




 本文介绍了使用Gephi绘制网络图的详细步骤,包括PMI-Gephi网络构建、edge_csv数据规整、解决导入数据时的乱码问题、图像调整以及保存设置。通过高级筛选功能优化数据,调整节点大小和线条粗细,以实现更清晰、简洁的网络图。
本文介绍了使用Gephi绘制网络图的详细步骤,包括PMI-Gephi网络构建、edge_csv数据规整、解决导入数据时的乱码问题、图像调整以及保存设置。通过高级筛选功能优化数据,调整节点大小和线条粗细,以实现更清晰、简洁的网络图。
写在前面
现在是2022年03月26日,周六晚20:35
前段时间准备将ROST CM6 绘制的图像转用 Gephi 软件来进行替代
也学习了一些前人的经验,但据我个人总结,Gephi具有以下2个硬伤:
1、绘制的线条过多过乱
2、无法直接选择节点大小
当然在之前也给出了一些解决方法,如通过筛选控制线条数目,采用导入文件的形式控制节点 Size 等,但我个人觉得依然不是一个很好的方法。
于是我就尝试了一下 Gephi 第一辑中我脑海中一闪而过的念头,事实证明,这确实或者说应该是对于大量无规则语义内容最为行之有效的 Gephi 绘图方案(至少目前我是这样觉得的)

收回第一辑的这段话(光速打脸)
并在第三辑阐明这才是最好用的方法!!
正餐开始
测试结果样例:

完成一幅高质量的 Gephi 图,需要从以下几个方面出发,下面就一步步讲如何实现上述过程:
1、PMI-Gephi 网络构建
利用PMI-Gephi相关代码构建完网络图(共现矩阵)之后,点选数据资料,即可查看相关数据信息
首先是节点的相关数据信息,具有代表性的是具有 Modularity Class(事先经过模块化处理) 和加权度,且AB块内容完全相同
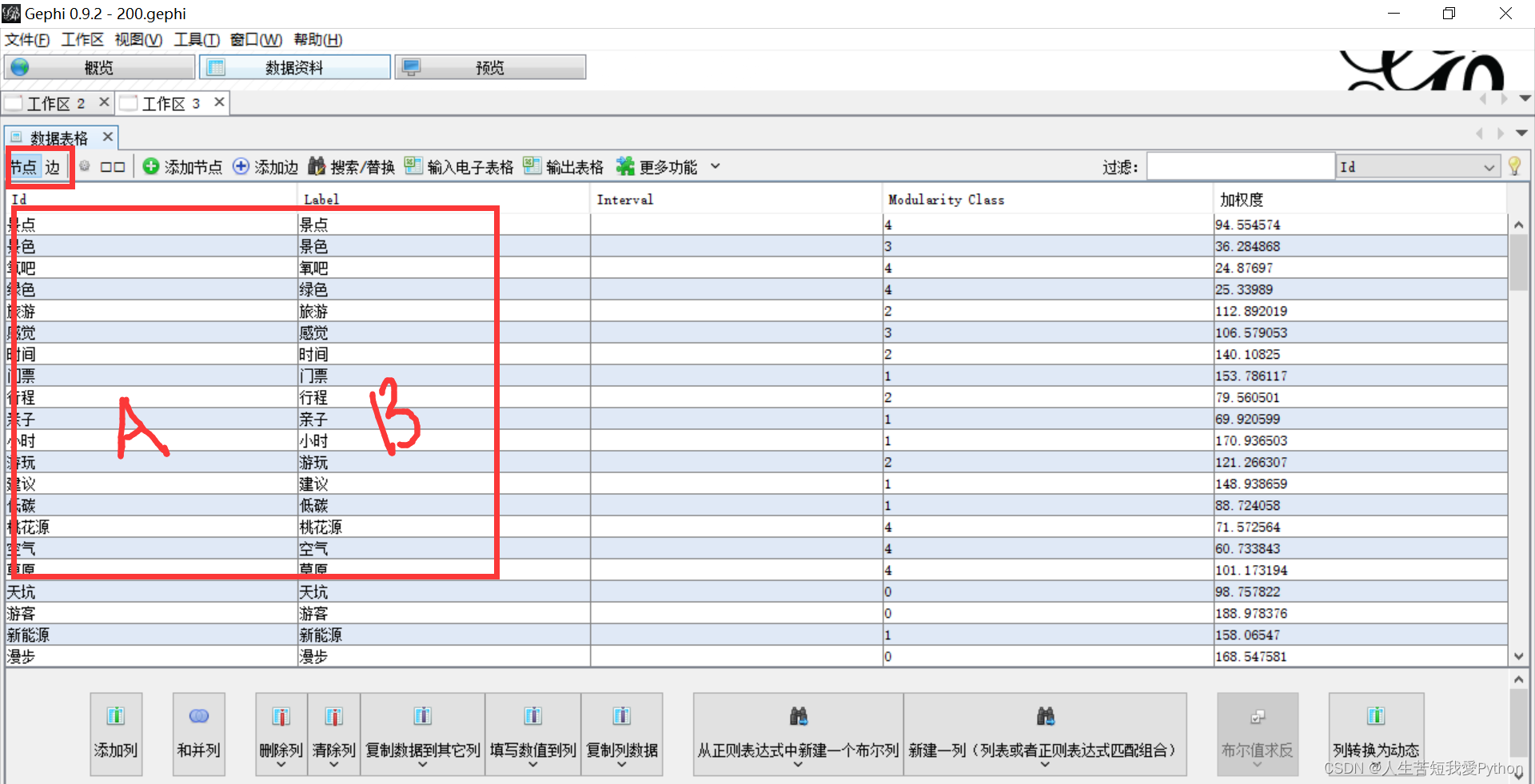
其次是边相关的数据信息,具有代表性的是有一个起点(源)和终点(目标),同时选用无向连接,也具有相关权重。
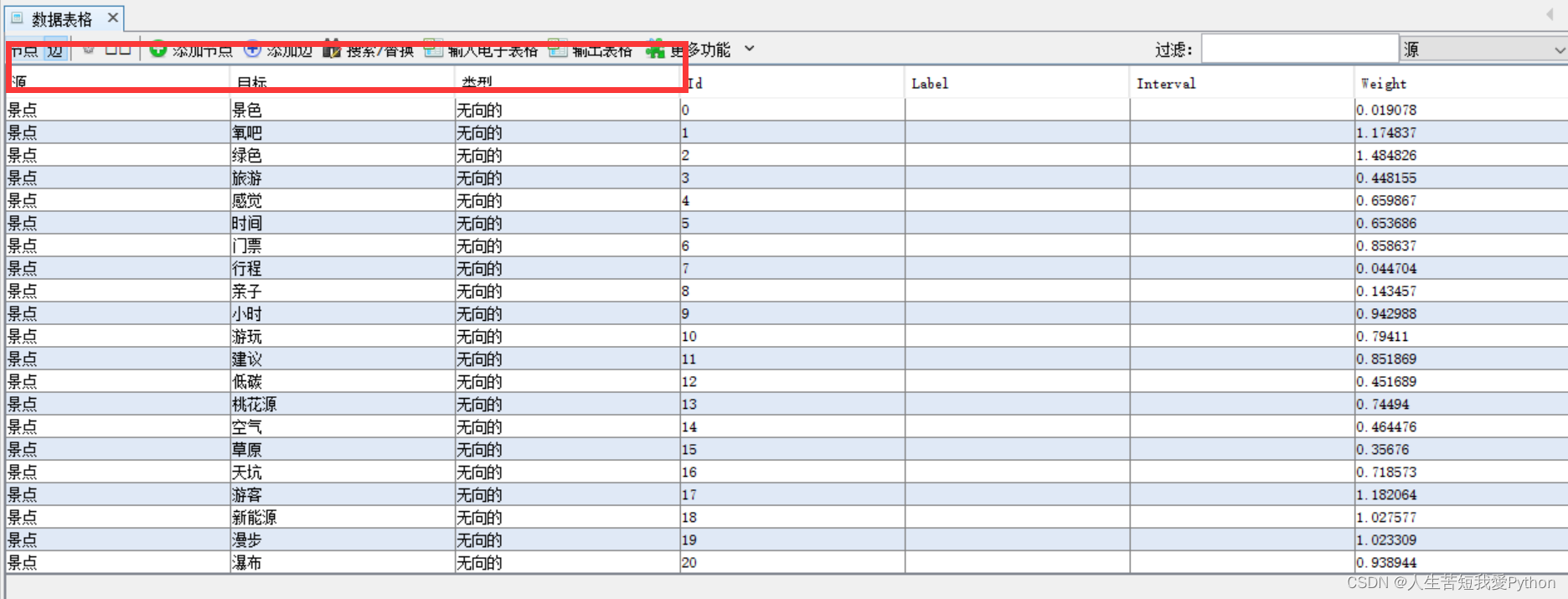
接下来需要把相关的两个表内数据复制粘贴到 Excel 文件中:
(另存为.csv文件)
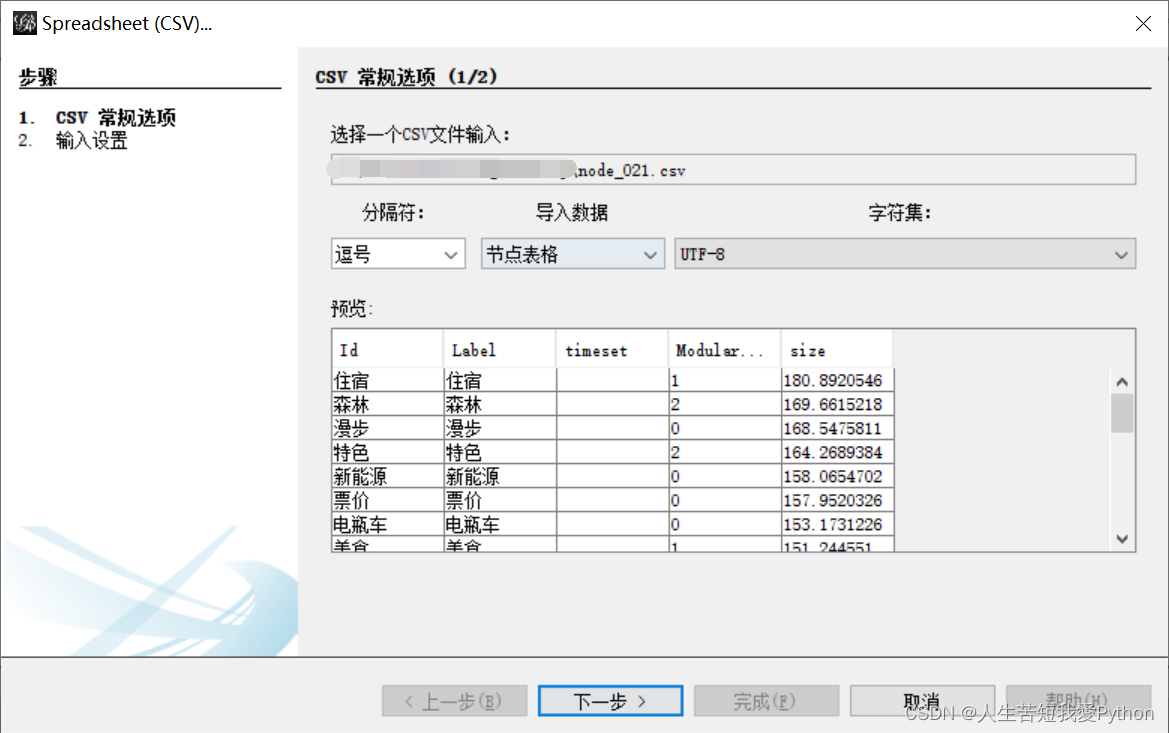
其中 node 文件可以直接拿来用:
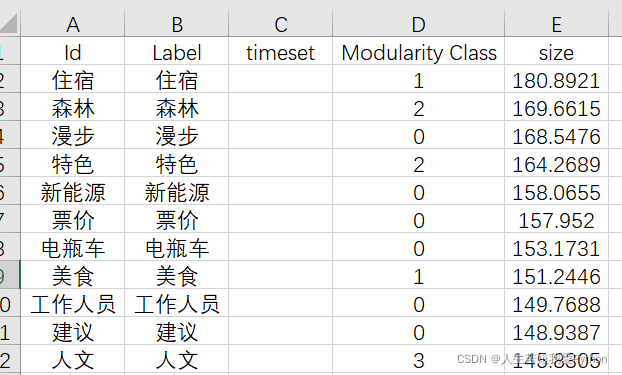
PS:其实在这里node文件也是经过修整的(不然还多搞这一步干嘛)主要是人工筛除一些对主题分析无关的词语,接着就可以将Node拿来用了(我这里是通过Python构建150词的共现矩阵,接着人工筛除至55词)
但是 edge 文件就需要大幅修改:
大幅修改的原因是将node文件进行了修整,但 edge 的边数数据依然没有变化,这将导致 边数>节点数 ,并且由于 edge 文件中 源和目标的数据不同,这将导致两次筛选
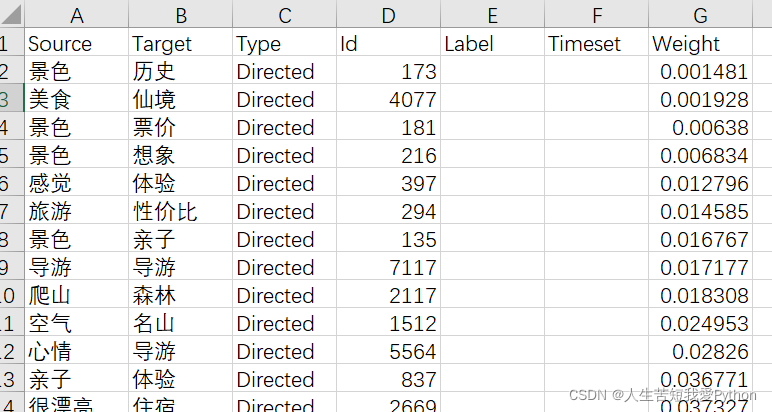
2、edge_csv 数据规整
传统对数据集进行点选筛除过于繁琐且容易出错,采用Excel的高级筛选功能进行解决:
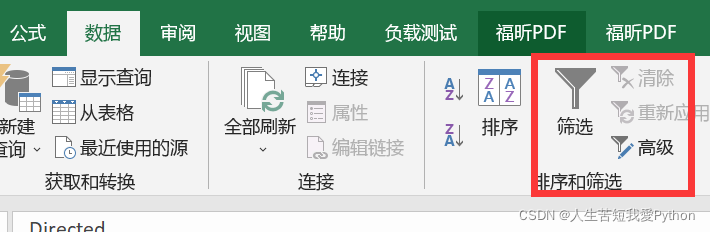
首先将作为参照的替换源和目标复制粘贴放在旁边:
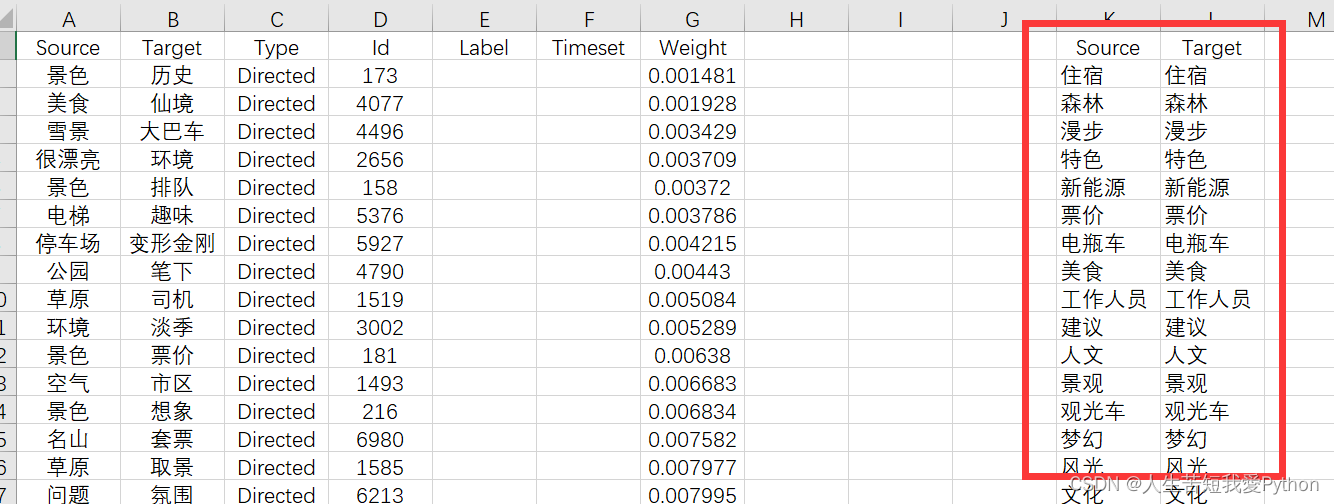
接着通过高级筛选功能将原edge数据进行第一次筛选:
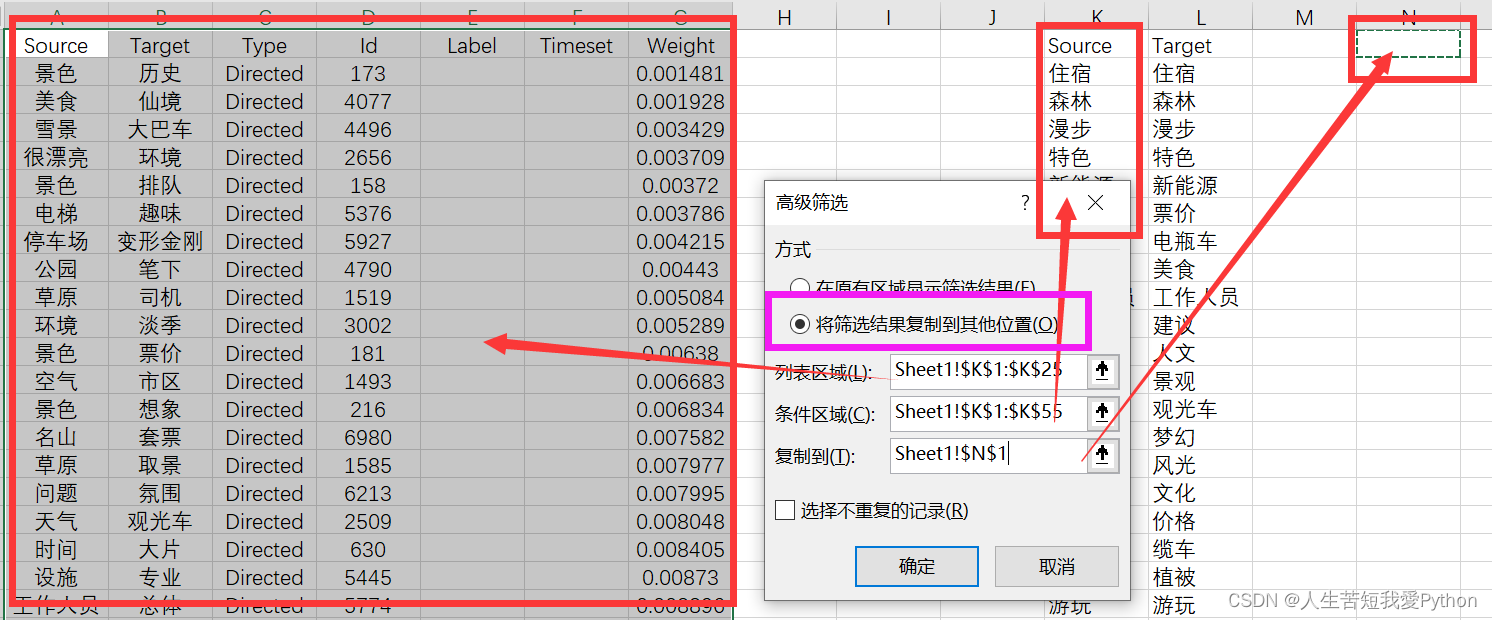
右侧绿色数据即是我们想要的数据,但绿色右侧的部分还需要进一次筛选,依然采用同样的方法进行。
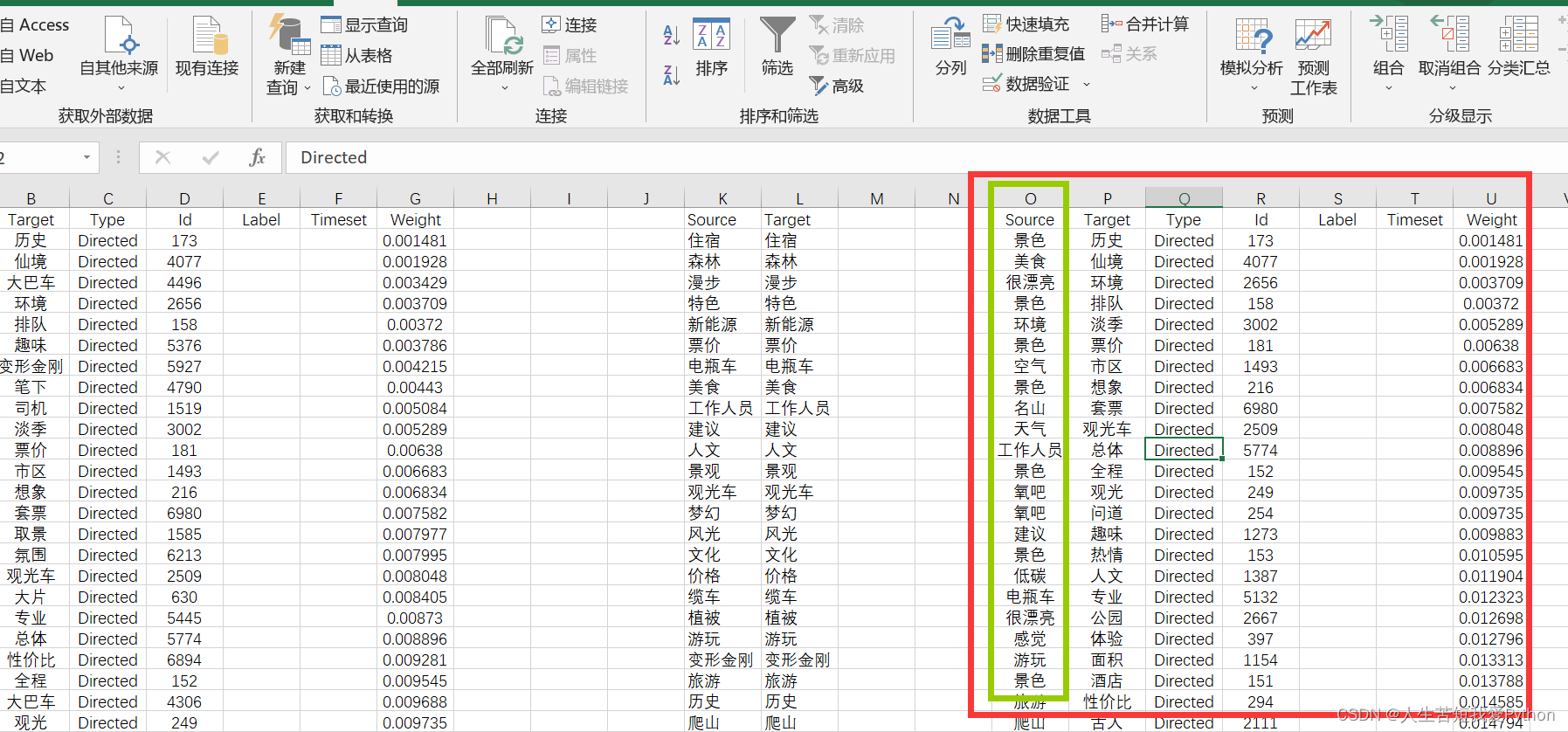
两次筛选过后,将最终内容放置到一个新的edge.csv里即可
于是我们就准备好了2个想要的数据。
3、打开Gephi导入数据
导入CSV文件,出现了乱码
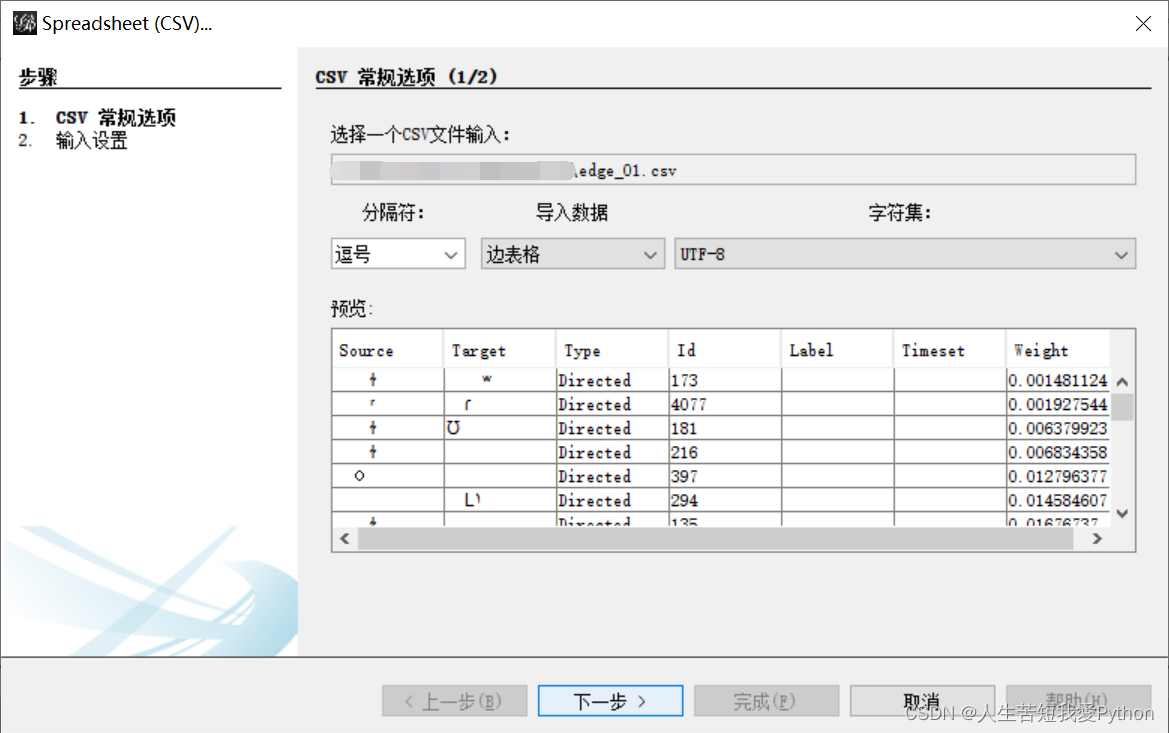
解决方案:
找到乱码CSV文件–用记事本打开–另存为UTF-8格式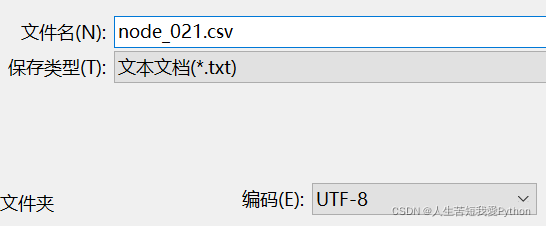
这时候再尝试导入即没有问题
点选无向图–新工作台
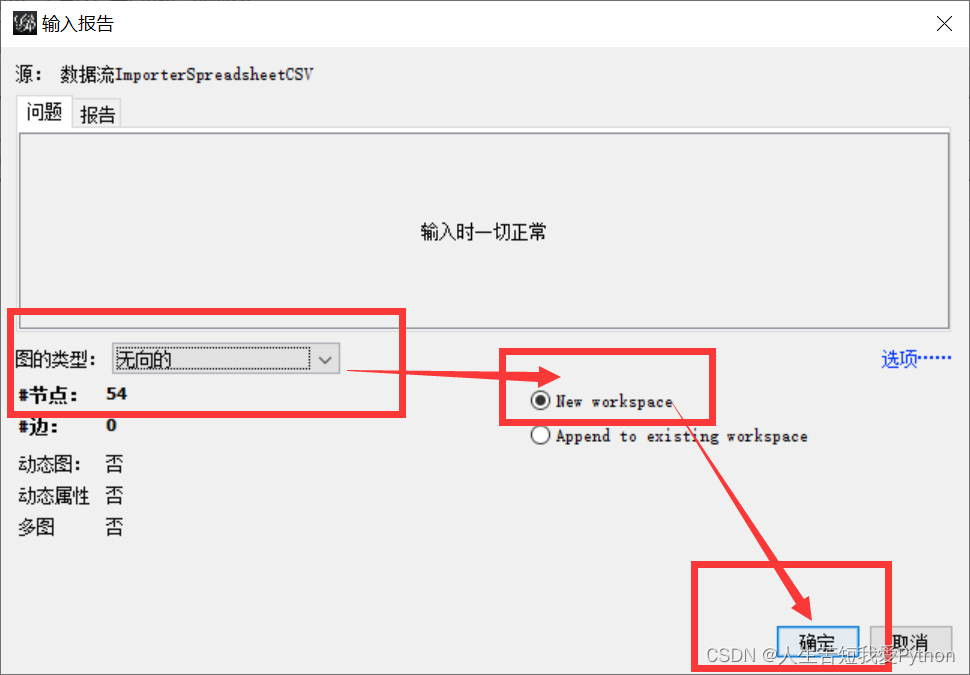
边文件也采取同样方案进行导入,唯一区别在于点选的是Append to existing workplace 选项。
4、图像调整
这个时候再点选概览,图像就简明很多了
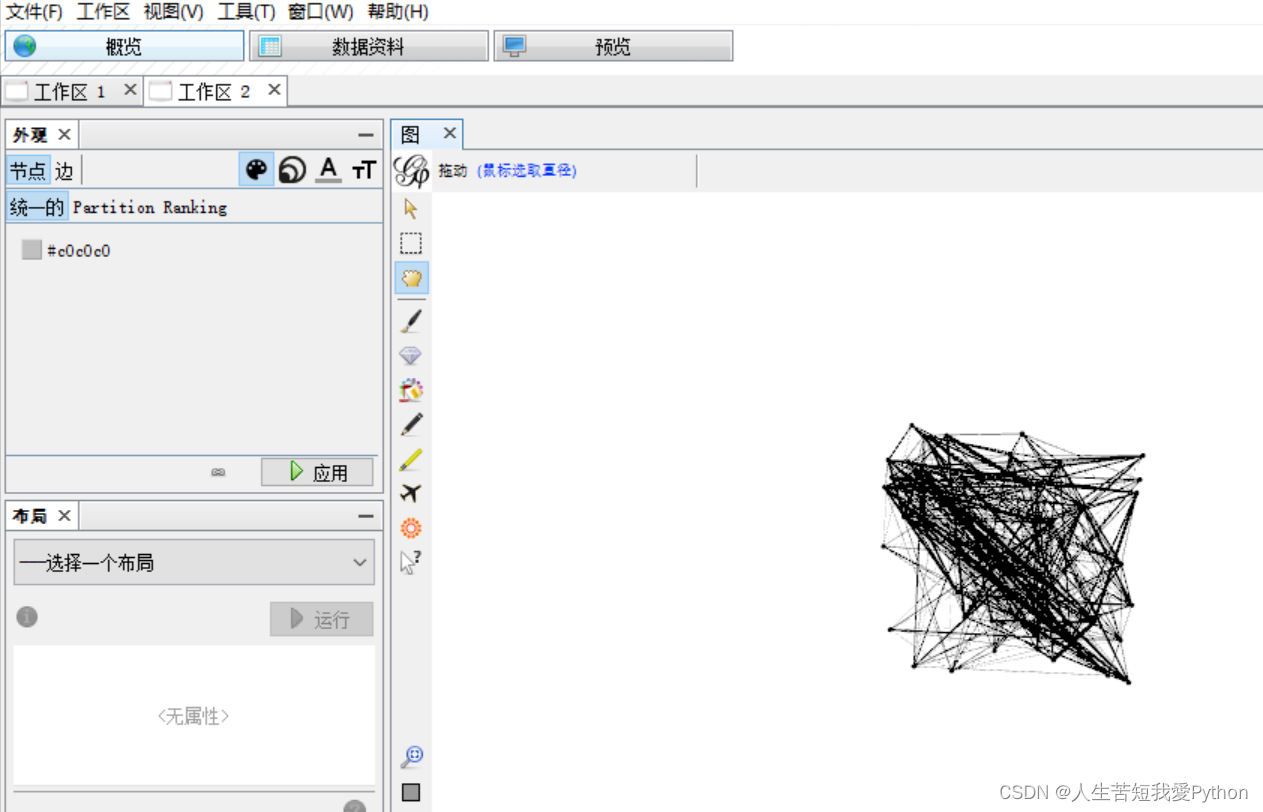
其他的调试基于1-2辑的数据,在这里不过多赘述,特别强调几个点:
由于自定义中可以自定义Size相关内容:
(这个size 可以通过pageranke得出)
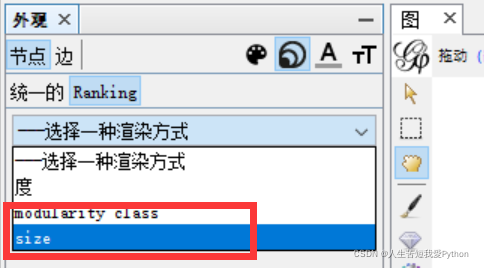 但是我调整多次Size没有任何变化,一怒之下将Size调整至200,效果就很明显了:
但是我调整多次Size没有任何变化,一怒之下将Size调整至200,效果就很明显了:

看来还是对Gephi太仁慈了(滚刀肉是吧? )

这个配色不错,偶然随便搞的,i了i了
接下来预览就出来了:
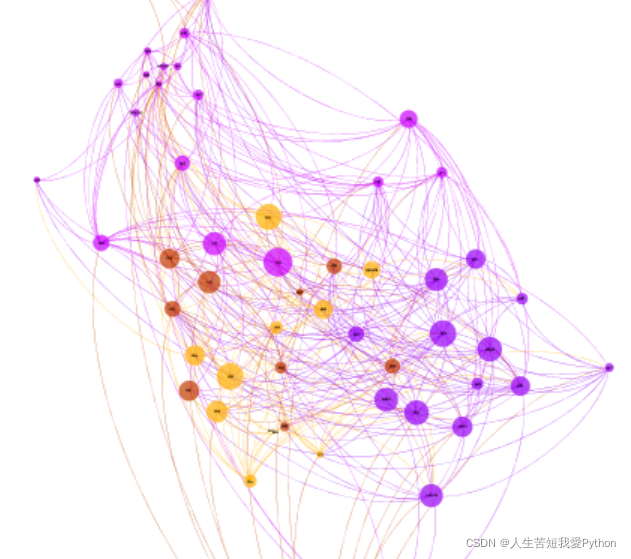
(线条还略显多,可以通过过滤–筛选功能去除部分)
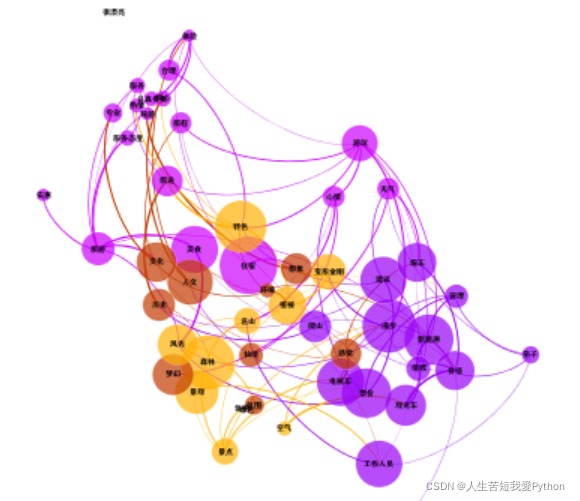
同时可以通过“厚度”选项调整变的粗细(4-7为宜)
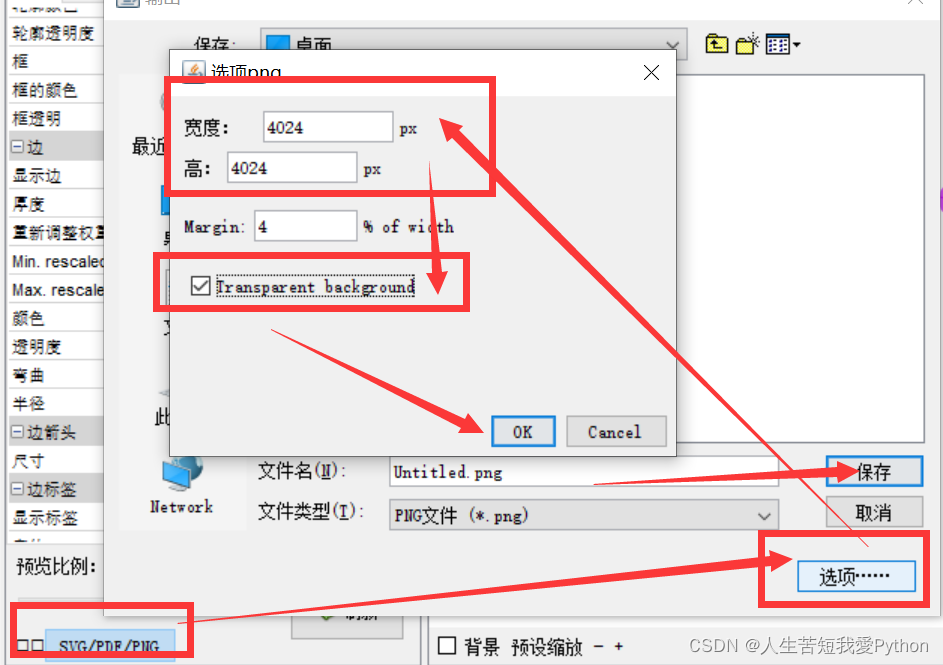
5、图像保存
将像素设置高些,清晰些:
总结
基本上就把Gephi玩耍了一遍,大概就是这些了
浅尝一下叭!



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











