




 本文介绍在Ubuntu系统安装和配置Hadoop与JDK的过程。先下载对应安装包,推荐从清华源下载Hadoop。接着解压安装包,配置环境变量,可在 /etc/profile 或 ~/.bashrc 中操作。最后进行本地模式测试,使用Hadoop自带示例程序统计文件单词次数。
本文介绍在Ubuntu系统安装和配置Hadoop与JDK的过程。先下载对应安装包,推荐从清华源下载Hadoop。接着解压安装包,配置环境变量,可在 /etc/profile 或 ~/.bashrc 中操作。最后进行本地模式测试,使用Hadoop自带示例程序统计文件单词次数。
下载hadoop与jdk安装包
Hadoop是一个基于Java语言开发的分布式计算框架, 因此在安装和运行Hadoop之前, 需要先安装Java Development Kit (JDK).
如何下载 :
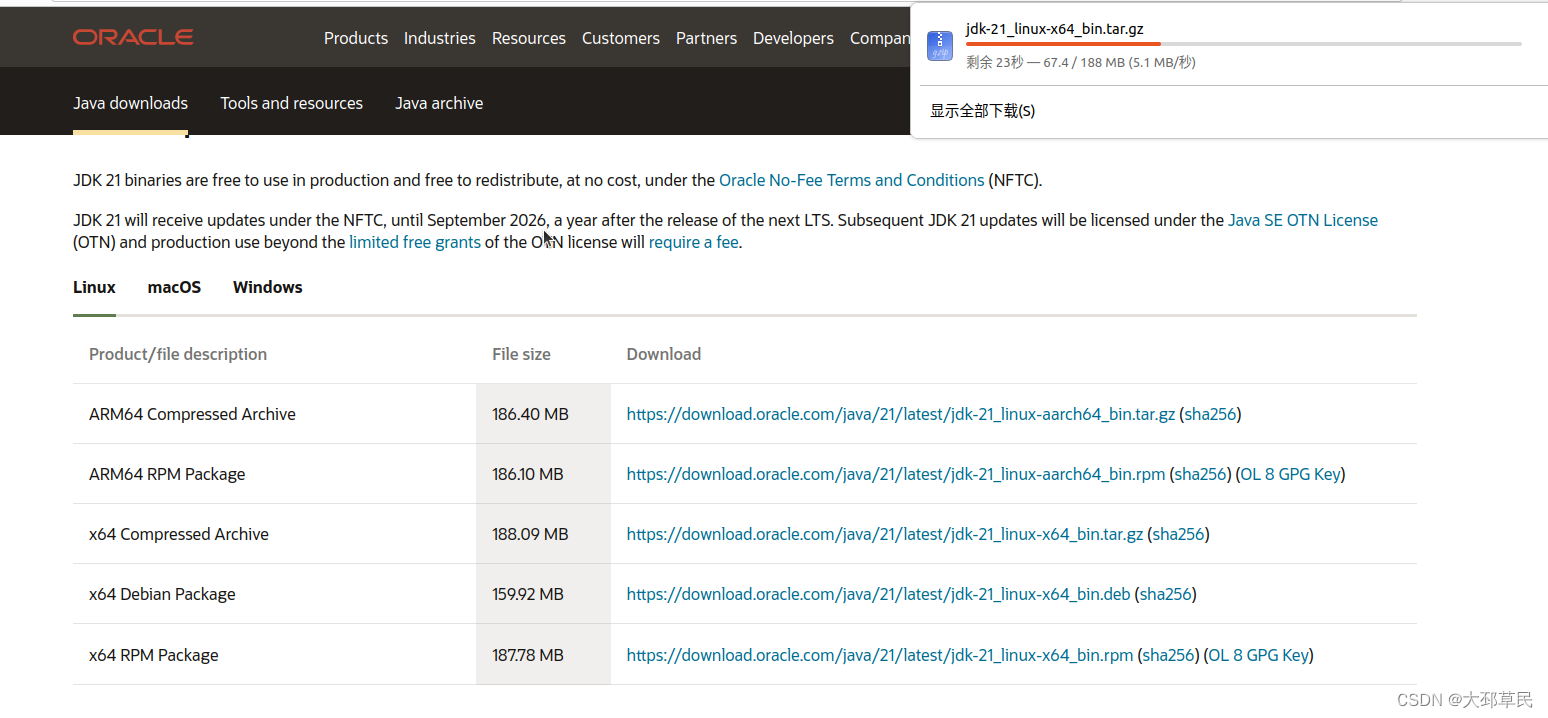
这里是在Ubuntu系统自带的火狐浏览器中直接搜索jdk官网进行安装即可.
需要注意的是我们要选择计算机的CPU架构对应的安装包.
这里使用 uname -m 指令来查看虚拟机的虚拟硬件架构.

接着我们去下载Hadoop安装包, 但是由于Hadoop官网的服务器位于美国, 下载速度会很慢.
推荐去国内的开源软件镜像站点下载.
这里选择清华源.
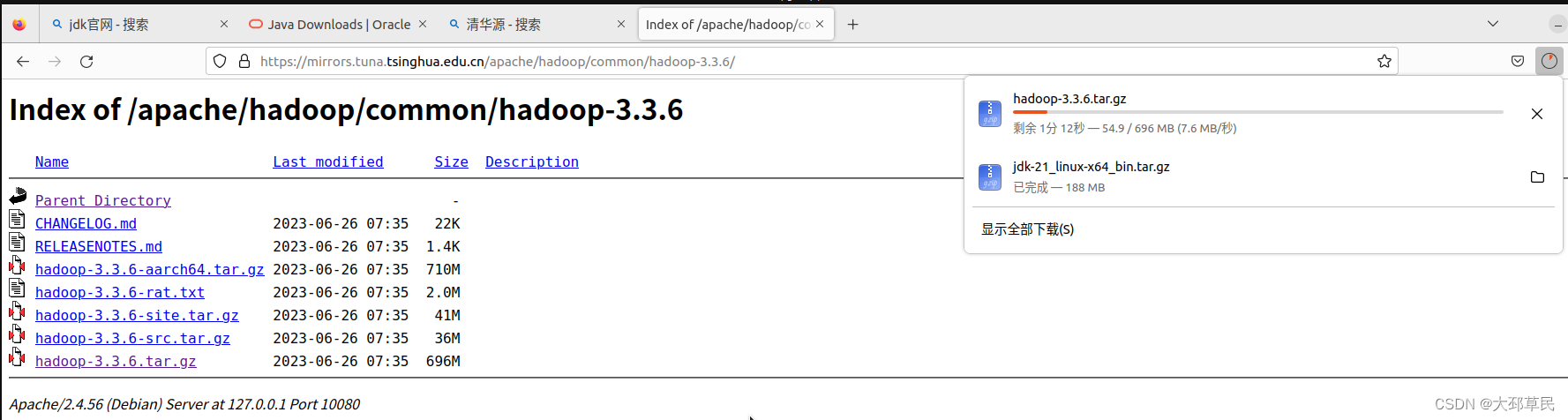
进入页面, 在搜索栏中直接搜索apache, 会出现它的很多子项目, 选择hadoop这一栏.
如下所示, 进行安装包的下载.
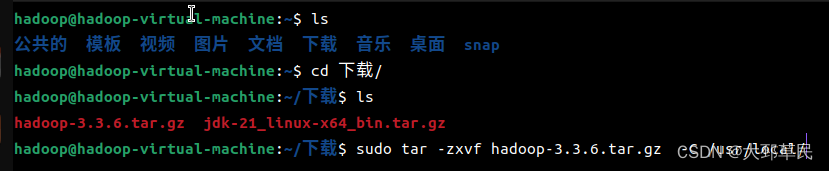
下载安装包后还需进行解压并选择解压的路径
指令如下:

这里JDK的推荐目录一般为/usr/lib,而Hadoop的推荐目录一般为/usr/local/.
不过,你也可以将它们安装在当前用户目录下,但这样文件的执行权限将仅限于本地用户.
下面是tar命令的常用选项详细介绍:
-c 或 --create:用于创建归档文件, 可以将多个文件或目录打包成一个tar文件.
-x 或 --extract:用于提取归档文件, 可以从一个tar文件中解压出其中的文件和目录.
-z 或 --gzip:用于在tar命令中同时使用gzip进行压缩和解压缩. 当使用-c选项创建tar文件时,进行gzip压缩. 同样地,当使用-x选项解压缩tar文件时,同时进行gzip解压缩.-v 或 --verbose:用于在操作过程中显示详细信息,包括被处理的文件和目录.
-f 或 --file:用于指定归档文件名. 后面需要接上文件名或路径.
-C 或 --directory:用于指定解压到的目录, 后面需要接上目录的路径.
接着,我们需要进行环境变量的配置.
进行环境变量配置的目的是为了能够在任何路径下执行特定的可执行文件,而不需要在执行时指定文件的完整路径
这里推荐使用 vim 文本编辑器来配置环境变量,如果操作系统中没有则需要下载.
我们需要在 /etc/profile 或 ~/.bashrc 中来配置环境变量.
特别说明一下:
/etc/profile 和 ~/.bashrc 是两个不同的文件,它们在 Bash Shell 中具有不同的作用和范围.
- /etc/profile 是系统级别的配置文件,它对所有用户都生效. 它是在用户登录时被读取和执行的. 在这个文件中, 可以设置系统级别的环境变量、路径和其他全局配置选项. 但是修改 /etc/profile 需要超级用户权限.
- ~/.bashrc 是用户级别的配置文件,它只对当前用户生效. 它是在用户每次打开新的终端窗口时被读取和执行的. 在这个文件中,可以设置用户级别的环境变量、别名、函数和其他个性化配置选项. 修改 ~/.bashrc 不需要超级用户权限.
因此, /etc/profile 适用于系统范围的配置,而 ~/.bashrc 适用于个人用户的配置. 通常,可以在 /etc/profile 中设置系统级别的环境变量和路径,然后在 ~/.bashrc 中设置个人用户的环境变量、别名和其他个性化配置. 这样可以保持系统级别和用户级别的配置分离,方便管理和维护.
这里使用 vim .bashrc 指令进行环境变量配置.
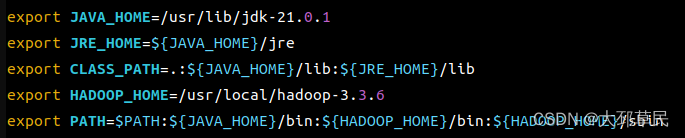
下面对这些添加的变量进行一些必要说明:
- JAVA_HOME 指定 Java 开发环境的根目录,这里设置为 /usr/lib/jdk-21.0.1
- JRE_HOME 指定 Java 运行环境的根目录,这里设置为 ${JAVA_HOME}/jre
- CLASSPATH 指定 Java 类的搜索路径,这里设置为当前目录、Java 标准库和 Java 运行环境的库.- PATH 指定可执行文件的搜索路径,这里将 Java 可执行文件的路径加入 PATH 中
这些设置可以让系统在运行 Java 程序时找到正确的 Java 开发环境,并且能够正确地加载所需的类和库 .
补充:
在
CLASSPATH环境变量中,.表示当前目录.在
CLASSPATH环境变量中,:是用来分隔不同路径的符号.当
CLASSPATH中包含.时,表示将当前目录作为类的搜索路径. 这意味着系统会在当前目录下查找所需的类文件 .通过使用
:分隔不同的路径,可以将多个路径组合起来,使得系统能够在这些路径中搜索所需的类文件.当编译或者运行 Java 程序时,系统会照
CLASSPATH中定义的路径顺序依次搜索类文件,直到找到所需的类为止.
注意: 变量名与文件的安装路径之间的 "=" 不能有空格, 否则会报错.

最后使用 用source .bashrc命令来重新加载.bashrc文件,使得修改的配置立即生效.
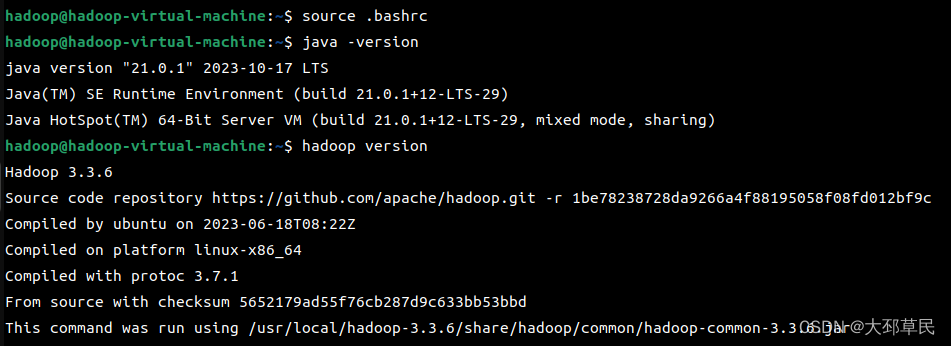
分别使用 java -version 与 hadoop version 指令查看安装包的版本信息.
若正常输出就代表环境变量配置成功.
特别提醒:
Java和Hadoop是两个不同的软件,它们的命令行参数和行为可能会有所不同
也就是
java -version是Java的标准命令行参数,用于显示Java的版本信息使用Hadoop时应该使用
hadoop version命令来查看Hadoop的版本信息,而不是
hadoop -version.
既然环境配置成功,接下来就是进行本地模式的测试.
这里使用Hadoop中 hadoop-mapreduce-examples-3.3.6.jar 文件进行测试.
在这之前需要在家目录下, 创建一个input目录用于存放要执行的测试文件.
接着, 使用vim创建一个test.txt文件并写入用于测试的内容.
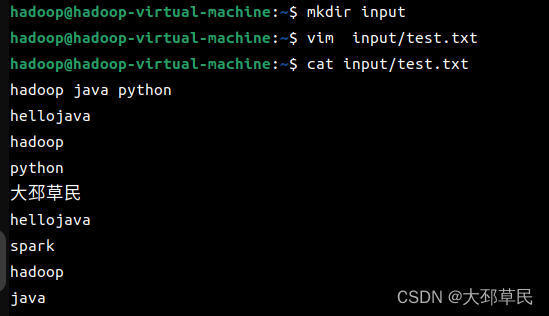
本次测试是统计文件中每单词出现的次数.
为了使操作结果的数量更易于观察,可以通过使用for循环和cat命令将一个文件的内容复制并追加到另一个文件中来实现.
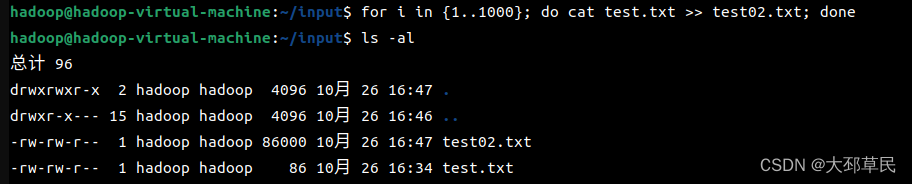
并执行以下指令

这个指令是运行Hadoop自带的一个MapReduce示例程序 wordcount ,用于统计一个文本文件中每个单词出现的次数.
具体来说,这个指令的含义如下:
- hadoop jar :运行Hadoop的一个Java程序,后面跟随要运行的Java程序的JAR包路径.
-${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar:要运行的Java程序的JAR包路径,这里是Hadoop自带的一个MapReduce示例程序的路径.
- wordcount :要运行的Java程序的类名,即 WordCount 类.
- input/ :输入文件路径,即要统计的文本文件所在的目录.
- output :输出文件路径,即统计结果要写入的目录.
这个指令的作用是在Hadoop集群上启动 wordcount 程序,对 input/ 目录下的文本文件进行单词计数,并将结果输出到 output 目录中.
最后使用以下指令来查看测试的结果.
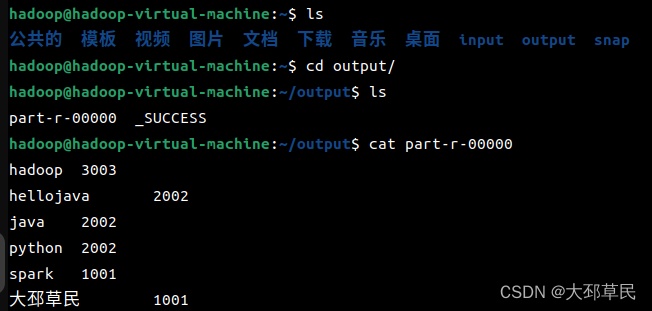

















 544
544





 到【灌水乐园】发言
到【灌水乐园】发言







