



基于聚类的奖励算法以在联邦机器学习驱动的物联网环境中检测对手
摘要
近年来,联邦机器学习在为物联网设备构建智能入侵检测系统方面非常有用。由于物联网设备配备的安全架构容易受到各种攻击,这些安全漏洞可能在去中心化物联网设备的联邦训练过程中带来风险。对抗者可以控制这些物联网设备并注入虚假梯度,从而降低全局模型性能。本文提出了一种利用聚类算法来检测对抗者的方法。在聚类之后,该方法进一步对客户端进行奖励,以识别诚实与恶意客户端。我们提出的梯度过滤方法不需要客户端提供任何处理能力,也不会占用过多带宽,因此非常适合物联网设备。此外,即使存在40%的对抗者,我们的方法在提升全局模型准确率方面也非常成功,最高可达99%。
I. 引言
近几十年来,人们见证了物联网设备的快速增长。由于对低功耗和计算基础设施的需求较低,以及远程控制访问和低成本的优势,物联网设备在健康信息学、交通、家庭自动化和其他领域得到了广泛应用[1‐2]。由于计算基础设施的限制,如今的物联网设备并未嵌入多层安全架构[3]。这种薄弱的安全架构已成为对抗者攻击以使物联网设备故障的主要目标。随着对抗者新型攻击的不断出现,传统的用于物联网设备入侵检测的黑名单技术已不再可靠。近年来,文献中出现了大量研究工作试图解决这一问题,这些工作采用了不同的机器学习和深度学习算法进行入侵检测[4‐5]。
基于机器学习和深度学习的入侵检测技术需要将大量数据集中聚合并进行处理[6]。基于数据集的入侵检测通常是网络和网页的日志。根据[7],近期的数据泄露活动已导致这些数据暴露给对抗者。对抗者利用这些日志获取有用信息,进而对用户发起更具破坏性的攻击[8]。考虑到人们的隐私问题,谷歌于2017年提出了联邦机器学习[9]。联邦机器学习利用客户端本地的数据集来训练全局模型。在此过程中,参与联邦训练的每个客户端在全球范围内去中心化分布。联邦环境通过不在服务器端导出客户端的数据集,保护了用户的隐私。此外,联邦学习还有助于构建更优的机器学习模型,通过发掘全球数十亿设备产生的数据中的知识来学习模型。
由于物联网节点是去中心化的,注入数据和梯度的中央权威掌握在这些物联网节点手中。由于物联网设备极易受到攻击,对抗者可以利用这些物联网设备中的安全漏洞来注入虚假数据和梯度。攻击者可以在任何时间注入这些虚假梯度,即在客户端、客户端与服务器之间的通信过程中,以及服务器端。通过控制客户端可在客户端侧发起攻击,在通信轮次期间可通过攻击者作为中间人的方式在联邦训练过程中实施攻击,而在服务器端则可通过控制服务器实现攻击。错误的梯度会导致从物联网设备生成的数据集中推断出错误知识。
这些虚假梯度可能导致全局模型在联邦环境中需要更多的通信轮次才能收敛。更高的通信轮次将消耗大量的计算能力和带宽,这超出了资源受限的物联网设备的能力范围。有时高度噪声化的梯度可能会导致模型性能显著下降。在基于机器学习的入侵检测系统中,复杂的梯度投毒攻击是数十亿物联网设备中多种其他攻击的源头,例如DDoS攻击和钓鱼攻击。由于梯度投毒直接损害了部署在物联网设备中的入侵检测系统检测入侵的能力,因此这些攻击成为可能。此时,开发一种高效且适用于资源受限物联网设备的方法来应对这类梯度投毒攻击变得至关重要。本文提出了一种基于聚类的算法,在服务器端对更新后的梯度进行过滤。该梯度过滤通过基于K均值聚类算法获得的诚实与恶意标识,对每个客户端的正负评分进行奖励来实现。基于奖励的算法进一步帮助识别大规模阻碍全局模型性能的对抗者,并将其永久移除。基于奖励的算法将减少通信轮次,同时提高全局模型的准确率。
本文其余部分组织如下:第二节介绍了在联邦环境中解决梯度投毒攻击的相关工作的文献综述。第三节介绍了联邦学习和平均化的背景知识。第四节简要讨论了我们提出的方法。第五节介绍了我们的实验方法,第六节简要讨论了我们的结果。最后,第七节对论文进行了总结。
II. 相关工作
联邦机器学习本身在文献中是一个非常新的概念。关于解决联邦机器学习中梯度投毒攻击的研究工作很少;然而,我们已尽可能涵盖研究人员为应对此类攻击所提出的大多数方法。文献中提出解决这些攻击的方法可分为两类,即:基于过滤的方法和基于区块链的方法。我们将在下文简要讨论这两类方法。
在基于过滤的方法中,客户端使用其本地数据集验证联邦训练中从全局模型获得的梯度。在验证过程中计算损失函数得分,并通过分析对全局模型产生负向贡献的客户端来识别对抗者,然后将其屏蔽。文献[11]的作者讨论了一种名为FoolsGold的方法,可解决女巫节点发起的投毒攻击。在他们的方法中,计算了更新后的梯度之间的余弦相似度。基于相似度得分,区分出女巫节点和非女巫节点的梯度。即使参与的女巫节点数量较多,该方法依然高效,并且不需要来自客户端的额外信息,仅需更新后的梯度。然而,当参与的女巫节点仅为一个时,其所提出的方法无法检测到投毒攻击。文献[12]的作者提出了一种基于Krum函数的方法。Krum函数无法容忍单个拜占庭故障。文献[11]的作者将Krum函数与FoolsGold相结合,以解决单个女巫节点引起的投毒攻击。文献[13]的作者提出了一种方法,在联邦训练过程中识别恶意模型,并在这些模型对全局平均化做出贡献之前将其剔除。通过使用客户端本地数据集对全局模型进行验证,并结合损失函数来识别恶意模型。具有较高损失函数值的客户端被识别为女巫节点。
在基于区块链的方法中,更新后的梯度首先通过基于区块链的认证协议。在对抗环境中,如果梯度过滤协议位于客户端,则对抗者可能控制该协议并逃避检测。然而,在基于区块链的方法中,梯度完整性并非由单个节点检查,而是由分布在全球的数千个去中心化节点共同验证。在此方法中,即使攻击者控制了作为梯度认证协议的一个节点,通过共识协议,虚假梯度的有效性仍会被忽略,从而减少对全局模型的污染。[14]的作者提出了一种完全去中心化的点对点区块链架构,该架构利用区块链和密码学协议来验证梯度。所提出的方法具有很高的可扩展性,能够过滤被污染的梯度;即使超过30%的女巫节点同时试图污染全局模型也能有效应对。[15]的作者提出了一种基于数字签名的验证协议,能够识别每个试图破坏全局模型的客户端。
III. 背景 为了更好地理解梯度投毒
为了理解攻击以及我们所提出的方法如何解决此类攻击,读者需要了解在机器学习中联邦训练和平局化的工作原理。在本节中,借助算法1,我们对这些主题进行了详细讨论。在我们的方法中,采用了McMahan提出的联邦平均算法[9]。基于SGD的联邦平均算法在算法1中进行了描述。在算法1中,最初所有参与训练的节点都会收到一些关于其机器学习算法参数的权重。在SGD的情况下,我们使用学习率η作为参数。每个参与节点都有其本地数据集,表示为dn。然后,客户端侧的模型参数通过从全局服务器接收到的权重进行更新,并在每个客户端的数据集(即dn)上对模型进行训练。
模型在每个客户端数据集上完美拟合后得到的权重表示为Wweight。每个客户端的Wweight随后被发送到全局服务器进行平均化。Waverage表示算法2中的平均权重。平均后的权重再次发送给所有参与的节点,用于下一轮训练。联邦平均化和训练的过程持续进行,直到全局模型的损失函数收敛到期望值。攻击者可以访问客户端,并通过注入虚假梯度参与联邦平均化。这里的虚假梯度是指幅值显著偏离真实梯度的任何梯度,可能会大幅降低模型准确率。
算法1. 联邦平均化SGD算法
过程 Server()
Wall_nodes = Receive_weight()
Waverage ← 1/n ∑_{k=1}^n Wk
设置 Mglobal ← Waverage 的权重
Send(Mglobal)
过程 节点()
D ← Local 数据集被划分为小数据集 dn
Mglobal = 接收(全局模型)
for 所有 K 中的每个节点并行 do
训练 Mglobal 使用它们各自的数据集 dn
W权重 = W权重 − η ∆l(W权重, dn)
Wupdated_weight ← Wweight
发送权重(Wupdated_weight)
第四节. 所提出的方法
在所提出的方法中,我们开发了一种梯度过滤协议,该协议利用聚类和基于奖励的算法来过滤来自攻击者的梯度。我们所提出的过滤协议如图1所示。为了使读者更清晰地了解所提出的方法,我们借助以下章节详细讨论了我们的架构。
A. 梯度聚类
在我们基于聚类的方法中,我们将参与联邦训练的客户端上传的梯度划分为不同的簇。创建不同的簇有助于识别偏离原始梯度的异常梯度。在联邦训练中,如果没有攻击者,则大多数情况下仅存在一个簇,该簇代表来自良性客户端的梯度。然而,在对抗环境中,这些簇可能多于一个,这取决于攻击者在联邦训练过程中向全局模型注入的梯度幅值的随机性。我们的假设基于这样一个事实:如果存在多个簇,则在联邦训练过程中很可能存在对抗者。第六节中呈现的结果证明了我们的这一假设。
为了对梯度进行聚类,我们使用了K均值聚类算法[16]。K均值聚类是一种无监督学习算法,其主要思想是找到有意义的簇的数量,即K。K均值算法分为两个阶段运行。在第一阶段,将邻近数据集分配给质心;在第二阶段,通过计算新的位置来重新定位同一质心。该过程持续进行,直到没有数据点可以重新分配给新的质心为止。设{(x1, y1),(x2, y2),(x3,y3),......,(xm,ym)}为未标记的梯度,其中xi ∈ Rd,Rd 表示数据集的d维向量。令K为簇数,质心为 μ1,μ2,....,μk。初始时,所有质心在XY坐标中随机初始化。每个质心使用公式1计算其邻近梯度xi与质心 μk之间的欧几里得距离。在公式1中,c(i)是簇的索引(1,2,…,K)。
$$
c(i) = \min || x^{(i)} - \mu_k ||^2 \quad (1)
$$
在计算距离时,主要思路是最小化代价函数 J,其由公式 2 表示。
$$
J(c(1),......,c(m), \mu_1,.....,\mu_k) = \frac{1}{m} \sum_{i=1}^{m} || x^{(i)} - \mu_k ||^2 \quad (2)
$$
一旦将 x(i) 的梯度分配给其最近的聚类中心 μk,就会计算分配给聚类中心 μk 的梯度位置的均值,即 μcenter,其由 (x) 给出。如算法所述,在无攻击者的联邦训练中通常只发现一个簇。然而,当存在攻击者时,簇的数量可能会增加。设 Di 和 Di’ 分别表示良性客户端和对抗者客户端的梯度簇,则它们的相异性函数由公式3给出。
$$
Δ(D_i, D_i’) = \sum_{j=1}^{L} Δ_j(D_i, D_i’) \quad (3)
$$
算法2。聚类与奖励算法
过程 聚类()
正常簇 = 1
对于 所有 每个 轮次 在训练轮次 执行:
所有梯度 = 获取梯度()
对于 所有 每个 梯度 在所有梯度 执行:
簇 = 计算簇()
如果 簇 > 正常簇
对抗者 = 获取对抗者节点
良性节点 = 获取良性节点
否则
良性节点 = 获取良性节点
过程 奖励()
客户端评分列表 = []
对于 所有 每个客户端 在对抗者和良性节点 执行:
如果 客户端是对抗者 执行:
客户端评分列表[客户端] = 负值
否则
客户端评分列表[客户端] = 正值
过程 淘汰()
对于 所有 每个 客户端评分, 客户端ID 在客户端列表 执行:
如果 客户端评分 > 阈值
淘汰客户端(客户端ID)
当攻击者参与联邦训练时,差异值会变得非常高,因为对抗者注入的梯度幅值远高于或低于原始梯度。高差异性评分会导致形成多个簇。簇的形成提供了关于对抗者节点ID、IP地址和地理位置的信息。在我们的实验评估中,我们仅提取了对抗者的节点ID。
B. 奖励与淘汰客户端
一旦对抗者的节点ID和良性客户端被识别后,如算法2所述,良性客户端将获得正分,而对抗者将获得负分。我们设定了负分的阈值,一旦有任何客户端的分数超过该阈值分数,即认定其为对抗者。在联邦训练中,识别永久对手并将其剔除非常重要,因为如果不剔除这些对抗者,客户端需要多轮次才能使模型收敛。剔除对抗者可以加快全局模型的收敛速度,第六节的实验结果证明了这一理论。
V. 实验
我们的实验是在一台配备有3.4GHz时钟频率的酷睿i5处理器、8GB内存和2GB显卡的机器上进行的。我们使用Python实现了完整的联邦机器学习模型以及所提出的方法。我们采用NSL‐KDD数据集构建基于联邦机器学习的入侵检测系统(IDS),并验证我们的方法。构建入侵检测系统的初衷是观察对抗者在联邦训练过程中通过污染梯度对入侵检测系统的检测能力所产生的影响。
NSL‐KDD数据集中包含125,973条记录,位于 KDDTrain+文件[17]中。我们将该文件中的记录分配给我们的十个参与客户端。我们仅选择了十个参与客户端;然而,在现实中,参与联邦训练的对抗者数量可达数百万。数据分布以非独立同分布(Non‐IID)方式进行,如表I所示。
| 客户端 | 攻击类型 | 实例数量 |
|---|---|---|
| 客户端_1 | neptune、smurf | 40466 |
| 客户端_2 | land、teardrop | 6107 |
| 客户端_3 | pod, back | 6315 |
| 客户端_4 | 端口扫描, nmap | 8938 |
| 客户端_5 | IP扫描, satan | 11135 |
| 客户端_6 | Imap,warezmaster | 5420 |
| 客户端_7 | ftp写入,猜测密码 | 5442 |
| 客户端_8 | 多跳,间谍 | 5402 |
| 客户端_9 | phf,盗版客户端,缓冲区溢出 | 6135 |
| 客户端_10 |
加载模块, perl
根工具包 | 5411 |
为了使读者清楚了解梯度投毒攻击在联邦训练中的影响,我们通过注入与原始梯度幅值差异较大的梯度发起了攻击。对抗者可以通过手动注入虚假梯度,或通过添加某种噪声机制[18]来实施联邦训练的投毒。在本例中,我们使用了拉普拉斯噪声对梯度添加噪声。我们采用了IBM开发的 Diffprivlib库来添加拉普拉斯噪声[19]。设Goriginal为原始梯度,则中毒梯度Gpoisoned由公式4得到。
$$
G_{\text{poisoned}} = \text{Lap}(G_{\text{original}} | \mu,b) = \frac{1}{2b} \exp\left(\frac{-|x-\mu|}{b}\right) \quad (4)
$$
在上述方程中,μ 表示分布的位置,其值为正值或负值,b是一个指数尺度参数,用于描述拉普拉斯噪声[18]的分布情况。我们设置b=0.005,以向梯度中添加较高水平的噪声。在实验中,我们假设攻击者可以在两种不同场景下发起攻击。在第一种场景中,攻击者可以控制客户端,使这些客户端表现为攻击者。在第二种场景中,攻击者自身可以通过大量物联网设备参与联邦训练。对于第一种场景,我们假设有40%的客户端为攻击者,在所有参与的客户端中对联邦训练过程中的梯度进行投毒。在第二种场景中,攻击者很难收集到大量物联网设备来参与联邦训练,因此我们假设有20%的参与客户端为攻击者。我们所提出的算法部署在全局服务器上,用于过滤参与的对抗者,同时考虑到物联网设备的处理能力较低。所有计算均在服务器端完成,从而减少了客户端的计算需求。
VI. 结果与讨论
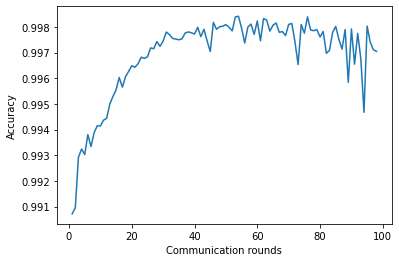
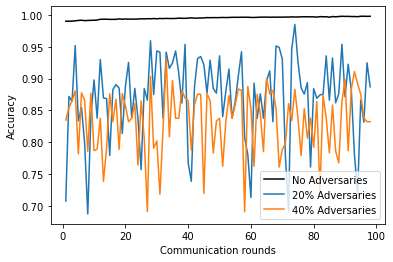
图2展示了在无对抗者的联邦训练中,全局模型准确率随通信轮次的变化情况。从图2可以看出,在无对抗者的联邦训练中,最大准确率可达99.8%。相比之下,图3显示了在存在对抗者的情况下,准确率显著下降至低至70%。通过比较图2和图3,我们可以发现,在没有对抗者的情况下,模型在约60轮内更快收敛,而在存在对抗者的情况下,模型在联邦训练期间需要更长的轮次才能收敛,即最多达80轮。在物联网环境中,我们的目标是开发一种基于机器学习的方法,其内存和功耗较低,但由于此类攻击需要更多轮次才能收敛,可能会大量消耗物联网设备的资源。在图3中,我们可以看到,当参与联邦训练的对抗者数量较多时,准确率的最大下降幅度比参与的对抗者数量较少时更为明显。
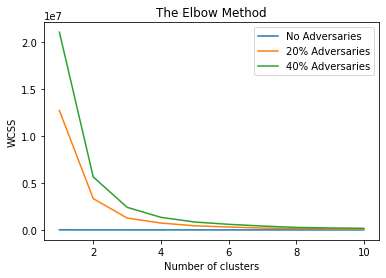
为了检测对抗者,我们将每轮来自参与者的梯度进行聚类。从图4可以看出,在没有对抗者的情况下,仅形成一个簇。这是因为在联邦训练中,当处理相同类型的机器学习问题时,我们获得的客户端权重具有相似的数据集。然而,当存在对抗者时,对抗者并不了解服务器与客户端之间交换的梯度权重,任何虚假梯度的注入都会导致簇数增加。在图4中,当存在20%和40%的对抗者时,可以观察到形成了两个簇,这明显证明了我们的假设。在图4中,Y轴上的WCSS分数是每个簇内观测值之间的方差之和。聚类问题在存在理想的聚类数量时,其WCSS分数会达到最优状态,此时在簇数增加时,WCSS分数不再降低。图4显示,该分数在两个簇时显著下降,在三个簇时中等程度下降,三个簇之后下降最小。因此,在我们的情况下,最优簇数为两个簇。然而,在对抗性联邦训练中,簇数可能超过两个,具体簇数取决于对抗者在联邦训练期间注入的梯度权重大小。
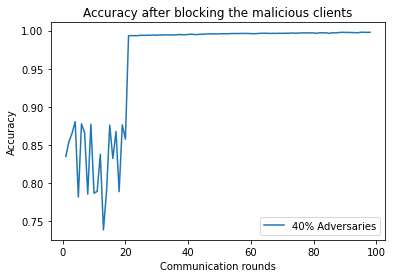
每一轮对梯度进行聚类有助于识别诚实与恶意客户端的身份。在我们的实验中,根据算法2,如果某个客户端超过了负奖励阈值,则该客户端将被完全排除在训练之外。我们设定阈值为20,从图5可以看出,当这40%的对抗者参与时,准确率有所下降,但一旦它们超过负奖励阈值,就会被彻底排除在训练之外。图5显示,在后续轮次中,客户端提高了联邦训练中全局模型的准确率。
随着簇数的增加,WCSS分数不再下降。图4显示,该分数在两个簇时大幅下降,在三个簇时中等程度下降,超过三个簇后下降幅度最小。因此,在我们的情况下,最优簇数为两个簇。然而,在对抗性联邦训练中,可能存在多于两个簇的情况。簇的数量取决于对抗者在联邦训练期间注入的梯度权重大小。
每一轮都有助于识别诚实与恶意客户端的身份。在我们的实验中,根据算法2,如果某个客户端超过了负奖励阈值,则会完全从训练中剔除。我们将该阈值分数设置为20,从图5可以看出,当这40%的对抗者参与时,准确率有所下降,但一旦他们超过负奖励阈值,就会被彻底排除在训练之外。图5显示,在后续轮次中剔除这些客户端后,全局准确率得到了提升。
我们的梯度过滤协议在服务器端运行,不需要客户端提供额外的处理能力。这使得我们的协议非常适合物联网设备。此外,与作者在其基于区块链的梯度认证协议[14,15]中描述的不同,我们的协议无需与任何额外的服务器进行交互以实现梯度认证。与外部服务器之间的最少交互次数减少了物联网设备的带宽消耗。
VII. 结论
本文讨论了基于无监督聚类算法的方法在基于联邦机器学习的物联网环境中检测对抗者的作用。通过实验结果我们得出结论:对抗者的存在会严重损害全局模型准确率,并可能占用物联网设备中的大量资源。考虑到物联网设备的资源受限特性,我们设计了高效的梯度过滤协议,用于检测并消除对抗者。在未来,我们希望将梯度过滤协议与一些适用于物联网设备的复杂深度学习算法相结合。


















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









