






 镭速传输系统采用独有传输引擎技术,提供高速、稳定可靠的数据传输服务。支持多种操作系统和存储设施,具备良好的适应性和兼容性。通过内置的安全加密机制确保数据传输的安全性。
镭速传输系统采用独有传输引擎技术,提供高速、稳定可靠的数据传输服务。支持多种操作系统和存储设施,具备良好的适应性和兼容性。通过内置的安全加密机制确保数据传输的安全性。

企业选择传统的FTP、网盘等方式来传输大文件时,除了速度慢,常遇到传输内容错误、传输中断、重新续传等情况。因为传统FTP传输方式尽管支持文件夹批量传输,但当文件数量多,除了速度非常慢,还常出现漏传文件、文件内容错误、文件数目不一致等问题。
当文件容量增大,网络环境变差时,文件传输和数据交换效率低下,安全性差,如果文件更大时,通常会采用快递硬盘等更低下的方式,因而不能满足企业及时获取文件的要求,严重影响企业整体运行效率。
另外,利用上述传统传输手段过于分散,不利于企业的集中管理,在云计算时代,当前企业拥有的服务节点和存储节点越来越多,基于业务流程和混合云架构的数据流动需求也越来越多,而缺乏有效的文件传输管理平台,无疑是一大痛点。
对于具备独有的传输引擎技术的大文件传输软件而言,在诸多方面都具更强的优势:
1.更有效的拥塞判断及处理
2.更准确及时地进行丢包判断恢复
3.高速传输速度:大数据传递速度可提高100倍以上,单条连接速度可以支持1Gbps
4.更好的实时性传输体验:得益于镭速传输协议的多通道设计
5.传输性能与带宽成正比,与传输距离无关,丢包率影响甚微
6.以安全的方式实现用户及终端的认证
7.应用加密算法,适用于传输过程中加密及落地加密
8.防火墙&NAT设备友好性
9.容易集成
10.跨平台
传输软件的传输协议从设计原理上解决了现有TCP传输协议的核心问题,可以快速部署在已有的设备上,无需重度投资和重复投资,即可帮助企业和用户快速传输其数据,在数据海量增长爆发的时代里,必将发挥更大的作用。
镭速大文件传输系统,是一个可以让企业快速部署且易于管理的文件传输及文件管理系统。它能够提供高速传输、组织权限、安全管理等服务,完美替代传统FTP传输方式,一站式大文件传输解决方案帮助企业实现全球数据高效流转,期间带给你的绝对是超棒的使用体验。
镭速传输主要功能:
1、高性能传输
镭速传输基于云计算、互联网、大数据架构应用,拥有自主研发的Raysync Protocol高速传输协议,能够消除传输技术的底层瓶颈,克服传统网络限制,充分利用网络带宽,传输效率提升超百倍,轻松满足TB级别大文件和海量小文件极速传输需求。全程智能化加速传输,提供完美数据传输载体。
2、稳定可靠
全程采用断点续传、错误重传机制,同时内置多重文件校验机制,确保传输结果的完整性和准确性,确保超远程、弱网环境传输效率稳定可靠。
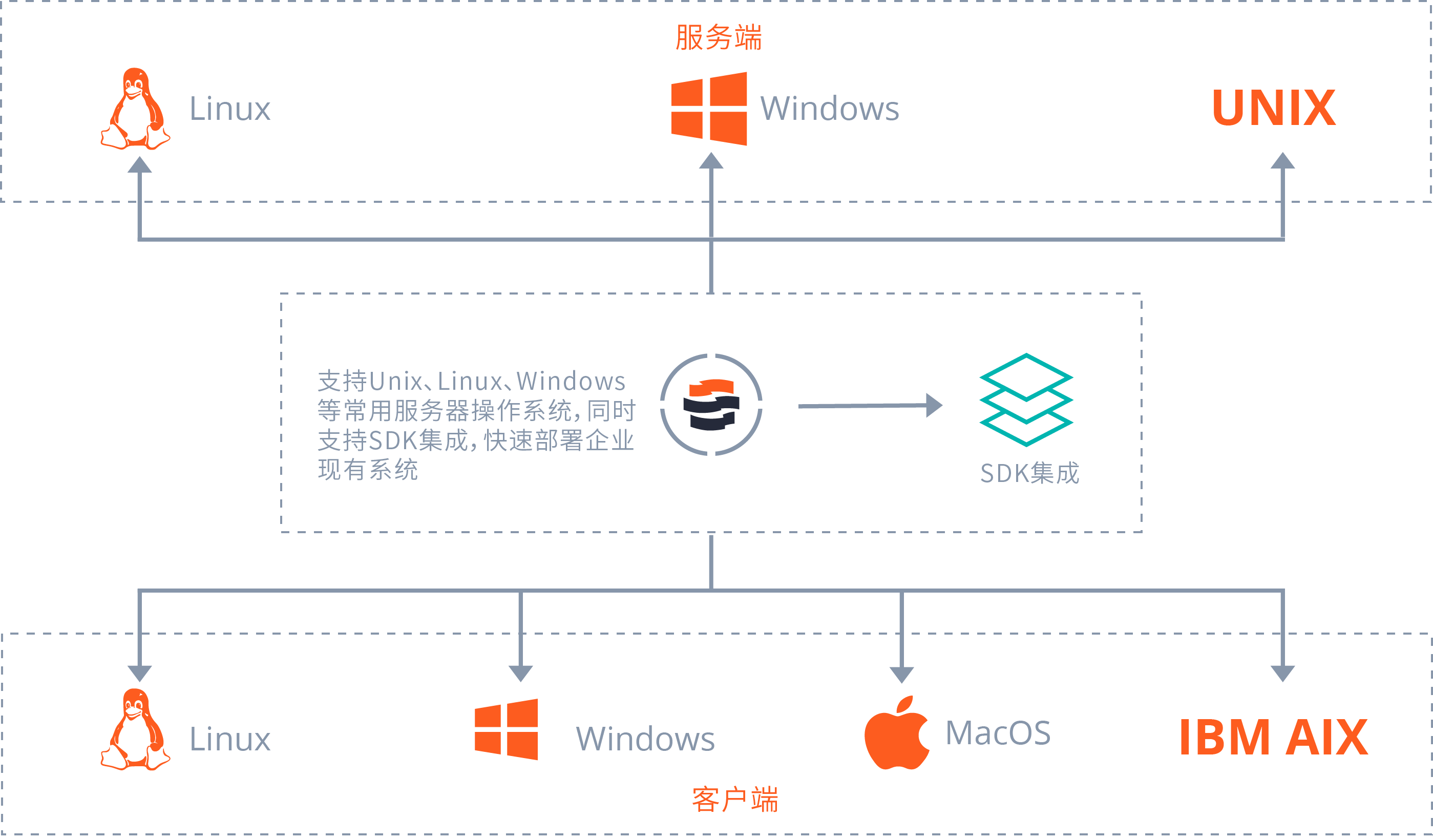
3、适应性和兼容性
支持Windows和Linux操作系统,支持各类存储设施,兼容常用浏览器,并支持私有部署和云服务模式。系统内置中英文界面,适应跨国业务需求。
4、传输安全 基于SSL加密传输协议,采用国际顶尖金融级别AES-256加密技术,内置CVE漏洞扫描,为数据信息增添多重防御墙,有效抵御外界攻击,保障传输过程的私密性,确保文件数据传输完整与安全。
5、全局中央控制 支持中央管理平台控制,实况监测在线传输、日志信息等精细化管控,支持企业多用户带宽控制,设置传输策略、速度等操作,实现企业核心业务数据可视、可控、可追溯。
6、快速部署 只需3步,快速完成安装,减少企业系统搭建成本,操作界面方便简洁,功能齐全,随时随地访问和管理文件数据。
7、技术支持 镭速传输全程提供技术支持服务,为用户在使用过程中遇到为问题进行排忧解答。


















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











