




一:客户端连接方式
1.命令行客户端
2.系统自带的命令行工具执行指令
mysql[-p 3306] -u root -p(使用这种方式,需要配置path环境变量)
二:SQL语句
1 SQL通用语法
- SQL语句可以单行或多行书写,以分号结尾
- SQL语句可以使用空格/缩进来增强语句的可读性
- M有SQL数据库的SQL语句不区分大小写,关键字建议大写
- 单行注释、多行注释
2 SQL分类
- DDL(Data Definition Language)操作数据库、表、字段
- DML(Data Manipulation Language)CRUD
- DQL (Data Query Language)查询表
- DCL(Data Control Language)数据控制语言,用来创建数据库用户、控制数据库访问权限
3 DDL(Data Definition Language)
(1)DDL-数据库操作
查询所有数据库:show databases
查询当前数据库select database()
创建:create database [if not exists] 数据库名 [default charset 字符集][collate 排序规则]
删除:drop database [if exists] 数据库名
使用数据库:use 数据库名;
(2)查询表操作
查询表结构:desc 表名;
查询制定表的建表语句:show create table 表名;
(3)创建表结构
create table 表名(字段1 字段1类型[comment 字段1注释],字段2 字段2类型[comment 字段2注释])[comment 表注释]
注:最后一个字段后面没有逗号
(4)数据类型汇总
MySQL数据类型主要分为三类:数值类型、字符串类型、日期时间类型
数值类型:

double(长度,精度)
字符串类型:

char为定长字符串就算输入一个字符串也会占用十个字符串的长度。性能高
varchar为变长字符串,输入一个字符就占一个字符长度。性能较差
日期时间类型:

(5)修改表结构(alter)
添加字段:
alter table 表名 add 字段名 类型(长度) [comment 注释][约束]
修改数据类型:
alter table 表名 modify 字段名 新数据类型(长度);
修改字段名和字段类型:
alter table 表名 change 旧字段名 新字段名 类型(长度)[comment 注释][约束]
删除字段:
alter table 表名 drop 字段名;
修改表名:
alter table 表名 rename to 新表名;
(6)删除表中数据(delete)
删除表:
drop table [if exists] 表名;
删除指定表,并重新创建该表(表中数据没有了,但会有该表结构):truncate table 表名;
4 DML(Data Manipulation Language)
控制表中数据增、删、改的操作
(1)添加数据(insert into)
1.给指定字段添加数据
insert into 表名(字段名1,字段名2,...)values(值1,值2,....);
给全部字段添加数据:insert into 表名 values (值1,值2....)
3.特殊操作
给指定字段添加多条数据:insert into 表名(字段名1,字段名2,...)values(值1,值2...),(值1,值2...),......
给全字段添加多条数据
insert into 表名 values(值1,值2,...)(值1,值2....)....
4.注意事项
插入数据时指定的字段顺序需要与值的顺序一一对应
字符串和日期型数据应该包含在引号中
(2)修改数据(update)
update 表名 set 字段名1 = 值1,字段名2 = 值2,...[where 条件];如果没有带where条件,将更新整张表数据
(3)删除数据
delete from 表名 [where 条件]5 DQL(Data Query Language)
(1)基础查询
1.查询多个字段
select 字段名1,字段名2.....from 表名;
select * from 表名;
2.设置别名
select 字段1[as 别名1],字段名2[as 别名2].....from 表名;
3.查询去除重复记录
select distinct 字段列表 from 表名;
(2)条件查询
select 字段名 from 表名 where 条件列表;

例题:查询姓名为两个字的员工信息
select * from where name like '_ _',用两个下划线代替选取两个字符
查询身份证号最后一位是X的员工信息
selecet * from where idcard like "%X"'
(3)分组查询(group by)
1.语法:select 字段列表 from 表名 [where 条件] group by 分组字段名[having 分组后过滤条件]
2.where和having区别:
执行时机不同:having是对分组之后的结果进行过滤
判断条件不同:where不能对聚合函数进行判断,而having可以
注意:
执行顺序:where>聚合函数>having
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
eg:查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
select workaddress,count(*) from emp where age<45 group by workaddress having count(*)>=3
(4)排序查询(order by)
select 字段列表 from 表名 order by 字段1 排序方式1,字段2 排序方式2;
asc升序(默认)desc(降序)
eg:根据年龄对公司的员工进行升序排序,年龄相同,再按照入职时间进行降序排序
select * from 表名 order by age asc,entrydate desc; (如果多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序)
(5)分页查询(LIMIT)
select 字段名 from 表名 limit 起始索引,查询记录数;
注:起始索引从0开始,起始索引=(查询页码-1)*每页显示记录数
分页查询是数据库的方言,不同的数据库有不同的实现,MySQL是LIMIT
查询的第一页数据,起始索引可以省略。如果查询10条数据,直接写limit10
6 DCL(Data Control Language)
用来管理数据库用户、控制用户数据库的访问权限
一:用户管理
1.查询用户
use mysql
select * from user;
2.创建用户
create user '用户名'@'主机名' identified by ‘密码’;
如果再要使用户在多个主机中查询数据库,则数据库的地方改为“%”
3.修改用户密码
alter user '用户名'@'主机名' identified with mysql_native_password by '新密码';
4.删除用户
drop user '用户名'@‘主机名’;
注意:
主机名可以使用”%“通配,即该用户可以访问任意主机的mysql数据库
这类SQL开发人员操作比较少,主要是DBA(Database Administrator 数据库管理员)使用
二:用户权限控制
具体可授予、撤销权限如下:
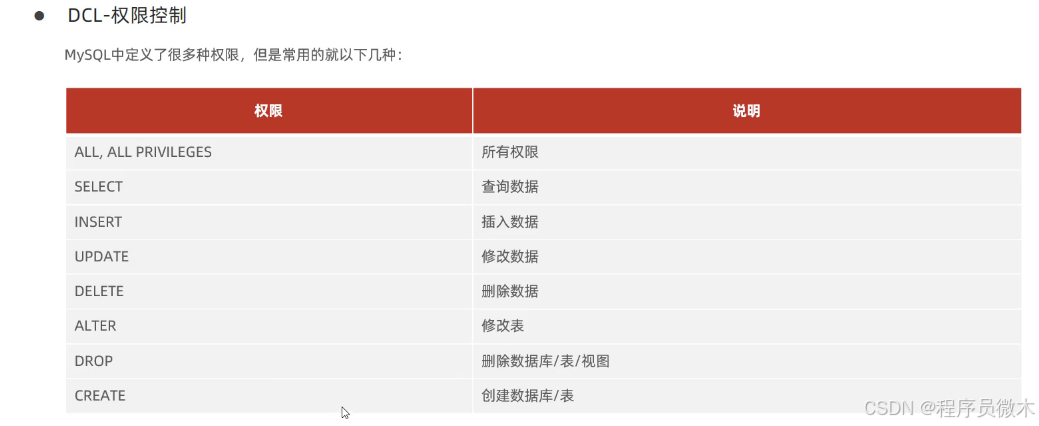
1.查询权限
show grants for ’用户名‘@'主机名'
2.授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名'
3.撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名'
注意:授权时,数据库名和表名可以使用*进行通配,代表所有数据库和数据库中的表。即可以完全的有权限访问数据库和数据表操作
三:函数
以下例题,均遵循这样的表结构
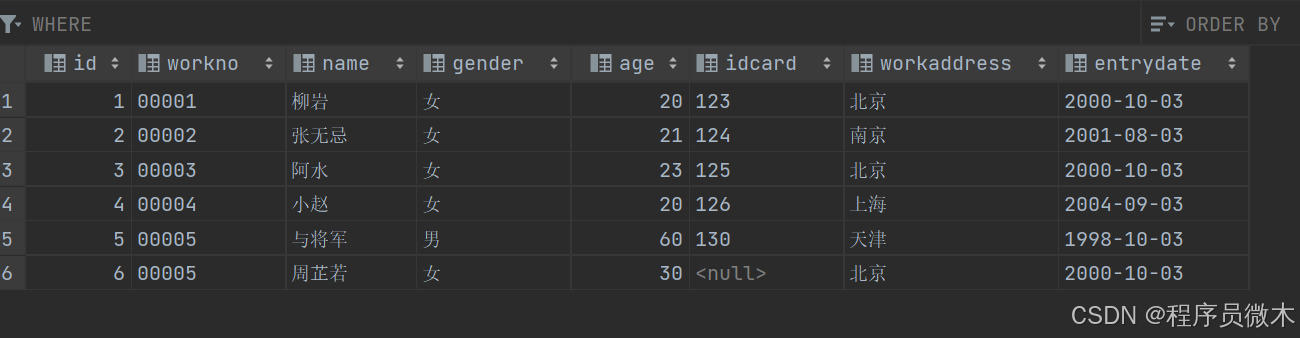
1.字符串函数
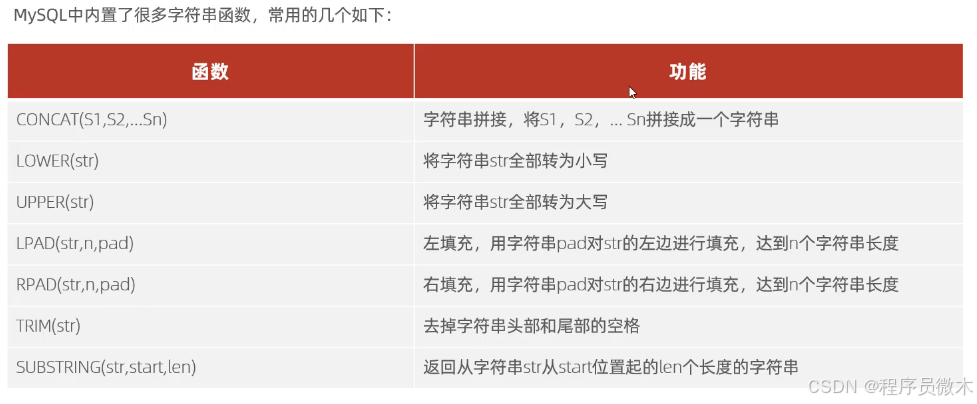
语法格式:select 函数(参数);
2.数值函数
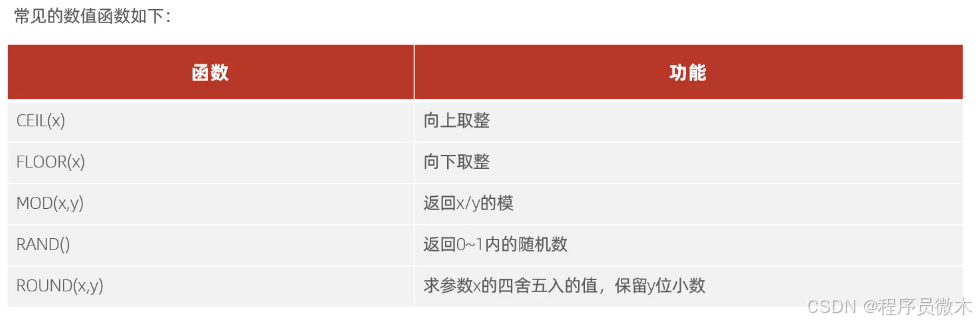
案例:通过数据库函数,生成一个六位数的随机验证码
select lpad(round(rand()*1000000,0),6,'0')
3.日期函数
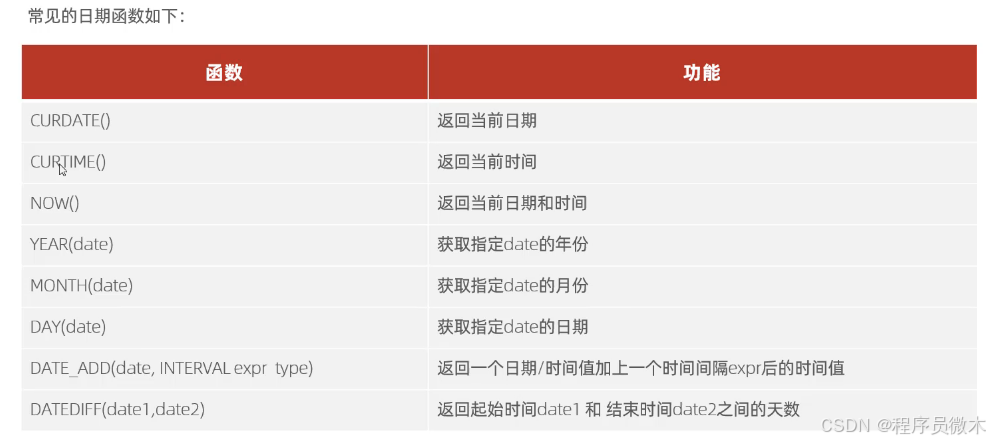
例题:查询所有员工的入职天数,并根据入职天数倒序排序
select name,datediff(curdate(),entrydate) as 'entrydates' from emp order by entrydates desc
4.流程函数
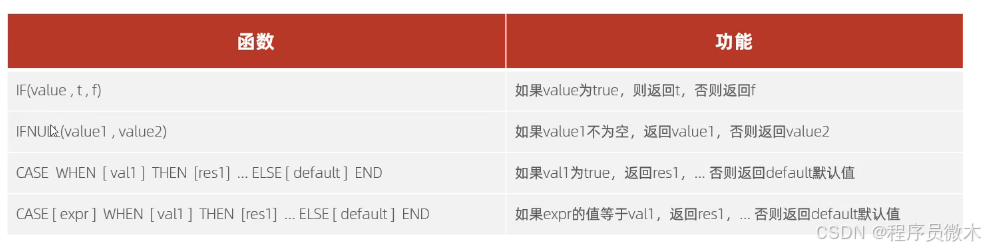
1.语法格式:select 函数名(参数)
2.需求1:查询emp表的员工姓名和工作地址(北京/上海----->一线城市,其他----->二线城市)
select name,(case workaddress when '北京' then '一线城市'when '上海' then '一线城市' else'二线城市' end)as '工作地址' from emp
需求2:根据成绩判断是否及格
create table score(
id int comment 'ID',
name varchar(20) comment '姓名',
math int comment'数学',
english int comment '英语',
chinese int comment '语文'
)comment '学员成绩表'
insert into score(id,name,math,english,chinese) values(1,'Tom',67,88,95),(2,'Rose',23,66,98),(3,'Jack',95,80,93)
select
id,
name,
(case when math>=85 then '优秀'when math>=60 then'及格' else '不及格' end)'数学'
from score四:约束
1.概述
什么是约束:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
目的:保证数据库中数据的正确、有效性和完整性
分类:

注:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束
2.约束案例
案例1:
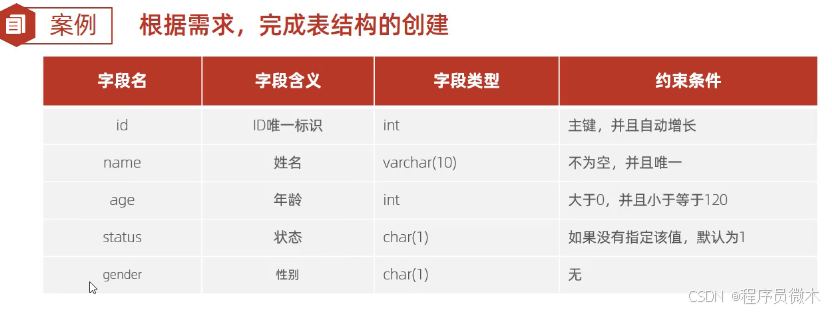
create table nuser(
id int primary key auto_increment comment'ID唯一标识',
name varchar(10) not null unique comment '姓名',
age int check(age>0 && age<=120)comment '年龄',
status char(1) default'1' comment '状态',
gender char(1) comment '性别'
)comment '用户表'3.外键约束
(1)外键作用
用于两张表之间建立联系,保证数据的一致性和完整性
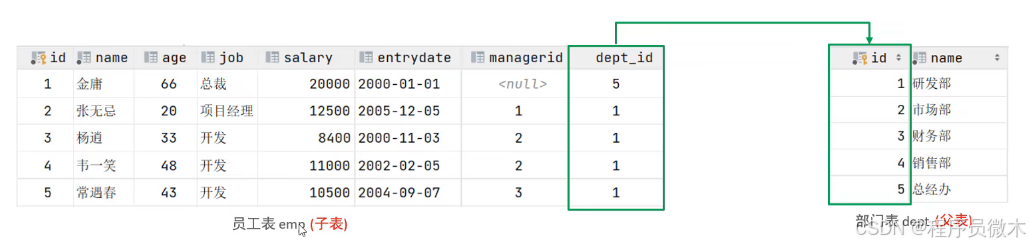
一张表中的一个字段接另一张表的主键,连接另一张表的字段称为外键
(2)语法:
添加外键
create table 表名(
字段名 数据类型
...
[constraint][外键名称]froeign key(外键字段名)references主表(主表列名)
);
alert table 表名 add constraint 外键名称 foreign key(外键字段名)references主表名(主表列名);删除外键
alter table 表名 drop foreign key 外键名称;(3)外键约束的删除/更新行为

语法格式:
alter table 表名 add constraint 外键名称 foreign key(外键字段) 主表名(主列表字段名) on update [cascade] on delete [cascade]
五:多表查询
1 多表之间关系
1.一对多(多对一)
在多的一方建立外键,指向一的一方的主键
典型案例部门和员工之间的关系
2.多对多
建立第三张中间表,中间表至少包含两个外键,分别关联另外两张表的主键
3.一对一
关系:一对一关系,用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率。
实现:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(unique)
2 多表查询概述
1.笛卡尔积
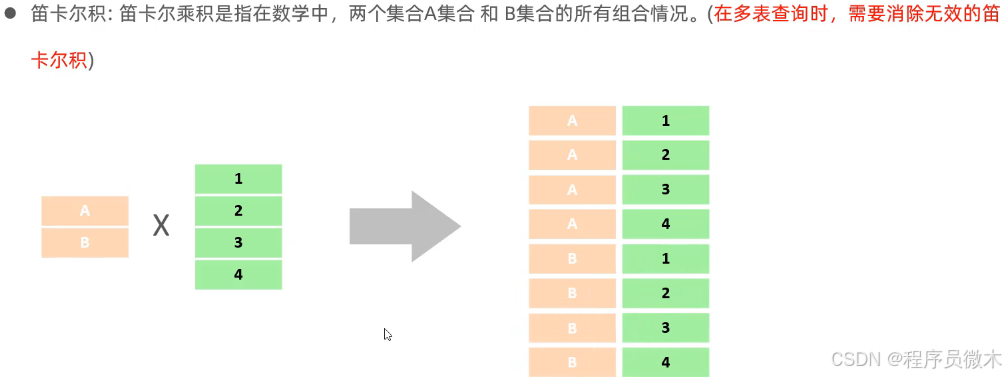
3.多表查询分类
3.1 连接查询
连接查询又分为内连接、外连接、自连接
1.内连接
查询两张表交集部分的数据
隐式内连接
select 字段列表 from 表1,表2 where 条件...;显示内连接
select 字段列表 from 表1 [inner]join 表2 on 连接条件...;2.外连接
左外连接:查询左表所有数据,以及两张表交集部分数据
select 字段列表 from 表1 left [outer] join 表2 on 条件...例题:查询emp表所有的数据,和对应的部门信息(左外连接)
--表结构:emp,dept
--连接条件:emp.emp_id=dept.id
select e.*,d.name from emp e left [outer] join dept d on e.emp_id = d.id
右外连接:查询右表所有数据,以及两张表交集部分数据
select 字段列表 from 表1 right [outer] join 表2 on 条件...例题:查询dept表的所有数据,和对应的员工信息(右外连接)
--表结构:emp,dept
--连接条件:emp.emp_id = dept.id
select d.*,e.* from emp e right join dept d on e.emp_id = d.id
3.自连接
当前表与自身的连接查询,自连接必须使用表别名(自连接查询,可以是内连接查询,也可以是外连接查询)
select 字段列表 from 表A 别名A join 表A 别名B on 条件....;
例题1:查询员工及其所属领导的名字
select a.name,b.name from emp a join emp b on a.manager_id = b.id
例题2:查询所有员工emp及其领导的名字emp,如果员工没有领导也需要查询出来
select a.name,b.name from emp a left join emp b on a.manager_id = b.id;
3.2 联合查询
union all 对查询记录进行不加去重结合
union 对查询记录去重操作
所查询的表列与字段属性要相同
3.3 子查询
SQL 语句中嵌套select语句,称为嵌套查询(子查询)
select * from 表1 where column1 = (select column1 from 表2)子查询外部语句可以是insert/update/delete/select的任何一个
3.3.1 标量子查询
子查询返回的结果是单个值(数字、字符串、日期等)
例题:查询“小赵”入职之后的员工信息
--a. 查询小赵入职时间
--b.根据比小赵入职时间晚的员工信息
select * from emp where entrydate > (select entrydate from emp where name = '小赵')
3.3.2 列子查询
列子查询返回的结果是一列(可以是多行)

例题1:查询“销售部”和“市场部”的所有员工信息
a.查询销售部和市场部id
select * from dept where name = '市场部' or name = '财务部'
b.根据销售部和市场部id值,查询对应员工信息
select * from emp where id = (2,4)
select * from emp where id in (select * from dept name = '市场部' or name = '财务部')
例题2:查询比财务部所有人工资都高的员工信息
a.查询财务部所有人工资
select salary from emp where emp_id = (select id from dept where name = '财务部')
b.比财务部所有人工资都高的员工信息
select * from emp where salary > all(select salary from emp where emp_id = (select id from dept where name = '财务部'))
3.3.3 行子查询
行子查询返回的结果是一行(可以是多列)
常用操作符:=、<>、in、not in
例题1:查询与“张无忌”的薪资及直属领导相同的员工信息
select * from emp where (salary,managerid) = (select salary,managerid from emp where name = '张无忌')
3.3.4 表子查询
子查询返回的结果是多行多列
常用操作符:in
例题1:查询与“张无忌”和“宋远桥”的年龄和薪资相同的员工信息
因为涉及到多行多列子查询语句就不能使用“=”,而应该使用“in”
select *from where (salary,age) in (select salary,age from where name = '张无忌' or name = "宋远桥")
例题2:查询入职日期是“2000-01-01”之后的员工信息,及部门信息
select name,emp_id from (select * from emp where entrydate >'2000-01-01') e left join dept d on e.dept_id = d.id;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









