 计数排序详解:算法、步骤与代码实现
计数排序详解:算法、步骤与代码实现





算法思想
计数排序是一种非比较排序,又称为鸽巢原理,是对哈希直接定址法的变形应用。
操作步骤
- 统计相同元素出现次数;
- 根据统计的结果将序列回收到原来的序列中。
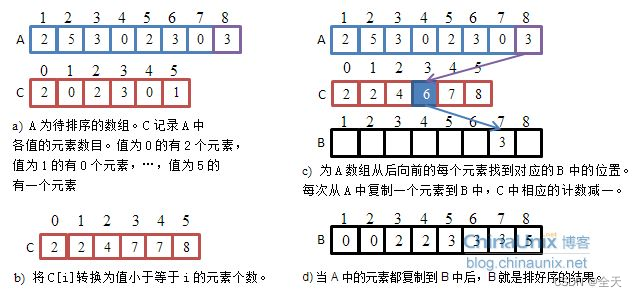
计数排序的特性总结
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,range))
- 空间复杂度:O(range)
- 稳定性:稳定
代码实现
#include<stdio.h>
#include<stdlib.h>
//时间复杂度 O(N+range)
//空间复杂度 O(range)
//适合范围集中的数据,只适合整型
void countSort(int* a, int n)//计数排序 -- 非比较排序
{
int maxArr = a[0], minArr = a[0];//1.求最大值和最小值
for (int i  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











