



今有 2017-2018 年每个季度的每股指标数据,共22720条数据记录,数据全部来源于CSMAR 数据库,部分数据记录及表结构见表7-16。其中,Stkcd为股票代码,Accper为截止日期,F090301B为归属于母公司每股的收益,F090601B 为每股营业收入,F091001A 为每股净资产,F091301A 为每股资本公积,FO91501A 为每收未分配利润,F091801B为每股经营活动产生的现金流量净额。问题如下:
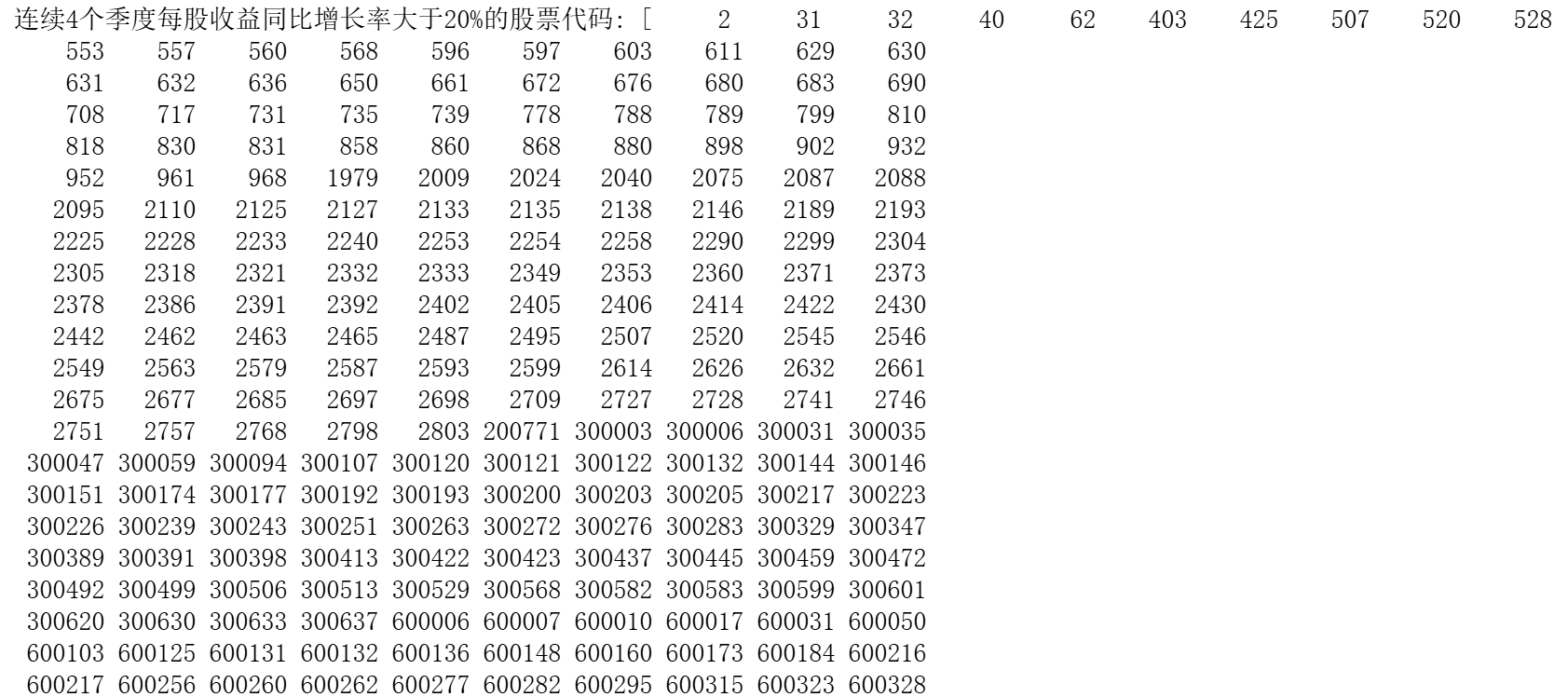
(1)对每个股票代码,计算每个季度每股收益同比增长率,并找出连续4个季度每股收
盗间比增长率大于20%的股票代码。
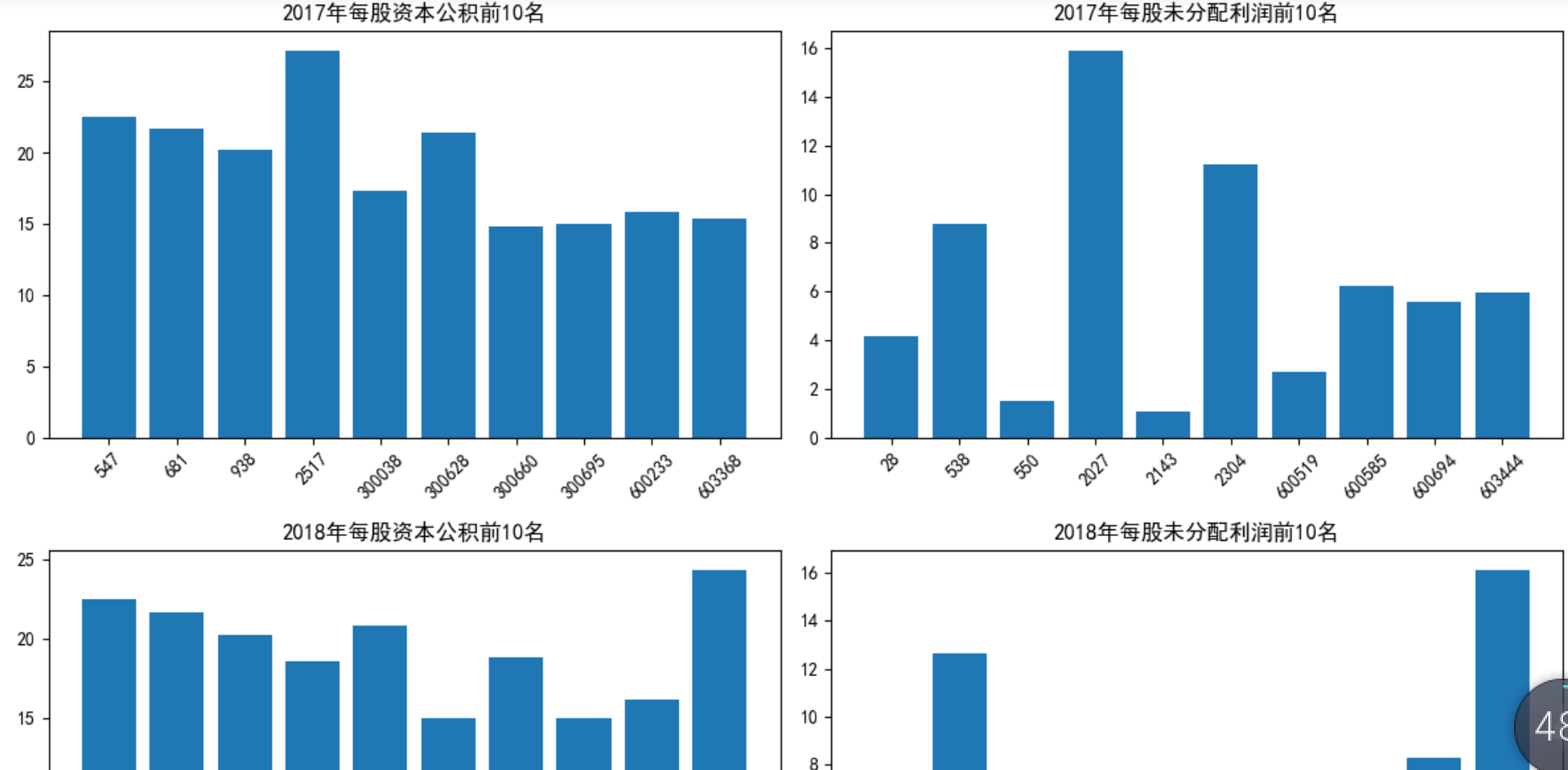
(2)找出2017年、2018年每股资本公积和每股未分配利润最大的10只股票代码,并通
过柱状图、子图的方法可视化展现出来。
(3)取2018年的数据,对以上6个指标做主成分分析,要求提取信息占比在95%以上,
并写出每个主成分的表达式,说明其主成分的意义。
(4)基于第(3)步提取的主成分进行K-均值聚类分析,并获取聚类中心。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
# 读取数据
data = pd.read_excel('data.xlsx')
# 将Accper列转换为日期格式
data['Accper'] = pd.to_datetime(data['Accper'])
# 对每个股票代码计算每股收益同比增长率
data['YoY_Growth'] = data.groupby('Stkcd')['F090301B'].pct_change(4) * 100
# 找出连续4个季度每股收益同比增长率大于20%的股票代码
result1 = data.groupby('Stkcd').filter(lambda x: (x['YoY_Growth'] > 20).rolling(4).sum().max() == 4)['Stkcd'].unique()
print("连续4个季度每股收益同比增长率大于20%的股票代码:", result1)
import matplotlib.pyplot as plt
# 找出2017年、2018年每股资本公积和每股未分配利润最大的10只股票代码
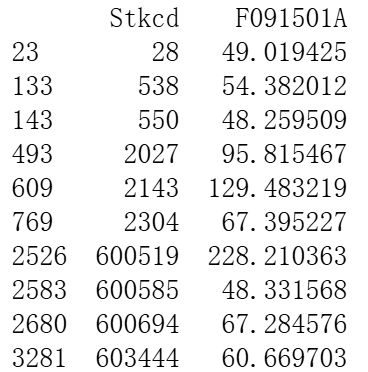
top_2017_f091301a = data[data['Accper'].dt.year == 2017].drop_duplicates(subset='Stkcd').nlargest(10, 'F091301A').sort_values(by='Stkcd')
top_2017_f091501a = data[data['Accper'].dt.year == 2017].groupby('Stkcd')['F091501A'].sum().reset_index().nlargest(10, 'F091501A').sort_values(by='Stkcd')
top_2018_f091301a = data[data['Accper'].dt.year == 2018].drop_duplicates(subset='Stkcd').nlargest(10, 'F091301A').sort_values(by='Stkcd')
top_2018_f091501a = data[data['Accper'].dt.year == 2018].groupby('Stkcd')['F091501A'].sum().reset_index().nlargest(10, 'F091501A').sort_values(by='Stkcd')
print(top_2017_f091501a)
# 可视化
plt.rcParams['font.family'] = 'SimHei' # 使用黑体字体,不同系统支持的中文字体可能不同
plt.rcParams['axes.unicode_minus'] = False
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 2017年每股资本公积
axes[0, 0].bar(top_2017_f091301a['Stkcd'].astype(str), top_2017_f091301a['F091301A'])
axes[0, 0].set_title('2017年每股资本公积前10名')
axes[0, 0].tick_params(axis='x', rotation=45)
# 2017年每股未分配利润
axes[0, 1].bar(top_2017_f091501a['Stkcd'].astype(str), top_2017_f091301a['F091501A'])
axes[0, 1].set_title('2017年每股未分配利润前10名')
axes[0, 1].tick_params(axis='x', rotation=45)
# 2018年每股资本公积
axes[1, 0].bar(top_2018_f091301a['Stkcd'].astype(str), top_2018_f091301a['F091301A'])
axes[1, 0].set_title('2018年每股资本公积前10名')
axes[1, 0].tick_params(axis='x', rotation=45)
# 2018年每股未分配利润
axes[1, 1].bar(top_2018_f091501a['Stkcd'].astype(str), top_2018_f091301a['F091501A'])
axes[1, 1].set_title('2018年每股未分配利润前10名')
axes[1, 1].tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()
from sklearn.decomposition import PCA
import numpy as np
# 取2018年的数据
data_2018 = data[data['Accper'].dt.year == 2018]
features = ['F090301B', 'F090601B', 'F091001A', 'F091301A', 'F091501A', 'F091801B']
X = pd.DataFrame(data_2018[features].values)
X = X.fillna(X.mean())
# 主成分分析
pca = PCA()
pca.fit(X)
# 找出信息占比在95%以上的主成分
cumulative_variance = np.cumsum(pca.explained_variance_ratio_)
n_components = np.argmax(cumulative_variance >= 0.95) + 1
# 重新拟合并提取主成分
pca = PCA(n_components=n_components)
pca.fit(X)
# 打印每个主成分的表达式
for i, comp in enumerate(pca.components_):
print(f"主成分{i+1}的表达式: {' + '.join([f'{coef:.4f}*{feat}' for coef, feat in zip(comp, features)])}")
# 解释主成分的意义
print("主成分的意义:")
for i in range(n_components):
print(f"主成分{i+1}: 解释方差比: {pca.explained_variance_ratio_[i]:.4f}")

from sklearn.cluster import KMeans
# 基于提取的主成分进行K-均值聚类分析
X_pca = pca.transform(X)
kmeans = KMeans(n_clusters=3, random_state=0).fit(X_pca)
# 获取聚类中心
cluster_centers = kmeans.cluster_centers_
print("聚类中心:", cluster_centers)
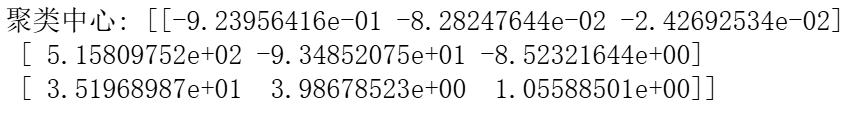


















 2102
2102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









