



文章目录
(三)、 灭鼠杀虫剂市场机会点
灭鼠杀虫剂市场机会点-业务逻辑
- 子类目市场确定后(灭鼠杀虫剂市场):确定市场中最受欢迎的产品类别–>细分价格段
–>属性进一步分析:什么样的价格作为主市场,什么样的商品符合大众口味 - 不同用途的商品定位:
- 商品布局时要考虑的问题:价格,产品特征,用户喜好度,商品需求等
- 引流商品:价格低,利润空间几乎没有,目的是为了引流
- 利润商品:价格合理,只要的盈利来源
- 品牌商品:价格偏高,门面商品或奢侈品
获取流量的方式有免费和付费两种,免费流量看缘分(lian),控制付费流量成本
即是对流量精准度的要求,即精准营销
灭鼠杀虫剂市场机会点-产品类别
- 使用灭鼠杀虫剂细分市场数据(截止到2018年11月22日30天的交易数据):
- 读取五个文件并且合并
- 清洗:去掉大量缺失值的列,去掉单一值的列,去掉逻辑上不可用的列,如:‘时间’,‘链接’,‘主图链接’,'主图视频链接’,‘页码’,‘排名’,‘宝贝标题’,‘运费’,‘下架时间’,‘旺旺’
os.listdir('../灭鼠杀虫剂细分市场')
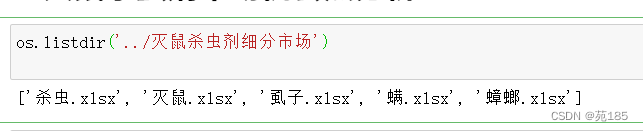
os.chdir('../灭鼠杀虫剂细分市场')
filenames1 = glob.glob('*.xlsx')
dfs1 = [pd.read_excel(i) for i in filenames1]
df2 = pd.concat(dfs1,sort=False)
df2.info()

#缺失值
df2.isnull().mean()
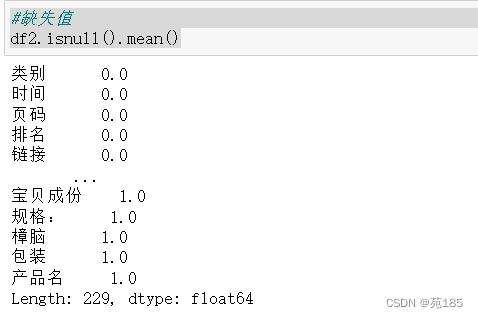
1、NA > 98% 2、单一值 3、逻辑上可删: - 如果我有新数据,新数据里会不会有这个x,会有则留下,没有则删去 - 链接等没用的列 4、类ID列 - 名字 - 分类多,每类频次太少,预测能力差
# 计算空值占比
null_percent = df2.isnull().sum() / len(df2)
# 找出空值占比大于98%的列
ind1 = null_percent > 0.98
# 删除空值占比大于98%的列
df20 = df2.loc[:, ~ind1]
# 药品登记号之后的文号列作用不大且空值占比依旧较大,删除
ind11 = df20.columns.get_loc('药品登记号')
df20 = df20.iloc[:,:ind11]
# 特征值单一,删除
ind2 = np.array([len(df20[i].unique())==1 for i in df20.columns])
df21 = df20.loc[:,~ind2]
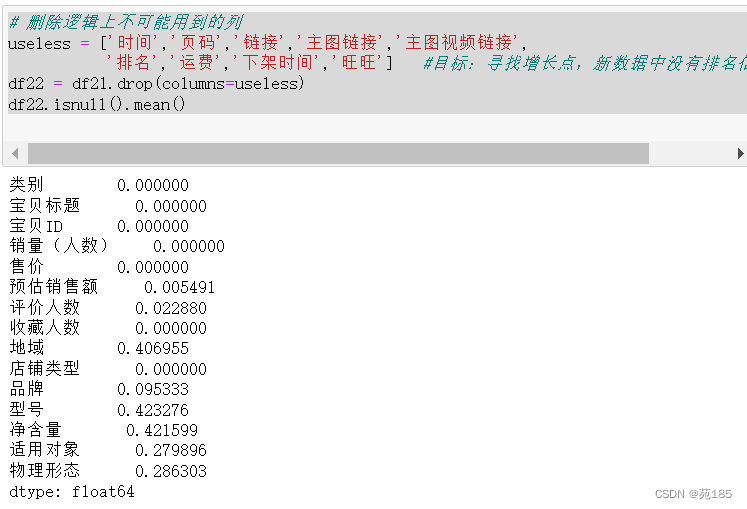
# 删除逻辑上不可能用到的列
useless = ['时间','页码','链接','主图链接','主图视频链接',
'排名','运费','下架时间','旺旺'] #目标:寻找增长点,新数据中没有排名信息,故删除
df22 = df21.drop(columns=useless)
df22.isnull().mean()
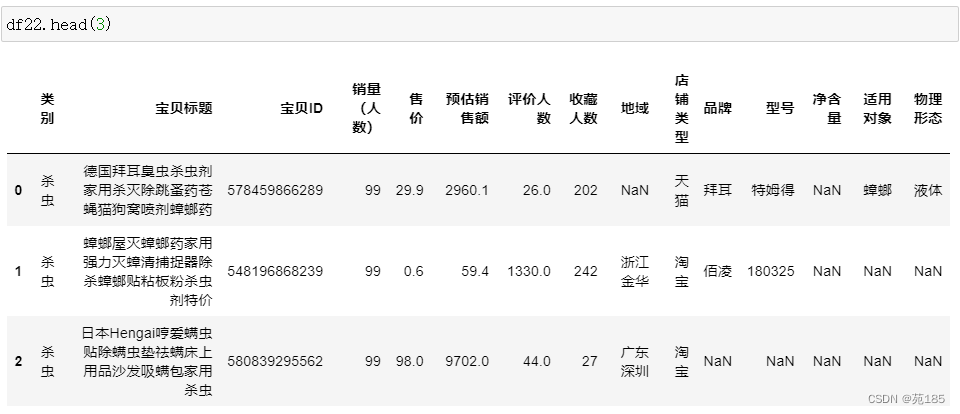
df22
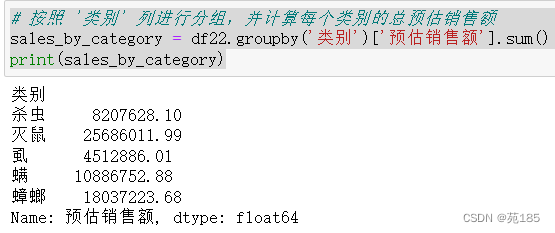
# 按照 '类别' 列进行分组,并计算每个类别的总预估销售额
sales_by_category = df22.groupby('类别')['预估销售额'].sum()
print(sales_by_category)
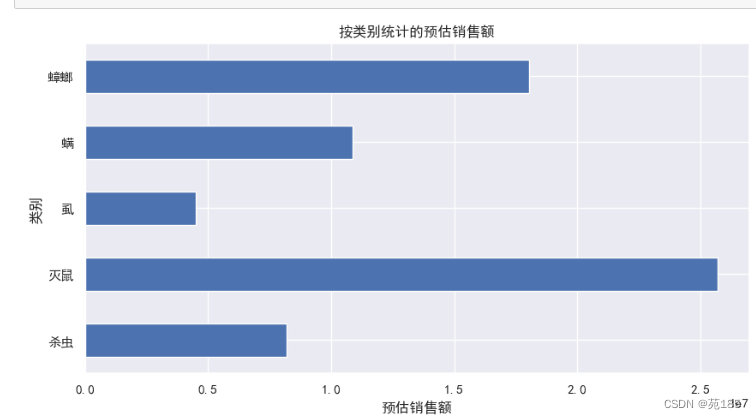
# 画出横向柱状图
plt.figure(figsize=(10, 5))
sales_by_category.plot(kind='barh')
plt.xlabel('预估销售额')
plt.ylabel('类别')
plt.title('按类别统计的预估销售额')
plt.show()
# 画出饼图
plt.figure(figsize=(8, 8))
sales_by_category.plot(kind='pie', autopct='%1.1f%%', startangle=90)
plt.ylabel('') # 隐藏y轴标签
plt.title('按类别统计的预估销售额分布')
plt.show()
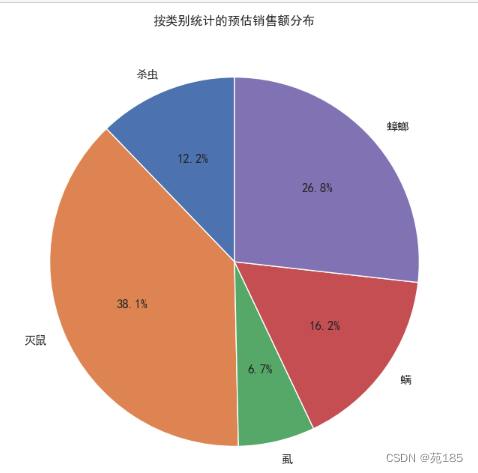
可见:最受欢迎的是灭鼠类产品,市场占比最大,高达38%,需要重点研究。
灭鼠杀虫剂市场机会点-灭鼠类别分析
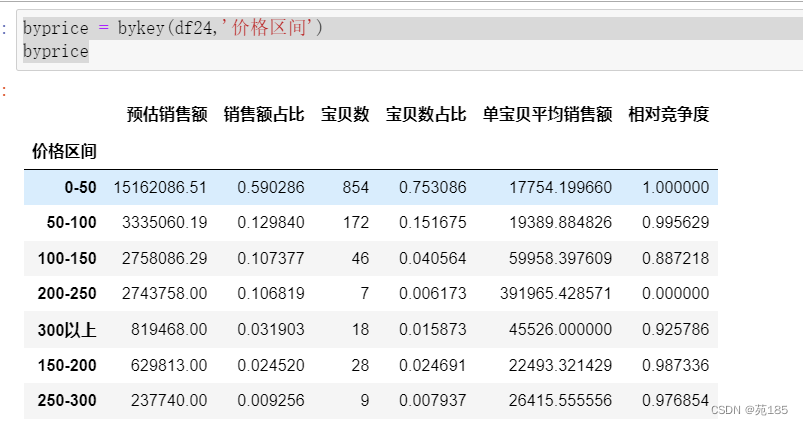
- 选择灭鼠数据进一步分析–>依据’售价’进行价格划分,得到若干的价格区间
- 每个价格区间计算:预估销售额(总和),销售额占比,宝贝数(不同’宝贝ID’数),宝贝数占比,单宝贝平均销售额(不同宝贝的平均预估销售额,可以理解为竞争的反面,单宝贝平均销售额越高,竞争越低,单宝贝销售额高才有的分),相对竞争度(由前一项套入线性变换 得到,0表示类目中最小竞争,1表示最大)
df24 = df22[df22['类别'] == '灭鼠']
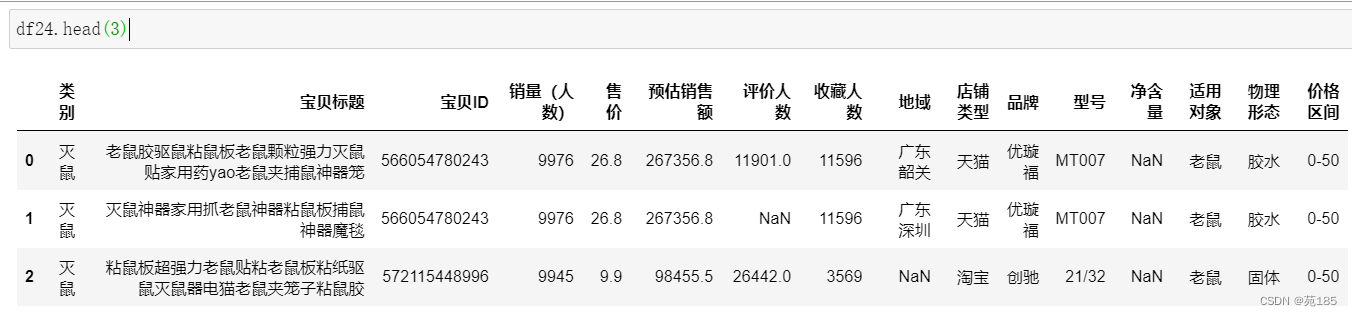
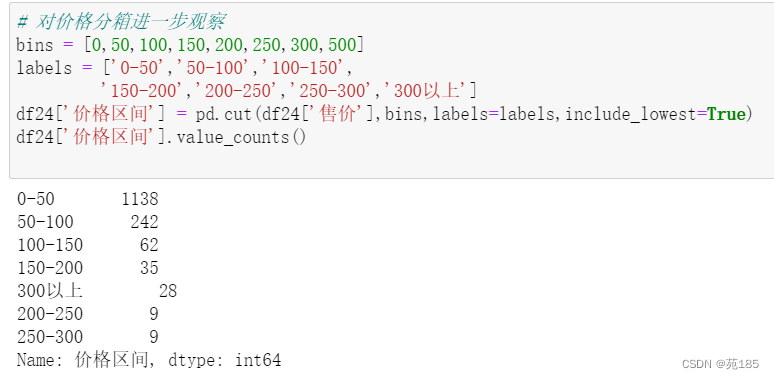
# 对价格分箱进一步观察
bins = [0,50,100,150,200,250,300,500]
labels = ['0-50','50-100','100-150',
'150-200','200-250','250-300','300以上']
df24['价格区间'] = pd.cut(df24['售价'],bins,labels=labels,include_lowest=True)
df24['价格区间'].value_counts()
# 对价格分箱进一步观察
bins = [0,50,100,150,200,250,300,500]
labels = ['0-50','50-100','100-150',
'150-200','200-250','250-300','300以上']
df24['价格区间'] = pd.cut(df24['售价'],bins,labels=labels,include_lowest=True)
df24['价格区间'].value_counts()
销售额 销售额占比 宝贝数 宝贝数占比 相对竞争度(1-归一化[‘单宝贝销售额’])
def bykey(df,by,sort='销售额占比'):
byk = pd.DataFrame(df.groupby(by).sum()).loc[:,['预估销售额']]
byk['销售额占比'] = byk['预估销售额']/byk['预估销售额'].sum()
byk['宝贝数'] = df.groupby(by).nunique()['宝贝ID']
byk['宝贝数占比'] = byk['宝贝数']/byk['宝贝数'].sum()
byk['单宝贝平均销售额'] = byk['预估销售额']/byk['宝贝数']
byk['相对竞争度'] = 1-(byk['单宝贝平均销售额']-byk['单宝贝平均销售额'].min())/(
byk['单宝贝平均销售额'].max()-byk['单宝贝平均销售额'].min())
if sort:
byk.sort_values(sort,ascending=False,inplace=True)
return byk
byprice = bykey(df24,'价格区间')
byprice
# 绘图观察
def plot_m(bydf):
'''
绘图函数
'''
sns.set(font='SimHei',style='white')
y1 = bydf['销售额占比']
y2 = bydf['相对竞争度']
x = bydf.index.tolist()
fig = plt.figure(figsize=(10,6))
# 柱形图
ax1 = fig.add_subplot(111)
ax1.set_ylim([0,1])
ax1.bar(x, y1, alpha=0.7,color='g')
ax1.set_ylabel('销售额占比',fontsize='14')
ax1.tick_params(labelsize=15)
for i,(_x, _y) in enumerate(zip(x, y1)):
plt.text(_x, _y,f'{_y*100:.2f}%',color='black', fontsize=20, ha='center', va='bottom')
plt.xlabel('价格区间')
# 折线图
ax2 = ax1.twinx()
ax2.set_ylim([-0.1,1.1])
ax2.plot(x, y2, 'b', ms=10, lw=3, marker='o')
ax2.set_ylabel(u'相对竞争度', fontsize='14')
sns.despine(left=True, bottom=True)
ax2.tick_params(labelsize=15)
ax2.legend(loc='upper right')
plt.show()
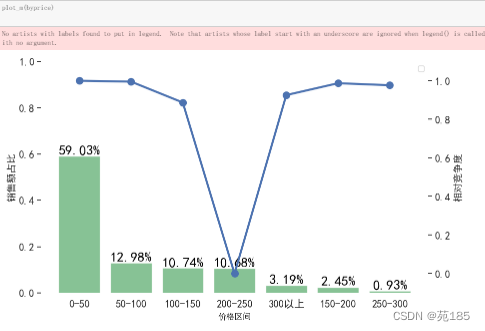
- 0-50是大容量市场,虽然竞争大,但这么大的蛋糕能参与还是要参与。 2、200-250,竞争小,做高价市场的优先选择,属于机会点,可发展轻奢产品。
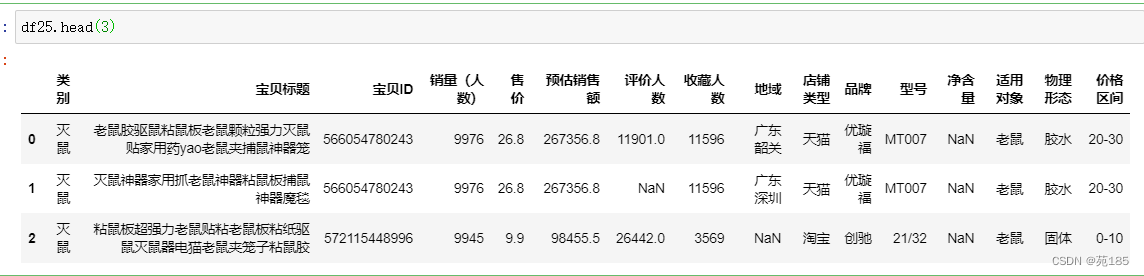
# 创建 df25,其中包含 df22 中 '售价' 大于 0 且小于 50 的每一行
df25 = df24[(df24['售价'] > 0) & (df24['售价'] < 50)]
灭鼠杀虫剂市场机会点-0_50细分价格市场
# 对0-50价格分箱进一步观察
bins = [0,10,20,30,40,50]
labels = ['0-10','10-20','20-30',
'30-40','40-50']
df25['价格区间'] = pd.cut(df25['售价'],bins,labels=labels,include_lowest=True)
df25['价格区间'].value_counts()

byprice2 = bykey(df25,'价格区间')
byprice2
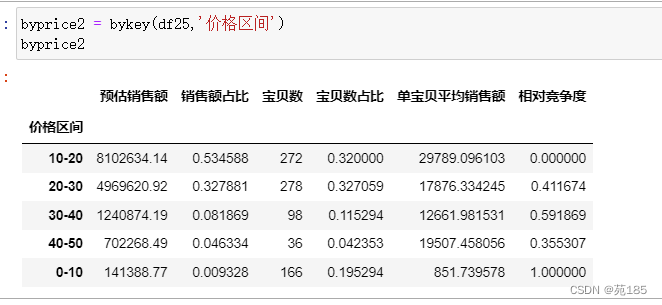
plot_m(byprice2)
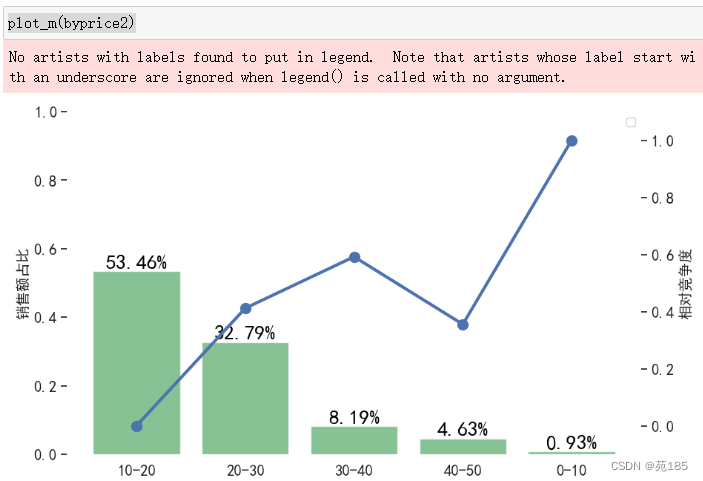
可见:10-20相对竞争度低,容量大,优选,20-30也不错。
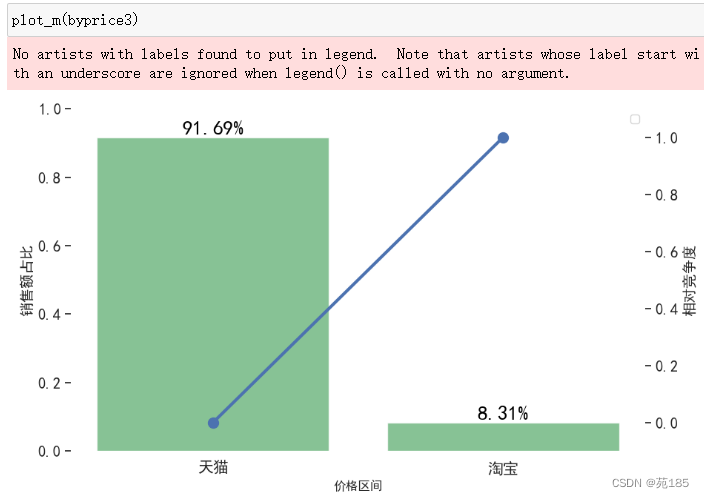
细分市场的其它属性分析
byprice3 = bykey(df24,'店铺类型')
byprice3
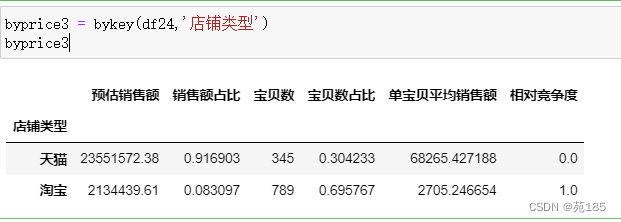
plot_m(byprice3)
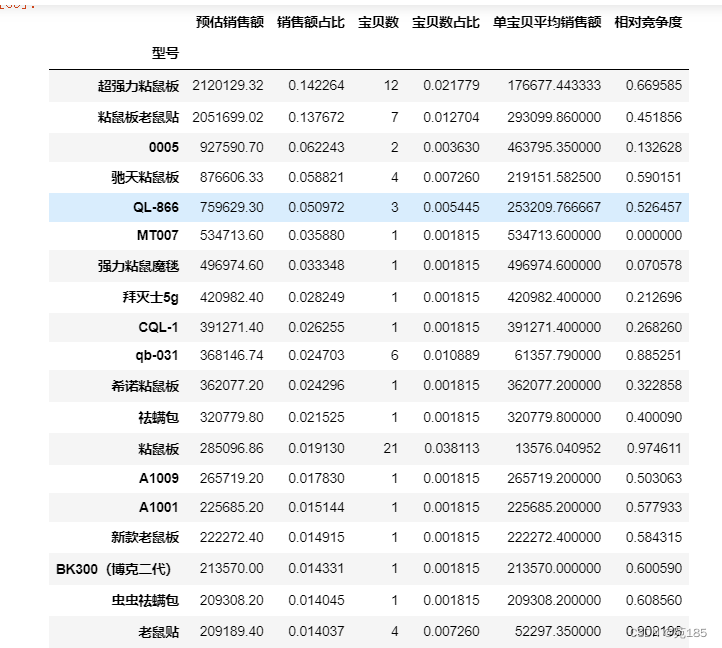
bytype = bykey(df25,'型号')
#预估销售额 前5%的型号
bytype1 = bytype[bytype['预估销售额']>=bytype['预估销售额'].quantile(0.95)]
bytype1
plot_m(bytype1)
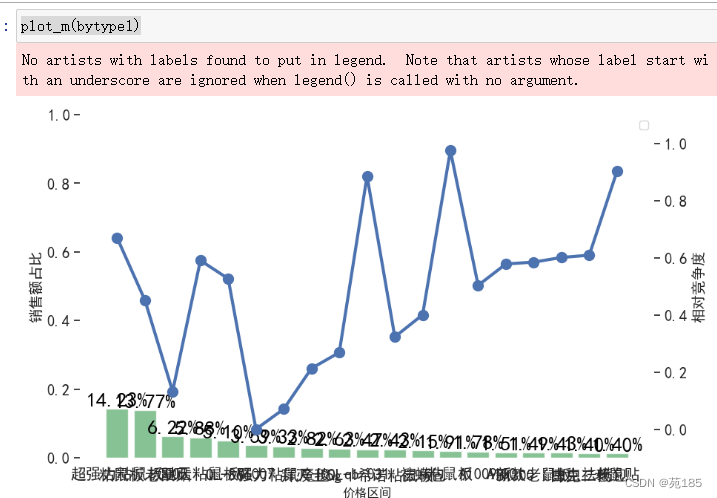
可见虽然粘鼠板市场份额普遍较高,但是0005、MT007在竞争度上有明显的优势。
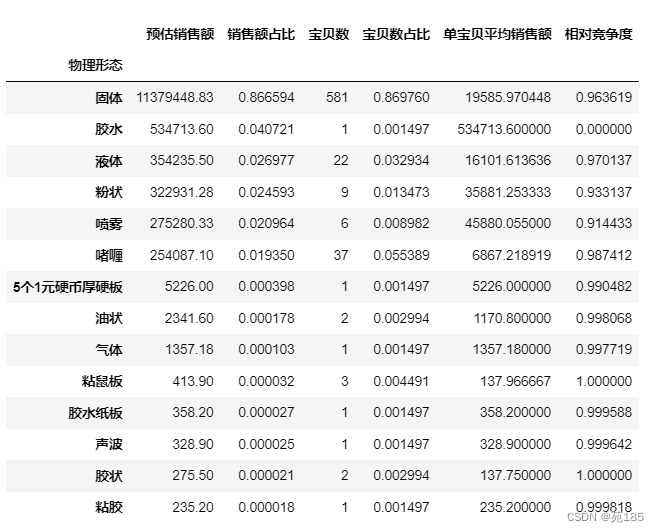
物理形态
byshape = bykey(df25,'物理形态')
byshape
plot_m(byshape)
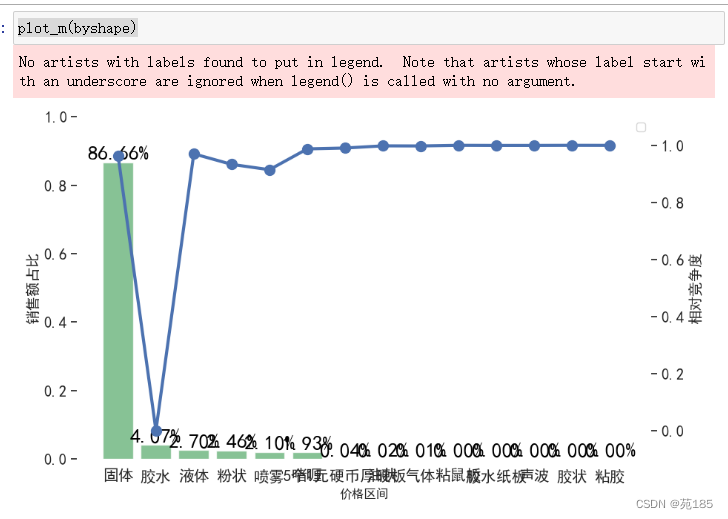
可见:常见物理形态是固体,竞争度也偏高,而胶水虽然竞争度低,但是市场份额较低。
物理形态、净含量
byhanliang = bykey(df25,'净含量')
byhanliang
plot_m(byhanliang)
-
可见:当物理形态为固体,净含量为1时,潜力较大。
-
可见市场份额最高的是固体,竞争度也偏高, 而胶水虽然竞争度低,但是市场份额较低, 基本可以认为常见的物理形态就是固体。
灭鼠杀虫剂市场机会点-结论
- 灭鼠杀虫剂市场中,需要重点关注的产品类别是:灭鼠和蟑螂
- 灭鼠中:
· 最大的市场集中在0-50的价格段,这个价格段竞争也很激烈
· 200-250这个价格段市场份额占10%左右,竞争度很低,是值得挖掘的高价市场
灭鼠0-50价格段的产品市场中: · 10-20价格段市场容量大,竞争度低,值得进一步开发,20-30也不错 - 店铺类型方面天猫明显优于淘宝
- 市场份额高的型号是粘鼠板,然而型号0005市场份额还行,竞争度较低,值得开发
- 产品的物理形态基本都是固体,也是被大众认可的形态
- 当物理形态为固体,净含量为1时,市场份额高竞争度低,值得开发
- 思考:数据分类多是人为填写的,那么分类的严谨性和可扩展性都值得考量,需要结合 业务逻辑和市场环境进一步判断
(四)、竞争分析
依据之前的top100品牌数据,分析市场份额前三的商家:拜耳,科凌虫控,安速
分析流程:
- 人群画像分析:三个品牌的人群特征基本一致(这里省略)
- 品类分布:依据各个商家产品类别和适用对象的分布,理解每个品牌的产品分布情况
(横向发展还是纵向发展) - 产品结构:依据波士顿矩阵,分析各品牌不同产品的结构特征,为产品发展策略提供依
据 - 流量结构:通过流量结构和流量效果的对比,制定推广策略
- 产品舆情:优质产品维稳
os.listdir('../竞争数据')

使用商品销售数据分析各家的产品类别的分布:
os.chdir('../竞争数据/商品销售数据')
filename2 = glob.glob('*.xlsx')
filename2

df3 = pd.read_excel(filename2[2])
df3.head(1)
# 删除无用特征
def load_xlsx_title(filename):
df = pd.read_excel(filename)
unless = ['序号','店铺名称','商品名称','主图链接','商品链接']
df.drop(columns=unless,inplace=True)
return df
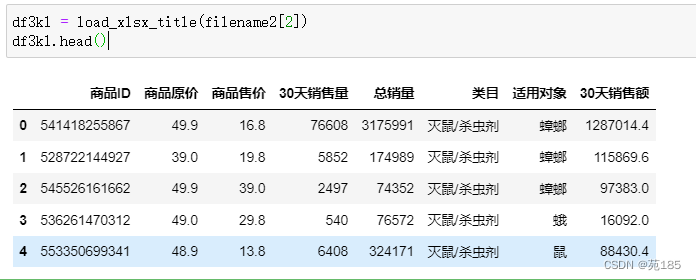
df3bai = load_xlsx_title(filename2[1])
df3bai.head()
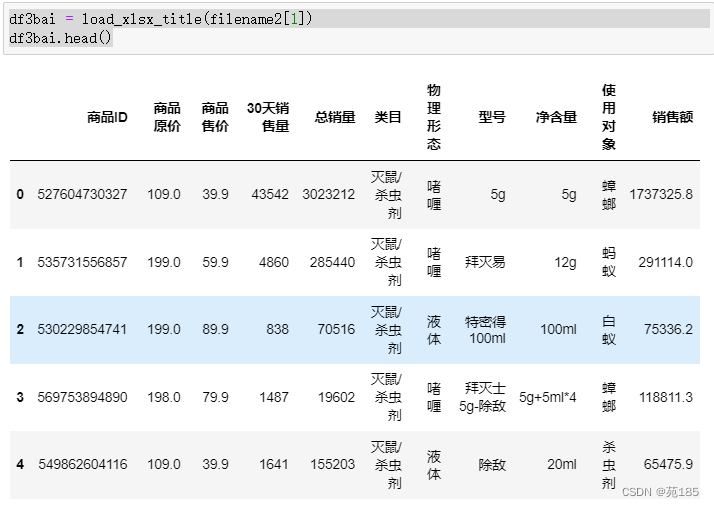
df3an = load_xlsx_title(filename2[0])
df3an.head()
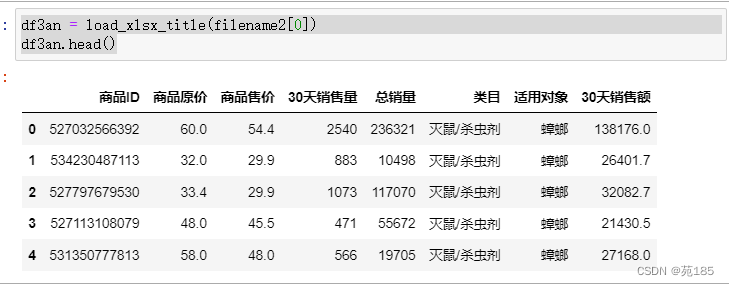
df3kl = load_xlsx_title(filename2[2])
df3kl.head()
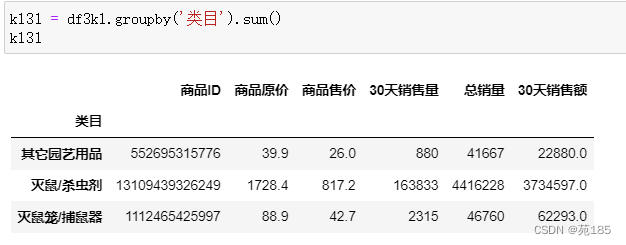
bai31 = df3bai.groupby('类目').sum()
bai31

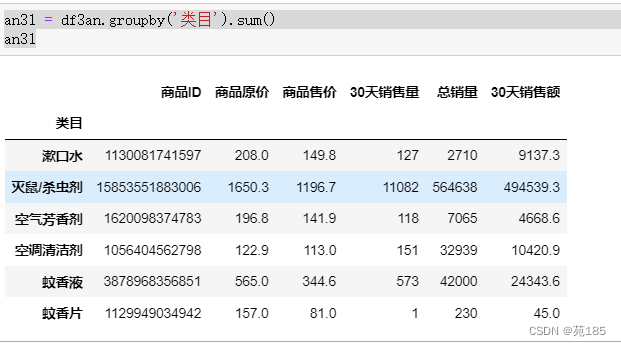
an31 = df3an.groupby('类目').sum()
an31
kl31 = df3kl.groupby('类目').sum()
kl31
#饼图 [0,1,2]
fig,axes = plt.subplots(1,3,figsize=(10,6))
ax = axes[0] #第一个拜耳
bai31['销售额'].plot.pie(autopct='%.f',title='拜耳',startangle=30,ax=ax)
ax.set_ylabel('')
ax = axes[1] #第二个安速
an31['30天销售额'].plot.pie(autopct='%.f',title='安速',startangle=60,ax=ax)
ax.set_ylabel('')
ax = axes[2] #第三个科凌虫控
kl31['30天销售额'].plot.pie(autopct='%.f',title='科凌虫控',startangle=90,ax=ax)
ax.set_ylabel('')
plt.show()
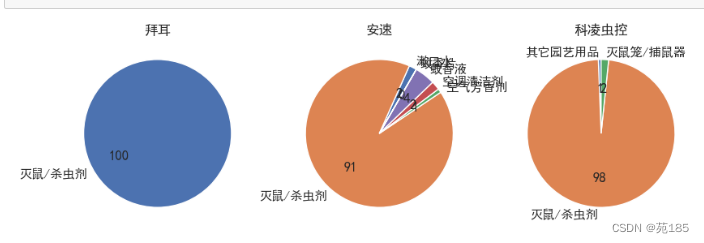
可见拜耳只有一个市场,其他的有不同市场,但主要市场都是灭鼠杀虫剂
竞争分析-品类分布-适用对象
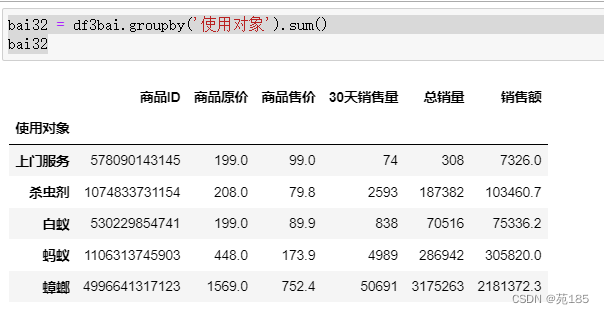
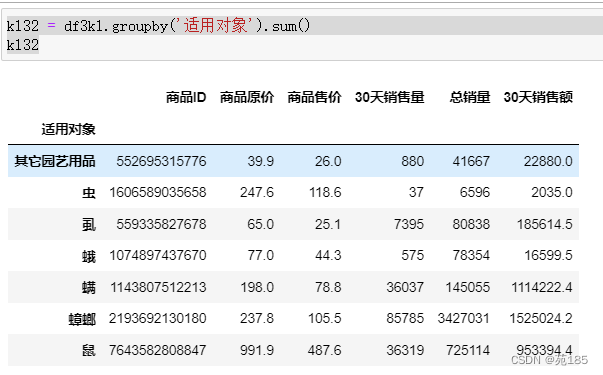
bai32 = df3bai.groupby('使用对象').sum()
bai32
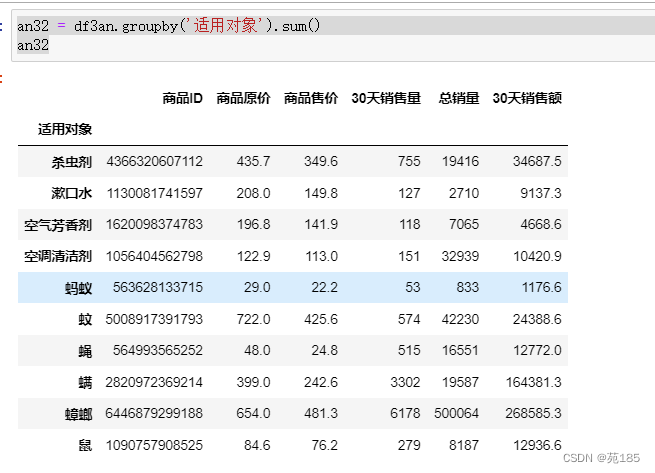
an32 = df3an.groupby('适用对象').sum()
an32
kl32 = df3kl.groupby('适用对象').sum()
kl32
#饼图 [0,1,2]
fig,axes = plt.subplots(1,3,figsize=(10,6))
ax = axes[0] #第一个拜耳
bai32['销售额'].plot.pie(autopct='%.f',title='拜耳',startangle=30,ax=ax)
ax.set_ylabel('')
ax = axes[1] #第二个安速
an32['30天销售额'].plot.pie(autopct='%.f',title='安速',startangle=60,ax=ax)
ax.set_ylabel('')
ax = axes[2] #第三个科凌虫控
kl32['30天销售额'].plot.pie(autopct='%.f',title='科凌虫控',startangle=90,ax=ax)
ax.set_ylabel('')
plt.show()
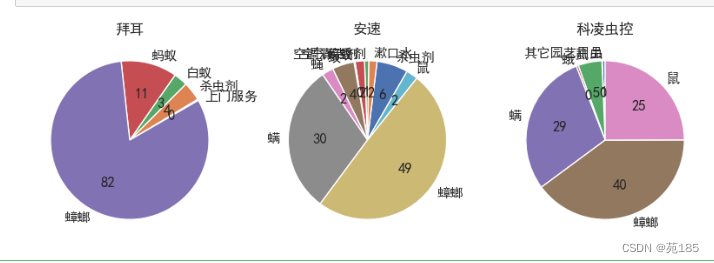
- 拜耳的主要对象是蟑螂,而另外两家除此之外还有螨,鼠
- 而从之前的分析看灭鼠和蟑螂的整体市场份额都大
- 应该开拓新市场,尤其是灭鼠,也考察其他两家都开拓的螨市场
竞争分析-产品结构-拜耳
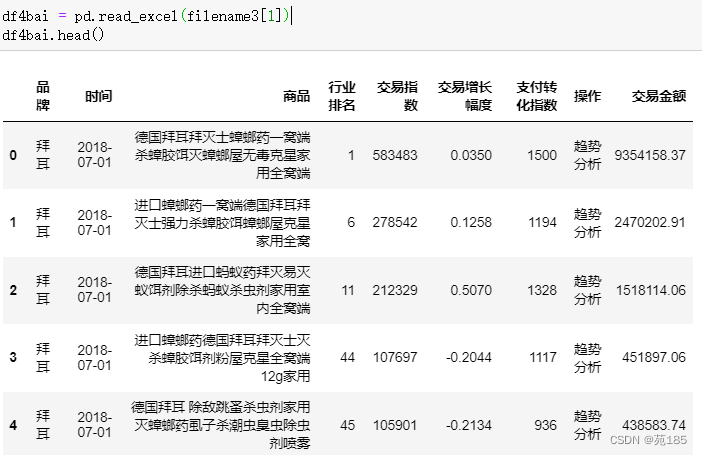
- 使用商品交易数据,每个竞争者分开分析,先分析拜耳的数据
- 包含五个月的数据,每个商品至多五个月都有,至少有一个月,故需要对商品分类汇总, 如下为分类汇总前五行结果
os.chdir('..')
os.chdir('./商品交易数据')
filename3 = glob.glob('*.xlsx')
filename3

拜耳数据:使用商品交易数据,每个竞争者分开分析,先分析拜耳的数据
df4bai = pd.read_excel(filename3[1])
df4bai.head()
df4bai.info()
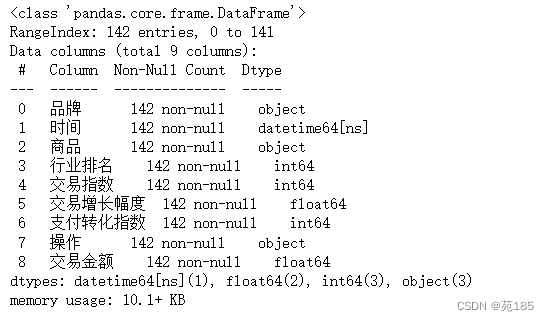
5个月的数据,每个商品最多5个月都在卖,至少有1个月,所以需要对商品分类汇总
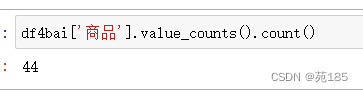
df4bai['商品'].value_counts().count()
#自定义分类汇总函数
def byproduct(df):
dfb = df.groupby('商品').mean().loc[:,['交易增长幅度']] #交易增长幅度做均值
dfb['交易金额'] = df.groupby('商品').sum()['交易金额']
dfb['交易金额占比'] = dfb['交易金额']/dfb['交易金额'].sum()
dfb['商品个数'] = df.groupby('商品').count()['交易金额']
dfb.reset_index(inplace= True)
return dfb
bai4 = byproduct(df4bai)
bai4.head()
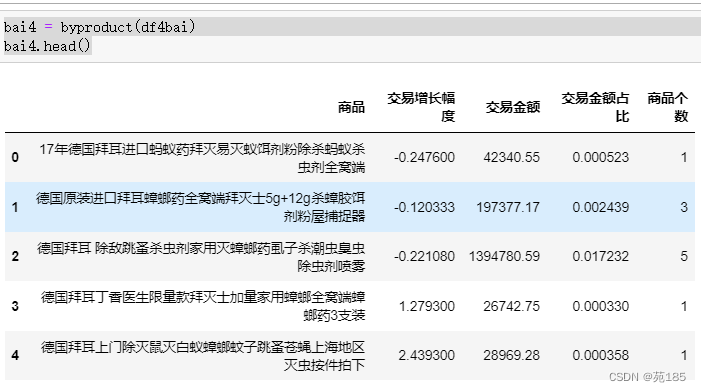
其中交易增长幅度可表示市场发展率,交易金额占比可表示市场份额
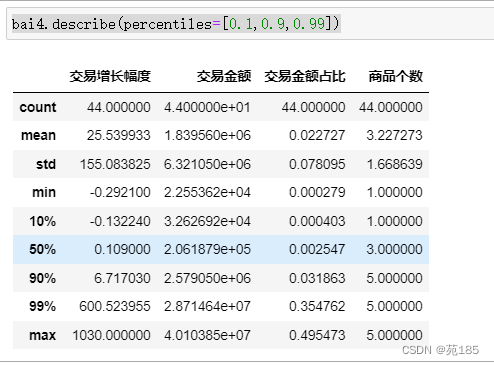
bai4.describe(percentiles=[0.1,0.9,0.99])
def block(x):
qu = x.quantile(.9)
out = x.mask(x>qu,qu) #当大于90%分位数的进行替换
return(out)
def block2(df):
df1 = df.copy()
df1['交易增长幅度'] = block(df1['交易增长幅度']) #使用盖帽法进行替换交易增长幅度
df1['交易金额占比'] = block(df1['交易金额占比']) #使用盖帽法进行替换交易增长幅度
return df1
bai41 = block2(bai4)
bai41.describe(percentiles=[0.1,0.9,0.99])
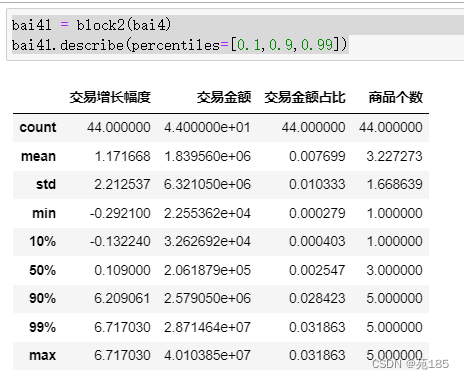
交易增长幅度和交易金额占比这两个指标的最大值都远大于3/4分位数,认为是异常值,考虑引入盖帽法,方便作图。
竞争分析-产品结构-拜耳-BCG图
定义波士顿矩阵绘图函数 可以使用均值、中位数来分割(0.33 0.33) 作为波士顿矩阵的切割线。
# mean True 均值
# mean False 中位数来分割(0.33 0.33)
def plotBOG(df,mean = False,q1=0.5,q2=0.5):
f,ax = plt.subplots(figsize=(10,8))
ax = sns.scatterplot('交易金额占比','交易增长幅度',hue='商品个数',size='商品个数',
sizes=(20,200),palette='cool',legend='full',data=df)
#给所有的点加行索引,点对应的是行数据(对应商品),方便探索
for i in range(0,len(df)):
ax.text(df['交易金额占比'][i]+0.001,df['交易增长幅度'][i],i) #索引标注相对于x轴右移
if mean:
plt.axvline(df['交易金额占比'].mean())#垂线
plt.axhline(df['交易增长幅度'].mean())#水平线
else:
plt.axvline(df['交易金额占比'].quantile(q1))#垂线
plt.axhline(df['交易增长幅度'].quantile(q2))#水平线
plt.show()
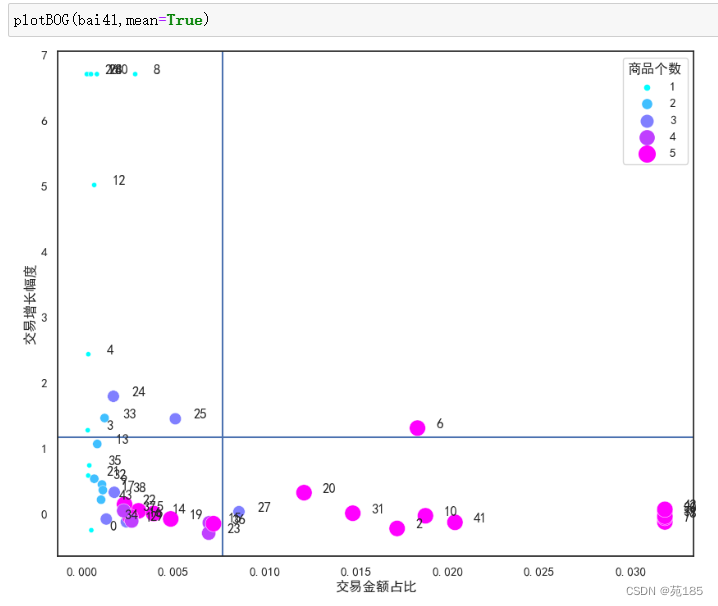
plotBOG(bai41,mean=True)
plotBOG(bai41,mean=False)
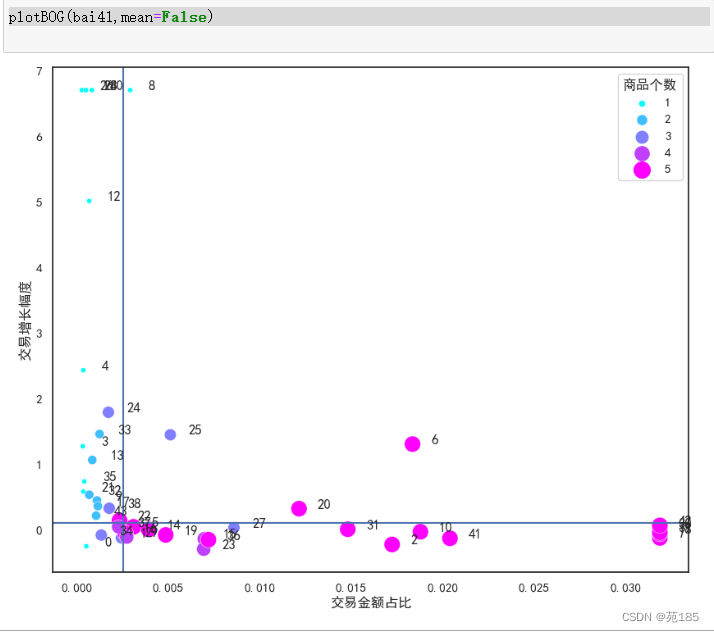
我们可以根据实际的业务选择区间的分隔线,由行业经验确定(例如认为增幅0.1在行业里算高,就可以作为分隔线)
从图可以看出:
明星产品和奶牛产品的商品个数普遍比较多。
没有突出的明星产品,但是有快进入明星产品的问题产品。
竞争分析-产品结构-拜耳-明星
查看各个产品结构的产品(除了瘦狗)
各种产品排序,关心点不同,排序依据不同
明星产品:都关心,依什么排序都可以,产品一般不多 奶牛产品:老爆款,关心市场份额,依交易金额占比排序 问题产品,潜力款,关心市场增长率,依交易增长幅度排序。
这里要查看实际数据,故使用盖帽前数据,拜耳明星产品如下:
def extractBOG(df,q1=0.5,q2=0.5,by='交易金额占比'):
# 明星产品
star = df.loc[(df['交易金额占比'] >= df['交易金额占比'].quantile(q1))#交易金额大于0.5
& (df['交易增长幅度'] >= df['交易增长幅度'].quantile(q2)),:] #交易增长幅度大于0.5
star = star.sort_values(by,ascending=False)
# 爆款产品
cow = df.loc[(df['交易金额占比'] >= df['交易金额占比'].quantile(q1))#交易金额大于0.5
& (df['交易增长幅度'] < df['交易增长幅度'].quantile(q2)),:] #交易增长幅度小于0.5
cow = cow.sort_values(by,ascending=False)
# 问题产品
que = df.loc[(df['交易金额占比'] < df['交易金额占比'].quantile(q1))#交易金额小于0.5
& (df['交易增长幅度'] >= df['交易增长幅度'].quantile(q2)),:] #交易增长幅度大于0.5
que = que.sort_values(by,ascending=False)
return star,cow,que
bai4star,bai4cow,bai4que = extractBOG(bai4)
bai4star
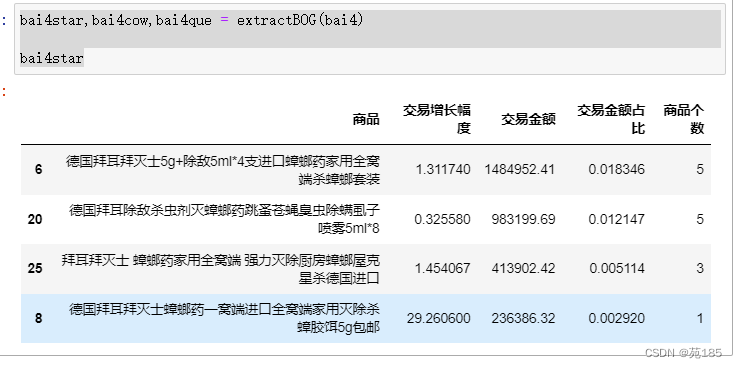
主要是除蟑和杀虫,但是占比不大,增幅一般。
竞争分析-产品结构-拜耳-奶牛
bai4cow
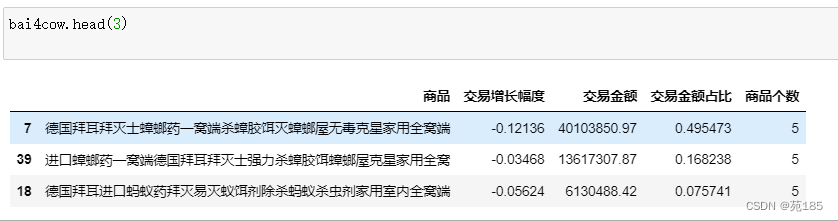
可见占比最高的是除蟑,灭虫也占一部分,占比一般。
竞争分析-产品结构-拜耳-问题
bai4que
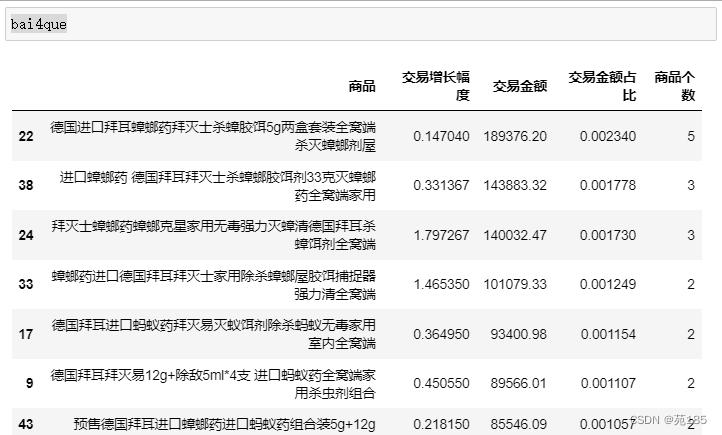
· 可见大部分仍然是灭蟑和杀虫 · 交易增长幅度最大的是灭鼠,而之前描述过灭鼠有最高的市场份额,可以作为下一步着 力点 · 总结:拜耳大部分产品集中在除蟑上,杀虫也有一定的规模,但是明星产品略乏力,可以 进一步发展问题产品灭鼠为明星产品。
总结:拜耳大部分产品集中在除蟑上,杀虫也有一定的规模,但是明星产品略乏力,可以进一步发展问题产品灭鼠为明星产品。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









