




 本文提出了一种结合结构化知识库(如Freebase)和非结构化资源(如Wikipedia)的问答方法。通过神经网络的关系提取器从Freebase检索候选答案,然后使用Wikipedia进行验证和答案细化。在WebQuestions数据集上的实验显示,这种方法在F1分数上实现了显著提升,解决了多约束问题和数据稀缺问题。
本文提出了一种结合结构化知识库(如Freebase)和非结构化资源(如Wikipedia)的问答方法。通过神经网络的关系提取器从Freebase检索候选答案,然后使用Wikipedia进行验证和答案细化。在WebQuestions数据集上的实验显示,这种方法在F1分数上实现了显著提升,解决了多约束问题和数据稀缺问题。
Abstract
现有的基于知识的问答系统通常依赖于少量带注释的培训数据。虽然浅层方法(如关系提取)对数据稀缺具有鲁棒性,但它们的表达能力不如深层意思表示方法(如语义解析),因此无法回答涉及多个约束的问题。在这里,我们通过使用来自维基百科的额外证据来授权关系提取方法来缓解这个问题。我们首先提出一个基于神经网络的关系提取器来从Freebase检索候选答案,然后通过Wikipedia进行推断来验证这些答案。在WebQuestions问答数据集上的实验表明,我们的方法实现了53.3%的F1,比最先进的方法有了实质性的改进。
1 Introduction
自从大型结构化知识库(KB)的出现,如Freebase(Bollacker等人,2008)、Y AGO(Suchanek等人,2007)和DBpedia(Auer等人,2007年),使用这些结构化知识库回答自然语言问题,也称为基于知识库的问题回答(或KB-QA),吸引了自然语言处理和信息检索社区越来越多的研究工作。
这项任务的最先进方法大致可分为两类。第一种是基于语义解析(Berant等人,2013;Kwiatkowski等人,2013),它通常学习能够将自然语言解析为复杂意义表示语言的语法。但是,这种复杂性需要大量包含合成结构的带注释的训练示例,对于Freebase等大型知识库来说,这几乎是不可能的解决方案。此外,语法预测结构和知识库结构之间的不匹配也是一个常见问题(Kwiatkowski等人,2013;Berant和Liang,2014;Reddy等人,2014)。
另一方面,信息提取方法不是构建正式的意义表示,而是使用关系提取(Yao和V an Durme,2014;Yih等人,2014;Yao,2015;Bast和Haussmann,2015)或分布式表示(Bordes等人,2014,Dong等人,2015)从知识库中检索一组候选答案。为这些方法设计大型训练数据集相对容易(Yao和V an Durme,2014;Bordes等人,2015;Serban等人,2016)。无论这些方法的正确性如何,它们通常都能很好地给出答案。然而,处理涉及多个实体和关系的组合问题仍然是一个挑战。考虑一下北美最高的山是什么。关系提取方法通常适用于北美的所有山脉,因为缺乏对最高数学函数的复杂表示。要选择正确的答案,必须检索山脉的所有高度,并按降序排序,然后选择第一个条目。我们提出了一种基于文本证据的方法,可以在不隐式求解数学函数的情况下回答这些问题。
像Freebase这样的知识库捕获了现实世界的事实,而像Wikipedia这样的网络资源提供了一个大型的句子库来验证或支持这些事实。例如,维基百科上的一句话说,德纳利(Denali)(也被称为麦金利山(Mount McKinley),其前官方名称)是北美最高的山峰,山顶海拔20310英尺(6190米)。要使用关系提取器回答针对知识库的示例问题,我们可以将此句子用作外部证据,过滤出错误答案并选择正确答案。
使用文本证据不仅缓解了关系提取中的表征问题,而且在一定程度上缓解了数据稀缺问题。考虑一下这个问题,谁是伊莎贝拉女王的母亲。回答这个问题需要预测隐藏在单词mother中的两个限制条件。一个限制是答案应该是伊莎贝拉的父母,另一个是答案的性别是女性。对于语义分析和关系提取来说,这种具有多重潜在约束的单词一直是一个难题,需要更多的训练数据(Wang et al.(2015)将这种现象称为亚词汇组合)。大多数系统都善于触发父约束,但在另一个系统上却失败了,即答案实体应该是女性。而维基百科的文本证据,……她的母亲是巴塞洛斯的伊莎贝拉……,可以作为进一步的约束来正确回答这个问题。
我们提出了一种新的基于结构化和非结构化资源的问答方法。我们的方法包括§2中概述的两个主要步骤。在第一步中,我们通过联合执行实体链接和关系提取(§3),使用结构化知识库(此处为Freebase)提取给定问题的答案。在下一步中,我们将使用非结构化资源(此处为Wikipedia)验证这些答案,以删除错误的答案并选择正确的答案(§4)。我们对基准数据集WebQuestions的评估结果表明,我们的方法优于现有的最先进模型。我们的实验设置和结果详见第5节。
2 Our Method
图1概述了我们对于“谁先为沙克踢球”这个问题的方法。我们有两个主要步骤:(1)对Freebase(KB-QA盒)进行推理;(2)进一步推断维基百科(答案提炼框)。让我们仔细看看步骤1。这里我们执行实体链接,以确定问题中的主题实体及其可能的Freebase实体。我们使用关系提取器来预测问题实体和答案实体之间可能存在的潜在Freebase关系。稍后,我们对实体链接和关系提取结果执行联合推理步骤,以找到最佳实体关系配置,从而生成候选答案实体列表。在步骤2中,我们通过应用一个答案细化模型来细化这些候选答案,该模型将主题实体的Wikipedia页面考虑在内,以过滤出错误的答案并选择正确的答案。
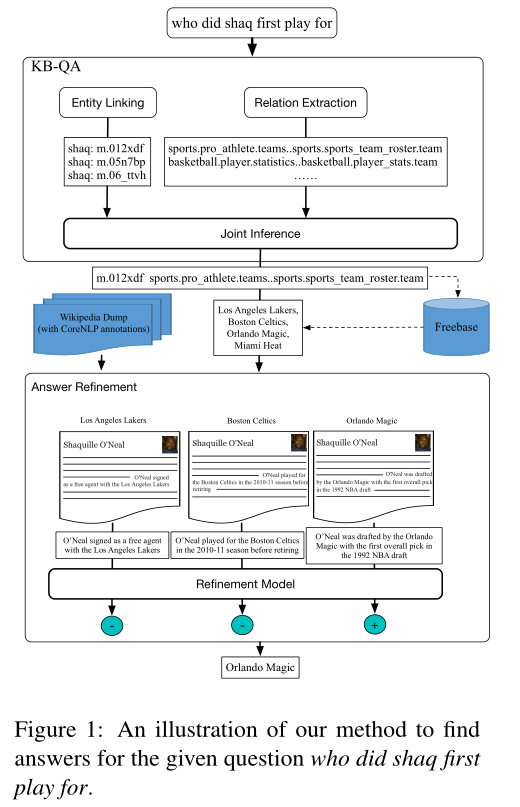
虽然图1中的概述适用于包含单个Freebase关系的问题,但也适用于涉及多个Freebases关系的问题。考虑一下在《星球大战1》中谁扮演阿纳金·天行者的问题。回答这个问题的演员应该满足以下限制条件:(1)演员扮演阿纳金·天行者;(2)《星球大战》中扮演的演员1。受Bao等人(2014)的启发,我们设计了一种基于依赖树的方法来处理此类多关系问题。我们首先使用附录中列出的句法模式将原始问题分解为一组子问题。原始问题的最终答案集是通过将其所有子问题的答案集相交得到的。对于示例问题,子问题是谁扮演阿纳金·天行者,谁在星球大战1中扮演。这些子问题通过Freebase和Wikipedia分别回答,他们对这些子问题的回答的交集被视为最终答案。
3 Inference on Freebase
给定一个子问题,我们假设表示答案的疑问词r与问题中的实体e有明显的KB关系,并预测单个KB三元组(e,r,?)对于每个子问题(这里?代表答案实体)。因此,QA问题被表述为一个信息提取问题,涉及两个子任务,即实体链接和关系提取。我们首先介绍这两个组件,然后介绍一个联合推理过程,它可以进一步提高整体性能。
3.1 Entity Linking
对于每个问题,我们使用人工构建的词类序列来确定所有可能的命名实体提及范围,例如序列NN(shaq)可能表示一个实体。对于每个提及范围,我们使用实体链接工具S-MART(Yang and Chang,2015)从Freebase检索前5个实体。这些实体被视为候选实体,最终将在联合推断步骤中消除歧义。对于给定的提及范围,S-MART首先通过曲面匹配检索Freebase的所有可能实体,然后使用统计模型对其进行排序,该模型根据实体出现曲面的频率计数进行训练。
3.2 Relation Extraction
我们现在开始确定答案和问题中的实体之间的关系。受最近神经网络模型在知识库问答中取得的成功(Yih等人,2015;Dong等人,2015)以及句法依赖关系提取的成功(Liu等人,2015年;Xu等人,2005年)的启发,我们提出了一种多通道卷积神经网络(MCCNN),它可以利用句法和句子信息进行关系提取。
3.2.1 MCCNNs for Relation Classification
在MCCNN中,我们使用两个通道,一个用于句法信息,另一个用于句子信息。网络结构如图2所示。卷积层处理不同长度的输入,为每个信道返回固定长度的向量(我们使用最大池)。将这些固定长度向量串联,然后送入softmax分类器,其输出维数等于预定义关系类型的数量。每个维度的值表示对应关系的置信度得分。
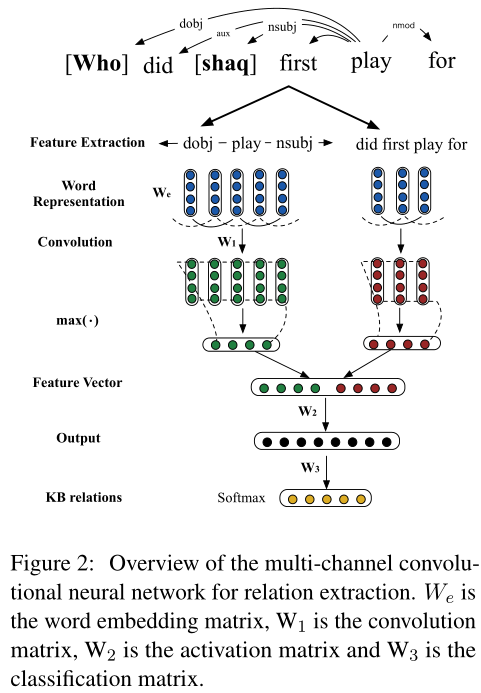
Syntactic Features 我们使用依赖树中实体提及和问题词之间的最短路径作为第一个通道的输入。与Xu et al.(2015)类似,我们将路径视为词向量、依赖边缘方向和依赖标签的串联,并将其馈送到卷积层。注意,实体提及和疑问词被排除在依赖路径之外,以便在句法层面学习更一般的关系表示。如图2所示,who和shaq之间的依赖路径是← dobj–play–nsubj→.
Sentential Features 这个频道将句子中的单词作为输入,不包括疑问词和所提及的实体。如图2所示,did、first、play和for的向量被输入这个通道。
3.2.2 Objective Function and Learning
该模型是通过训练数据中的成对问题及其对应的黄金关系来学习的。给定一个带有注释实体的输入问题x,网络输出一个向量o(x),其中条目ok(x)是实体和预期答案之间存在第k个关系的概率。我们表示t(x)∈ RK×1作为目标分布向量,其中gold关系的值设置为1,其他值设置为0。我们计算t(x)和o(x)之间的交叉熵误差,并进一步将训练数据的目标函数定义为:
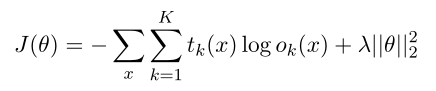
其中θ表示权重,λ表示L2正则化参数。通过网络结构的反向传播,可以有效地计算权重θ。为了最小化J(θ),我们对AdaGrad应用随机梯度下降(SGD)(Duchi et al.,2011)。
3.3 Joint Entity Linking & Relation Extraction
实体链接和关系提取的管道可能会受到错误传播的影响。正如我们所知,实体和关系具有强烈的选择偏好,某些实体不会与某些关系一起出现,反之亦然。本地优化的模型无法利用这些隐含的双向首选项。因此,我们使用联合模型从局部预测中找到全局最优的实体关系分配。背后的关键思想是利用两个本地模型和知识库中的各种线索,将正确的实体关系赋值排名高于其他组合。我们在下面描述学习过程和特点。
3.3.1 Learning
假设这对(egold,rgold)代表问题q的黄金实体/关系对。我们对q进行所有实体和关系预测,从q创建实体和关系对{(e0,r0),(e1,r1),…,(en,rn)}的列表,并使用SVM秩分类器对其进行排序(Joachims,2006),该分类器经过训练,可以预测每对的秩。理想情况下,较高的等级表明预测更接近黄金预测。对于训练,SVM秩分类器需要一个排序或评分的实体关系对列表作为输入。我们创建包含排序输入对的训练数据,如下所示:如果epred=egold和rpred=rgold都是,则我们给它赋值3分。如果只有实体或关系等于gold(即epred=ecold,rpred 6=rgold或epred 6=egold,prred=rgld),则我们为它赋值2分(鼓励部分重叠)。当实体和关系赋值都错误时,我们给1分。
3.3.2 Features
对于给定的实体-关系对,我们提取以下特征作为输入向量传递给上面的SVM等级:
Entity Clues.我们使用实体链接系统返回的预测实体的分数作为特征。实体提及和实体的Freebase名称之间的字数重叠也是一个特征。在Freebase中,大多数实体都有描述实体的关系fb:description。例如,在运行的示例中,shaq与三个潜在实体m.06 ttvh(shaq Vs.Television Show)、m.05n7bp(shaq Fu视频游戏)和m.012xdf(Shaquille O'Neal)相关联。有趣的是,play这个词只出现在沙奎尔·奥尼尔的描述中,而且出现了三次。我们计算给定问题和实体描述之间的内容词重叠,并将其作为一个特征。
Relation Clues. MCCNN返回的关系分数用作特征。此外,我们将每个关系视为一个文档,其中包含表达这种关系的培训问题。对于给定的问题,我们使用其单词的tf-idf分数之和作为特征。Freebase关系r是一系列片段r=r1.r2.r3的串联。例如,people.person的三个片段。父母是人、人和父母。前两个片段表示这个关系的主题的Freebase类型,第三个片段表示对象类型,在我们的例子中是答案类型。我们使用一个指示符特征来表示第三个片段(这里是父片段)的表面形式是否出现在问题中。
Answer Clues. 以上两个要素类表示本地要素。从实体关系(e,r)对,我们创建查询三元组(e,r,?)检索答案,并进一步从答案中提取特征。这些特性是非本地的,因为我们需要e和r来检索答案。其中一个特征是,基于疑问词通常表示答案类型的直觉,使用答案类型和疑问词的同时出现,例如,疑问词通常指示答案类型。日期时间。另一个特性是检索到的应答实体的数量。
4 Inference on Wikipedia
我们使用上面步骤中排名最好的实体关系对从Freebase检索候选答案。在这一步中,我们使用维基百科作为我们的非结构化知识资源来验证这些答案,其中的大多数语句都由多个人验证其真实性。
我们的求精模型受到人们如何求精答案的直觉启发。如果你问某人:沙克首先为谁踢球,并给他们四个候选答案(洛杉矶湖人队、波士顿凯尔特人队、奥兰多魔术队和迈阿密热火队),以及访问维基百科,此人可能会首先确定问题是关于沙奎尔·奥尼尔的,然后转到奥尼尔的维基页面,搜索包含候选答案的句子作为证据。通过分析这些句子,人们可以判断一个候选答案是否正确。
4.1 Finding Evidence from Wikipedia
如上所述,我们应该首先找到与给定问题中的主题实体相对应的Wikipedia页面。我们使用FreebaseAPI将Freebase实体转换为Wikipedia页面。我们从Wikipedia页面中提取内容,并使用Wikifier(Cheng and Roth,2013)对其进行处理,Wikifiers识别Wikipedian实体,可以使用Freebase API将其进一步链接到Freebases实体。此外,我们使用Stanford CoreNLP(Manning et al.,2014)进行标记化和实体共同参考解析。我们搜索包含从Freebase检索到的候选答案实体的句子。例如,奥尼尔的维基百科页面包含一句话“奥尼尔是由奥兰多魔术队起草的,在1992年NBA选秀中获得了第一个总冠军”,这一句话被细化模型(我们在维基百科》上的推理模型)考虑,以区分奥兰多魔法队是否是给定问题的答案。
4.2 Refinement Model
我们将细化过程视为对候选答案的二元分类任务,即正确(肯定)和错误(否定)答案。我们为细化模型准备的训练数据如下。在训练数据集上,我们首先推断Freebase以检索候选答案。然后,我们使用这些问题的注释黄金答案和维基百科来创建培训数据。具体来说,我们将包含正确/错误答案的句子视为精化模型的积极/消极示例。我们使用LIBSVM(Chang and Lin,2011)学习分类权重。
注意,在主题实体的维基百科页面中,我们可能会收集多个包含候选答案的句子。然而,并非所有句子都是相关的,因此,如果至少有一个肯定的证据,我们认为候选人的答案是正确的。另一方面,有时我们可能找不到任何证据来证明候选人的答案。在这些情况下,我们回到基于知识库的方法的结果。
4.3 Lexical Features
关于LIBSVM中使用的特征,我们使用以下从问题和维基百科句子中提取的词汇特征。形式上,给定问题q=<q1,…qn>和证据句s=<s1,…sm>,我们分别用qi和sj表示q和s的标记。对于每对(q,s),我们确定一组所有可能的令牌对(qi,sj),其出现次数用作特征。随着学习的进行,我们希望学习像(初稿)这样的功能的更高权重和(初稿,播放)的更低权重。
5 Experiments
在这一部分中,我们介绍了实验装置、主要结果和对系统的详细分析。
5.1 Training and Evaluation Data
我们使用WebQuestions(Berant et al.,2013)数据集,其中包含通过Google Suggest服务搜索的5810个问题,答案标注在Amazon Mechanical Turk上。这些问题分为训练和测试集,分别包含3778个问题(65%)和2032个问题(35%)。我们进一步将培训问题分成80%\/20%进行开发。
为了训练MCCNN和联合推理模型,我们需要问题的金标准关系。由于该数据集仅包含问答对和带注释的主题实体,因此我们不依赖黄金关系,而是依赖于产生与黄金答案重叠度最高的答案的替代黄金关系。具体来说,对于给定的问题,我们首先在Freebase图中找到主题实体e,然后选择连接到主题实体的1跳和2跳关系作为候选关系。2跳关系是指Freebase的n元关系,即第一跳从主题跳到中介节点,第二跳从中介节点跳到目标节点。对于每个关系候选r,我们发出查询(e,r,?)并将生成答案的关系标记为替代黄金关系,该关系相对于黄金答案具有最小的F1损失。从训练集中,我们收集了461个关系来训练MCCNN,测试期间的目标预测超过了这些关系。
5.2 Experimental Settings
基于Bao等人(2014),我们有6个依赖树模式,将问题分解为子问题(见附录)。我们使用Turian et al.(2010)的单词表示初始化单词嵌入,维度设置为50。我们模型中的超参数使用开发集进行调整。MCCNN的窗口大小设置为3。两个MCCNN频道的隐藏层1和隐藏层2的大小分别设置为200和100。我们使用Berant et al.(2013)的Freebase版本,其中包含4M实体和5323个关系。
5.3 Results and Discussion
我们使用平均问题F1作为评估指标。为了了解我们方法的不同配置的影响,我们将以下方法与现有方法进行了比较。
Structured.此方法仅涉及对Freebase的推理。首先运行实体链接(EL)系统来预测主题实体。然后,我们运行关系提取(RE)系统,并选择与主题实体可能发生的最佳关系。我们选择这个实体-关系对来预测答案。

















 3330
3330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









