




作者为 Lihe Yang1 Bingyi Kang2† Zilong Huang2 Xiaogang Xu3,4 Jiashi Feng2 Hengshuang Zhao1*
于2024年1月19日发布在arxiv网站上
The University of Hong Kong TikTok Zhejiang University
收录于 CVPR 2024 为CCF-A类会议
核心挑战:
- 现有模型在训练数据覆盖不到的场景中表现很差**(泛化能力不足)**
- 获取大量标注的深度数据非常困难**(数据标注瓶颈)**
- 如何构建一个能处理任何图像、任何场景的通用深度估计模型?
核心思想:数据为王,利用海量廉价多样的无标注图像来构建强大的单目深度估计基础模型。其核心理念为扩大数据覆盖范围来减少模型泛化误差。
作者利用大量标记图像来训练初始MDE模型(T模型),然后利用这个T模型对未标记图像进行伪标注,让最终模型(S模型)利用伪标注的大量数据和真实数据共同学习。(半监督学习)
但作者发现在已有大量有标注数据的前提下,简单利用自训练无法带来性能提升,因为学生模型无法从老师那里学到“新知识”,针对这个问题作者提出创新一。
创新一:在使用无标注图像训练学生模型时对图像施加强扰动,对图像施加强颜色扰动和强空间扰动,来迫使模型主动挖掘图像中更鲁棒更本质的视觉特征。下图为空间扰动。

作者发现当MDE模型已经足够强大时,利用语义分割任务很难带来进一步的收益**(利用语义分割的结果进行引导训练),作者推测是由于将图像解码为离散类空间时语义信息的严重丢失,针对这个问题作者提出创新二。**
创新二:引入一个特征对齐损失,让学生模型的中间特征与一个冻结的、强大的DINOv2模型的特征保持相似**(利用语义分割的特征进行训练)。设置一个容忍边界(同一物体有远有近)**,只优化那些相似度低于阈值的特征,使模型保持DINOv2丰富语义先验的同时保留对深度估计至关重要的几何判别能力。
通过 Ll 学习深度基础,通过 Lu 强迫模型在困难模式下学习鲁棒特征,通过 Lfeat 巧妙地注入高级语义知识
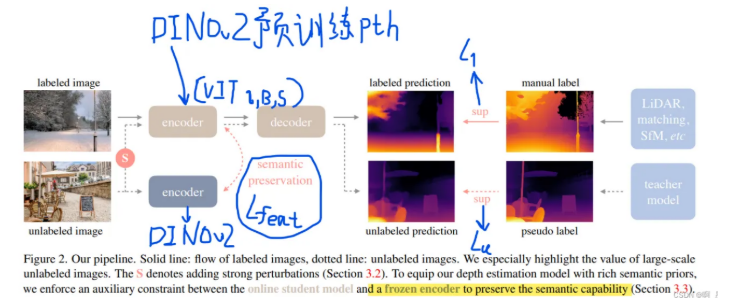 (让学生模型编码器的特征与一个预训练的DINOv2模型的特征在余弦相似度上尽可能接近,但设置了一个容忍边界(α=0.85),只有当余弦相似度低于这个边界时才进行优化。这样做的目的是让学生模型继承DINOv2的语义先验,但又不过分约束,允许深度模型保留对深度估计重要的几何细节。)
(让学生模型编码器的特征与一个预训练的DINOv2模型的特征在余弦相似度上尽可能接近,但设置了一个容忍边界(α=0.85),只有当余弦相似度低于这个边界时才进行优化。这样做的目的是让学生模型继承DINOv2的语义先验,但又不过分约束,允许深度模型保留对深度估计重要的几何细节。)
实验结果:
- 直接用DA模型(未使用KITTI和NYUv2数据集)和MiDasv3(使用了KITTI和NYUv2数据集)在KITTI和NYUv2数据集上比较,MDE也全面优于MiDasv3。且DA模型使用较小的encoder也能达到很好效果。
- 作者通过微调得到绝对深度估计,与其他模型比较得到更好的结果。
- 作者通过消融实验发现,多样的数据+扰动+语义分割约束是性能提升的关键。
- 语义分割约束送入到标记的图像时不会有性能提升,仅当送入到伪标签数据中时会有提升。

















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









