




什么是提示技术?
提示技术是实现提示工程目标的具体技术手段,是提示工程中的“工具库”。
什么又是提示工程?
提示工程是指通过设计、优化和迭代输入到大语言模型(LLM)的提示(Prompt),系统性提升模型输出质量(如相关性、准确性、可控性)的实践领域。它是一个覆盖全流程的方法论,包括:
- 明确目标任务(如生成教学内容、问答、翻译);
- 设计提示结构(如指令、上下文、示例);
- 选择模型与参数(如温度、top_p);
- 验证与迭代(根据输出调整提示)。
其核心是“通过工程化方法控制大语言模型(LLM)的行为”。
概念
检索增强生成(Retrieval-augmented Generation,RAG),是当下热门的大语言模型前沿技术之一,是提示技术其中的一种。
检索增强生成,结合了大语言模型和信息检索技术。具体来说,当大模型需要生成文本或回答问题时,它会先从一个庞大的文档集合中检索出相关的信息,然后利用这些线索到的信息来指导文本的生成,从而提高预测的质量和准确性。
与传统的 LLM 对比优势:
- 减少幻觉:通过外部知识验证生成内容的准确性;
- 动态更新:无需重新训练模型即可更新知识库;
- 领域适配:通过定制化知识库快速适配垂直领域(如金融、医疗、法律等)。
概念图解
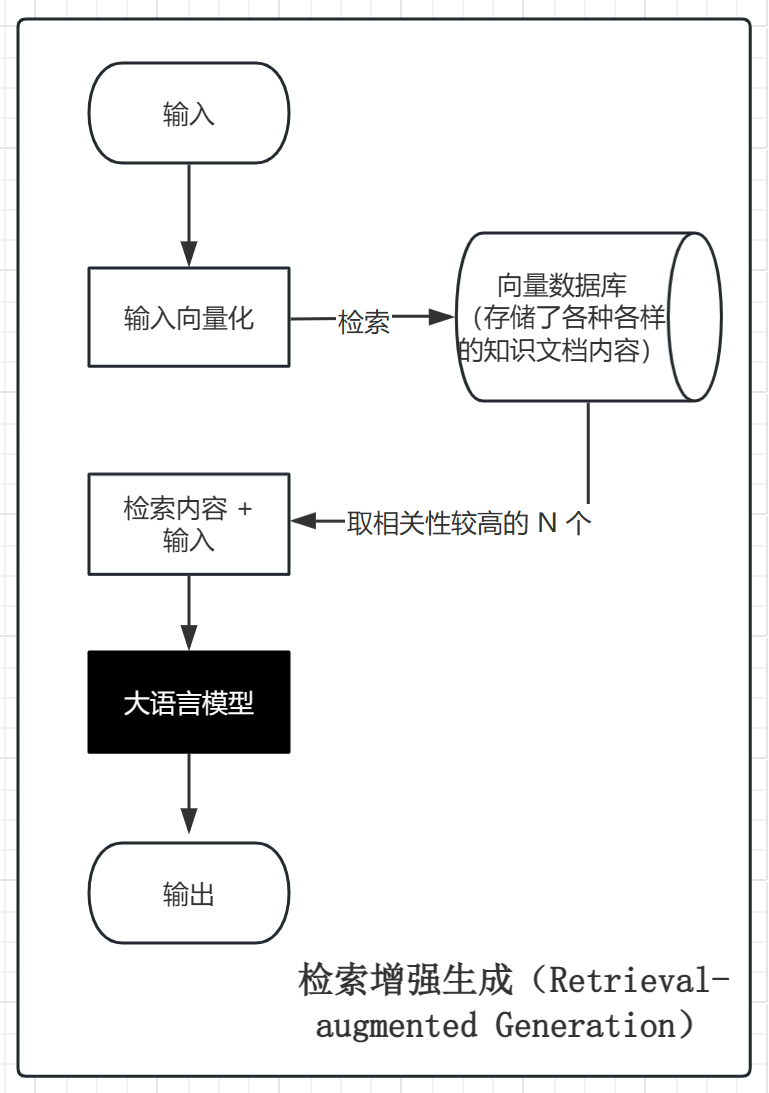
应用场景
- 智能客服与企业问答系统;
- 个性化推荐与内容生成;
- 法律咨询;(为非专业人士提供法基本的法律咨询服务,比如合同审查、法律解读等)
- 医疗健康咨询;(提供基础的医疗健康建议,如挂诊指导、症状查询、疾病预防等)
- ……
案例实操
使用工具:扣子
实现方式:扣子工作流
完整工作流如下:
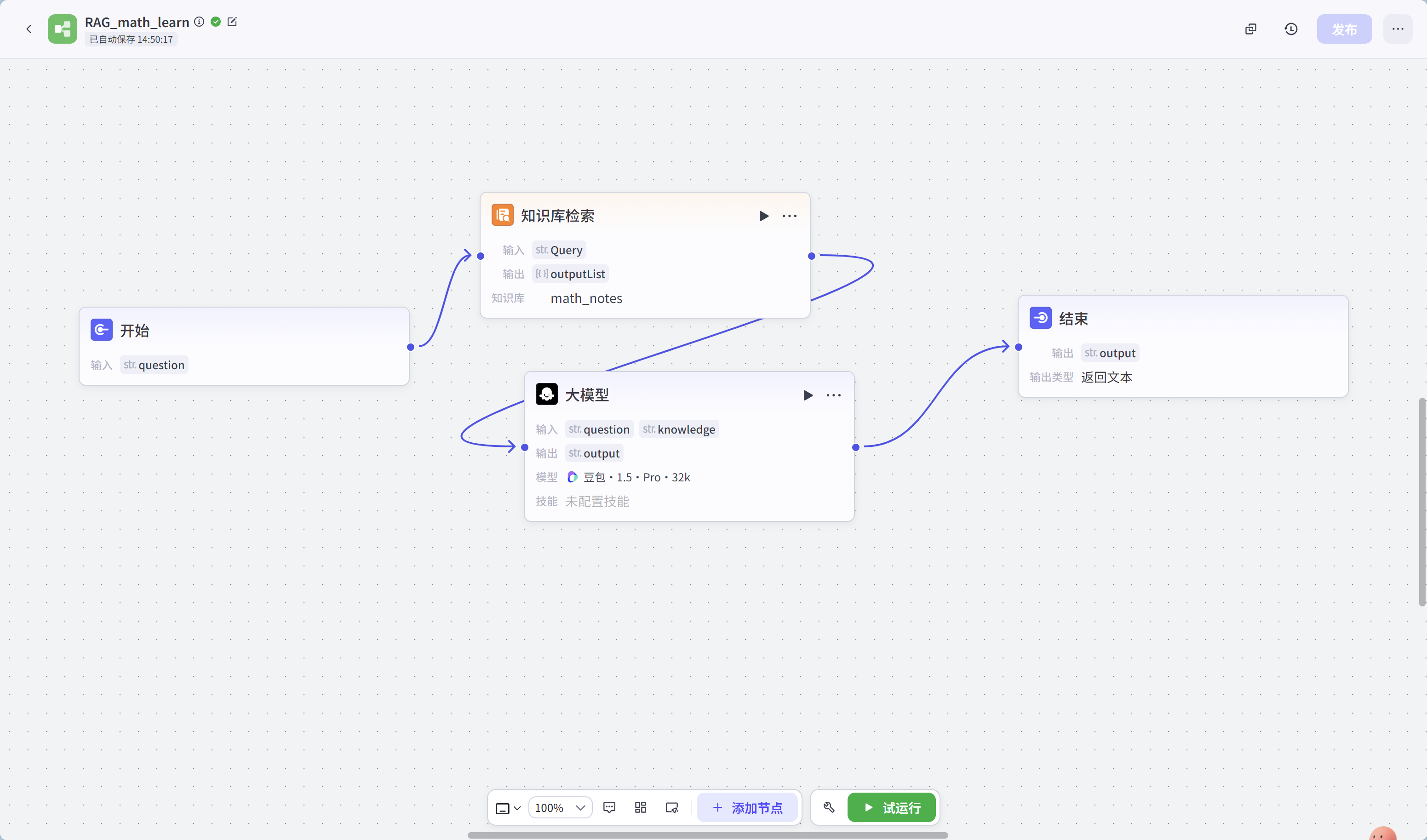
工作流各节点配置信息:
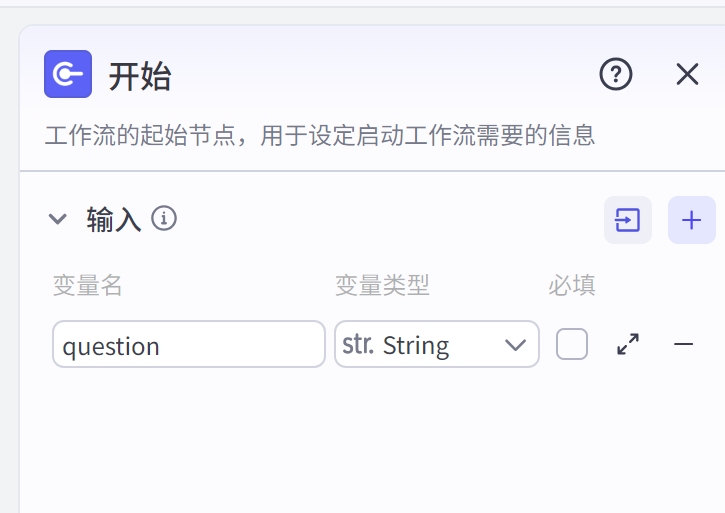
- 开始节点:
- 知识库检索节点:(知识库创建,可参考下文【创建知识库的过程:】)
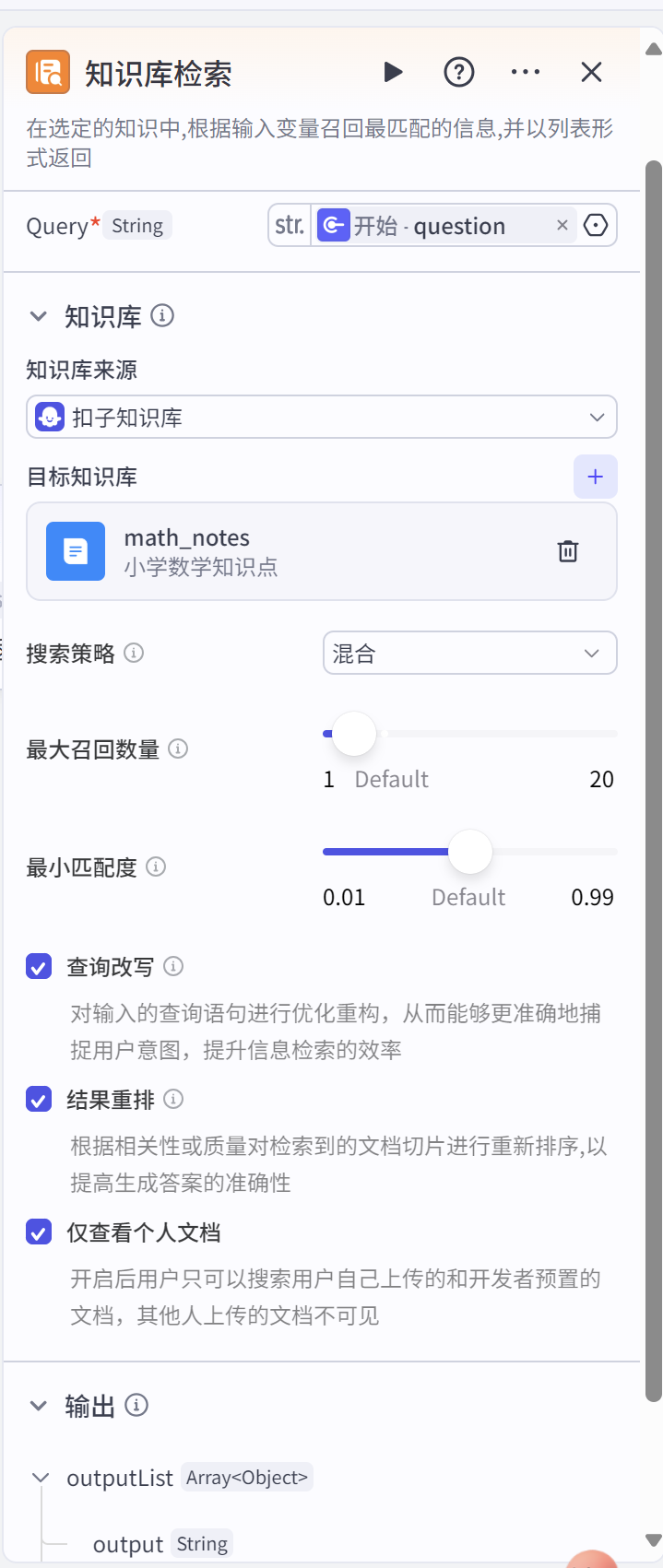
里面的参考什么意思,扣子有详细介绍,可点击对应配置项旁边的灰色小图标查看。
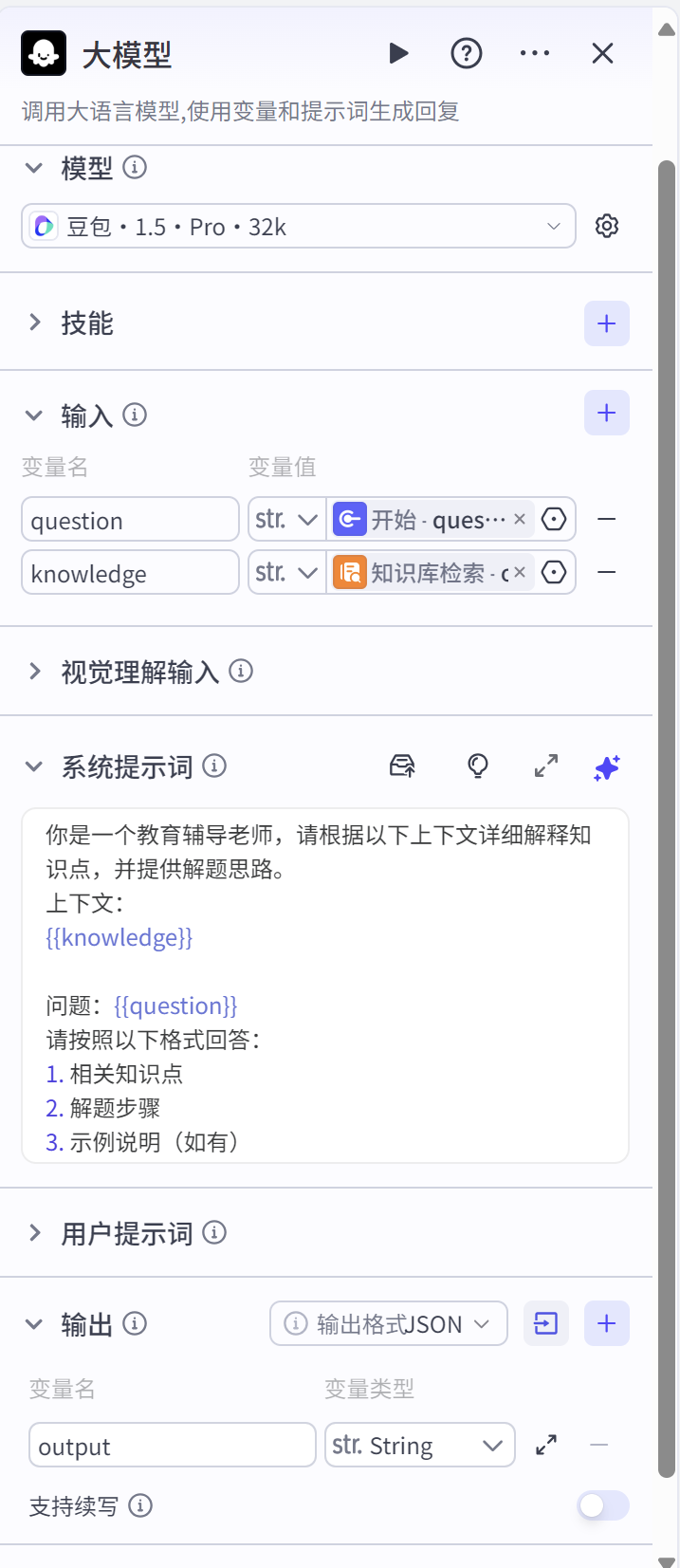
- 大模型节点:
- 结束节点:
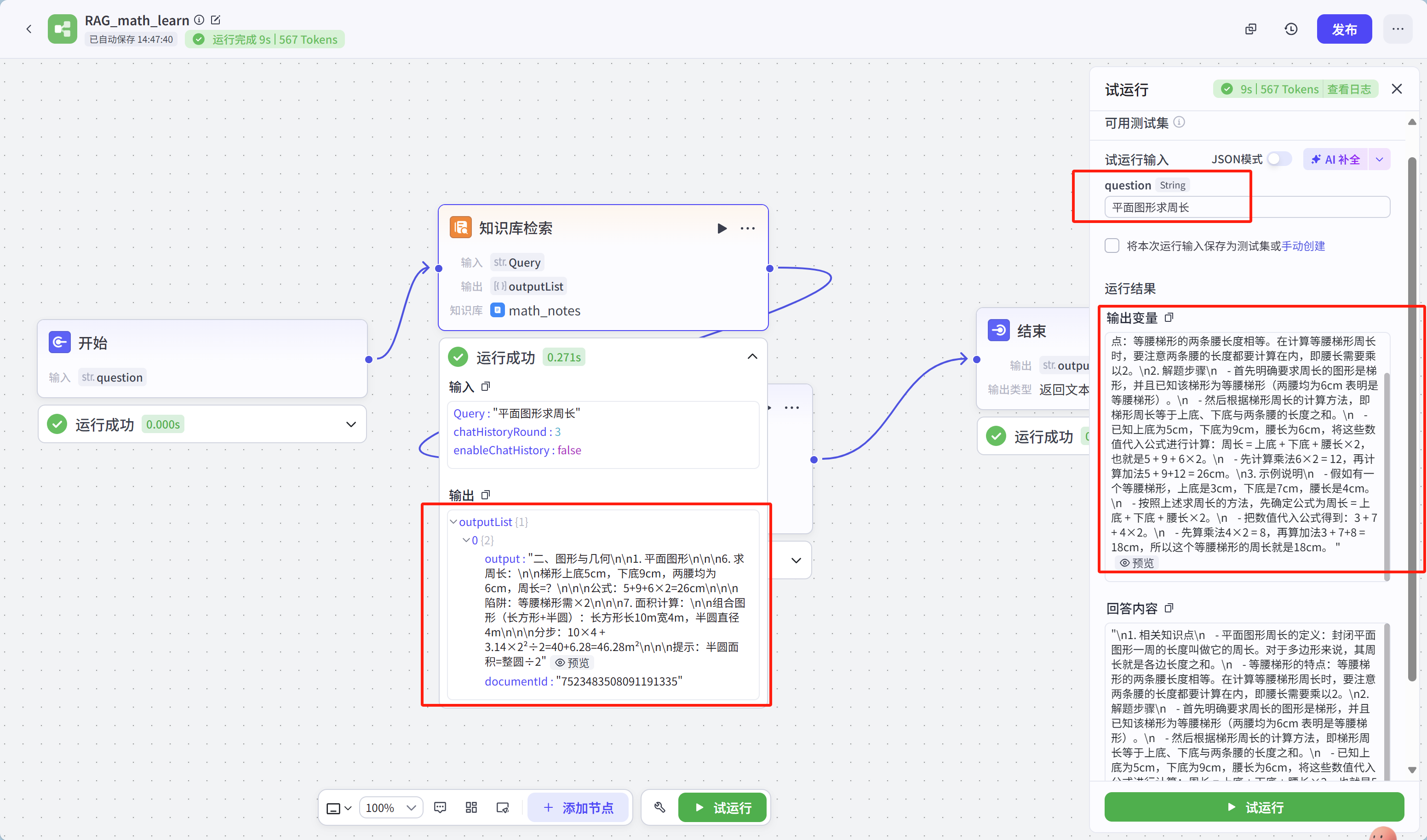
运行结果如下:
创建知识库的过程:
在使用知识库的时候,发现没创建,可以在选择知识库界面先创建,如下:
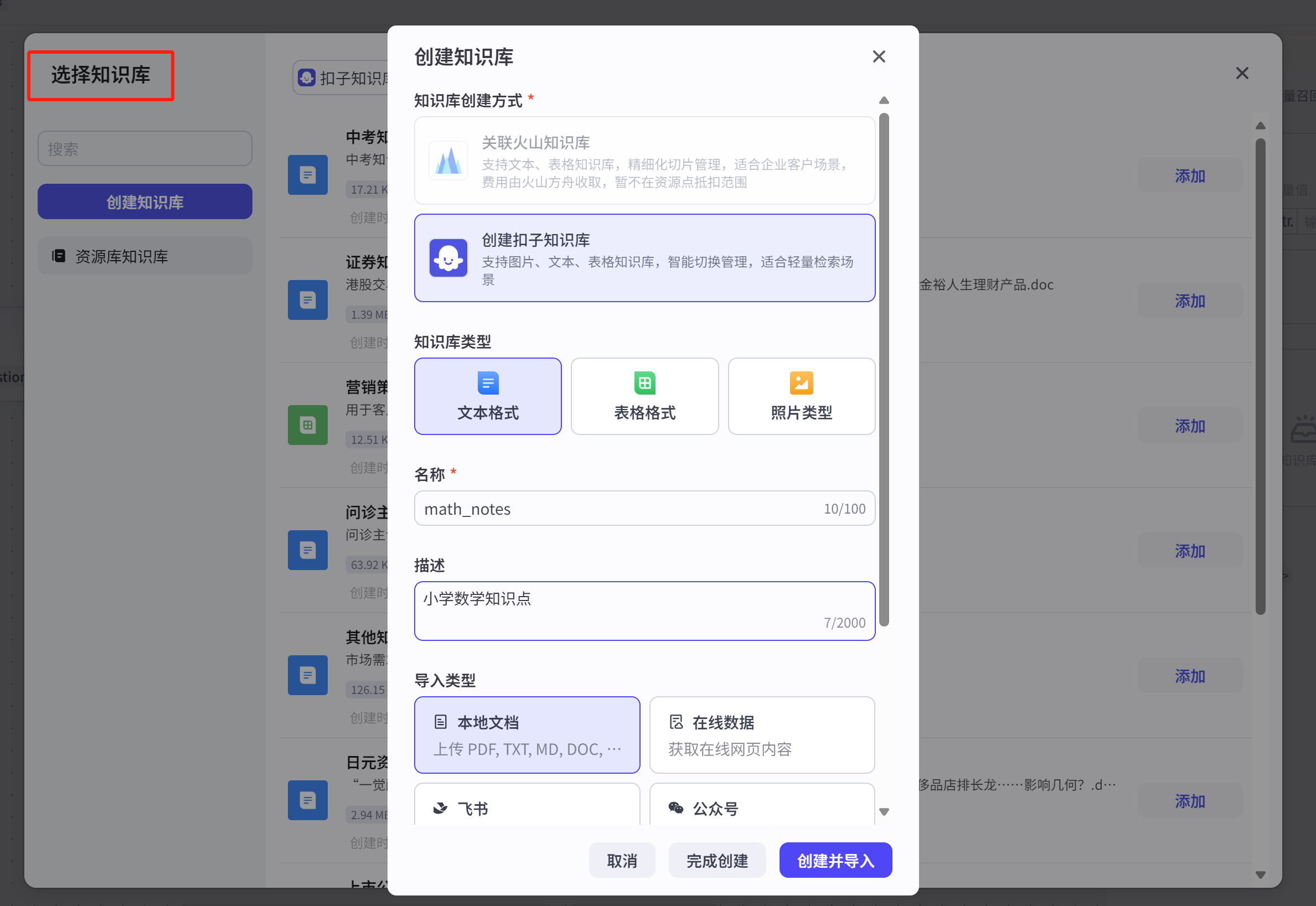
点击【创建并导入】,并上传文件:
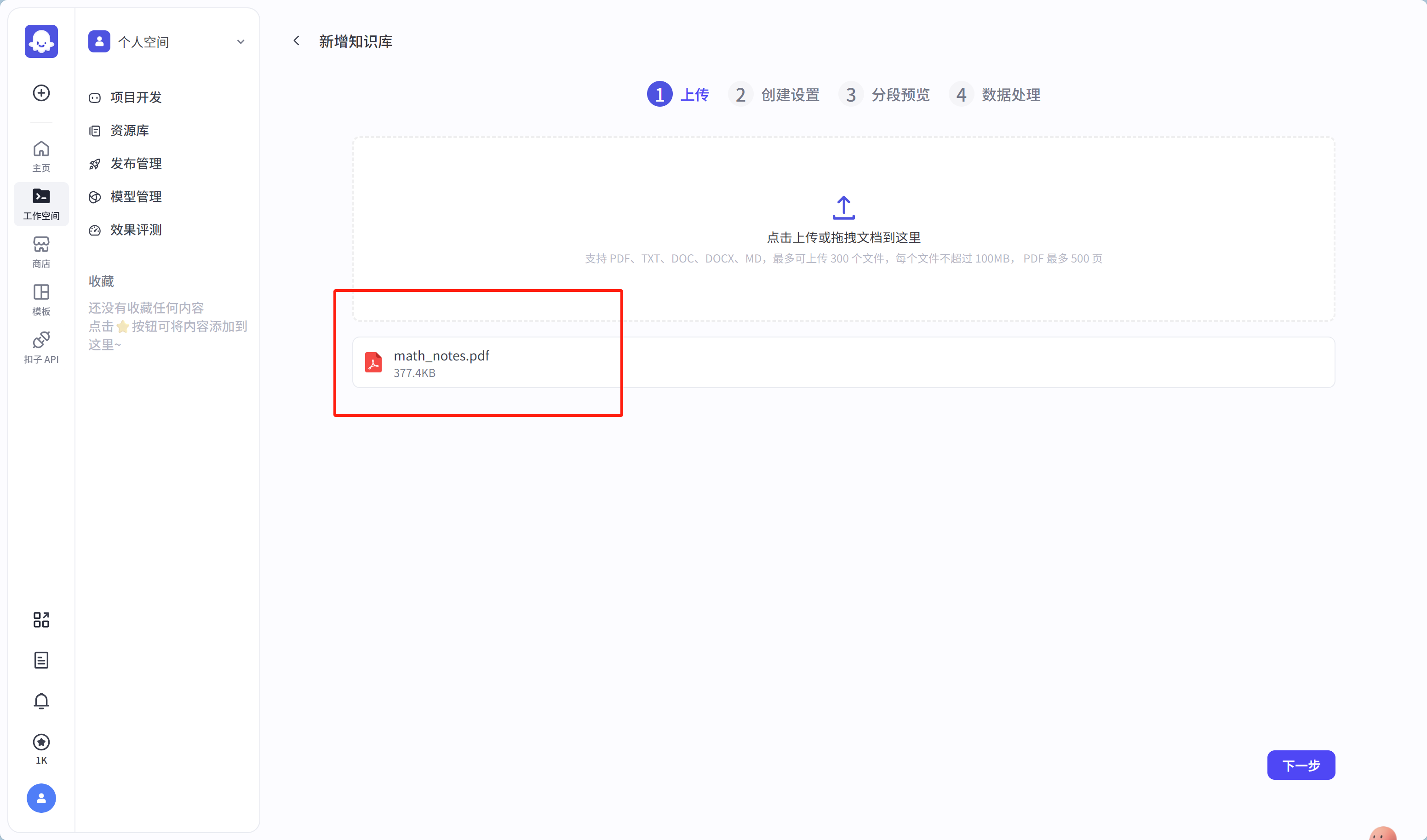
点击【下一步】,进入创建设置,这步最为关键,根据文档的特征,以及实际需求来考虑怎么切分文档的内容(图中的【分段策略】),如同你做菜要切土豆一样,是切丝呢,还是切块呢,亦或者是切条呢,这都取决于你要做什么菜式。
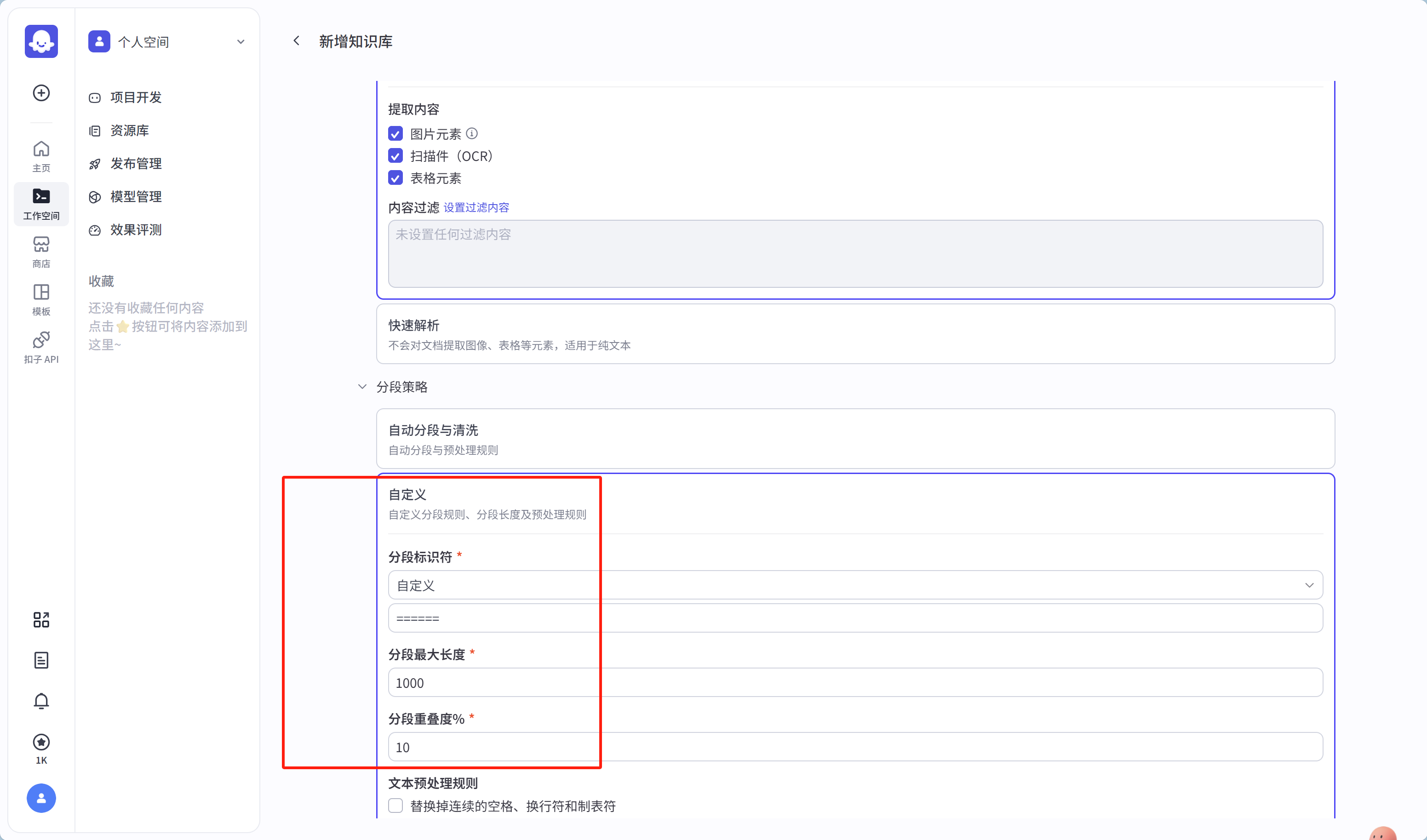
(这里选择了的分段标识符是自定义,是因为文档我根据需求处理了一下,实际的开发中人工处理文档是常见的一种方式)
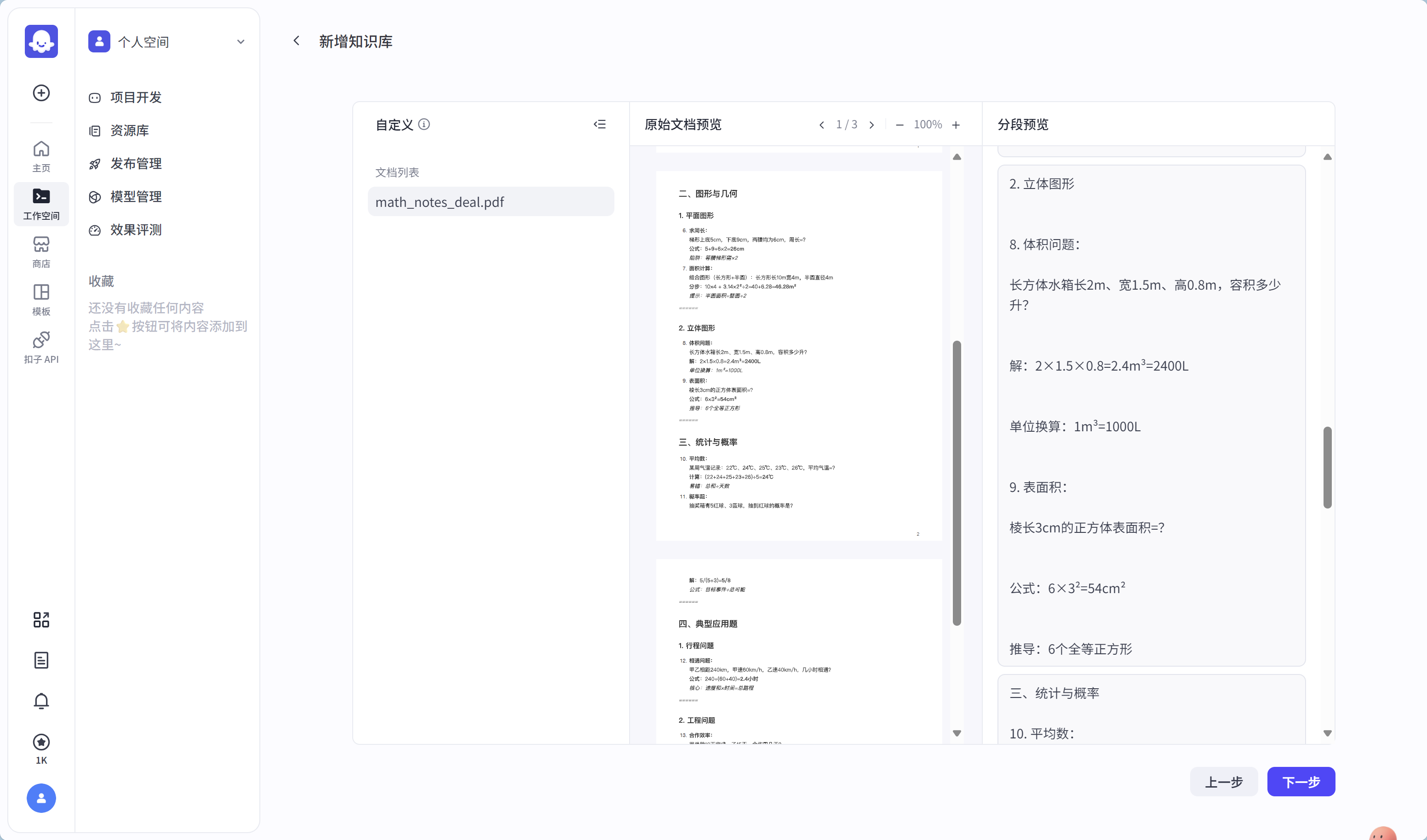
点击【下一步】,就可以看到切分后的文档效果了,若觉得不合适返回上一步继续调整策略
若切分效果符合,点击【下一步】进行文档保存,可以不用等到保存完毕,就可以点【确认】
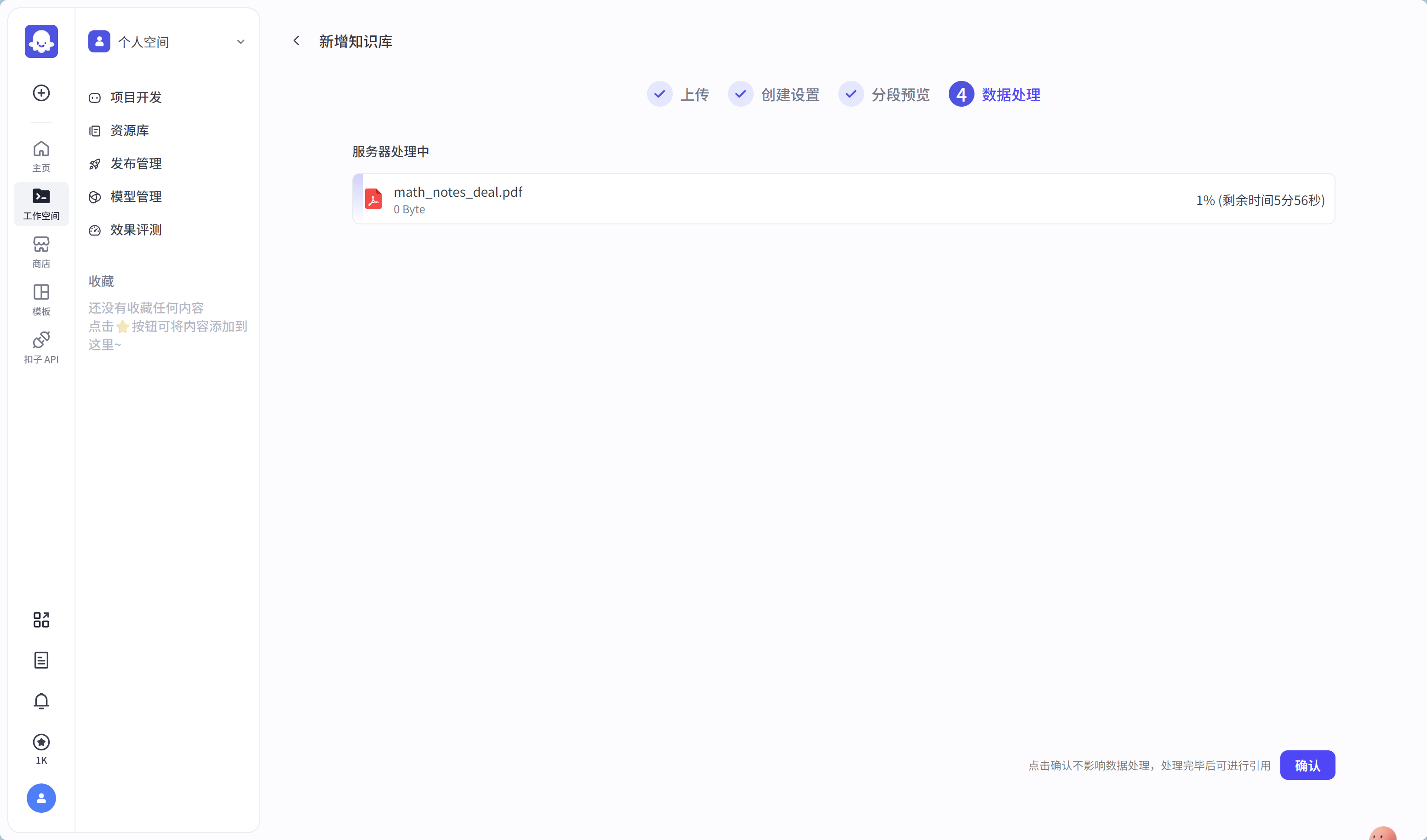
至此,知识库创建完成。
大家若有编程基础的话,可以参考下面的代码案例来实现与体验不同场景下使用检索增强生成(RAG)提示。
代码实现检索增强生成提示
技术栈:Python;LangChain
代码实现引用包导入:
pip install langchain_community==0.3.26;
pip install langchain==0.3.26;
代码结构:
- data 目录下的是要加载的知识文档,代码支持的文档格式有:pdf,txt, docx;
- RAG_Base.py,是代码文件,如下具体代码;
具体代码:
import os
# 加载环境变量
from dotenv import load_dotenv
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.chat_models import ChatZhipuAI
from langchain_community.document_loaders import PyPDFLoader, TextLoader, UnstructuredWordDocumentLoader
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_community.vectorstores import FAISS
load_dotenv()
api_key = os.getenv("ZHIPUAI_API_KEY")
# 加载教材文档
def load_educational_materials(data_dir):
documents = []
for file in os.listdir(data_dir):
path = os.path.join(data_dir, file)
if file.endswith(".pdf"):
loader = PyPDFLoader(path)
elif file.endswith(".txt"):
loader = TextLoader(path, encoding="utf-8")
elif file.endswith(".docx"):
loader = UnstructuredWordDocumentLoader(path)
else:
continue
documents.extend(loader.load())
return documents
# 分割文本
def split_documents(documents):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=50)
return text_splitter.split_documents(documents)
# 构建向量数据库
def build_vectorstore(splits, persist_dir="vectorstore"):
embeddings = ZhipuAIEmbeddings(model="embedding-3", api_key=api_key)
vectorstore = FAISS.from_documents(splits, embeddings)
vectorstore.save_local(persist_dir)
return vectorstore
# QA 链
def create_education_qa_chain(vectorstore):
llm = ChatZhipuAI(model="glm-4", temperature=0.7, api_key=api_key)
prompt_template = """你是一个教育辅导老师,请根据以下上下文详细解释知识点,并提供解题思路:
{context}
问题:{question}
请按照以下格式回答:
1. 相关知识点
2. 解题步骤
3. 示例说明(如有)
答案:"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(search_kwargs={"k": 4}),
chain_type_kwargs={"prompt": prompt},
return_source_documents=True
)
return qa_chain
# 主函数
def main():
data_dir = "data"
vectorstore_dir = "vectorstore"
print("正在加载教材文档...")
documents = load_educational_materials(data_dir)
splits = split_documents(documents)
if not os.path.exists(vectorstore_dir):
print("正在构建知识库...")
vectorstore = build_vectorstore(splits, vectorstore_dir)
else:
print("正在加载已有知识库...")
embeddings = ZhipuAIEmbeddings(model="embedding-3", api_key=api_key)
vectorstore = FAISS.load_local(vectorstore_dir, embeddings, allow_dangerous_deserialization=True)
print("初始化教育辅导模型...")
qa_chain = create_education_qa_chain(vectorstore)
print("\n欢迎使用 AI 教辅助手!请输入你的学习问题(输入 'exit' 退出):")
while True:
query = input("\n??问题:")
if query.lower() == "exit":
break
result = qa_chain.invoke({"query": query})
answer = result["result"]
sources = result.get("source_documents", [])
print("\n--回答如下:")
print(answer)
print("\n知识来源片段预览:")
for i, doc in enumerate(sources[:3]):
print(f"{i + 1}. ...{doc.page_content[:200]}...")
if __name__ == "__main__":
main()
总结与思考
相对于生成知识提示来说,检索增强生成提示技术是利用了检索技术来实现知识的获取,而生成知识提示还是依赖于大模型本身,同样会受制于大模型的知识瓶颈,RAG并不会,而且还可以理解为一种补充。
为此,可以从不同维度比较一下它们:
| 维度 | 生成知识提示 | 检索增强生成(RAG) |
| 核心思想 | 利用语言模型自身知识库生成答案或解释。 | 在生成前先检索外部知识,再结合其生成回答。 |
| 是否依赖外部数据源 | 否,完全依赖模型内部知识。 | 是,依赖外部文档库或知识库。 |
| 是否实时更新能力 | 否,受限于训练数据截止时间。 | 是,可接入最新信息(如新闻、政策)。 |
| 生成内容的准确性 | 中等,易产生幻觉或错误。 | 高,基于实际文档内容生成。 |
| 可解释性 | 低,无法追溯答案来源。 | 高,可展示引用文档片段。 |
| 提示设计复杂度 | 简单,直接给出问题即可。 | 较复杂,需构建检索流程 + 提示工程。 |
| 对模型依赖程度 | 高,模型知识决定输出质量。 | 中等,模型 + 检索结果共同影响输出。 |
| 资源消耗 | 低(仅调用LLM) | 高(需检索+向量匹配+生成) |
一句话总结:
生成知识提示适合处理通用知识和创意型任务,实现简单但存在幻觉风险;而 RAG 更适合需要高准确性和时效性的专业领域,虽然部署相对复杂,但具备更强的实用性和可解释性。
怎么选择它们呢?
| 你的需求 | 推荐技术 |
| 快速响应用户问题,不追求精确出处 | 生成知识提示 |
| 构建企业级知识库问答系统 | RAG |
| 需要引用权威资料、避免错误答案 | RAG |
| 进行创意写作、故事生成 | 生成知识提示 |
| 模型知识已足够满足任务需求 | 生成知识提示 |
| 任务依赖最新数据或专有文档 | RAG |
前面概念中提到,RAG 是当下热门的大语言模型前沿技术之一,又是为何呢?
从它本身的技术优势来看:
- 解决大语言模型现存问题:大语言模型存在知识更新滞后、易产生幻觉、对特定领域知识掌握不足等问题。RAG技术通过检索外部知识库,能获取最新、更准确的知识,减少模型幻觉,还可根据特定领域知识库定制,提升在特定领域的表现。
- 强大的功能优势:
- 利用外部知识:可引用大量信息,提供更深入、准确且有价值的答案,提高生成文本的可靠性。
- 数据更新及时:具备检索库的更新机制,无需重新训练模型就能实现知识的即时更新,适配对时效性要求高的应用。
- 回复具有解释性:答案直接来自检索库,用户可核实答案准确性,从信息来源获取支持,减少大模型的幻觉。
- 高度定制能力:能根据特定领域的知识库和prompt进行定制,快速具备该领域能力,广泛适用于多领域多场景。
- 安全和隐私管理:通过限制知识库权限实现安全控制,确保敏感信息不被泄露,提高数据安全性。
- 减少训练成本:可将大量数据直接更新到知识库实现知识更新,无需重新训练模型,更经济实惠。
除了上述技术本身的优势之外,我认为更重要的就是不少政府单位、高校、研究机构、企业等,它们都不愿意把自己核心的知识积累随意泄露出去,而这种技术能较好地满足它们使用LLM。因此,又回到了数据本身啊,不愧是新生产要素。
好了,到此。
提示技术系列,到此会暂告一段落。……
为了方便大家学习,这里给出专栏链接:https://blog.youkuaiyun.com/quf2zy/category_12995183.html
欢迎大家一起来学习与交流……


















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









