
盘上的可执行文件 hello 到存储器(对应线③)。内核加载完可执行文件中的代码及其所要
处理的数据(这里是字符串"hello,world\n")后,将hello 程序第一条指令的地址送到程序
计数器(program counter,PC)中,CPU永远都是将PC的内容作为将要执行的指令的地址,
因此,CPU随后从第一条指令开始执行hello程序,将加载到主存的字符串"hello,world\n"
中的每一个字符从主存取到CPU的寄存器中(对应线④),然后将 CPU寄存器中的字符送
到显示器上显示出来(对应线⑤)。
1.4.3 程序与指令及控制信号的关系

1.4.4 指令的执行过程
- 现代计算机结构模型(冯·诺依曼结构模型机)
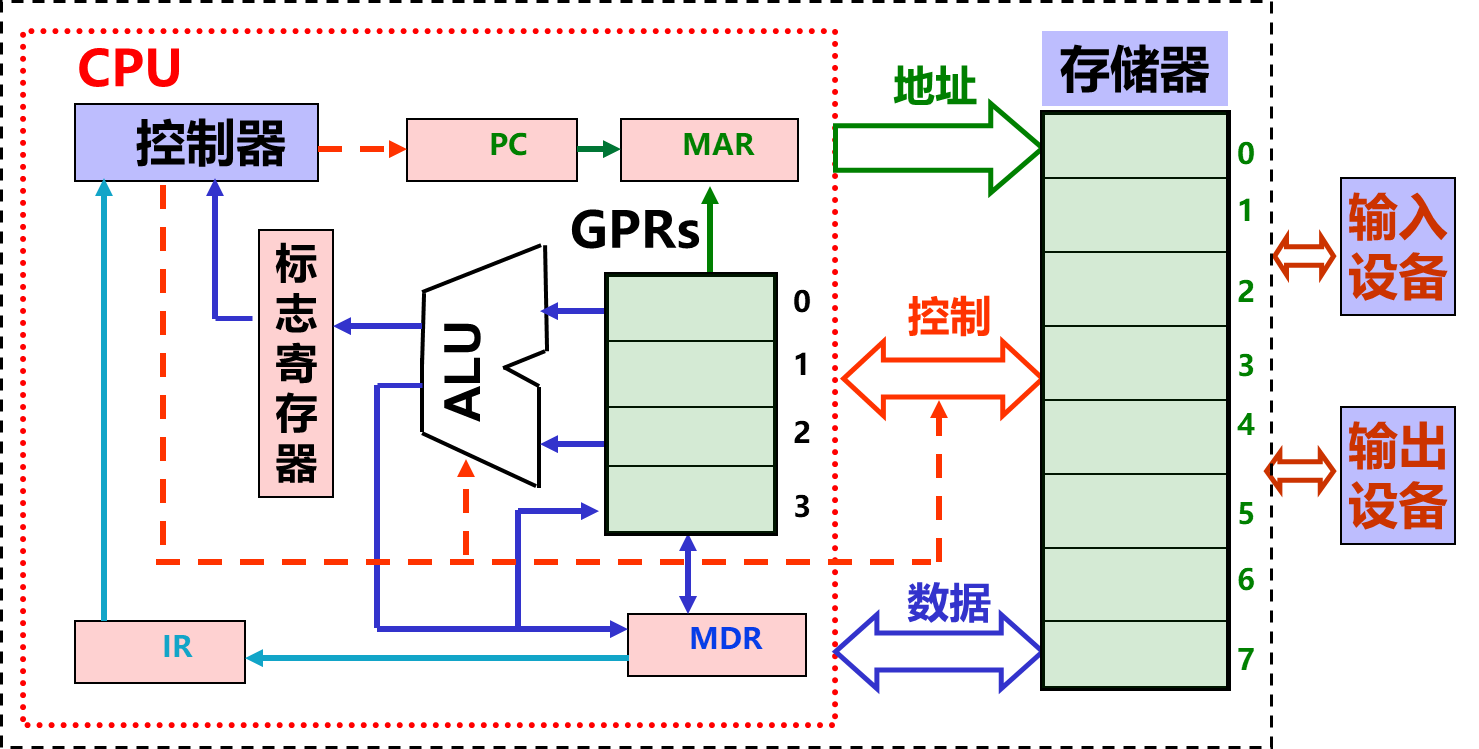
- CPU:中央处理器;PC:程序计数器;MAR:存储器地址寄存器
ALU:算术逻辑部件;IR:指令寄存器;MDR:存储器数据寄存器
GPRs:通用寄存器组(由若干通用寄存器组成,早期就是累加器)
厨房-CPU,你妈-控制器,盘-GPRs,锅灶等-ALU ,架子-存储器 - 计算机是如何工作的?“存储程序”工作方式!
- 类似“存储程序”工作方式:
- 做菜前
原材料(数据)和菜谱(指令)都按序放在厨房外的架子(存储器)上, 每个架子有编号(存储单元地址)。
菜谱上信息:原料位置、做法、做好的菜放在哪里等
例如,把10、11号架上的原料一起炒,并装入3号盘
然后,我告诉妈妈从第5个架上(起始PC=5)指定菜谱开始做 - 开始做菜
第一步:从5号架上取菜谱(根据PC取指令)
第二步:看菜谱(指令译码)
第三步:从架上或盘中取原材料(取操作数)
第四步:洗、切、炒等具体操作(指令执行)
第五步:装盘或直接送桌(回写结果)
第六步:算出下一菜谱所在架子号6=5+1(修改PC的值)
继续做下一道菜(执行下一条指令)
- 做菜前
- 程序由指令组成(菜单由菜谱组成)
- 程序在执行前
数据和指令事先存放在存储器中,每条指令和每个数据都有地址,指令按序存放,指令由OP(操作码)、ADDR(地址码)字段组成,程序起始地址置PC
(原材料和菜谱都放在厨房外的架子上, 每个架子有编号。妈妈从第5个架上指定菜谱开始做) - 开始执行程序
第一步:根据PC取指令(从5号架上取菜谱)
第二步:指令译码(看菜谱)
第三步:取操作数(从架上或盘中取原材料)
第四步:指令执行(洗、切、炒等具体操作)
第五步:回写结果(装盘或直接送桌)
第六步:修改PC的值(算出下一菜谱所在架子号6=5+1)
继续执行下一条指令(继续做下一道菜)
- 程序在执行前
- 指令和数据
- 程序启动前,指令和数据都存放在存储器中,形式上没有差别,都是0/1序列
- 采用”存储程序“工作方式:
- 程序由指令组成,程序被启动后,计算机能自动取出一条一条指令执行,在执行过程中无需人的干预。
- 指令执行过程中,指令和数据被从存储器取到CPU,存放在CPU内的寄存器中,指令在IR中,数据在GPR中。
- 指令中需给出的信息:
- (1)操作码,具体说明了操作的性质及功能。
- (2)操作数的地址。(立即数、寄存器编号、存储地址)
- (3)操作结果的存储地址。(寄存器编号、存储地址)
- (4)下一条指令的地址
- 存储地址的描述与操作数的数据结构有关!.
该课程及其实验课程的主要学习内容
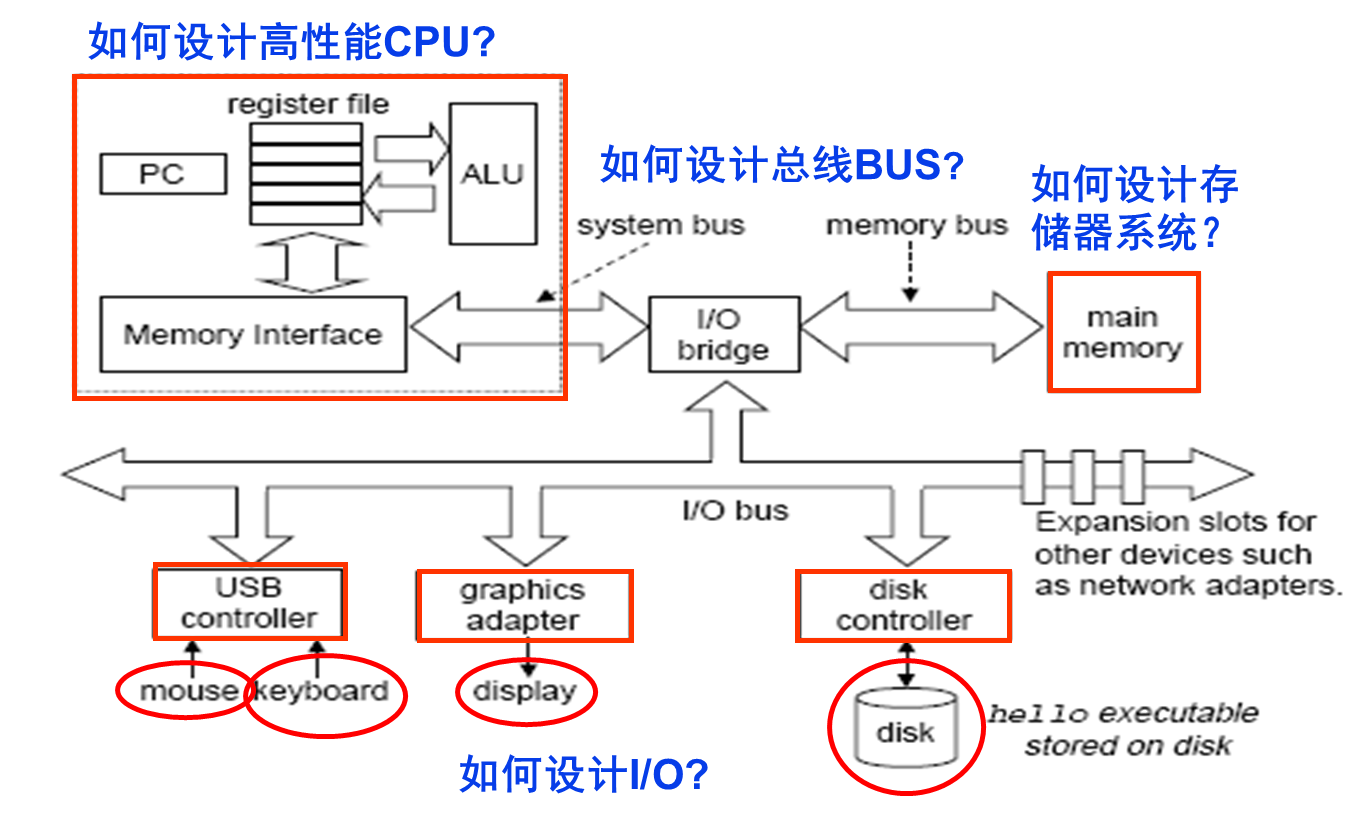
Course Outline
- 性能评价(Performance measurement)
- 计算机算术(Arithmetic for Computer)
- 数据的表示和运算
- 存储器层次结构(Memory Hierarchies )
- 指令集体系结构(Instruction Set Architecture)
- CPU设计
- 数据通路 (Data path) 和控制器(Control Unit)
- 流水线技术(Pipelining)
- 系统总线 (System Buses)
- 输入/输出系统(Input / Output system)
1.5 计算机系统性能评价
- 制造成本(manufacturing cost)
- 衡量计算机性能的基本指标
- 计算机性能测量
- 指令执行速度(MIPS、MFLOPS/TFLOPS/PFLOPS)
- 基准程序( Benchmark)
- SPEC (Systems Performance Evaluation Committee)
- Linpack (Linear system package):线性系统软件包基准测试程序
- 每个圆晶片上的小片数、集成电路成本都与芯片面积有关!
1.5.1计算机性能的定义
- 衡量计算机性能的基本指标
- 响应时间(response time) (执行时间(execution Time)/ 等待时间(latency))
- 从作业提交开始到作业完成所用的时间。
- 吞吐率( throughput)
- 吞吐率表示在单位时间内所完成的工作量
- 带宽(bandwidth)
- 响应时间(response time) (执行时间(execution Time)/ 等待时间(latency))
- 不同应用场合用户关心的性能不同:
- 要求吞吐率高的场合,例如: 多媒体应用(音/视频播放要流畅)
- 要求响应时间短的场合:例如: 事务处理系统(存/取款速度要快)
- 要求吞吐率高且响应时间短的场合: ATM、文件服务器、Web服务器等
- 基本的性能评价标准是:CPU的执行时间
计算机性能的测量
- 比较计算机的性能时,用执行时间来衡量
- 完成同样工作量所需时间最短的那台计算机就是性能最好的
- 处理器时间往往被多个程序共享使用,因此,用户感觉到的程序执行时间并不是程序真正的执行时间(从hello程序执行过程可知)
- 通常把用户感觉到的响应时间分成以下两个时间:
- CPU时间:指CPU真正花在程序执行上的时间。又包括两部分:
- 用户CPU时间:用来运行用户代码的时间
- 系统CPU时间:为了执行用户程序而需要运行操作系统程序的时间
- 其他时间:指等待I/O操作完成或CPU花在其他用户程序的时间
- CPU时间:指CPU真正花在程序执行上的时间。又包括两部分:
- 系统性能和CPU性能不等价,有一定的区别
- 系统性能(System performance):系统响应时间,与CPU外的其他部分有关
- CPU性能(CPU performance):用户CPU时间
- 本章主要讨论CPU性能,即:CPU真正用在用户程序执行上的时间
问题:用户CPU时间与系统响应时间哪个更长?
CPU执行时间的计算
- 几个重要的概念和参数。
- 程序由指令构成。
- CPU执行时间就是执行程序中每条指令的时间。
- 时钟周期:是由CPU时钟定义的定长时间间隔,是CPU工作的最小时间单位,也称节拍脉冲或T周期。
- 时钟频率(clock rate)。CPU的主频就是主脉冲信号的时钟频率,它是CPU 时钟周期的倒数。
- CPI(cycles per instruction)。CPI表示执行一条指令所需的时钟周期数。不同指令的功能不同,所需的时钟周期数也可能不同,
- 因此,对于一条特定指令而言,其CPI指执行该条指令所需的时钟周期数,此时CPI是一个确定的值;
- 对于一个程序或一台机器来说,其综合CPI指该程序或该机器指令集中的所有指令执行所需的平均时钟周期数。
- 只考虑执行一个程序
- 用户 CPU 时间 =程序总时钟周期数÷时钟频率=程序总时钟周期数×时钟周期
- 程序总时钟周期数=程序总指令条数×CPI(综合CPI)
- 如果已知程序中共有n种不同类型的指令,第i种指令的条数和CPI分别为Ci和CPIi
- 程序总时钟周期数 = ∑ i = 1 n ( C P I i ∗ C i ) \sum_{i=1}^{n}(CPI_i * C_i) ∑i=1n(CPIi∗Ci)
- 所以,CPU时间= 时钟周期 x ∑ i = 1 n ( C P I i ∗ C i ) \sum_{i=1}^{n}(CPI_i * C_i) ∑i=1n(CPIi∗Ci)
- 程序的综合CPI也可由以下公式求得,其中,Fi表示第i种指令在程序中所占的比例:
- CPI = ∑ i = 1 n ( C P I i ∗ F i ) \sum_{i=1}^{n}(CPI_i * F_i) ∑i=1n(CPIi∗Fi) =程序总时钟周期数÷程序总指令条数
- 已知CPU时间、时钟频率、总时钟数、指令条数,则程序综合CPI为:
- CPI = (CPU 时间×时钟频率) / 指令条数 = 总时钟周期数 / 指令条数
- 用户 CPU 时间=程序总指令条数×CPI(综合CPI)× 时钟周期
- (CPU执行多个程序,求单个程序)
- CPU 执行时间 = CPU时钟周期数 / 程序 × 时钟周期 = CPU时钟周期数 / 程序 ÷ 时钟频率 = 指令条数 / 程序 × CPI × 时钟周期
- CPU时钟周期数 / 程序 = 指令条数 / 程序 × CPI
- CPI = CPU时钟周期数 / 程序 ÷指令条数 / 程序
- CPI 用来衡量以下各方面的综合结果
- Instruction Set Architecture(ISA)
- Implementation of that architecture
(Organization & Technology) - Program(Compiler、Algorithm)
- 单靠CPI不能反映CPU性能!为什么?没有时钟周期
- 例如,单周期处理器CPI=1,但性能差!因为单周期处理器时钟周期很长
基本的性能评价标准是:CPU的执行时间
- 机器X的速度(性能)是Y的n倍”的含义:
- 两台计算机性能之比就是用户 CPU 时间之比的倒数
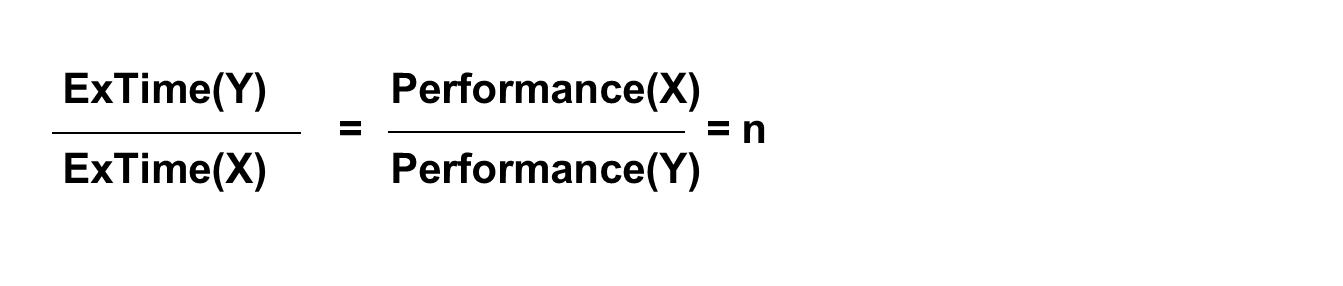
- 相对性能用执行时间的倒数来表示!
- X和Y的性能之比为n,则计算机 X的速度是计算机Y的速度的n倍”,
- 两台计算机性能之比就是用户 CPU 时间之比的倒数
- Architecture = Instruction Set Arch. + Organization
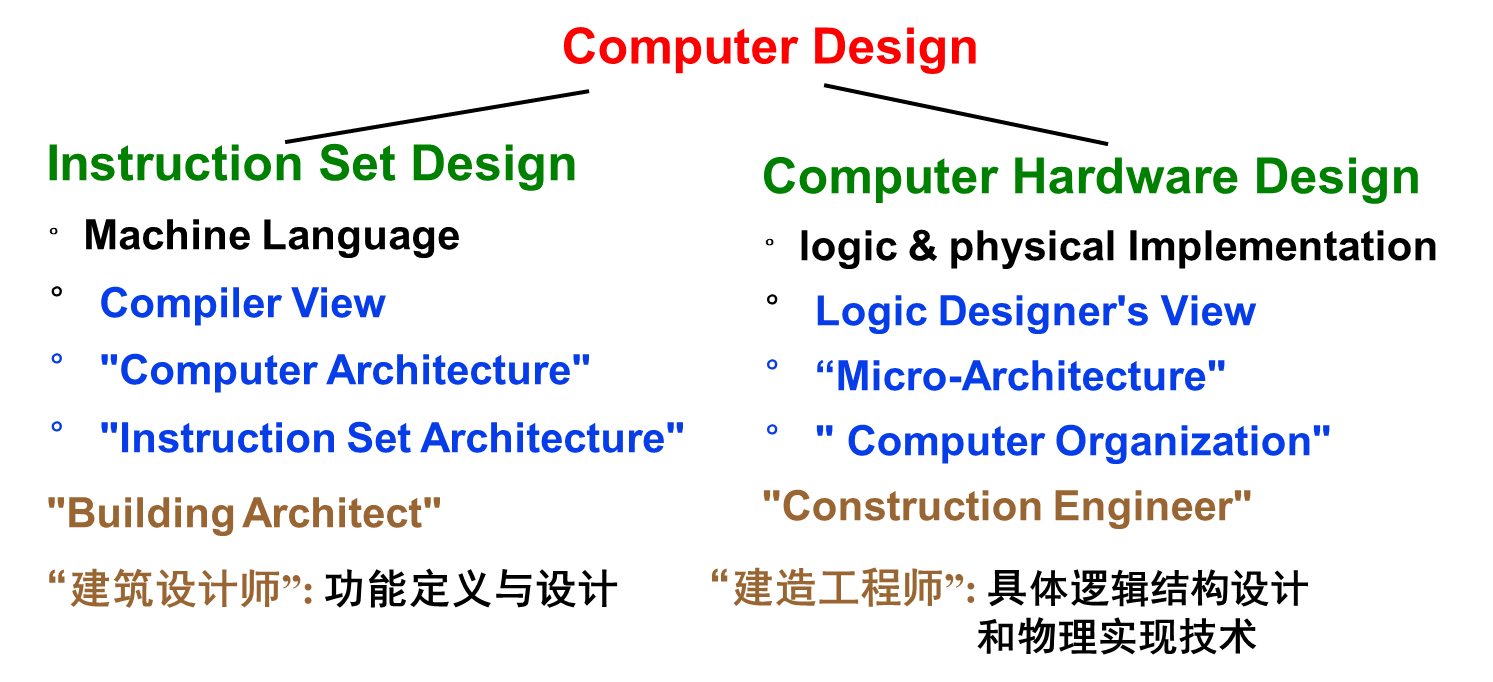
例如,是否提供“乘法指令”是ISA设计要考虑的问题;如何实现乘法指令(用专门乘法器还是用一个加法器+移位器实现)是组成(Organization)考虑的问题;如何布线、用什么材料和工艺设计等是实现技术(Technology)考虑的问题。 - Aspects of CPU Performance

program程序,instructions指令,Cycles时钟周期

- Example1
- 程序P在机器A上运行需10 s, 机器A的时钟频率为400MHz。 现在要设计一台机器B,希望该程序在B上运行只需6 s. 机器B时钟频率的提高导致了其CPI的增加,使得程序P在机器B上时钟周期数是在机器A上的1.2倍。机器B的时钟频率达到A的多少倍才能使程序P在B上执行速度是A上的10/6=1.67倍?
- Answer:
CPU时间A = 时钟周期数A / 时钟频率A
时钟周期数A = 10 sec x 400MHz = 4000M个
时钟频率B = 时钟周期数B / CPU时间B
= 1.2 x 4000M / 6 sec = 800 MHz
机器B的频率是A的两倍,但机器B的速度并不是A的两倍!
1.5.2用指令执行速度进行性能评估
-
Marketing Metrics (产品宣称指标)
-
指令速度所用的计量单位为MIPS(million instructions per second),其含义:是平均每秒钟执行多少百万条指令。
- MIPS = Instruction Count / Second x1/106 = Clock Rate / CPI x 1/106
- MIPS反映了机器执行定点指令的速度
- 因为每条指令执行时间不同,所以MIPS总是一个平均值。
-
用MIPS数表示性能的局限?
- 不同机器的指令集不同
- 程序由不同的指令混合而成
- 指令使用的频度动态变化
- Peak MIPS: (不实用)(有些制造商经常将峰值MIPS直接当作 MIPS,)
-
与定点指令执行速度 MIPS相对应的用来表示浮点操作速度的指标是 MFLOPS(million floating point operations per second)
- 它表示每秒钟所执行的浮点运算有多少百万次,它是基于所完成的操作次数而不是指令数来衡量的。
- MFLOPS = FP Operations / Second x 1/106
- 用MFLOPS数表示性能也有一定局限!不一定是程序中花时间的部分
- 浮点运算实际上包括了所有涉及小数的运算,在某类应用软件中常常出现,比整数运算更费时间。现今大部分的处理器中都有浮点运算器。因此每秒浮点运算次数所量测的实际上就是浮点运算器的执行速度。而最常用来测量每秒浮点运算次数的基准程序(benchmark)之一,就是Linpack。
• 一个MFLOPS(megaFLOPS):每秒一佰万(=10^6)次的浮点运算,
• 一个GFLOPS(gigaFLOPS):每秒拾亿(=10^9)次的浮点运算,
• 一个TFLOPS(teraFLOPS):每秒万亿(=10^12)次的浮点运算,
• 一个PFLOPS(petaFLOPS):每秒千万亿(=10^15)次的浮点运算,
• 一个EFLOPS(exaFLOPS):每秒百亿亿(=10^18)次的浮点运算。
-
Example: MIPS数不可靠!
- (书中例1.3)Assume we build an optimizing compiler for the load/store machine. The compiler discards 50% of the ALU instructions.
仅在软件上优化,没涉及到任何硬件措施 - (1) What is the CPI ?
- ( 2) Assuming a 20 ns clock cycle time (50 MHz clock rate). What is the MIPS rating for optimized code versus unoptimized code? Does the MIPS rating agree with the rating of execution time?

- (书中例1.3)Assume we build an optimizing compiler for the load/store machine. The compiler discards 50% of the ALU instructions.
1.5.3 用基准程序进行性能评估
选择性能评价程序(Benchmarks)
基准程序(benchmarks)是进行计算机性能评测的一种重要工具。
- 用基准程序来评测计算机的性能
- 基准测试程序是专门用来进行性能评价的一组程序
- 不同用户使用的计算机用不同的基准程序
- 基准程序通过运行实际负载来反映计算机的性能
- 最好的基准程序是用户实际使用的程序或典型的简单程序
- 基准程序的缺陷
- 现象:基准程序的性能与某段短代码密切相关时,会被利用以得到不当的性能评测结果
- 手段:硬件系统设计人员或编译器开发者针对这些代码片段进行特殊的优化,使得执行这段代码的速度非常快
- 例1:Intel Pentium处理器运行SPECint时用了公司内部使用的特殊编译器,使其性能极高
- 例2:矩阵乘法程序SPECmatrix300有99%的时间运行在一行语句上,有些厂商用特殊编译器优化该语句,使性能达VAX11/780的729.8倍!
Successful Benchmark: SPEC
- 1988年,5家公司( Sun, MIPS, HP, Apollo, DEC )联合提出了SPEC (Systems Performance Evaluation Committee)
- SPEC给出了一组标准的测试程序、标准输入和测试报告。它们是一些实际的程序,包括 OS calls、 I/O等。
- 版本 89:10 programs = 4 for integer + 6 for FP, 用每个程序的执行时间求出一个综合性能指标
- 版本92:SPECInt92 (6 integer programs) and SPECfp92 (14 floating point programs)
- 整数和浮点数单独提供衡量指标:SPECInt92和SPECfp92
- 增加 SPECbase: 禁止使用任何与程序有关的编译优化开关
- 版本95: 8 int + 10fp
- 较新版本: include SPEC HPC96, SPEC JVM98, SPEC WEB99, SPEC OMP2001. SPEC CPU2000,See http://www.spec.org
- “benchmarks useful for 3 years”
- Base machine is changed from VAX-11/780 to Sun SPARC 10/40
综合性能评价的方法
- 可用以下两种平均值来评价:
- Arithmetic mean(算术平均):求和后除n
- Geometric mean(几何平均):求积后开根号n
- 根据算术平均执行时间能得到总平均执行时间
- 根据几何平均执行时间不能得到程序总的执行时间
- 执行时间的规格化(测试机器相对于参考机器的性能):
- time on reference machine ÷ time on measured machine
- 平均规格化执行时间不能用算术平均计算,而应该用几何平均
- program A going from 2s to 1s as important as
program B going from 2000s to 1000s.
(算术平均值不能反映这一点!)
- program A going from 2s to 1s as important as
1.5.4 Amdahl定律
- 阿姆达尔定律是计算机系统设计方面重要的定量原则之一
- 基本思想:对系统中某部分(硬件或软件)进行更新所带来的系统性能改进程度,取决于该部分被使用的频率或其执行时间占总执行时间的比例

- 若整数乘法器改进后可加快10倍,整数乘法指令在程序中占40%,则整体性能可改进多少倍?若占比达60%和90%,则整体性能分别能改进多少倍?
- 40%:1/(0.4/10+0.6)=1.56;
60%:1/(0.6/10+0.4)=2.17;
90%:1/(0.9/10+0.1)=5.26。
- 基本思想:对系统中某部分(硬件或软件)进行更新所带来的系统性能改进程度,取决于该部分被使用的频率或其执行时间占总执行时间的比例
- 例:某程序在某台计算机上运行所需时间是100秒,其中,80秒用来执行乘法操作。要使该程序的性能是原来的5倍,若不改进其他部件而仅改进乘法部件,则乘法部件的速度应该提高到原来的多少倍?
- 解:根据公式 p=1/(t/n+1-t) 知:
5=1/(0.8/n+0.2),0.8/n+0.2 = 1/5 = 0.2
要使上述公式满足,则必须 0.8/n=0,即n→∞
- 解:根据公式 p=1/(t/n+1-t) 知:
- 也就是说,即使乘法运算时间占80%,也不可能通过对乘法部件的改进,使整体性能提高到原来的5倍。
当乘法运算时间占比<=80%,则无论如何对乘法部件进行改进,都不能使整体性能提高到原来的5倍。
1.5 小结
- 性能的定义:一般用程序的响应时间或系统的吞吐率表示机器或系统整体性能。
- CPU性能的测量(用户程序的CPU执行时间):
- 一般把程序的响应时间划分成CPU时间和等待时间,CPU时间又分成用户CPU时间和系统CPU时间。
- 因为操作系统对自己所花费的时间进行测量时,不十分准确,所以,对CPU性能的测算一般通过测算用户CPU时间来进行。
- 各种性能指标之间的关系:
- CPU执行时间=CPU时钟周期数 x 时钟周期
- 时钟周期和时钟频率互为倒数
- CPU时钟周期数 = 程序指令数 x 每条指令的平均时钟周期数CPI
- MIPS数在有些情况下不能说明问题,不具有可比性!
- 性能评价程序的选择:
- 采用一组基准测试程序进行综合(算术(加权)平均/几何平均)评测。
- 有些制造商会针对评测程序中频繁出现的语句采用专门的编译器,使评测程序的运行效率大幅提高。因此有时基准评测程序也不能说明问题。
- Amdahl定律定义了增强或加速部分部件而获得的整体性能的改进程度
- 对于某种特定的指令集体系结构,提高计算机性能的主要途径有:
- 提高时钟频率(第七章 流水线)
- 优化处理器中数据通路的结构以降低CPI(单周期/多周期/流水线)
- 采用编译优化措施来减少指令条数或降低指令复杂度(第五章 指令系统 )

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









