






 本文详细介绍了Hadoop HDFS的数据写入流程,包括节点间的距离计算和速度、安全的考量。在写入过程中,数据首先被写入内存的fsimage,随后记录到editlog。当editlog达到一定容量或时间点,将与fsimage合并并同步到Secondary NameNode。在读取数据时,Namenode根据元数据信息指引DataNode提供服务。Namenode的工作机制涉及到fsimage和editlog,fsimage存储静态元数据,editlog记录变更操作。在格式化后,新的fsimage和editlog被创建并加载到内存。
本文详细介绍了Hadoop HDFS的数据写入流程,包括节点间的距离计算和速度、安全的考量。在写入过程中,数据首先被写入内存的fsimage,随后记录到editlog。当editlog达到一定容量或时间点,将与fsimage合并并同步到Secondary NameNode。在读取数据时,Namenode根据元数据信息指引DataNode提供服务。Namenode的工作机制涉及到fsimage和editlog,fsimage存储静态元数据,editlog记录变更操作。在格式化后,新的fsimage和editlog被创建并加载到内存。
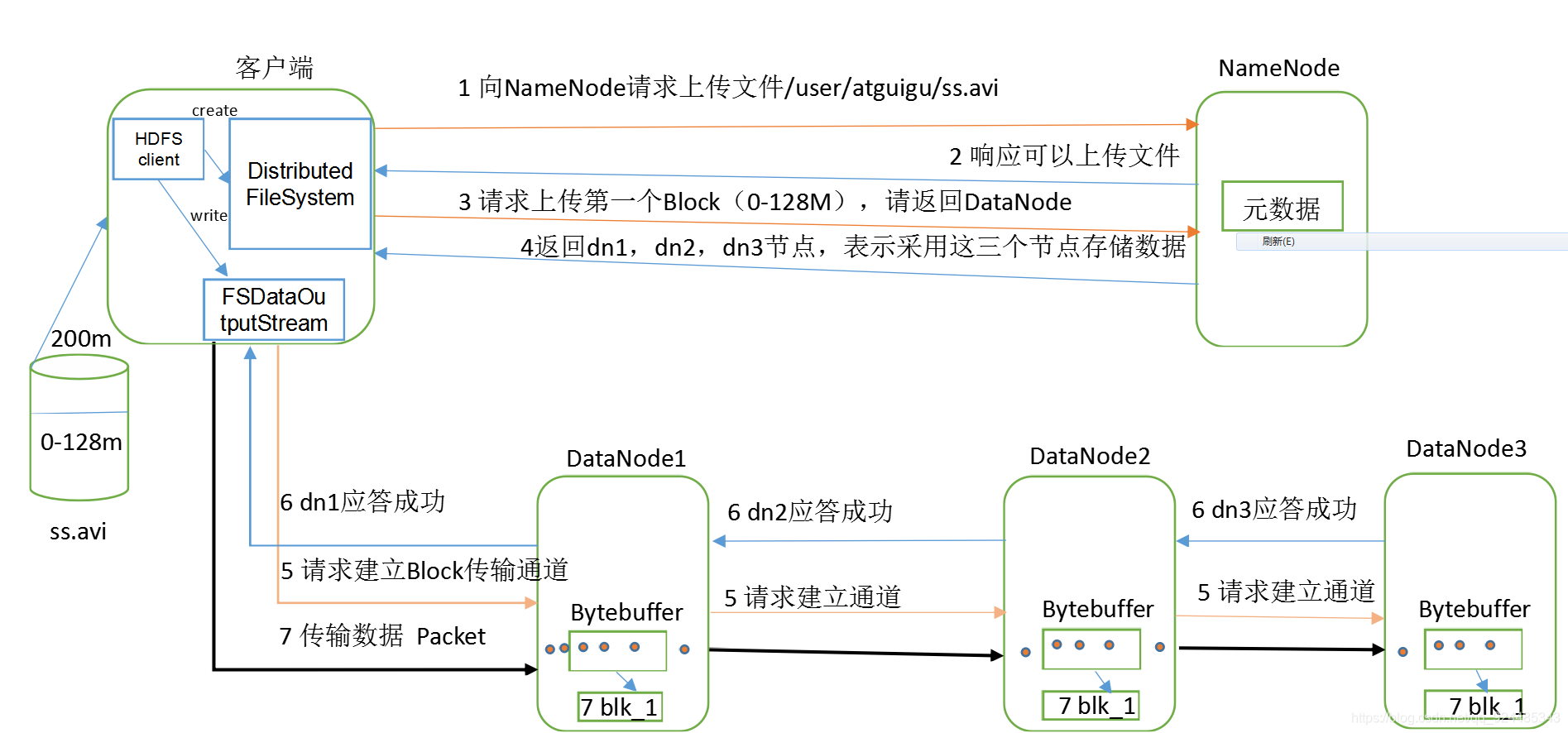
1.HDFS写数据流程
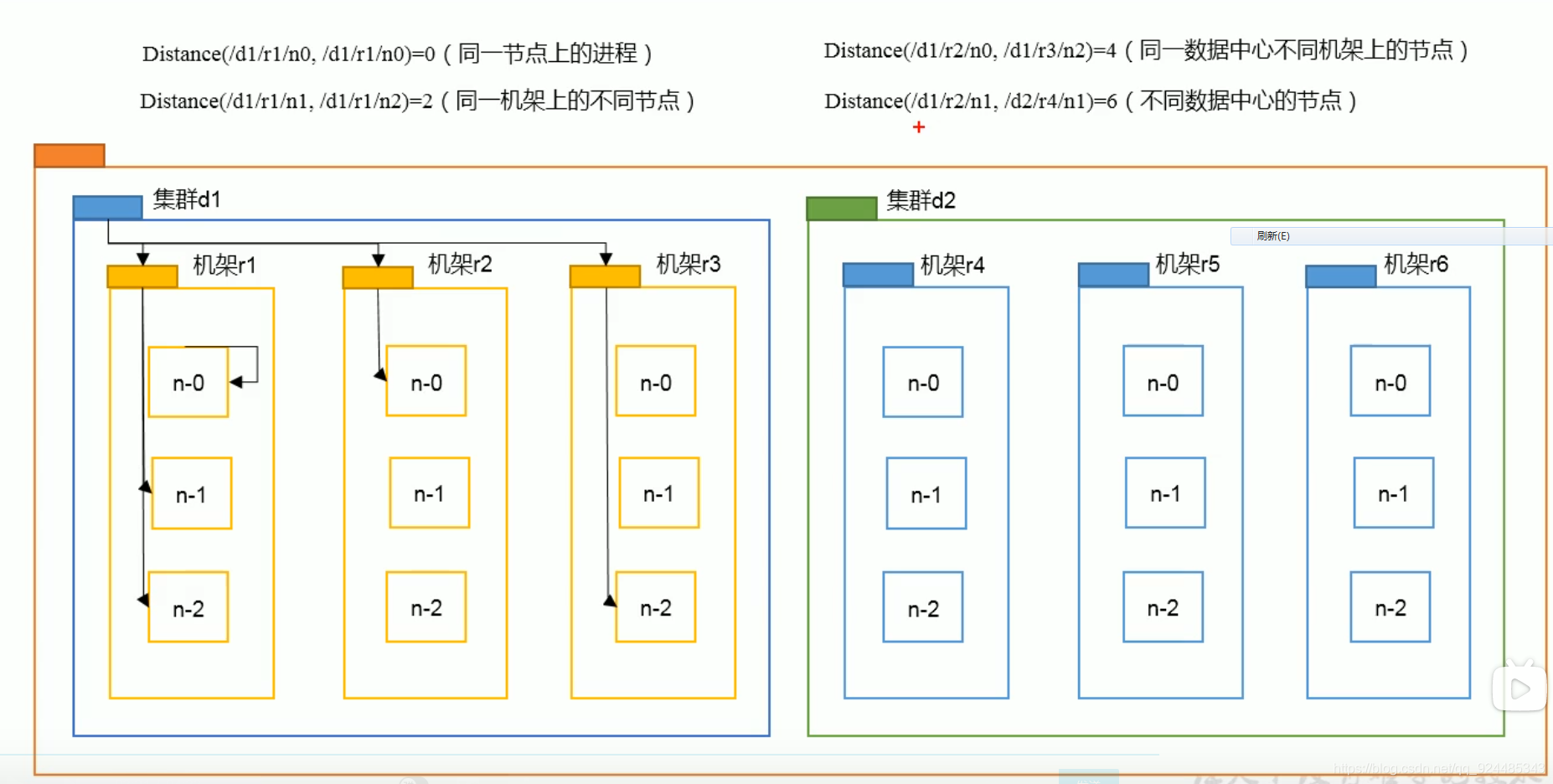
2.节点间的距离计算
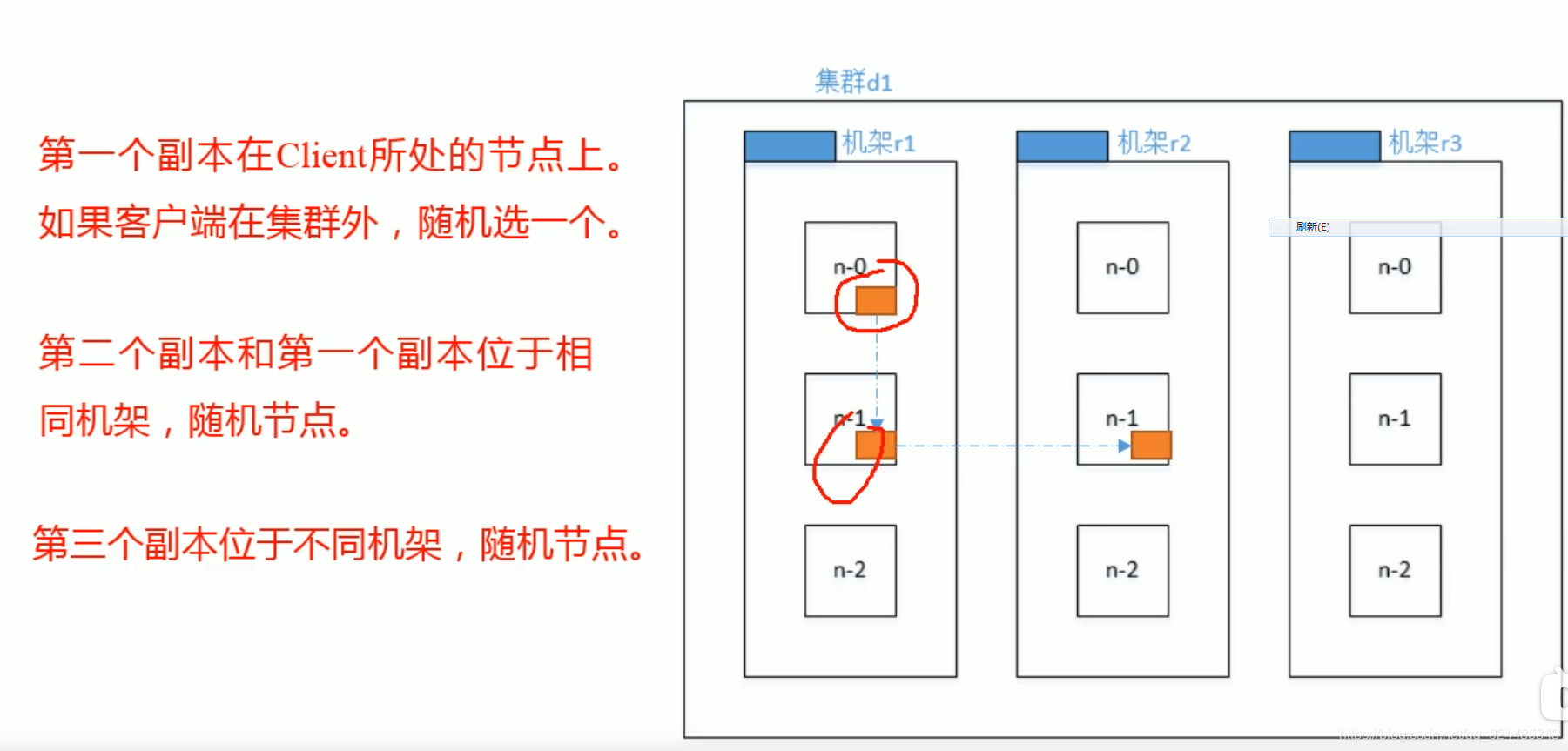
速度上的考虑,安全上的考虑 :
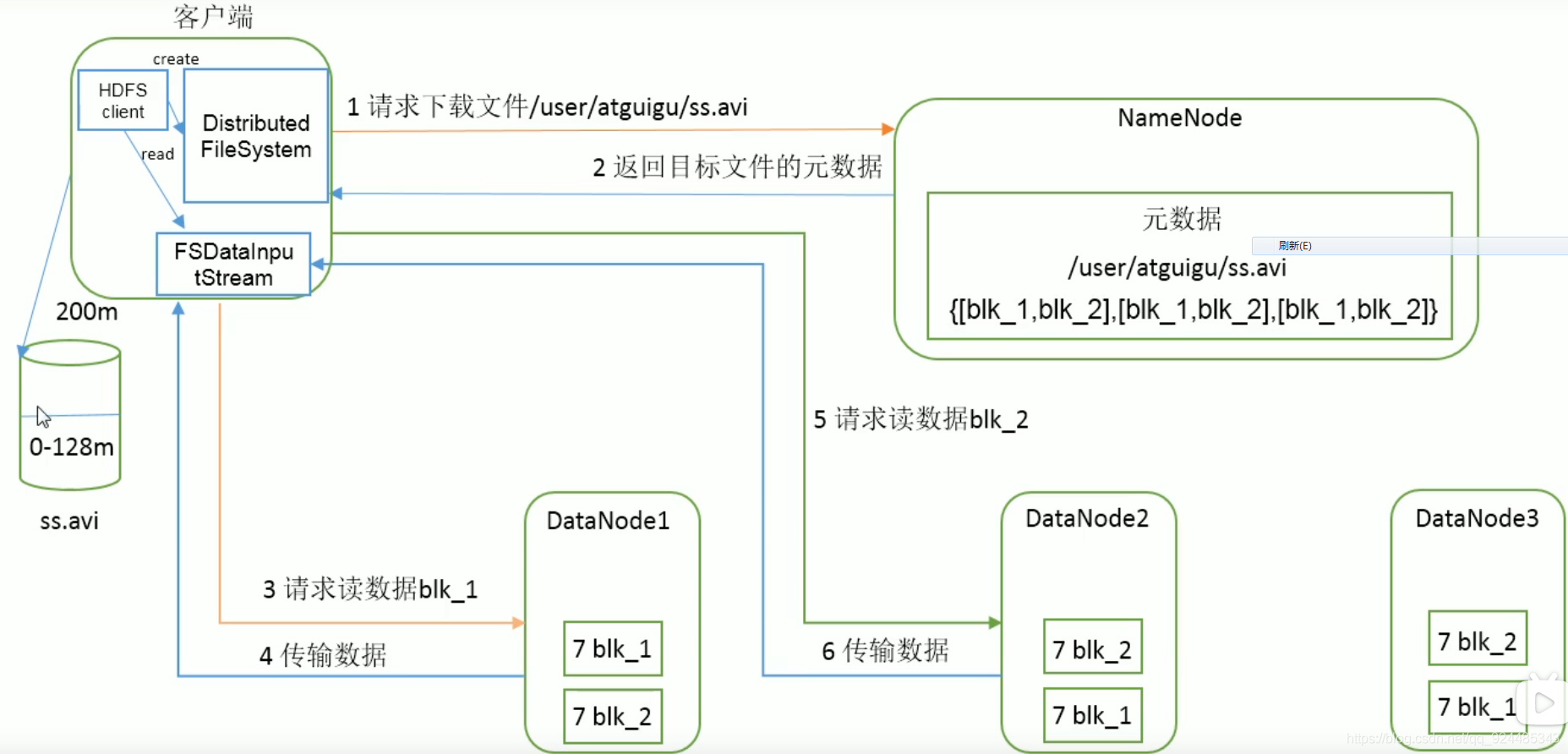
3.读数据
4.Namenode工作机制
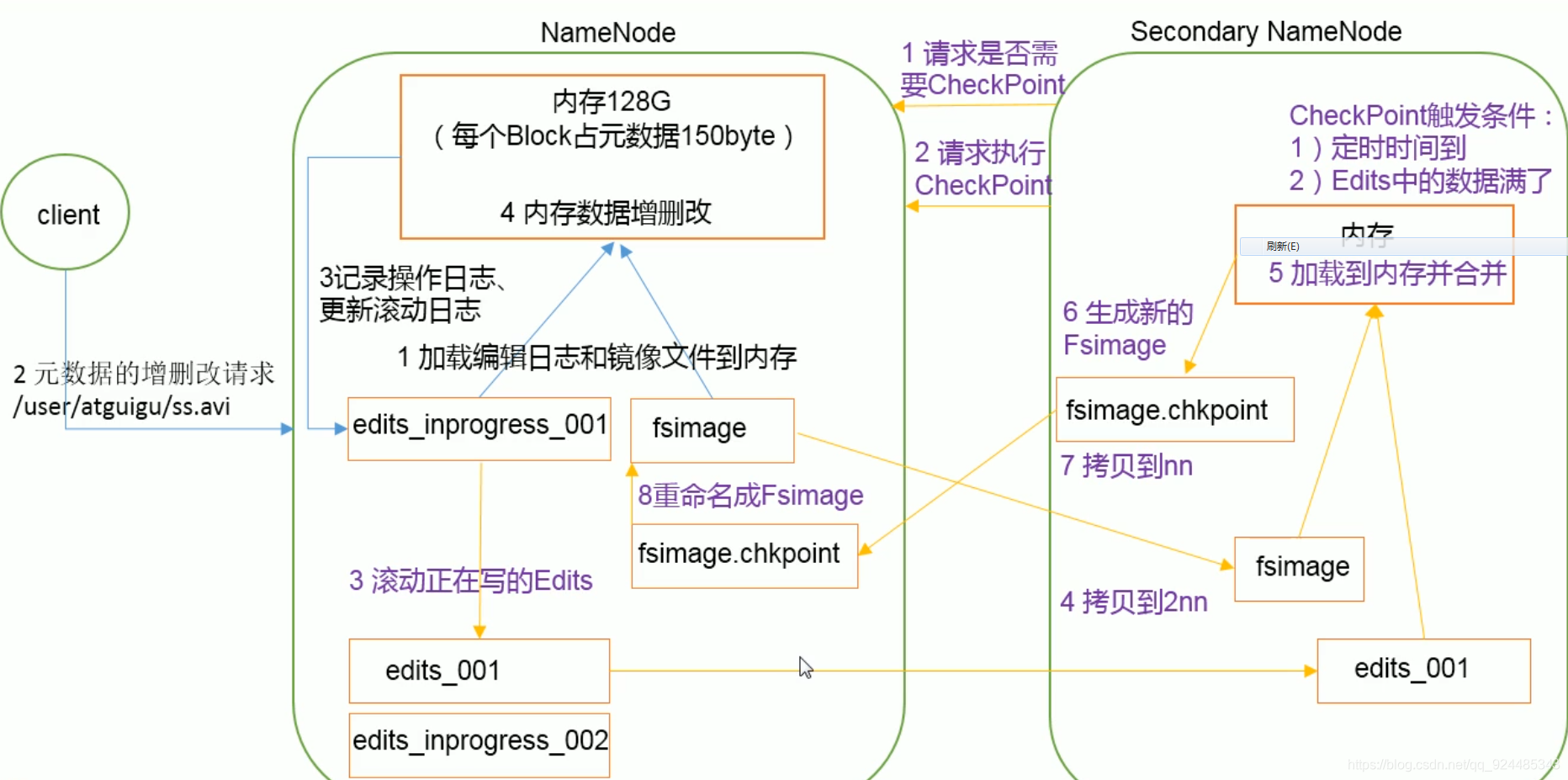
fsImage和Editlog的概念:

fsimage的内容xml形式显示
<inode>
<id>16386</id>
<type>DIRECTORY</type>
<name>user</name>
<mtime>1512722284477</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16387</id>
<type>DIRECTORY</type>
<name>atguigu</name>
<mtime>1512790549080</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16389</id>
<type>FILE</type>
<name>wc.input</name>
<replication>3</replication>
<mtime>1512722322219</mtime>
<atime>1512722321610</atime>
<perferredBlockSize>134217728</perferredBlockSize>
<permission>atguigu:supergroup:rw-r--r--</permission>
<blocks>
<block>
<id>1073741825</id>
<genstamp>1001</genstamp>
<numBytes>59</numBytes>
</block>
</blocks>
</inode >达到 editlog的容量,或者 固定的时间:
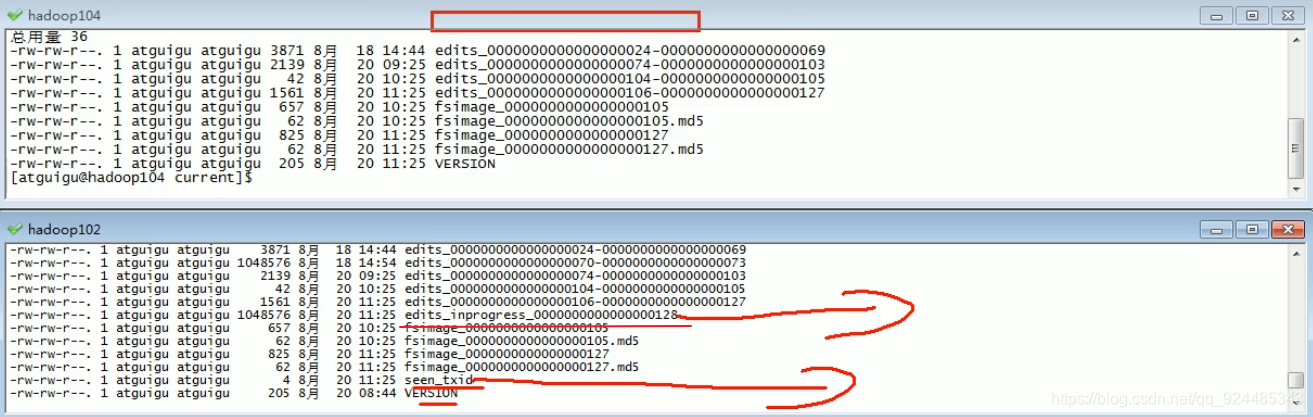
在 对集群进行 hadoop namenode -format 后,在master上的namenode的 元数据信息就都被清空了(磁盘上与内存上),当启动集群的时候,就会创建新的 fsimage 元数据镜像 和 editlog 日志文件,这些是被写入到磁盘中的,然后将 fsimage加载到内存中去,这个时候在集群中进行创建文件操作,会作用到namenode的内存中的fsimage上,并且在作用前先将操作写到editlog中,这个时候查看磁盘上的对应的fsimage其实可以发现并没有这个操作,因为操作是在内存中的fsimage中进行的,只有等到editlog和fsimage(dk)被cp到2nn被合并并且传回nn后,才可以在shell中查看到进行的操作。
client:键入command
metadata的情况:
与 nn和2nn 有关,
nn:写入editlog(dk),写入fsimage(mem)
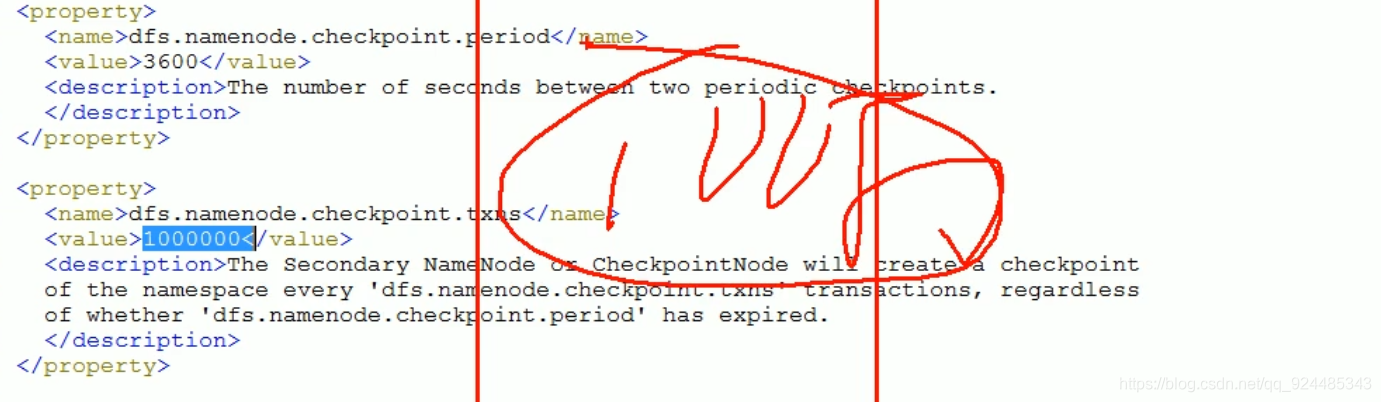
2nn: 达到editlog的容量,或者固定的时间
cp nn的 e与f, 合并,返回给nn f.checkpoint
nn: 存入f.checkpoint 并改为 f , 将这个最新的景象加载到内存,同时创立了一个新的 editlog
data的情况:
与dn有关:

















 3948
3948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









