




 本文探讨了JDBC在操作MySQL数据库时的性能优化策略,包括批处理、限制查询结果集大小和使用索引,特别是普通索引和复合索引,以减少回表操作,提升查询速度。
本文探讨了JDBC在操作MySQL数据库时的性能优化策略,包括批处理、限制查询结果集大小和使用索引,特别是普通索引和复合索引,以减少回表操作,提升查询速度。
当我们在使用JDBC查询或操作mysql数据库中的数据时,每当有一条查询语句执行,JDBC便会与数据库建立一次连接,当我们的业务量较大时,频繁的与数据库建立连接,这会十分影响性能。
如何提升性能?
首先明确,mysql的返回结果机制是,我们查询多少,数据库便返回多少结果,当我们不慎要求返回了某个表的所有结果,可能在java中出现OutofMemory错误,因此我们先限制查询时一次的数目返回值.
PreparedStatement.setFetchSize(50);
mysql 中需要在连接参数中加入: useCursorFetch=true
批处理
倘若我们可以一次性先将所有需要执行的sql语句准备好,一同发往数据库进行执行操作,那么无疑可以大大减少与数据库建立连接的次数,这样便可以极大的提升性能。
JDBC实现批处理
PreparedStatement.addBatch() 加入批处理包
PreparedStatement.executeBatch() 把批处理包中所有sql,一次性发送给数据库服务器
同样,对于mysql需要通过连接参数,开启批处理功能,同限制返回参数一起给出:
jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&useCursorFetch
给出示例代码:
JDBC获取连接
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
/**
* jdbc工具类
* @author yihang
*/
public class JdbcUtil {
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
System.out.println("加载驱动失败");
}
}
/**
* 获取数据库连接
* @return 连接对象
*/
public static Connection getConnection() {
try {
Connection conn = conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&useCursorFetch", "root", "root");
return conn;
} catch (SQLException e) {
System.out.println("获取连接失败" + e.getMessage());
throw new RuntimeException(e);
}
}
}
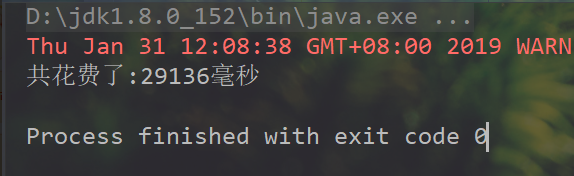
先是普通的插入操作,不使用批处理
try(Connection conn = JdbcUtils.getConnection()) {
PreparedStatement psmt = conn.prepareStatement("insert into big(name) values(?)");
long start = System.currentTimeMillis();
for (int i = 1; i <= 1000; i++) {
psmt.setString(1, "张" +i);
psmt.executeUpdate();
}
long end = System.currentTimeMillis();
System.out.println("共花费了:" +(end-start)+"毫秒");
} catch (SQLException e) {
e.printStackTrace();
}
try(Connection conn = JdbcUtils.getConnection()) {
PreparedStatement psmt = conn.prepareStatement("insert into big(name) values(?)");
long start = System.currentTimeMillis();
for (int i = 1; i <= 1000; i++) {
psmt.setString(1, "张" +i);
psmt.addBatch();
}
psmt.executeBatch();
long end = System.currentTimeMillis();
System.out.println("共花费了:" +(end-start)+"毫秒");
} catch (SQLException e) {
e.printStackTrace();
}
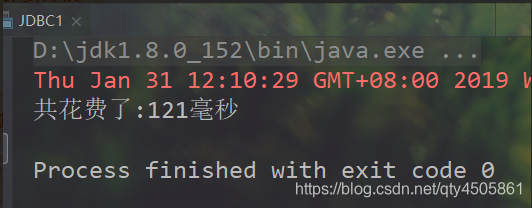
对比之下,批处理操作可以极大的减少程序运行的时空开销。
如何提升 “ 查询 ” 性能?
Mysql中索引有多种,我们常使用的主键,也是一种索引,且它是一种唯一性索引,我们这里使用一种另外的普通索引。这也是提升查询性能有效的方法。普通索引是对现有的数据进行排序,在排序的结果中搜索,效率会很高
普通索引的数据结构是:B+树
mysql中建立普通索引的语句是:
create index 索引名 on 表(列);
// 向 big 表中的 name 建立一个索引
create index idx_name on big(name);
B+树的数据结构如图所示:
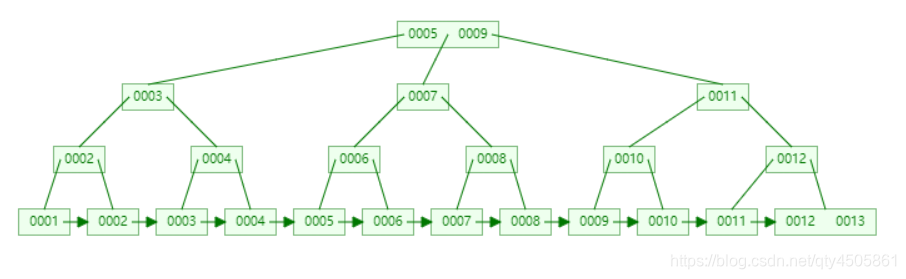 当表中数据建立起如上图所示的数据结构时,查询操作性能将会提升,不再当查询一个数据时便遍历整张表,根据索引值,即使有上千行的数据,只需要数层树即可完成查询
当表中数据建立起如上图所示的数据结构时,查询操作性能将会提升,不再当查询一个数据时便遍历整张表,根据索引值,即使有上千行的数据,只需要数层树即可完成查询
主键将该行的值都存放在叶子结点中,而普通索引只存储主键的值(如上图结点中的值),因此,查询时先查询普通索引,再查询主键
(这个图的结构有网站可以画,不止这一种数据结构,常见的很多可以快速制图,安利一下https://www.cs.usfca.edu/~galles/visualization/Algorithms.html)
回表的概念
先附上图
我们为big表中name列添加普通索引:
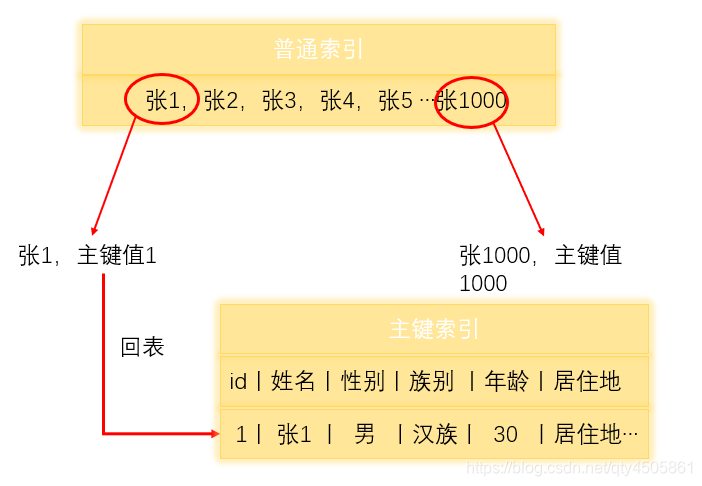
假如我们的查询语句是 select id from big where name = “张1”;
那么普通索引中其实已经得知了张1的主键值是1,而我们的需求是得知id值,id正是主键,所以普通索引中存在我们想要查询的值,那么此时不再去查询主键索引,我们说此时没有发生回表。假如语句查询的数据需要查询主键索引,比如我们需要得到张1的性别,年龄,居住地等信息,那么此时就发生回表操作。回表操作也会消耗性能,因此倘若可以建立复合索引的话,建议使用复合索引,最大程度的避免回表。
复合索引语句:
create index_namesex on big(name,sex);(先按name排序,name相同的再按sex排序)
说的简单些就是让普通索引尽可能有更丰富的值,这样可以避免去查询主键索引。
上述语句为姓名和性别同时建立索引,普通索引中拥有两个值,更大程度避免回表。
索引使用的注意事项:
- 使用了空间换时间,因为表是提前排序好的,那么排序结果的记录需要额外占用存储空间
- 查询性能的提升会影响增、删、改的性能,因此只有当查询业务远远大于其他业务时,建立索引才有实际意义
- null值不适合建立索引
- 区分度较低的列不适合建立索引,什么列区分度低?比如性别,什么列区分度高,比如id,比如姓名
- 避免回表,尽可能不要使用select * from 等语句以及建立复合索引

















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









