



1.Mysql实战
1.1我们先创建一个数据库
-- 创建“京东”数据库,指定字符集为UTF-8
create database jing_dong charset=utf8;
-- 使用“京东”数据库
use jing_dong;
-- 创建一个商品goods数据表
create table goods(
id int unsigned primary key auto_increment,
name varchar(150) not null,
cate_name varchar(40) not null,
brand_name varchar(40) not null,
price decimal(10,3) not null default 0,
is_show bit not null default 1,
is_saleoff bit not null default 0
);
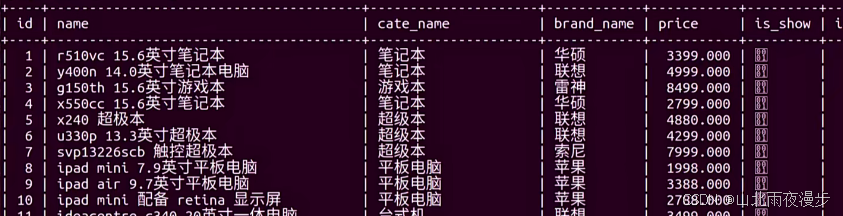
-- 向goods表中插入数据(这里只展示部分,实际应按图中完整插入)
insert into goods values(0,'r510vc 15.6英寸笔记本','笔记本','戴尔',0,1,0);
insert into goods values(0,'y400n 14.0英寸笔记本','笔记本','联想',0,1,0);
insert into goods values(0,'g150th 15.6英寸游戏本','游戏本','雷神',0,1,0);
有以下需求:
-- sql强化演练( goods 表练习)
-- 查询类型 cate_name 为 '超级本' 的商品名称 name 、价格 price ( where )
select name,price from goods where cate_name="超级本";
-- 显示商品的种类
-- 1 分组的方式( group by )
select cate_name from goods group by cate_name;
-- 2 去重的方法( distinct )
select distinct cate_name from goods;
-- 求所有电脑产品的平均价格 avg ,并且保留两位小数( round )
select round(avg(price),2) from goods;
-- 显示 每种类型 cate_name (由此可知需要分组) 的 平均价格
select avg(price),cate_name from goods group by cate_name;
-- 查询 每种类型 的商品中 最贵 max 、最便宜 min 、平均价 avg 、数量 count
select cate_name,max(price),min(price),avg(price),count(*) from goods group by cate_name;
-- 查询所有价格大于 平均价格 的商品,并且 按 价格降序 排序 order desc
-- 1 查询平均价格(avg_price)
select avg(price) as avg_price from goods;
-- 2 使用子查询
select * from goods where price>(select avg(price) as avg_price from goods) order by price desc;
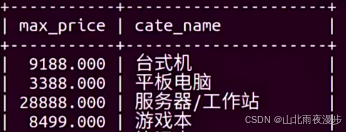
看一个难的:我们无法直接得到每种类型中最贵的,这个例子告诉我们使用内连接可以起到数据筛选的作用。
-- 查询每种类型中最贵的电脑信息(难)
-- 1 查找 每种类型 中 最贵的 max_price 价格
select max(price) as max_price,cate_name from goods group by cate_name;
-- 2 关联查询 inner join 每种类型 中最贵的物品信息
-- select * from goods
-- inner join
-- (select cate_name,max(price) as max_price from goods group by cate_name) as max_price_goods
-- on goods.cate_name=max_price_goods.cate_name and goods.price=max_price_goods.max_price;
select * from goods
inner join
(select max(price) as max_price,cate_name from goods group by cate_name) as max_price_goods
on goods.cate_name=max_price_goods.cate_name and goods.price=max_price_goods.max_price;
good表:
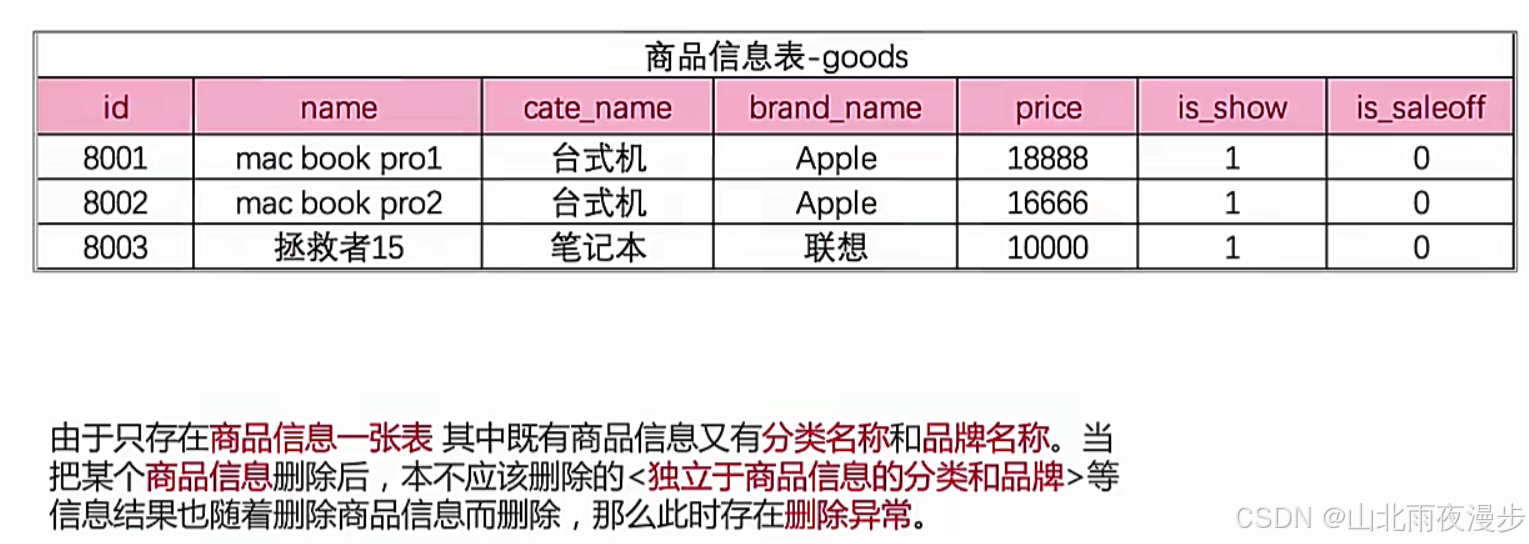
1.2由删除引发的异常
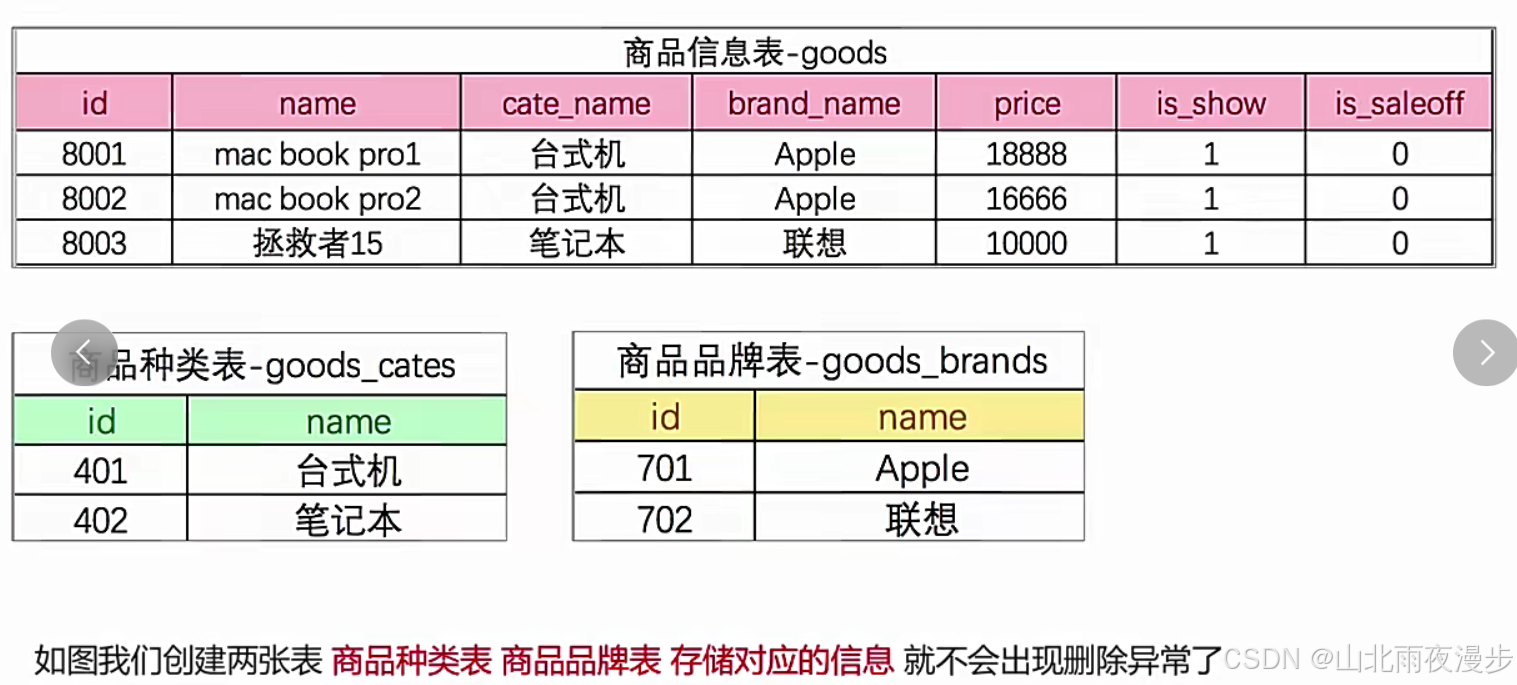 而且如果apple变成了华为,我们直接在品牌表里进行更改就可以了,避免对原表进行大量修改。我们可以这样做:
而且如果apple变成了华为,我们直接在品牌表里进行更改就可以了,避免对原表进行大量修改。我们可以这样做:
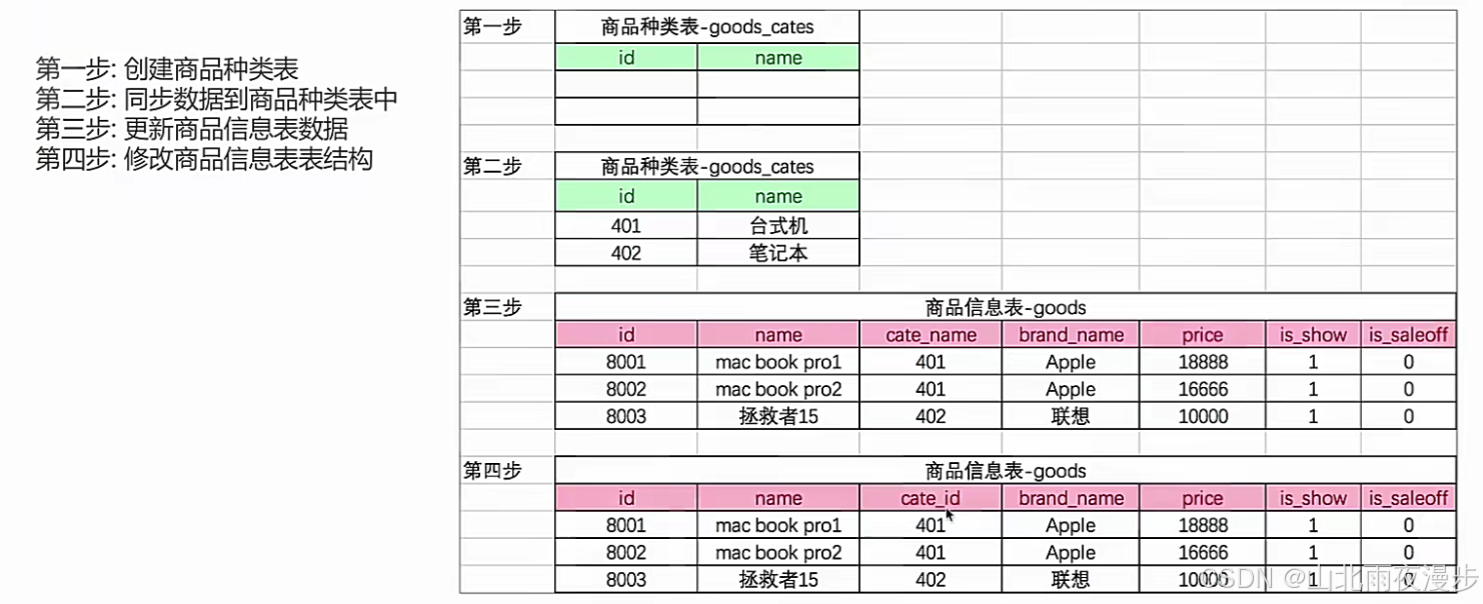
-- 创建"商品分类"表
-- 第一步 创建表(商品种类表 goods_cates )
create table if not exists goods_cates(
id int unsigned primary key auto_increment,
name varchar(40) not null
);
-- 第二步 同步 商品分类表 数据 将商品的所有(种类信息)写入到(商品种类表)中
-- 按照 分组 的方式查询 goods 表中的所有 种类(cate_name)
select cate_name from goods group by cate_name;
insert into goods_cates(name) (select cate_name from goods group by cate_name);
-- 第三步 同步 商品表 数据 通过 goods_cates 数据表来更新 goods 表
-- 因为要通过 goods_cates表 更新 goods 表 所以要把两个表连接起来
select * from goods inner join goods_cates on goods.cate_name=goods_cates.name;
-- 把 商品表 goods 中的 cate_name 全部替换成 商品分类表中的 商品id ( update... set )
update goods inner join goods_cates on goods.cate_name=goods_cates.name set goods.cate_name=goods_cates.id;
-- 第四步 修改表结构
-- 查看表结构(注意 两个表中的 外键类型需要一致)
desc goods;
-- 修改表结构 alter table 字段名字不同 change,把 cate_name 改成 cate_id int unsigned not null
alter table goods change cate_name cate_id int unsigned not null;
第一行if not exists 表示如果没有才会创建。
第三行 我们的种类表id是自己增长的,只需要插入name即可,当我们一次性加入时不需要加values了。
2.外键
外键(Foreign Key)是数据库中的一个重要概念,用于建立表与表之间的关联关系,
- 定义:外键是一个表中的一个或多个字段,它的值必须匹配另一个表(通常称为 “主表” 或 “父表”)中的主键值或唯一键值 。例如,在 “订单表” 中有个 “用户 ID” 字段,它关联 “用户表” 中的 “ID” 主键字段,这里 “订单表” 中的 “用户 ID” 就是外键。
- 作用:
- 数据完整性:确保相关表之间的数据一致性。比如在上述例子中,如果 “订单表” 中的 “用户 ID” 值在 “用户表” 的 “ID” 中不存在,数据库会根据设置阻止该订单数据插入或更新,避免出现无效关联。
- 建立关系:清晰地表示表与表之间的联系,方便进行连接查询等操作。例如要查询某个用户的所有订单,就可以通过 “用户 ID” 这个外键关联 “用户表” 和 “订单表” 来获取数据。
- 约束规则:当主表中的主键值发生变化(如更新或删除)时,外键约束可以设置不同的处理方式,常见的有:
- 级联更新:若主表的主键值更新,从表中对应的外键值也会自动更新。
- 级联删除:当主表中的记录被删除时,从表中关联的记录也会被自动删除。
- 限制更新 / 删除:如果从表中有相关的外键记录,主表中的主键值不能被更新或删除。
- 置空:当主表中的记录被删除或主键值更新时,从表中对应的外键值会被设置为 NULL(前提是外键字段允许为空) 。
-- 外键的使用
-- 向goods表里插入任意一条数据
insert into goods (name,cate_id,brand_id,price) values('老王牌拖拉机', 10, 10,'6666');
-- 约束 数据的插入 使用 外键 foreign key
-- alter table goods add foreign key (brand_id) references goods_brands(id);
alter table goods add foreign key(cate_id) references goods_cates(id);
alter table goods add foreign key(brand_id) references goods_brands(id);
-- 失败原因 老王牌拖拉机 delete
-- delete from goods where name="老王牌拖拉机";
delete from goods where name="老王牌拖拉机";
-- 如何取消外键约束
-- 需要先获取外键约束名称,该名称系统会自动生成,可以通过查看表创建语句来获取名称
show create table goods;
-- 获取名称之后就可以根据名称来删除外键约束
alter table goods drop foreign key goods_ibfk_1;
alter table goods drop foreign key goods_ibfk_2;

3. 视图
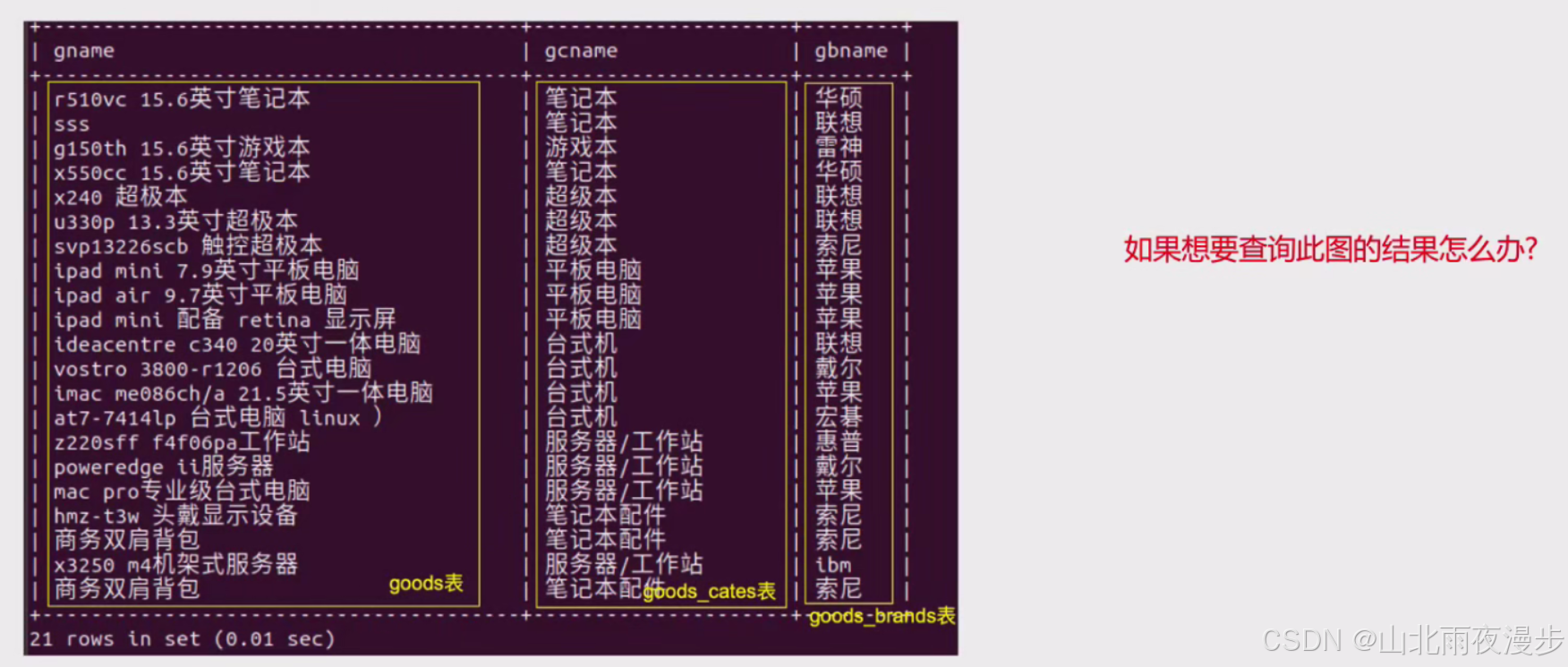
这是用三个表内连接形成的一个新表。但是我们如果要用这个表就会很麻烦,因为我们需要再一次打代码。

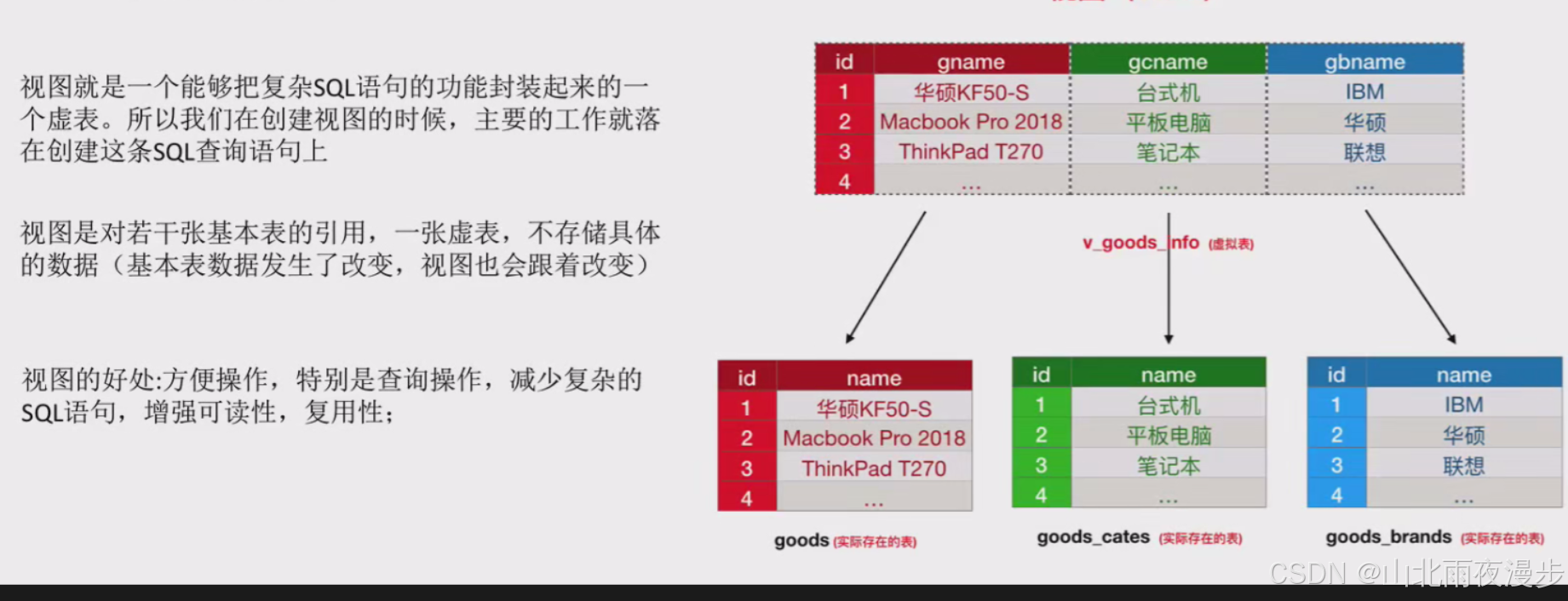
- 定义:视图是一种虚拟的表,它封装了复杂 SQL 语句的功能。它并不实际存储数据,而是基于一个或多个基本表(真实存在的数据表)的查询结果来构建。例如,将多个表的连接查询封装成一个视图,用户后续可直接查询视图,而不用每次都写复杂的连接语句。
- 数据更新特性:由于视图是基于基本表构建的,当基本表中的数据发生变化时,视图查询出的结果也会相应改变。比如基本表中某条记录被修改或删除,再次查询视图时,其呈现的数据会反映这些变化。
- 优点:在操作上,尤其是查询时能带来便利。它可以将复杂的查询逻辑隐藏起来,简化用户的操作,提高 SQL 语句的可读性。而且视图可以被多次复用,在不同的查询场景中直接使用,避免重复编写复杂的查询代码
以下是实现的方法,视图创建完成后就可以当做一个表去使用它。
-- 视图的作用
-- 视图的定义方式
create view 视图名称(一般使用V开头) as select语句;
-- 查出学生的id,姓名,年龄,性别 和 学生的 班级
select s.id,s.name,s.age,s.gender,c.name as cls_name
from students as s
inner join classes as c
on s.cls_id=c.id;
-- 创建上述结果的视图( v_students )
create view v_students as
select s.id,s.name,s.age,s.gender,c.name as cls_name
from students as s
inner join classes as c
on s.cls_id=c.id;
-- 删除视图 (drop view 视图名字)
drop view v_students;
4.事务
- 作用:
- 确保数据一致性和完整性:事务将多个操作视为一个整体,要么全部成功提交,使数据库状态保持一致;要么全部失败回滚,避免出现部分操作成功导致的数据不一致问题,保障数据的完整性。比如在银行转账场景中,从一个账户扣款和向另一个账户存款是一个事务,要么两者都成功,要么都不执行,防止资金出现错误增减。
- 控制并发访问:在多用户并发访问数据库时,事务提供隔离机制,防止不同事务的操作相互干扰,保证每个事务都能得到正确结果,避免数据冲突和不一致。例如多个用户同时对同一账户进行操作,事务可以确保操作的准确性和数据的一致性。
- 特点(ACID 特性):
- 原子性(Atomicity):事务中的所有操作是一个不可分割的整体,要么全部执行成功,要么全部回滚,不存在部分成功部分失败的情况。
- 一致性(Consistency):事务执行前后,数据库都必须处于一致性状态,即满足预定的完整性约束。比如转账事务,转账前后的总金额应保持不变。
- 隔离性(Isolation):各个事务的执行相互隔离,一个事务的执行不会被其他事务干扰,其内部操作和使用的数据对其他并发事务不可见。根据隔离程度不同,有读未提交、读已提交、可重复读、串行化等隔离级别。
- 持久性(Durability):一旦事务提交,对数据库中数据的修改就是永久性的,即便系统出现故障(如断电、硬件损坏等),数据也不会丢失。
- 结构:事务通常以特定语句开始和结束,在不同数据库系统中具体语法略有差异,常见结构如下:
- 开始事务:如在 SQL Server 中使用
BEGIN TRANSACTION,表示一个事务的开始,后续的数据库操作都将纳入该事务管理。 - 事务操作:包含一系列对数据库的增、删、改、查等操作,这些操作会依据业务逻辑进行组合。
- 提交或回滚事务:
- 提交事务:使用
COMMIT语句,将事务中对数据库的更新永久保存到物理数据库中。当事务内所有操作都成功完成后,执行此操作。 - 回滚事务:使用
ROLLBACK语句,当事务执行过程中遇到错误或异常时,将撤销事务已经执行的所有操作,使数据库恢复到事务开始前的状态 。
- 提交事务:使用
- 开始事务:如在 SQL Server 中使用
实例:

- 原子性和一致性示例
- 操作流程:在终端 1 中,先使用
begin开启事务,接着执行update语句修改数据,此时终端 1 查询发现数据改变,但实际上修改暂存于缓存。终端 2 查询数据,发现数据未变。当终端 1 执行commit提交事务后,终端 2 再次查询,数据才改变。 - 原理:体现事务的原子性,事务中的操作在提交前处于未确定状态,提交后才会一次性使数据库状态发生改变,保证数据一致性。
- 操作流程:在终端 1 中,先使用
- 隔离性示例
- 操作流程:终端 1 和终端 2 都开启事务,终端 1 先执行
update语句,此时终端 2 也执行update语句会处于阻塞状态。直到终端 1 执行commit提交事务,终端 2 的阻塞状态解除,完成数据修改。 - 原理:展示事务的隔离性,一个事务的操作执行过程中会阻止其他事务对相同数据的操作,防止并发操作导致的数据不一致。
- 操作流程:终端 1 和终端 2 都开启事务,终端 1 先执行
- 回滚示例
- 操作流程:终端 1 开启事务后执行
update语句修改数据,执行rollback回滚操作后,数据恢复到初始状态。 - 原理:体现事务回滚机制,当事务执行中出现问题,通过
rollback可撤销事务内已执行的操作,让数据回到事务开始前的状态。
- 操作流程:终端 1 开启事务后执行
- 注意事项:图片指出
innodb存储引擎能使用事务,说明事务功能依赖于数据库的存储引擎支持
5.索引
索引是数据库中用于快速定位和访问数据的一种数据结构,类似于书籍的目录,能大大提高数据查询效率
作用
- 加速查询:无需扫描全表,通过索引可快速定位到所需数据的位置,显著缩短查询时间。比如在一个有大量用户记录的表中查询特定用户,若基于用户 ID 创建索引,就能快速找到对应记录。
- 保证数据唯一性:唯一索引可确保表中特定字段的值不会重复,如身份证号字段设置为唯一索引,能避免录入重复的身份证号。
- 支持排序和分组操作:在对数据进行排序(
ORDER BY)或分组(GROUP BY)时,若相关字段有索引,数据库可利用索引快速完成操作,提升性能。
特点
- 占用存储空间:索引会占用一定的磁盘空间,创建过多或不合理的索引会导致数据库占用空间增大。
- 维护成本:当表中的数据发生增、删、改操作时,索引需要相应更新,这会消耗额外的系统资源,增加数据库的维护成本。
常见类型
- B-tree 索引:最常见的索引类型,适用于大多数场景,支持范围查询、排序等操作,如在 MySQL 的 InnoDB 和 MyISAM 存储引擎中广泛应用。
- 哈希索引:通过哈希函数计算数据值的哈希码来定位数据,查询速度极快,适合等值查询。但不支持范围查询,且在数据量大时可能出现哈希冲突。
- 全文索引:专门用于文本数据的搜索,能快速查找包含特定关键词的文本记录,常用于搜索引擎、文章检索等场景。
创建与使用
- 创建索引:使用
CREATE INDEX语句创建普通索引,如CREATE INDEX idx_name(索引名) ON table_name (column_name){表名(字段)};;创建唯一索引则用CREATE UNIQUE INDEX。 - 使用索引:创建索引后,数据库查询优化器会根据查询条件和索引情况,自动决定是否使用索引来执行查询。但在一些复杂查询中,可能需要优化查询语句,以确保索引被正确使用。
以下以 MySQL 数据库为例,展示几种常见索引的创建和使用代码实例:
1. 创建表
首先创建一个简单的students表,用于后续演示索引的操作。
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
age INT,
email VARCHAR(100)
);
2. B - tree 索引
B - tree 索引是最常用的索引类型,适用于范围查询、排序等操作。
在上述代码中,CREATE INDEX语句创建了一个名为idx_name的索引,基于students表的name字段。后续的SELECT查询语句在name字段上进行条件筛选时,数据库有可能会使用这个索引来加速查询。
3. 唯一索引
唯一索引可以确保索引列中的值是唯一的。
-- 创建基于email字段的唯一索引
CREATE UNIQUE INDEX idx_email ON students (email);
-- 尝试插入两条相同email的记录
INSERT INTO students (name, age, email) VALUES ('Alice', 20, 'alice@example.com');
INSERT INTO students (name, age, email) VALUES ('Bob', 22, 'alice@example.com'); -- 这行会报错,因为email值重复违反唯一索引约束
这里创建了idx_email唯一索引,当尝试插入两条具有相同email值的记录时,第二条插入语句会失败,因为违反了唯一索引的约束。
4. 全文索引(了解)
全文索引主要用于文本数据的搜索。假设students表中的name字段存储的是学生的全名,现在要进行全文搜索。
-- 修改表引擎为支持全文索引的MyISAM(InnoDB从MySQL 5.6版本开始也支持全文索引,但语法略有不同)
ALTER TABLE students ENGINE = MyISAM;
-- 创建基于name字段的全文索引
CREATE FULLTEXT INDEX idx_name_fulltext ON students (name);
-- 使用MATCH AGAINST进行全文搜索
SELECT * FROM students WHERE MATCH(name) AGAINST('John' IN NATURAL LANGUAGE MODE);
上述代码先将表引擎修改为 MyISAM(适合演示全文索引,InnoDB 的全文索引配置可按需调整),然后创建全文索引idx_name_fulltext。最后使用MATCH AGAINST语句进行全文搜索,查找名字中包含John的学生记录。

















 4642
4642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









