




一 k8s网络通信
1.1 k8s通信整体架构
-
k8s 通过 CNI(容器网络接口)接入第三方插件实现网络通讯,主流插件有 flannel、calico 等(CNI 是标准化接口,插件负责具体网络实现)。
-
CNI 插件存放位置:
# cat /etc/cni/net.d/10-flannel.conflist- 解释:该命令用于查看当前节点使用的 CNI 插件配置文件,10-flannel.conflist 是 flannel 插件的配置清单。
-
插件常用解决方案:
- 虚拟网桥:多个容器通过虚拟网桥共享虚拟网卡通信(类似局域网内交换机转发)。
- 多路复用(MacVLAN):多个容器共享物理网卡,通过不同 MAC 地址区分(类似物理网卡分多个虚拟接口)。
- 硬件交换(SR-IOV):物理网卡虚拟出多个独立接口,性能最优(直接绕过内核,接近物理机性能)。
-
容器间通信:
- 同一 Pod 内多容器:通过 lo(本地回环)通信(Pod 内容器共享网络命名空间)。
- 同一节点 Pod:通过 CNI 网桥(如 flannel 的 cni0)转发数据包(类似同一交换机下的设备通信)。
- 不同节点 Pod:依赖网络插件实现跨节点路由(如 flannel 的 VXLAN 隧道、calico 的 BGP 路由)。
-
Pod 和 Service 通信:通过 iptables 或 ipvs 实现(Service 是 Pod 的固定访问入口,iptables/ipvs 负责负载均衡和地址转换)。
- 注意:ipvs 仅负责负载均衡,NAT 转换仍需 iptables,因此两者常配合使用。
-
Pod 和外网通信:通过 iptables 的 MASQUERADE(地址伪装),将 Pod 的私有 IP 转换为节点的公网 IP 后访问外网。
-
Service 与集群外部通信:通过 ingress(七层路由)、nodeport(节点端口映射)、loadbalancer(云厂商负载均衡)实现。
1.2 flannel网络插件
插件组成:
| 插件 | 功能 |
|---|---|
| VXLAN | 即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VXLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出覆盖网络(Overlay Network) |
| VTEP | VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因 |
| Cni0 | 网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡) |
| Flannel.1 | TUN设备(虚拟网卡),用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端 |
| Flanneld | flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息 |
1.2.1 flannel跨主机通信原理
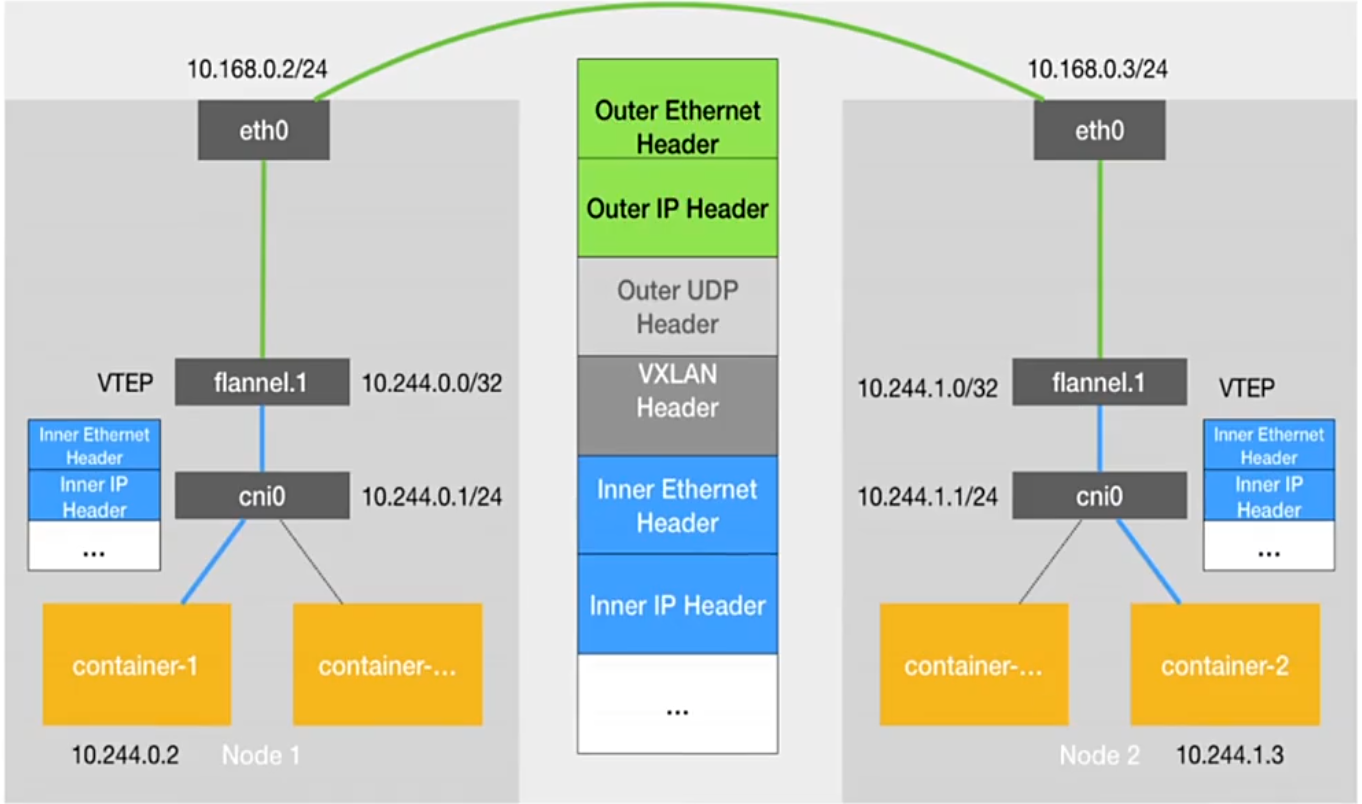
- 容器发送 IP 包:通过 veth pair 发送到 cni0 网桥(Pod 内的 eth0 与 cni0 的虚拟端口直连)。
- 路由到 flannel.1:cni0 根据节点路由表,将数据包转发到本机的 flannel.1 设备。
- 封装内部数据帧:flannel.1 给原始 IP 包添加目的 VTEP 的 MAC 地址,封装成内部数据帧(标识目标节点的 flannel.1 设备)。
- VXLAN 封装:Linux 内核给内部数据帧添加 VXLAN 头(含 VNI=1,用于识别隧道流量),再封装成宿主机的普通数据帧(源为当前节点 eth0 的 IP/MAC,目标为对方节点 eth0 的 IP/MAC)。
- 宿主机网络传输:数据帧从当前节点 eth0 发出,经物理网络到达目标节点 eth0。
- 解封装:目标节点内核识别 VXLAN 头(VNI=1),拆包后将内部数据帧交给本机 flannel.1。
- 转发到目标 Pod:flannel.1 拆包后,根据路由表转发到 cni0,再通过 veth pair 到达目标 Pod 的 eth0。
# 查看节点路由表
[root@master ~]# ip r
default via 192.168.2.2 dev ens160 proto static metric 100
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.2.0/24 dev ens160 proto kernel scope link src 192.168.2.60 metric 100
# 查看flannel.1的FDB(转发数据库,记录VTEP的MAC与目标节点IP的映射)
[root@master ~]# bridge fdb
01:00:5e:00:00:01 dev ens160 self permanent
33:33:00:00:00:01 dev ens160 self permanent
01:00:5e:00:00:fb dev ens160 self permanent
33:33:ff:4b:96:b2 dev ens160 self permanent
33:33:00:00:00:fb dev ens160 self permanent
33:33:00:00:00:01 dev docker0 self permanent
01:00:5e:00:00:6a dev docker0 self permanent
33:33:00:00:00:6a dev docker0 self permanent
01:00:5e:00:00:01 dev docker0 self permanent
01:00:5e:00:00:fb dev docker0 self permanent
ee:40:79:d7:d8:2e dev docker0 vlan 1 master docker0 permanent
ee:40:79:d7:d8:2e dev docker0 master docker0 permanent
33:33:00:00:00:01 dev kube-ipvs0 self permanent
1a:3d:84:39:33:cd dev flannel.1 dst 192.168.2.62 self permanent
ba:9a:ab:4b:f1:ef dev flannel.1 dst 192.168.2.63 self permanent
33:33:00:00:00:01 dev cni0 self permanent
01:00:5e:00:00:6a dev cni0 self permanent
33:33:00:00:00:6a dev cni0 self permanent
01:00:5e:00:00:01 dev cni0 self permanent
33:33:ff:4c:67:e4 dev cni0 self permanent
01:00:5e:00:00:fb dev cni0 self permanent
33:33:00:00:00:fb dev cni0 self permanent
5a:a1:4e:4c:67:e4 dev cni0 vlan 1 master cni0 permanent
5a:a1:4e:4c:67:e4 dev cni0 master cni0 permanent
76:8f:84:f8:90:13 dev veth88dfdeb4 master cni0
8a:dc:bc:8e:7a:4b dev veth88dfdeb4 vlan 1 master cni0 permanent
8a:dc:bc:8e:7a:4b dev veth88dfdeb4 master cni0 permanent
33:33:00:00:00:01 dev veth88dfdeb4 self permanent
01:00:5e:00:00:01 dev veth88dfdeb4 self permanent
33:33:ff:8e:7a:4b dev veth88dfdeb4 self permanent
33:33:00:00:00:fb dev veth88dfdeb4 self permanent
# 查看ARP表(节点IP与MAC的映射)
[root@master ~]# arp -n
Address HWtype HWaddress Flags Mask Iface
192.168.2.63 ether 00:0c:29:c3:b7:b7 C ens160
10.244.2.0 ether ba:9a:ab:4b:f1:ef CM flannel.1
192.168.2.1 ether 00:50:56:c0:00:08 C ens160
192.168.2.2 ether 00:50:56:f5:17:3e C ens160
10.244.1.0 ether 1a:3d:84:39:33:cd CM flannel.1
10.244.0.2 ether 76:8f:84:f8:90:13 C cni0
192.168.2.62 ether 00:0c:29:fa:d5:b5 C ens160
1.2.2 flannel支持的后端模式
| 网络模式 | 功能及适用场景 |
|---|---|
| vxlan(默认) | 通过 VXLAN 隧道封装数据包,支持跨网段通信(如不同子网的节点),兼容性好但性能有损耗(封装 / 解封装耗时)。 |
| Directrouting | 同网段节点用 host-gw(直接路由),跨网段用 vxlan,兼顾性能和兼容性(优先直接通信,跨网才隧道)。 |
| host-gw | 直接将节点作为网关,通过路由表转发,性能最优,但仅支持二层网络(节点需在同一子网),大规模集群可能引发广播风暴。 |
| UDP | 基于 UDP 封装,性能最差(用户态处理),仅用于调试,不推荐生产环境。 |
更改flannel的默认模式
[root@master ~]# kubectl -n kube-flannel edit cm kube-flannel-cfg
apiVersion: v1
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"EnableNFTables": false,
"Backend": {
"Type": "host-gw" # 切换为host-gw模式
}
}
# 删除现有flannel Pod,让新配置生效(Pod重建时加载新配置)
[root@master ~]# kubectl -n kube-flannel delete pods --all
pod "kube-flannel-ds-gqcts" deleted
pod "kube-flannel-ds-tvlt8" deleted
pod "kube-flannel-ds-zfd42" deleted
#host-gw模式下,跨节点路由直接指向节点IP
[root@master ~]# ip r
default via 192.168.2.2 dev ens160 proto static metric 100
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 192.168.2.62 dev ens160
10.244.2.0/24 via 192.168.2.63 dev ens160
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.2.0/24 dev ens160 proto kernel scope link src 192.168.2.60 metric 100
**结果:**切换为 host-gw 模式后,路由表中跨节点 Pod 网段的下一跳直接是节点的物理 IP(ens160),而非 flannel.1,说明取消了 VXLAN 隧道,性能更优。
1.3 calico网络插件
官网:
https://docs.projectcalico.org/getting-started/kubernetes/self-managed-onprem/onpremises
1.3.1 calico简介:
- 纯三层路由转发,无 NAT 和 Overlay 隧道,转发效率极高(直接通过路由表转发,无封装开销)。
- Calico 仅依赖三层路由可达。Calico 较少的依赖性使它能适配所有 VM、Container、白盒或者混合环境场景。
1.3.2 calico网络架构
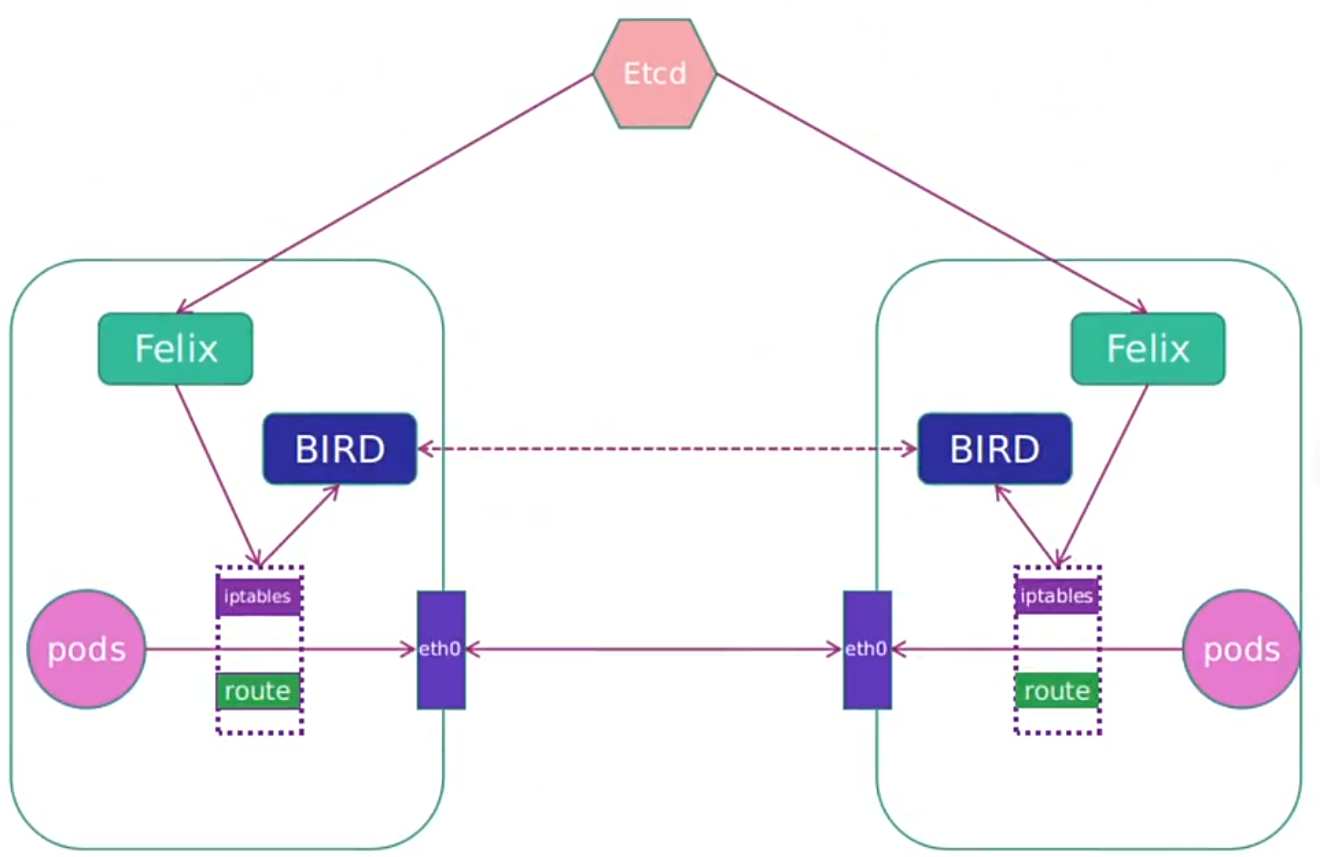
- 用户创建 Pod 后,Felix(每个节点的代理进程)负责:
- 配置 Pod 的网卡、IP、MAC(为 Pod 分配集群网段内的 IP)。
- 在节点内核路由表中添加条目(如 “10.244.166.128/32 via 节点网卡”),指定 Pod IP 的转发路径。
- 应用网络策略(ACL 规则),控制 Pod 间的访问权限。
- BIRD(路由程序)从内核获取路由变化,通过 BGP 协议将 Pod 的 IP 路由扩散到集群所有节点(让每个节点知道 “某 Pod IP 在某节点上”)。
- 跨节点通信时,节点直接根据路由表将数据包转发到目标节点,无需隧道封装(纯三层路由)。
1.3.3 部署calico
#删除flannel插件
[root@master ~]# kubectl delete -f kube-flannel.yml
#删除所有节点上flannel配置文件,避免冲突
[root@master ~]# cd /etc/cni/net.d/
[root@master net.d]# ls
10-flannel.conflist
[root@master net.d]# rm -rf 10-flannel.conflist
#下载部署文件
[root@master calico]# curl https://raw.githubusercontent.com/projectcalico/calico/v3.28.1/manifests/calico-typha.yaml -o calico.yaml
我这里选择本地上传
[root@master ~]# cd network/
[root@master network]# ls
flannel-0.25.5.tag.gz kube-flannel.yml nginx-1.23.tar.gz
[root@master network]# mkdir calico
[root@master network]# cd calico/
[root@master calico]# ls
calico-3.28.1.tar calico.yaml
[root@master calico]# docker load -i calico-3.28.1.tar
6b2e64a0b556: Loading layer [==================================================>] 3.69MB/3.69MB
38ba74eb8103: Loading layer [==================================================>] 205.4MB/205.4MB
5f70bf18a086: Loading layer [==================================================>] 1.024kB/1.024kB
Loaded image: calico/cni:v3.28.1
3831744e3436: Loading layer [==================================================>] 366.9MB/366.9MB
Loaded image: calico/node:v3.28.1
4f27db678727: Loading layer [==================================================>] 75.59MB/75.59MB
Loaded image: calico/kube-controllers:v3.28.1
993f578a98d3: Loading layer [==================================================>] 67.61MB/67.61MB
Loaded image: calico/typha:v3.28.1
#推送到私有仓库(供集群内节点拉取)
[root@master calico]# docker tag calico/cni:v3.28.1 rch.hjn.com/calico/cni:v3.28.1
[root@master calico]# docker tag calico/node:v3.28.1 rch.hjn.com/calico/node:v3.28.1
[root@master calico]# docker tag calico/kube-controllers:v3.28.1 rch.hjn.com/calico/kube-controllers:v3.28.1
[root@master calico]# docker tag calico/typha:v3.28.1 rch.hjn.com/calico/typha:v3.28.1
[root@master calico]# docker push rch.hjn.com/calico/cni:v3.28.1
[root@master calico]# docker push rch.hjn.com/calico/node:v3.28.1
[root@master calico]# docker push rch.hjn.com/calico/kube-controllers:v3.28.1
[root@master calico]# docker push rch.hjn.com/calico/typha:v3.28.1
更改yml设置
[root@master calico]# vim calico.yaml
# 修改镜像地址为私有仓库(确保节点能拉取)
4835 image: rch.hjn.com/calico/cni:v3.28.1
4906 image: rch.hjn.com/calico/node:v3.28.1
# 关闭IPIP隧道(使用纯三层路由)
4970 - name: CALICO_IPV4POOL_IPIP
4971 value: "Never"
# 指定Pod网段(与k8s集群配置一致)
4999 - name: CALICO_IPV4POOL_CIDR
5000 value: "10.244.0.0/16"
# 指定节点网卡(calico用于通信的物理网卡)
5001 - name: CALICO_AUTODETECTION_METHOD
5002 value: "interface=ens160" #得看自己网卡名字
[root@master calico]# kubectl apply -f calico.yaml
[root@master calico]# kubectl -n kube-system get pods
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6849cb478c-27hm4 1/1 Running 0 81s
calico-node-24htc 1/1 Running 0 81s
calico-node-rgz2r 1/1 Running 0 81s
calico-node-v97jv 1/1 Running 0 81s
calico-typha-fff9df85f-vkzxx 1/1 Running 0 81s
coredns-f84b85d65-4qr6t 1/1 Running 2 (51m ago) 29h
coredns-f84b85d65-hv9br 1/1 Running 2 (51m ago) 29h
etcd-master 1/1 Running 2 (51m ago) 15d
kube-apiserver-master 1/1 Running 2 (51m ago) 4d
kube-controller-manager-master 1/1 Running 3 (51m ago) 15d
kube-proxy-b4fp9 1/1 Running 2 (51m ago) 3d7h
kube-proxy-n6d4d 1/1 Running 2 (51m ago) 3d7h
kube-proxy-xcvdf 1/1 Running 2 (51m ago) 3d7h
kube-scheduler-master 1/1 Running 3 (51m ago) 15d
[root@master calico]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane 15d v1.30.0
node1 Ready <none> 15d v1.30.0
node2 Ready <none> 15d v1.30.0
# 测试Pod通信(创建Pod并访问)
[root@master calico]# kubectl run testpod --image myapp:v1
pod/testpod created
[root@master calico]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 7s 10.244.166.128 node1 <none> <none>
[root@master calico]# curl 10.244.166.128
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
**结果:**calico 部署后,Pod 能正常分配 IP 且跨节点通信,说明纯三层路由生效,无隧道封装,性能优于 flannel 的 vxlan 模式。
网络插件(flannel vs calico)区别总结:
| 维度 | flannel | calico |
|---|---|---|
| 转发方式 | 依赖 VXLAN 隧道(overlay)或 host-gw | 纯三层路由(无隧道) |
| 性能 | 中(vxlan 有封装开销) | 高(直接路由,无额外开销) |
| 网络策略 | 不支持 | 支持(细粒度 ACL 规则) |
| 适用场景 | 中小规模集群,追求部署简单 | 大规模集群,需高性能和安全策略 |
二 k8s调度(Scheduling)
2.1 调度在Kubernetes中的作用
- 调度是指将未分配的 Pod 自动分配到合适的节点,确保集群资源高效利用。
- 调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod
- 调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行
2.2 调度原理:
- 创建Pod
- 用户通过Kubernetes API创建Pod对象,并在其中指定Pod的资源需求、容器镜像等信息。
- 调度器监视Pod
- Kubernetes调度器监视集群中的未调度Pod对象,并为其选择最佳的节点。
- 选择节点
- 调度器通过算法选择最佳的节点,并将Pod绑定到该节点上。调度器选择节点的依据包括节点的资源使用情况、Pod的资源需求、亲和性和反亲和性等。
- 绑定Pod到节点
- 调度器将Pod和节点之间的绑定信息保存在etcd数据库中,以便节点可以获取Pod的调度信息。
- 节点启动Pod
- 节点定期检查etcd数据库中的Pod调度信息,并启动相应的Pod。如果节点故障或资源不足,调度器会重新调度Pod,并将其绑定到其他节点上运行。
- 故障重调度:若节点故障,调度器会将 Pod 重新调度到其他健康节点。
2.3 调度器种类
- 默认调度器(Default Scheduler):
- 是Kubernetes中的默认调度器,负责对新创建的Pod进行调度,并将Pod调度到合适的节点上。
- 自定义调度器(Custom Scheduler):
- 是一种自定义的调度器实现,可以根据实际需求来定义调度策略和规则,以实现更灵活和多样化的调度功能。
- 扩展调度器(Extended Scheduler):
- 是一种支持调度器扩展器的调度器实现,可以通过调度器扩展器来添加自定义的调度规则和策略,以实现更灵活和多样化的调度功能。
- kube-scheduler是kubernetes中的默认调度器,在kubernetes运行后会自动在控制节点运行
[root@master ~]# mkdir scheduler
[root@master ~]# cd scheduler/
[root@master scheduler]# kubectl -n kube-system get pods
NAME READY STATUS RESTARTS AGE
pod/kube-scheduler-master 1/1 Running 3 (61m ago) 15d # 默认调度器Pod
2.4 常用调度方法
2.4.1 nodename
- nodeName 是节点选择约束的最简单方法,但一般不推荐
- 如果 nodeName 在 PodSpec 中指定了,则它优先于其他的节点选择方法
- 使用 nodeName 来选择节点的一些限制
- 如果指定的节点不存在。
- 如果指定的节点没有资源来容纳 pod,则pod 调度失败。
- 云环境中的节点名称并非总是可预测或稳定的
[root@master scheduler]# kubectl run testpod --image myapp:v1 --dry-run=client -o yaml > nodename.yml
[root@master scheduler]# vim nodename.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeName: node2 # 强制Pod运行在node2
containers:
- image: myapp:v1
name: testpod
[root@master scheduler]# kubectl apply -f nodename.yml
pod/testpod created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 11s 10.244.104.0 node2 <none> <none> # 成功运行在node2
[root@master scheduler]# vim nodename.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeName: node1 # 修改为node1
containers:
- image: myapp:v1
name: testpod
[root@master scheduler]# kubectl delete -f nodename.yml
pod "testpod" deleted
[root@master scheduler]# kubectl apply -f nodename.yml
pod/testpod created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 2s 10.244.166.129 node1 <none> <none> # 成功运行在node1
#不存在的节点会导致调度失败
[root@master scheduler]# vim nodename.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeName: node3 # 修改nodeName为node3(不存在)
containers:
- image: myapp:v1
name: testpod
[root@master scheduler]# kubectl delete -f nodename.yml
pod "testpod" deleted
[root@master scheduler]# kubectl apply -f nodename.yml
pod/testpod created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 0/1 Pending 0 2s <none> node3 <none> <none> # 调度失败,状态为Pending
**结果:**nodeName 优先级最高,但有明显局限(节点不存在或资源不足时 Pod 无法运行),仅适合调试场景。
2.4.2 Nodeselector(通过标签控制节点)
-
nodeSelector 是节点选择约束的最简单推荐形式
-
给选择的节点添加标签:
kubectl label nodes node2 lab=rch -
可以给多个节点设定相同标签
示例:
[root@master scheduler]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
master Ready control-plane 15d v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
node1 Ready <none> 15d v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node1,kubernetes.io/os=linux
node2 Ready <none> 15d v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux
# 1. 给节点打标签(给node2添加app=rch标签)
[root@master scheduler]# kubectl label nodes node2 app=rch
node/node2 labeled
[root@master scheduler]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
master Ready control-plane 15d v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
node1 Ready <none> 15d v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node1,kubernetes.io/os=linux
node2 Ready <none> 15d v1.30.0 app=rch,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux
# 2. 创建Pod时通过nodeSelector匹配标签
[root@master scheduler]# cp nodename.yml nodeselector.yml
[root@master scheduler]# vim nodeselector.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeSelector:
app: rch # 仅调度到有app=rch标签的节点
containers:
- image: myapp:v1
name: testpod
[root@master scheduler]# kubectl apply -f nodeselector.yml
pod/testpod created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 9s 10.244.104.1 node2 <none> <none> # 成功调度到node2
**结果:**nodeSelector 通过标签匹配节点,可给多个节点打相同标签(如给 node1 和 node2 都打 app=rch),实现 Pod 在多个节点间的负载均衡,比 nodeName 更灵活。
2.5 affinity(亲和性)
提供更复杂的调度规则(如 “尽量调度到某类节点”“与某类 Pod 在同一节点”),比 nodeSelector 更灵活。
官方文档 :
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node
2.5.1 亲和与反亲和
- 亲和性:让 Pod “倾向” 或 “必须” 调度到满足条件的节点 / Pod 所在节点。
- 反亲和性:让 Pod “避免” 调度到满足条件的节点 / Pod 所在节点。
2.5.2 nodeAffinity节点亲和
- 那个节点服务指定条件就在那个节点运行
- requiredDuringSchedulingIgnoredDuringExecution 必须满足,但不会影响已经调度
- preferredDuringSchedulingIgnoredDuringExecution 倾向满足,在无法满足情况下也会调度pod
- IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
- nodeaffinity还支持多种规则匹配条件的配置如
| 匹配规则 | 功能 |
|---|---|
| ln | label 的值在列表内 |
| Notln | label 的值不在列表内 |
| Gt | label 的值大于设置的值,不支持Pod亲和性 |
| Lt | label 的值小于设置的值,不支持pod亲和性 |
| Exists | 设置的label 存在 |
| DoesNotExist | 设置的 label 不存在 |
nodeAffinity示例
[root@master scheduler]# kubectl explain pod.spec.affinity | less
FIELDS:
nodeAffinity <NodeAffinity>
Describes node affinity scheduling rules for the pod.
podAffinity <PodAffinity>
Describes pod affinity scheduling rules (e.g. co-locate this pod in the same
node, zone, etc. as some other pod(s)).
podAntiAffinity <PodAntiAffinity>
Describes pod anti-affinity scheduling rules (e.g. avoid putting this pod in
the same node, zone, etc. as some other pod(s)).
[root@master scheduler]# kubectl explain pod.spec.affinity.nodeAffinity | less
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]PreferredSchedulingTerm>
The scheduler will prefer to schedule pods to nodes that satisfy the
affinity expressions specified by this field, but it may choose a node that
violates one or more of the expressions. The node that is most preferred is
the one with the greatest sum of weights, i.e. for each node that meets all
of the scheduling requirements (resource request, requiredDuringScheduling
affinity expressions, etc.), compute a sum by iterating through the elements
of this field and adding "weight" to the sum if the node matches the
corresponding matchExpressions; the node(s) with the highest sum are the
most preferred.
requiredDuringSchedulingIgnoredDuringExecution <NodeSelector>
If the affinity requirements specified by this field are not met at
scheduling time, the pod will not be scheduled onto the node. If the
affinity requirements specified by this field cease to be met at some point
during pod execution (e.g. due to an update), the system may or may not try
to eventually evict the pod from its node.
必须满足规则:
[root@master scheduler]# vim nodeaffinity.yml
apiVersion: v1
kind: Pod
metadata:
name: node-affinity
spec:
containers:
- name: nginx
image: nginx:1.23
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 必须满足(调度时检查,运行中不驱逐)
nodeSelectorTerms:
- matchExpressions:
- key: disk # 节点标签的key
operator: In # 匹配规则:标签值在列表中
values:
- ssd
- m2 # 仅调度到disk=ssd或disk=m2的节点
# 应用后Pod处于Pending(无符合条件的节点)
[root@master scheduler]# kubectl apply -f nodeaffinity.yml
pod/node-affinity created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity 0/1 Pending 0 8s <none> <none> <none> <none>
# 给node1添加disk=ssd标签后,Pod成功调度
[root@master scheduler]# kubectl label nodes node1 disk=ssd
node/node1 labeled
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity 1/1 Running 0 28s 10.244.166.130 node1 <none> <none>
testpod 1/1 Running 0 20m 10.244.104.1 node2 <none> <none>
[root@master scheduler]# kubectl delete -f nodeaffinity.yml
pod "node-affinity" deleted
[root@master scheduler]# vim nodeaffinity.yml
operator: NotIn #不调度到disk=ssd或disk=m2的节点
[root@master scheduler]# kubectl apply -f nodeaffinity.yml
pod/node-affinity created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity 1/1 Running 0 3s 10.244.104.2 node2 <none> <none>
必须满足规则:
[root@master scheduler]# vim nodeaffinity.yml
apiVersion: v1
kind: Pod
metadata:
name: node-affinity
spec:
containers:
- name: nginx
image: nginx:1.23
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution: # 倾向满足(不满足也能调度)
- preference:
matchExpressions:
- key: disk
operator: In
values:
- ssd
- m2
weight: 50 # 权重(0-100,越高越优先)
# 应用后,Pod优先调度到有disk=ssd的node1
[root@master scheduler]# kubectl apply -f nodeaffinity.yml
pod/node-affinity created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity 1/1 Running 0 8s 10.244.166.131 node1 <none> <none>
[root@master scheduler]# vim nodeaffinity.yml
[root@master scheduler]# kubectl delete -f nodeaffinity.yml
pod "node-affinity" deleted
[root@master scheduler]# kubectl apply -f nodeaffinity.yml
pod/node-affinity created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity 1/1 Running 0 2s 10.244.166.132 node1 <none> <none>
**结果:**required 规则是 “硬限制”(不满足则无法调度),preferred 是 “软限制”(尽量满足,不满足也能运行),灵活度更高。
2.5.3 Podaffinity(pod的亲和)
让新 Pod 与指定标签的 Pod 调度到同一节点(如 “web Pod 和 db Pod 在同一节点,减少网络延迟”)。
- 那个节点有符合条件的POD就在那个节点运行
- podAffinity 主要解决POD可以和哪些POD部署在同一个节点中的问题
- podAntiAffinity主要解决POD不能和哪些POD部署在同一个节点中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
- Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时,
- Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度。
Podaffinity示例
[root@master scheduler]# kubectl create deployment web --image nginx:1.23 --replicas=2 --dry-run=client -o yaml > podaffinity.yml
[root@master scheduler]# vim podaffinity.yml
[root@master scheduler]# kubectl apply -f podaffinity.yml
deployment.apps/web created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7597746468-8wlhw 1/1 Running 0 7s 10.244.166.133 node1 <none> <none>
web-7597746468-pbcv2 1/1 Running 0 7s 10.244.104.3 node2 <none> <none>
[root@master scheduler]# kubectl delete -f podaffinity.yml
deployment.apps "web" deleted
# 创建Deployment,让Pod与其他带app=web标签的Pod在同一节点
[root@master scheduler]# vim podaffinity.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx:1.23
name: nginx
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web # 匹配带app=web标签的Pod
topologyKey: "kubernetes.io/hostname" # 同一节点(按主机名分组)
# 应用后,2个Pod都调度到同一节点(因需与已有app=web的Pod在同一节点)
[root@master scheduler]# kubectl apply -f podaffinity.yml
deployment.apps/web created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-c988fc947-b57ht 1/1 Running 0 10s 10.244.166.134 node1 <none> <none>
web-c988fc947-jdlmq 1/1 Running 0 10s 10.244.166.135 node1 <none> <none>
# 新 Pod 与指定标签的 Pod 调度到同一节点
[root@master scheduler]# kubectl edit -f podaffinity.yml
replicas: 3
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-c988fc947-9h2kq 1/1 Running 0 2s 10.244.166.136 node1 <none> <none>
web-c988fc947-b57ht 1/1 Running 0 7m21s 10.244.166.134 node1 <none> <none>
web-c988fc947-jdlmq 1/1 Running 0 7m21s 10.244.166.135 node1 <none> <none>
**结果:**podAffinity 确保新 Pod 与目标 Pod 在同一节点(拓扑键kubernetes.io/hostname指定 “同一节点”),适合依赖紧密的服务(如前端和后端)。
2.5.4 Podantiaffinity(pod反亲和)
让新 Pod 避免与指定标签的 Pod 调度到同一节点(如 “多个 web Pod 分散在不同节点,实现高可用”)。
Podantiaffinity示例
[root@master scheduler]# cp podaffinity.yml podantiaffinity.yml
[root@master scheduler]# vim podantiaffinity.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx:1.23
name: nginx
affinity:
podAntiAffinity: # 避免在同一节点
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web
topologyKey: "kubernetes.io/hostname"
# 应用后,Pod分散在不同节点,节点不足时 Pod 会 Pending
[root@master scheduler]# kubectl apply -f podaffinity.yml
deployment.apps/web created
[root@master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-6cb695486f-7xxtt 1/1 Running 0 4s 10.244.166.138 node1 <none> <none>
web-6cb695486f-cwdrl 0/1 Pending 0 4s <none> <none> <none> <none>
web-6cb695486f-gh8dr 1/1 Running 0 4s 10.244.104.5 node2 <none> <none>
**结果:**podAntiAffinity 实现 Pod 分散部署,提高服务可用性(避免单点故障),但受节点数量限制(节点不足时 Pod 会 Pending)。
调度方法区别总结:
| 方法 | 核心逻辑 | 灵活性 | 适用场景 |
|---|---|---|---|
| nodeName | 直接指定节点名称 | 低 | 调试、固定节点部署 |
| nodeSelector | 匹配节点标签 | 中 | 简单的节点分组调度 |
| nodeAffinity | 基于节点标签的复杂规则(硬 / 软限制) | 高 | 按节点属性(如磁盘类型)调度 |
| podAffinity | 与指定 Pod 在同一节点 | 高 | 依赖紧密的服务(如 web+db) |
| podAntiAffinity | 与指定 Pod 不在同一节点 | 高 | 高可用部署(分散 Pod) |
2.6 Taints(污点模式,禁止调度)
通过给节点设置污点,阻止 Pod 调度到该节点;只有 Pod 设置了对应的容忍,才能被调度(用于特殊节点,如控制节点、GPU 节点)。
- Taints(污点)是Node的一个属性,设置了Taints后,默认Kubernetes是不会将Pod调度到这个Node上
- Kubernetes如果为Pod设置Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去
- 可以使用命令 kubectl taint 给节点增加一个 taint:
$ kubectl taint nodes <nodename> key=string:effect #命令执行方法
$ kubectl taint nodes node1 key=value:NoSchedule #创建
$ kubectl describe nodes server1 | grep Taints #查询
$ kubectl taint nodes node1 key- #删除
其中[effect] 可取值:
| effect值 | 解释 |
|---|---|
| NoSchedule | POD 不会被调度到标记为 taints 节点 |
| PreferNoSchedule | NoSchedule 的软策略版本,尽量不调度到此节点 |
| NoExecute | 如该节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被逐出 |
Taints示例
创建无污点时的Deployment(Pod均匀分布在node1和node2)
[root@master ~]# mkdir taints
[root@master ~]# cd taints/
[root@master taints]# cp ../scheduler/podaffinity.yml taints.yml
[root@master taints]# vim taints.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx:1.23
name: nginx
[root@master taints]# kubectl apply -f taints.yml
deployment.apps/web created
# 查看Pod分布(此时node1和node2都无污点,Pod会均匀分布)
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7597746468-5pkgg 1/1 Running 0 8s 10.244.166.139 node1 <none> <none>
web-7597746468-c455n 1/1 Running 0 8s 10.244.104.6 node2 <none> <none>
web-7597746468-dgt6r 1/1 Running 0 8s 10.244.166.140 node1 <none> <none>
# 扩容到5个副本(依然均匀分布在node1和node2)
[root@master taints]# kubectl scale deployment web --replicas 5
deployment.apps/web scaled
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7597746468-5pkgg 1/1 Running 0 73s 10.244.166.139 node1 <none> <none>
web-7597746468-6kzp5 1/1 Running 0 2s 10.244.166.141 node1 <none> <none>
web-7597746468-c455n 1/1 Running 0 73s 10.244.104.6 node2 <none> <none>
web-7597746468-dgt6r 1/1 Running 0 73s 10.244.166.140 node1 <none> <none>
web-7597746468-wfnd8 1/1 Running 0 2s 10.244.104.7 node2 <none> <none>
给node1添加NoSchedule污点(演示 “禁止新 Pod 调度到该节点” 的效果)
# 给node1添加key为name=nodetype、effect为NoSchedule的污点
[root@master taints]# kubectl taint node node1 name=nodetype:NoSchedule
# 查看节点污点(确认node1已添加污点)
[root@master taints]# kubectl describe nodes | grep Taint
Taints: node-role.kubernetes.io/control-plane:NoSchedule # master节点默认污点
Taints: name=nodetype:NoSchedule # 刚给node1加的污点
Taints: <none> # node2无污点
# 删除旧的Deployment(清除已有Pod,方便看新调度结果)
[root@master taints]# kubectl delete -f taints.yml
deployment.apps "web" deleted
[root@master taints]# kubectl apply -f taints.yml
deployment.apps/web created
# 查看新Pod分布(node1有NoSchedule污点,新Pod只能调度到node2)
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7597746468-4p9g7 1/1 Running 0 3s 10.244.104.8 node2 <none> <none>
web-7597746468-tx689 1/1 Running 0 3s 10.244.104.10 node2 <none> <none>
web-7597746468-wpf5m 1/1 Running 0 3s 10.244.104.9 node2 <none> <none>
# 扩容到6个副本(新Pod仍只能调度到node2)
[root@master taints]# kubectl scale deployment web --replicas 6
deployment.apps/web scaled
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7597746468-89269 1/1 Running 0 20s 10.244.104.14 node2 <none> <none>
web-7597746468-c2pnv 1/1 Running 0 2s 10.244.104.15 node2 <none> <none>
web-7597746468-dtw6s 1/1 Running 0 2s 10.244.104.17 node2 <none> <none>
web-7597746468-lp6qv 1/1 Running 0 20s 10.244.104.12 node2 <none> <none>
web-7597746468-shdw8 1/1 Running 0 2s 10.244.104.16 node2 <none> <none>
web-7597746468-xjhn5 1/1 Running 0 20s 10.244.104.13 node2 <none> <none>
删除 node1 的污点(演示 “取消限制后 Pod 恢复正常调度” 的效果)
# 删除node1上key为name的污点
[root@master taints]# kubectl taint node node1 name-
# 确认污点已删除(node1的Taints变为<none>)
[root@master taints]# kubectl describe nodes | grep Taint
Taints: node-role.kubernetes.io/control-plane:NoSchedule
Taints: <none>
Taints: <none>
# 重新创建Deployment并扩容(查看调度恢复情况)
[root@master taints]# kubectl delete -f taints.yml
deployment.apps "web" deleted
[root@master taints]# kubectl apply -f taints.yml
deployment.apps/web created
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7597746468-92rpw 1/1 Running 0 2s 10.244.166.142 node1 <none> <none>
web-7597746468-k86j2 1/1 Running 0 2s 10.244.166.143 node1 <none> <none>
web-7597746468-qjzx7 1/1 Running 0 2s 10.244.104.11 node2 <none> <none>
# 查看Pod分布(重新均匀分布在node1和node2)
[root@master taints]# kubectl scale deployment web --replicas 6
deployment.apps/web scaled
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7597746468-cvljh 1/1 Running 0 5s 10.244.166.146 node1 <none> <none>
web-7597746468-f7jps 1/1 Running 0 5s 10.244.104.20 node2 <none> <none>
web-7597746468-fg9hf 1/1 Running 0 5s 10.244.104.19 node2 <none> <none>
web-7597746468-qlxn7 1/1 Running 0 10s 10.244.166.144 node1 <none> <none>
web-7597746468-vzzlr 1/1 Running 0 10s 10.244.104.18 node2 <none> <none>
web-7597746468-wppbk 1/1 Running 0 10s 10.244.166.145 node1 <none> <none>
给 node2 添加 NoExecute 污点(演示 “驱逐已有无容忍 Pod” 的效果)
[root@master taints]# kubectl taint node node2 name=nodetype:NoExecute
node/node2 tainted
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-7597746468-2xs4l 1/1 Running 0 3s 10.244.166.151 node1 <none> <none>
web-7597746468-cvljh 1/1 Running 0 103s 10.244.166.146 node1 <none> <none>
web-7597746468-dnhpv 0/1 ContainerCreating 0 3s <none> node1 <none> <none>
web-7597746468-pf7g2 1/1 Running 0 3s 10.244.166.147 node1 <none> <none>
web-7597746468-qlxn7 1/1 Running 0 108s 10.244.166.144 node1 <none> <none>
web-7597746468-wppbk 1/1 Running 0 108s 10.244.166.145 node1 <none> <none>
**结果:**添加 NoSchedule 污点后,新 Pod 无法调度到 node1,只能调度到无污点的 node2,实现对节点的 “保护”(如预留节点资源给特定 Pod)。若需允许某些 Pod 调度到有污点的节点,需在 Pod 中设置tolerations匹配污点。
tolerations(污点容忍)
- tolerations中定义的key、value、effect,要与node上设置的taint保持一直:
- 如果 operator 是 Equal ,则key与value之间的关系必须相等。
- 如果 operator 是 Exists ,value可以省略
- 如果不指定operator属性,则默认值为Equal。
- 还有两个特殊值:
- 当不指定key,再配合Exists 就能匹配所有的key与value ,可以容忍所有污点。
- 当不指定effect ,则匹配所有的effect
污点容忍示例:
[root@master taints]# kubectl taint node node2 nodetype=bad:NoExecute
node/node2 tainted
[root@master taints]# kubectl taint node node1 nodetype=bad:NoSchedule
node/node1 tainted
[root@master taints]# kubectl describe nodes | grep Taint
Taints: node-role.kubernetes.io/control-plane:NoSchedule
Taints: nodetype=bad:NoSchedule
Taints: name=nodetype:NoExecute
[root@master taints]# cp taints.yml toleration.yml
[root@master taints]# vim toleration.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx:1.23
name: nginx
tolerations: # 添加容忍规则
- operator: Exists # 匹配方式:存在即可(不指定key,匹配所有污点)
[root@master taints]# kubectl apply -f toleration.yml
deployment.apps/web configured
# 查看Pod分布(能调度到node1、node2、甚至master,因为容忍所有污点)
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-845c87fddc-bjf56 1/1 Running 0 7s 10.244.166.156 node1 <none> <none>
web-845c87fddc-vtf29 1/1 Running 0 10s 10.244.104.21 node2 <none> <none>
web-845c87fddc-xz8rk 1/1 Running 0 9s 10.244.219.64 master <none> <none>
[root@master taints]# kubectl delete -f toleration.yml
deployment.apps "web" deleted
[root@master taints]# vim toleration.yml
tolerations:
- operator: Exists
effect: NoSchedule # 只匹配effect为NoSchedule的污点
[root@master taints]# kubectl apply -f toleration.yml
deployment.apps/web created
#只容忍 NoSchedule 污点,所以 Pod 能调度到 node1(NoSchedule)和 master(默认 NoSchedule),但不能调度到 node2(NoExecute,未被容忍)。
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-5b46f6c7-rltcl 1/1 Running 0 2s 10.244.166.157 node1 <none> <none>
web-5b46f6c7-sbpfr 1/1 Running 0 2s 10.244.219.66 master <none> <none>
web-5b46f6c7-w4j6c 1/1 Running 0 2s 10.244.219.65 master <none> <none>
[root@master taints]# kubectl delete -f toleration.yml
deployment.apps "web" deleted
[root@master taints]# vim toleration.yml
tolerations:
- key: nodetype # 匹配污点的key
value: bad # 匹配污点的value
effect: NoSchedule # 匹配污点的effect
# operator默认Equal,需严格匹配key、value、effect
[root@master taints]# kubectl apply -f toleration.yml
deployment.apps/web created
# 精确匹配 node1 的nodetype=bad:NoSchedule污点,所以 Pod 只能调度到 node1(其他节点的污点不匹配)。
[root@master taints]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-6f4b69478-rkvq2 1/1 Running 0 3s 10.244.166.158 node1 <none> <none>
web-6f4b69478-vw85l 1/1 Running 0 3s 10.244.166.160 node1 <none> <none>
web-6f4b69478-xd4nw 1/1 Running 0 3s 10.244.166.159 node1 <none> <none>
总结(Taints 与 Tolerations 核心区别与联系)
| 类型 | 作用对象 | 核心功能 | 关系 |
|---|---|---|---|
| Taints | 节点 | 阻止 Pod 调度(设置限制) | 需 Tolerations 匹配才能解除限制 |
| Tolerations | Pod | 忽略节点污点(突破限制) | 仅对有对应 Taints 的节点生效 |
三 Kubernetes 网络与调度总结
- 网络通信:通过 CNI 插件实现,主流有 flannel(依赖 VXLAN 隧道或 host-gw,部署简单)和 calico(纯三层路由,性能高且支持网络策略)。涵盖 Pod 间、Pod 与 Service、内外网通信等场景,依赖网桥、隧道、路由表等技术。
- 调度机制:默认调度器负责将 Pod 分配到合适节点,核心方法包括 nodeName(强制指定节点)、nodeSelector(标签匹配)、亲和性(nodeAffinity 按节点标签、podAffinity/AntiAffinity 按 Pod 关系调度,支持硬 / 软规则),满足灵活调度需求。

















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









