




 本文深入探讨了Java中集合类的使用,包括Array与ArrayList的转化、在list的循环中修改list元素的方法、HashMap与相关集合的区别、异常处理、Collection集合的排序策略以及Java核心概念的理解与应用。
本文深入探讨了Java中集合类的使用,包括Array与ArrayList的转化、在list的循环中修改list元素的方法、HashMap与相关集合的区别、异常处理、Collection集合的排序策略以及Java核心概念的理解与应用。
1、Array 与 ArrayList的转化
通常情况下,数组转list,我们会用这样的方式去转换。
List<String> list = Arrays.asList(arr);最终会得到一个ArrayList,但是这不是一个java.util.ArrayList的类对象,而是java.util.Arrays.ArrayList内部类对象,而它只有get、set、contains方法。也就是说只可以读不能修改,并且大小固定。这样当你再想去修改这个list的时候就会悲剧了。。。
ArrayList如果是转成Integer[ ],那用ArrayList.toArray()没有问题,转成int[ ]就不行了,这个建议使用
int[] array = ArrayUtils.toPrimitive(list.toArray(new Integer[0])),Apache Commons中的工具包。
2、在list的循环中修改list的元素
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c", "d"));
for (int i = 0; i < list.size(); i++) {
list.remove(i);
}
System.out.println(list);输出的结果时[b,d],因为在循环的过程中修改list,index也会变化,导致最终的结果出乎意料。
你可能想使用for each循环来修改,能够解决问题。看看下面这块代码:
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c", "d"));
for (String s : list) {
if (s.equals("a"))
list.remove(s);
}会抛出ConcurrentModificationException这样的异常。其实for-each的底层实现用的就是iterator,所以改用iterator还是有可能报这个异常,只是可能。因为如下做法才是正确的:
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c", "d"));
Iterator<String> iter = list.iterator();
while (iter.hasNext()) {
String s = iter.next();
if (s.equals("a")) {
iter.remove();
}
}其中next的方法必须在remove之前调用,而for-each的实现中next方法在remove之后调用了,所以报错,可以查看ArrayList.iterator().源码便一目了然。
3、HashMap vs. TreeMap vs. HashTable vs. LinkedHashMap
HashMap:哈希结构存储,按key取值比较快
TreeMap :增加了按key排序的功能
HashTable:是同步安全的保证,但是因此也会损害一部分性能
LinkedHashMap:对于冲突的键值对链式存储,可以保证按照插入的顺序保存
4、泛型与类型擦除
public class Main {
public static void main(String[] args) throws IOException {
ArrayList<String> al = new ArrayList<String>();
al.add("a");
al.add("b");
accept(al);
}
public static void accept(ArrayList<Object> al){
for(Object o: al)
System.out.println(o);
}
}上面的代码编译就报错了,因为ArrayList<Object> al并不能用于ArrayList<String> al参数,前者并不是后者的父类型,如果换成数组就没问题了。究其原因,泛型是基于编译时的,运行时泛型信息会被擦除。上面的代码在编译时,判断泛型不匹配,所以报错。
public static void main(String args[]) {
ArrayList<Object> al = new ArrayList<Object>();
al.add("abc");
test(al);
}
public static void test(ArrayList<?> al){
for(Object e: al){
System.out.println(e);
}
}如果确实需要List可以放入任何参数,就应该将其定义为?,这样就可以放入任意类型了。? extends和 ? super也是一样的道理。
5、异常
异常的继承体系如下所示:
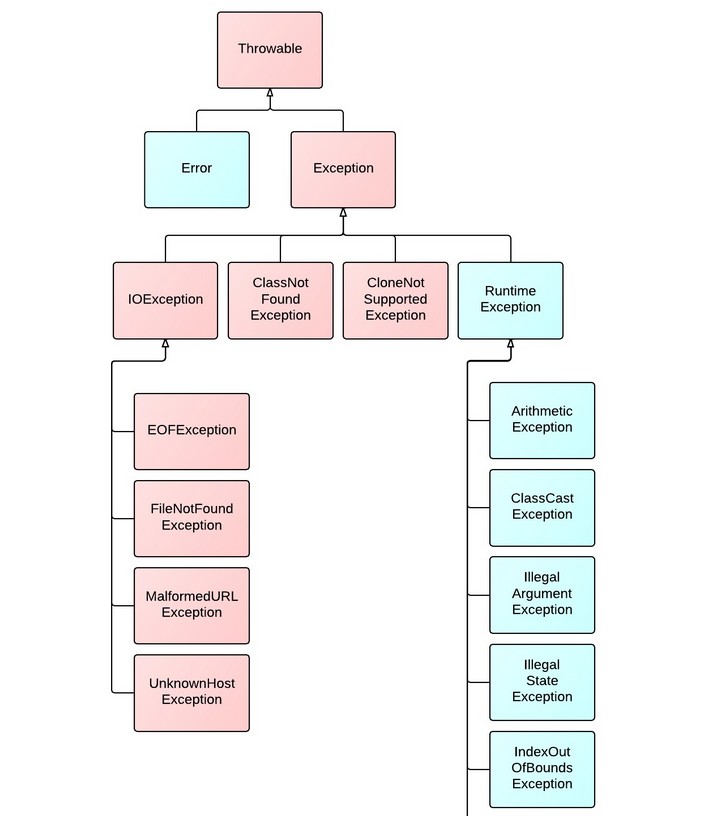
最佳实践:如果一个异常能够被很好地控制住,它就应该被catch,否则就应该throws来告知使用者。
Checked与Unchecked exceptions :简单来说Checked要么被catch,要么被声明throws,是必须处理的异常,而Unchecked是由一些严重的系统问题导致的,没有办法解决的,比如被0除等。
6、Collection的排序:
TreeSet的排序,默认的无参构造函数或者参数为Collection<? extends E> 得到的set,其中的元素必须实现Comparable接口,从而实现按compareTo方法排序,而TreeSet(Comparator<? super E> comparator)理所当然地按传入的comparator的compare方法排序。同时Collections.sort()排序也是一样,对传入的list按comparator的实现来排序。
Comparable与comparator的区别:Comparable是一个对象本身就已经支持自比较所需要实现的接口(如String Integer自己就可以完成比较大小操作); 而Comparator是一个专用的比较器,当这个对象不支持自比较或者自比较函数不能满足你的要求时,你可以写一个比较器来完成两个对象之间大小的比较。Comparator的使用更加灵活。
Collections.sort()与TreeSet排序差别:Collections.sort()是稳定的、一次性的排序,并且可以随机地取list中的任何元素,而TreeSet的排序是不稳定的并且排序只能获取其第一个或最后一个元素。
当然TreeMap的排序是按照其中的key来排序,而key又是按照自己实现的排序接口来完成,就不多说了。
7、通过六张图来理解java
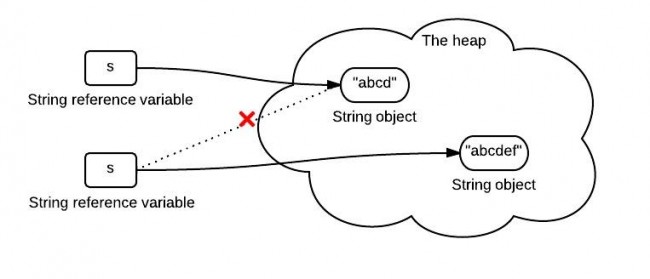
1>String的不可变性
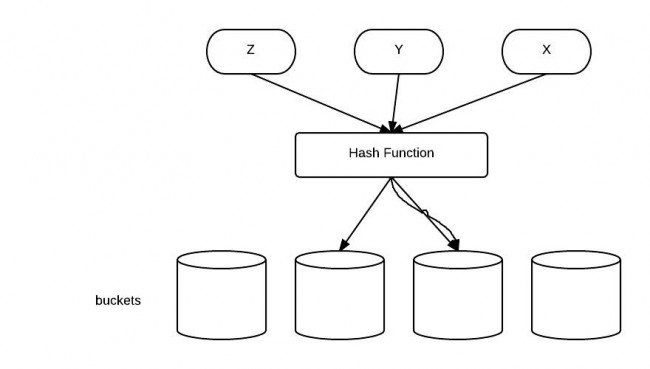
2> java中hashcode的实现
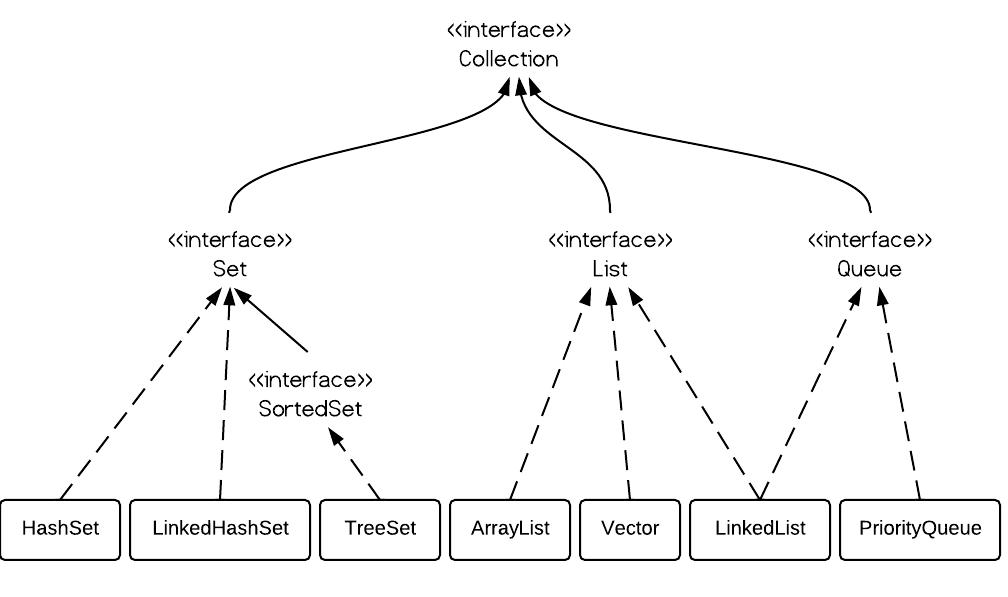
3> Collection集合的结构
4> java中的同步
具体细节请参阅:http://rainforc.iteye.com/admin/blogs/2039501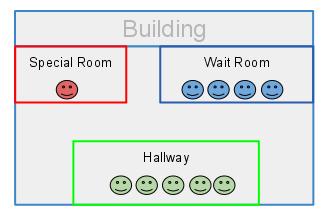
5> java中的堆与栈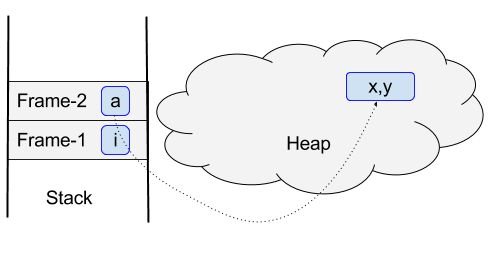
6> jvm运行时数据区的结构
具体细节请参阅:http://rainforc.iteye.com/admin/blogs/2015693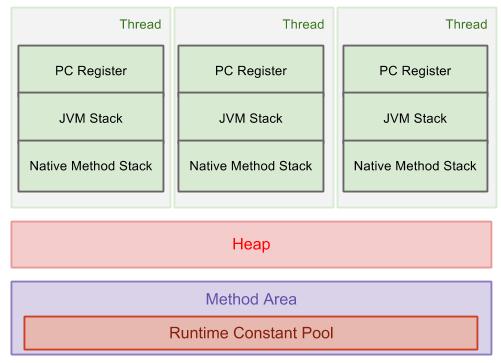
以上每张图具体去解释,可以延伸到很多东西,全部弄懂就能使java融会贯通。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









