




达人探店
接下来实现“达人探店”功能。这个功能可以理解为到店体验并分享的过程。
这一章我们将分为三个小节:
- 第一小节是发布探店笔记,把拍的照片和相关文字发出去,让别人查看;
- 第二小节是点赞功能,如果有人看了你的笔记觉得满意可以点赞,点赞越多排名越靠前。
- 第三小节是点赞排行榜功能。
探店笔记
发布探店笔记
首先来实现"发布探店笔记"功能。探店笔记类似于以往的评价,但比评价更丰富,因为它图文结合更容易吸引目光。相关的表有两张:
- tp_blog,探店笔记表,包含了笔记的标题、文字、图片等详细信息;
- tb_blog_comments,其他用户对探店笔记的评价信息。
在我们发布探店图文时,主要关注第一张表。tp_blog表的结构包括主键id、商户shop_id(即你发布的笔记与哪个商户有关)、用户user_id(即谁发的这篇笔记)、标题、照片(最多不超过九张,多个以逗号隔开,作为一个字段包含多张图片)、内容(探店的文字描述)、点赞数量和评论数量,以及创建时间和更新时间。其中最核心的是标题、图片、内容和关联的店铺信息。
在首页点击最下方的"+"按钮,会弹出一个新页面去发布一个新的笔记。可以看到页面上有照片、标题和内容(文字描述)等核心元素。选择关联哪个商户后,点击发布就发出去了。
需要注意的是,发布照片和发布笔记这两个功能是分离的,因为上传照片的功能不仅发笔记时有需求,其他业务也有需求。所以上传照片是一个独立的功能。点击上传照片时,会先发出一个请求实现上传,上传成功后返回图片的地址,这个地址将来作为表单的参数在发布笔记时一起提交到后台。
我们有两个接口已经实现好了,我们依次来介绍。
首先是上传图片,UploadController中的uploadImage()方法负责接收图片并保存。一般会保存至文件服务器,但我们不关注文件上传,只关注Redis,因此将其简化为直接保存至本地的前端服务器的html\hmdp\imgs目录下。原项目中定义了一个文件上传的dir:image.transferTo(new File(SystemConstants.IMAGE_UPLOAD_DIR, fileName));,因为每个人的nginx安装目录都不一样,所以要将字符串IMAGE_UPLOAD_DIR改为自己的存储路径。
@PostMapping("blog")
public Result uploadImage(@RequestParam("file") MultipartFile image) {
try {
// 获取原始文件名称
String originalFilename = image.getOriginalFilename();
// 生成新文件名
String fileName = createNewFileName(originalFilename);
// 保存文件
image.transferTo(new File(SystemConstants.IMAGE_UPLOAD_DIR, fileName));
// 返回结果
log.debug("文件上传成功,{}", fileName);
return Result.ok(fileName);
} catch (IOException e) {
throw new RuntimeException("文件上传失败", e);
}
}
public class SystemConstants {
public static final String IMAGE_UPLOAD_DIR = "nginx存储路径\\html\\hmdp\\imgs\\";
......
}
然后是上传博客,BlogController中的saveBlog()方法负责保存博客信息。其会先获取登录用户的id,然后根据id获取用户的信息,最后和前端提交过来的店铺id、标题、图片和内容一起保存到数据库中。
@PostMapping
public Result saveBlog(@RequestBody Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 保存探店博文
blogService.save(blog);
// 返回id
return Result.ok(blog.getId());
}
接下来测试该功能。点击加号,会弹到发布新笔记的页面,上传图片,控制台会显示图片的上传地址,打开对应路径可找到该图片。
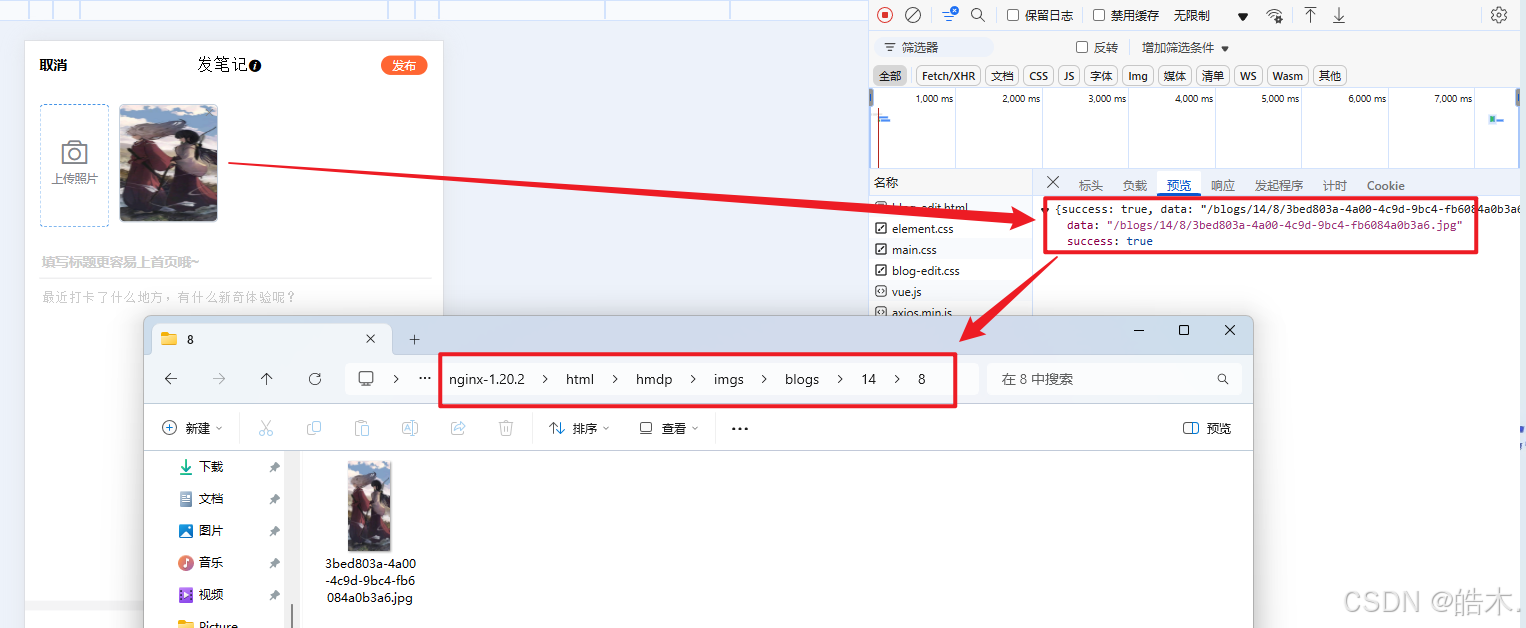
然后填写标题和内容,最后关联一个商户,最后点击发布。发布成功后,会跳到我的个人主页,在个人主页的笔记里就能看到刚刚发布的笔记。在首页也能看到刚刚发布的笔记,这样就实现了发布探店图文的功能。
查看笔记详情
在首页点击某个笔记进入详情页时,因为还未实现查询笔记详情的功能,所以系统会报错。我们需要实现该接口。
该接口请求方法为get,请求路径为/blog/{id},id为blog的id。返回Blog类。因为每一篇探店笔记都包含用户信息,因此在详情页面展示时,除了展示图片、标题和内容以外,还需要展示发布这篇笔记的用户信息。这样其他用户看到这篇笔记后,如果感兴趣,就可以直接关注当前的用户。所以返回的信息包括笔记信息和用户信息。
为了实现该功能,我们有两种选择。第一种是在Blog类中添加一个User的成员变量,将查询到的用户信息存进去。第二种则是简化的方法,就是在Blog类中添加了两个字段:icon和name,分别用来存储用户的图标和姓名。这两个字段不属于Blog表,因此添加了@TableField(exist = false)注解来标识。
接下来实现该接口。在BlogController中编写queryBlogById()方法用于处理查询请求。这个接口之前没有实现过,所以我们需要重新编写。接口的路径是"blog"后面跟上ID,返回值是我们统一的Result对象。
在实现接口的过程中,我们需要查询Blog中的用户信息。上方的queryHotBlog()已经有一个查询博客的功能了,其中也包含查询对应用户信息的逻辑。因此我们可以借鉴这个功能来实现当前的接口。同时因为Controller中不应该包含太多的业务逻辑,而BlogServiceImpl的queryHotBlog()的逻辑过于复杂,应该放到Service中去实现。
//BlogController——————————————————————————————
@RestController
@RequestMapping("/blog")
public class BlogController {
......
@GetMapping("/hot")
public Result queryHotBlog(@RequestParam(value = "current", defaultValue = "1") Integer current) {
return blogService.queryHotBlog(current);
}
@GetMapping("/{id}")
public Result queryBlogById(@PathVariable("id") Long id) {
return blogService.QueryBlogById(id);
}
}
//IBlogService——————————————————————————————————
public interface IBlogService extends IService<Blog> {
Result queryHotBlog(Integer current);
Result QueryBlogById(Long id);
}
在QueryBlogById()中先根据id查询Blog,然后再根据id查询用户名称和头像,最后将用户信息写入Blog,再封装到Result对象中并返回即可。可以将查询相关用户信息并写入的逻辑封装到一个方法中,然后在queryHotBlog()和QueryBlogById()中调用这个方法即可。
@Service
public class BlogServiceImpl extends ServiceImpl<BlogMapper, Blog> implements IBlogService {
@Resource
private IUserService userService; // 注入用户服务接口
/**
* 查询热门博客
* @param current 当前页码
* @return 返回封装了博客列表的结果对象
*/
@Override
public Result queryHotBlog(Integer current) {
// 分页查询博客,按点赞数降序排列
Page<Blog> page = query()
.orderByDesc("liked")
.page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页的博客数据
List<Blog> records = page.getRecords();
// 遍历博客列表,为每篇博客查询并设置相关用户信息
records.forEach(this::queryBlogUser);
return Result.ok(records); // 返回成功结果和博客列表
}
/**
* 根据博客ID查询博客详情
* @param id 博客ID
* @return 返回封装了博客详情的结果对象
*/
@Override
public Result QueryBlogById(Long id) {
// 根据ID查询博客
Blog blog = getById(id);
if (blog == null) {
return Result.fail("笔记不存在"); // 如果博客不存在,返回失败结果
}
// 查询并设置博客相关用户信息
queryBlogUser(blog);
return Result.ok(blog); // 返回成功结果和博客详情
}
/**
* 为博客查询并设置相关用户信息
* @param blog 博客对象
*/
private void queryBlogUser(Blog blog) {
Long userId = blog.getUserId(); // 获取博客的用户ID
User user = userService.getById(userId); // 根据用户ID查询用户信息
blog.setName(user.getNickName()); // 设置博客的用户昵称
blog.setIcon(user.getIcon()); // 设置博客的用户头像
}
}
点击笔记进入详情页,就能够看到详细的笔记信息了。仍弹出的报错是与当前业务无关的其他接口问题。
点赞功能
在首页和笔记的详情页面,都有一个大拇指的按钮,只要点击这个按钮,就会向后台发起一个点赞请求。这个请求的路径是blog/like/{id},后面跟上的是笔记的ID。后台收到请求后,BlogController中的likeBlog()方法会将对应笔记的点赞数量加一。
@PutMapping("/like/{id}")
public Result likeBlog(@PathVariable("id") Long id) {
// 修改点赞数量 相当于UPDATE tb_blog SET liked = liked + 1 WHERE id = 指定的id;
blogService.update()
.setSql("liked = liked + 1").eq("id", id).update();
return Result.ok();
}
新发布的笔记的点赞数量是零,每当有人点赞,后台就会直接更新数据库中的这个数量。这会导致一个人可以无限次地点赞同一篇笔记,这显然是不合逻辑的。在我们的点赞业务逻辑中,一个用户对于同一篇笔记应该只能点赞一次。如果已经点赞过,再次点击就应该取消点赞。如果当前用户已经点赞,则点赞按钮高亮显示(前端已实现,判断字段Blog类的isLike属性)
首先,我们要给笔记类(Blog类)添加一个isLike字段,用来标识用户是否已经点赞过。然后在点赞业务中,我们需要先判断当前用户是否已经点赞过。这个判断可以通过Redis来实现。我们可以以笔记的ID为key,在Redis中记录给这个笔记点过赞的所有的用户ID。这样,下次用户再来点赞时,我们就可以先判断这个用户ID是否存在于Redis的集合中,从而决定是点赞还是取消点赞。-同时id又不能重复,必须唯一,Redis的set结构刚好满足这一要求。
具体实现时,我们需要修改点赞功能的逻辑。在用户点击点赞按钮时,先去Redis的集合中判断用户是否存在。如果不存在,则点赞数量加一,并将用户ID添加到Redis的集合中。如果用户已经存在则点赞数量减一,并将用户ID从Redis的集合中移除。
此外,我们还需要在根据id查询笔记、分页查询Blog时给isLike字段赋值,以判断当前用户是否点赞过。这个赋值操作可以在根据ID查询笔记详情和分页查询笔记列表时进行。我们可以通过判断用户ID是否在Redis的集合中来设置“is like”字段的值。
接下来修改代码。首先需要在Blog类中添加isLike字段(原项目已添加)。然后修改likeBlog()方法。
//BlogController——————————————————
@PutMapping("/like/{id}")
public Result likeBlog(@PathVariable("id") Long id) {
return blogService.likeBlog(id);
}
//IBlogService————————————————————
Result likeBlog(Long id);
//BlogServiceImpl—————————————————
@Override
public Result likeBlog(Long id) {
// 获取登录用户
Long userId = UserHolder.getUser().getId();
// 构建Redis中的key,用于存储该id的笔记的点赞状态
String key = BLOG_LIKED_KEY + id;
// 判断当前用户是否已点赞
Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
if (BooleanUtil.isFalse(isMember)) {
// 用户未点赞 允许点赞 数据库点赞数+1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 保存用户至Redis的set集合中
if (isSuccess) {// 执行Redis命令:SADD key userId
stringRedisTemplate.opsForSet().add(key, userId.toString());
}
} else {
// 用户已点赞 取消点赞 数据库点赞数-1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
// 删除Redis的set集合中的用户
if (isSuccess) {// 执行Redis命令:SREM key userId
stringRedisTemplate.opsForSet().remove(key, userId.toString());
}
}
return Result.ok();
}
然后还需修改查询Blog的方法,查询的值也需包含isLike。因为多个方法需要该功能,因此我们将其封装到一个新方法isBlogLike()中,传入一个Blog,根据Redis中该笔记的key对应的value中是否存在该用户id,来判断用户是否已点赞该笔记。
@Override
public Result queryHotBlog(Integer current) {
......
// 遍历博客列表,为每篇博客查询并设置相关用户信息
records.forEach(blog -> {
queryBlogUser(blog);
// 查询Blog是否被点赞
isBlogLike(blog);
});
return Result.ok(records); // 返回成功结果和博客列表
}
@Override
public Result QueryBlogById(Long id) {
......
isBlogLike(blog);
return Result.ok(blog); // 返回成功结果和博客详情
}
private void isBlogLike(Blog blog) {
// 获取当前登录用户的ID
UserDTO user = UserHolder.getUser();
if(user == null){
//用户未登录,无需查询是否点赞
return ;
}
Long userId = user.getId();
// 构建Redis中的key,用于存储该博客的点赞用户集合
String key = BLOG_LIKED_KEY + blog.getId() ;
// 使用Redis的Set数据结构查询当前用户是否已经点赞该博客
// 对应的Redis命令:SISMEMBER key userId
Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
// 设置博客的isLike属性,根据查询结果判断用户是否已点赞
// 如果isMember为true,则表示用户已点赞,设置isLike为true;否则为false
blog.setIsLike(BooleanUtil.isTrue(isMember));
}
此时即可实现一个用户只能点赞一次、点赞后高亮显示、Redis中存储对应数据。
点赞排行榜
接下来实现点赞的排行榜功能。这个排行榜会展示在探店笔记的详情页,所有图文信息的最下方。这个列表需要展示出给当前笔记点赞的用户信息。但一个笔记点赞的人可能会很多,由于空间有限,我们不可能展示出所有用户,所以我们将展示前几名的用户,比如前五名,即top 5,这样就形成了一个排行榜。该排行榜的排序方式可以按照点赞时间排序的,越早点赞就越靠前。
查看点赞列表的请求方法为GET,路径为blog/like/{id},ID为这篇笔记的ID,返回List集合,为点赞的前五名用户信息,泛型选择UserDTO(数据传输对象),因为DTO里把敏感信息都已经丢掉了,所以不用担心数据泄漏的风险。
之前实现点赞功能是基于Redis的set集合来实现的。也就是说我们需要去set集合里查询符合要求的用户信息。但set集合是无序的,我们只需要前五名,set集合无法满足。
目前为止,我们学习的Redis集合共有三种:set、list和sorted set。
| List | Set | SortedSet | |
|---|---|---|---|
| 排序方式 | 按添加顺序排序 | 无法排序 | 根据score值排序 |
| 唯一性 | 不唯一 | 唯一 | 唯一 |
| 查找方式 | 按索引查找或首尾查找 | 根据元素查找 | 根据元素查找 |
List集合可以排序的,因为它是个链表,只能按添加顺序排序。如果我们一直从同一侧插入信息,例如使用RPUSH,先点赞的在最前边,后点赞的在最后边,能够实现排序。
SortedSet集合,它是可以按score(分数)排序。也就是说存入SortedSet的元素,除了元素本身以外,还要附带一个score。这个score可以是用户自定义的任意东西,我们可以将时间戳作为score值存进去。添加越早,时间戳越小;添加越晚,时间戳越大。这样天然就带有一个按添加顺序排序了。
因此,从排序上来看,只有list和sorted set两个符合要求。
再从唯一性上来看,直接把list排除了,因为list是链表,无法保证数据的唯一性。但是set和sorted set都满足,因为他们底层都有一个哈希表,可以判断元素是否存在,从而把一些重复元素给剔除或者是覆盖。
最后从查找方式上来看,list底层是链表,只能按角标查找元素或者是首尾查找。想知道一个元素存不存在,只能是遍历一遍。Set和SortedSet底层采用的是哈希表,所以可以根据元素做哈希运算,快速定位到对应的那个数组位置,然后去判断是否存在。所以他们的查找更加高效。
所以从这三点来看,sorted set更符合我们的业务需求。接下来需要用SortedSet来代替set集合,改造我们之前的点赞业务。但sorted set虽然跟set类似,但还是存在差异的,很多的命令上是不一样的。之前我们使用set的时候,添加元素是用SADD,判断元素是否存在是用SISMEMBER。SortedSet添加元素一样也是SADD,但没有SISMEMBER用于判断元素是否存在。
我们可以使用ZSCORE命令,即获取指定一个元素对应的分数。获取元素的分数后,元素如果存在,返回的自然就是分数;元素不存在,返回的就是空。查排行榜使用ZRANGE。ZRANGE查询的是按范围查,它天然地会帮你做排序。假如说按时间戳插入,那么它会天然地按照时间戳从小到大排序。那么最早插入的就在最前,查前五名就是查分数从0到4的五个key。
点赞优化
然后改造原来的业务。首先是点赞业务,不再往set集合里存,而是往SortedSet里存。执行ZADD时需要指定三个参数:key,value,分数。分数可以用System.currentTimeMillis()来获取时间戳。
@Override
public Result likeBlog(Long id) {
......
// 判断当前用户是否已点赞
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if (score == null) {
......
// 保存用户至Redis的set集合中
if (isSuccess) {// 执行Redis命令:ZADD key userId SCORE
stringRedisTemplate.opsForZSet().add(key, userId.toString(),System.currentTimeMillis());
}
} else {
......
// 删除Redis的set集合中的用户
if (isSuccess) {// 执行Redis命令:SREM key userId
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}
return Result.ok();
}
然后是查询博客的isBlogLike()方法,使用ZSCORE替换掉原来的SISMEMBER,查完以后返回的分数不等于空,就是点赞了。
private void isBlogLike(Blog blog) {
......
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
blog.setIsLike(score!= null);
}
此时再去点赞就是存储到SortedSet中。
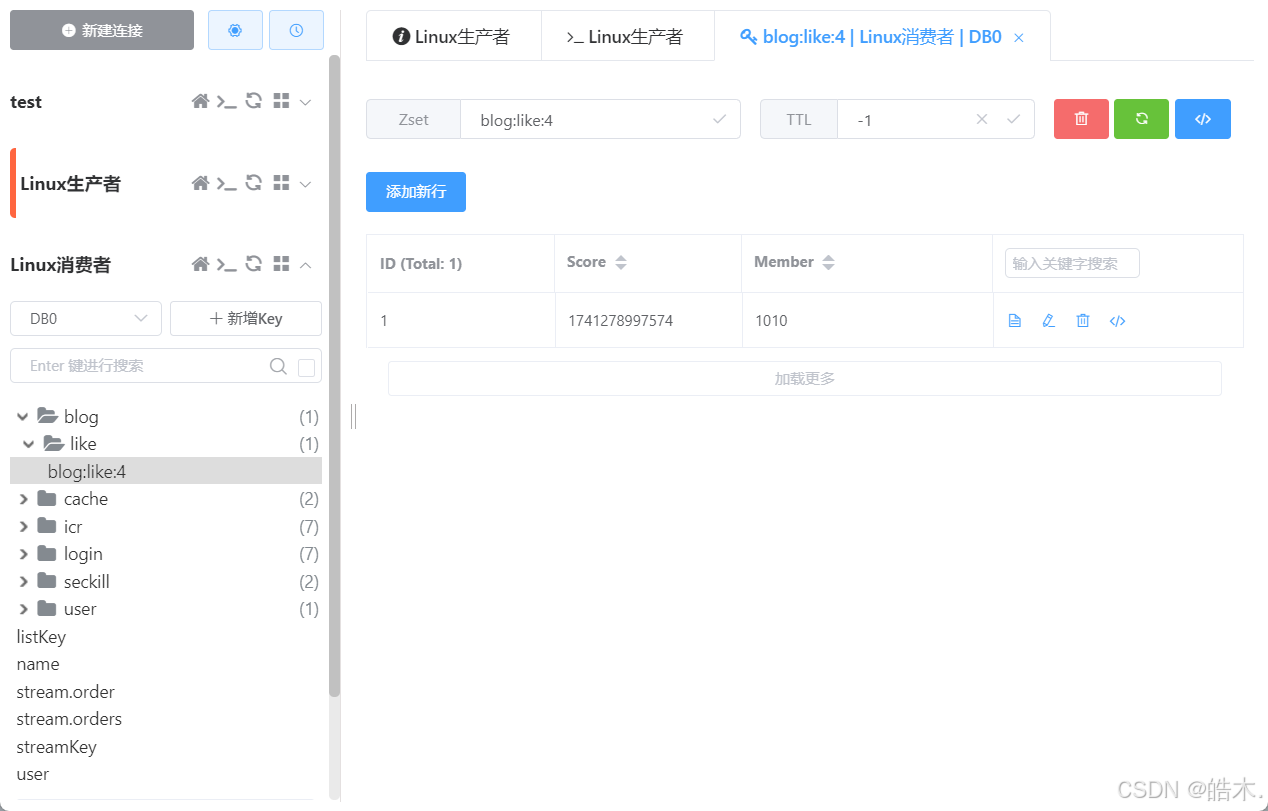
点赞列表
然后是点赞列表的查询。请求方法为get,请求路径为/likes/{id},id为blog的id。这个查询需要获取点赞的前五名用户。查询前五名用户用到的是范围查询(range)。我们指定一个key,然后指定范围,如0到4,就可以获取前五条记录。但需要注意的是,我们查询到的是sorted set中的用户ID和分数,而我们真正需要的是用户信息。因此,查询完成后,我们需要先解析出用户ID,然后根据用户ID去查询用户信息,并返回结果。
首先使用range方法进行查询,获取前五名用户的ID集合。然后将字符串类型的用户ID转换为long类型。接着通过userService.query()查询用户信息。在返回用户信息之前,我们需要将用户信息转换为DTO(数据传输对象),以确保返回的数据格式一致。如果查询结果为空,则返回一个空集合以避免空指针异常。
此时基础功能已实现,但存在顺序问题。这是因为数据库查询时使用IN子句进行查询时,数据库返回的结果并不会按照给定的ID顺序排列。可以使用了ORDER BY FIELD语句,手动指定查询结果的排序顺序解决此问题。
@Override
public Result queryBlogLikes(Long id) {
// 构建Redis中存储博客点赞信息的键,其中BLOG_LIKED_KEY是常量,表示点赞信息的前缀
String key = BLOG_LIKED_KEY + id;
// 使用Redis的ZSet数据结构查询点赞数排名前5的用户ID
// 对应的Redis命令为:ZRANGE key 0 4,表示获取键为key的ZSet中排名0到4的成员
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);
// 如果没有点赞用户,直接返回空列表
if (top5 == null || top5.isEmpty()) {
return Result.ok(Collections.emptyList());
}
// 将Set中的用户ID字符串转换为Long类型列表
List<Long> ids = top5.stream() // 将Set转换为Stream流
.map(Long::valueOf) // 将每个字符串ID转换为Long类型
.collect(Collectors.toList()); // 收集转换后的Long类型ID到列表中
// 将用户ID列表转换为以逗号分隔的字符串,用于SQL语句中的FIELD函数
String idStr = StrUtil.join(",", ids);
// 根据用户ID列表查询用户详细信息
// 使用MyBatis-Plus的查询构造器,in("id", ids)表示ID在列表ids中
// last("ORDER BY FIELD(id,"+idStr+")")用于指定排序,按照FIELD函数的返回值排序,保持与Redis中相同的顺序
List<UserDTO> userDTOS = userService.query()
.in("id", ids)
.last("ORDER BY FIELD(id," + idStr + ")") // 注意:这里可能存在SQL注入风险,应使用参数化查询
.list() // 执行查询并获取结果列表
.stream() // 将结果列表转换为Stream流
// 将User实体类转换为UserDTO数据传输对象
.map(user -> BeanUtil.copyProperties(user, UserDTO.class)) // 复制属性到UserDTO对象
.collect(Collectors.toList()); // 收集转换后的UserDTO对象到列表中
// 返回查询到的用户DTO列表
return Result.ok(userDTOS);
}
好友关注
接下来实现关注的相关功能。当你感觉某位博主的笔记还不错时,就可以关注一下。
好友关注共分为三部分。第一部分是关注和取关。关注是单向操作,不需要经过对方同意,你可以随意地关注或取关,因此实现起来非常简单。
第二部分是共同关注功能。在他人主页有共同关注按钮,点击即可查看当前用户与指定用户的共同关注。
第三部分是关注推送功能。当你关注了某位博主时,这些博主一更新,你就会收到推送。
关注/取关
首先来看关注和取关。在笔记的详情页面,作者的右侧会有一个“关注”按钮。当我们点击关注按钮时,就会发起一个请求去尝试关注用户。请求方法为put,请求路径为follow/{id}/{isFollow},{id}为要关注的用户的id,{isFollow}是布尔值,true表示关注,false表示取关。因此,这一个接口就同时实现关注和取关两个功能。
同时,为了确定在页面上显示“已关注”还是“未关注”,在页面加载时还会发一个请求去查询当前用户是否已关注过该播主。请求方法为get,请求路径为follow/or/not/{id},id为当前用户的id,它会返回一个布尔值,true表示已关注,false表示未关注。
用户关注就是用户与用户之间的关系。一个用户可以关注很多其他用户,他自己也可以被很多人关注。因此,用户之间关注的关系是一种多对多的关系,想在数据库里记录这种关系,需要有一张中间表。
有一张表名为tb_follow,因为只记录用户与用户的关系,所以它字段也非常简单,除了主键id和记录时间的create_time以外,就两个字段,一个是user_id,为当前用户的id,另一个是follow_user_id,为被关注的用户的id。这样两个关系就记录下来了。
要想实现关注,就是把用户id和被关注的用户id插入该表,两用户之间的关系就建立起来了。取关则是把这一条关系删除。
还有一种实现方案是不删除数据,而是加一个布尔值字段,用true和false来标记到底是关注还是取关。但当用户取关时,该数据还会留在表中,如果有大量的取关,就会有大量的无用数据。所以本项目仍采用删除的方案,关注就是新增,取关就删除。
判断有没有关注,则是根据用户id和followed_user_id来查,查到了则表示已关注,反之则未关注。表tb_follow对应的实体类为Follow类,字段与数据库中的tb_follow表完全一致。
先到FollowController中实现关注/取关接口。参数isFollow为true就是关注,false就是取关。这里调用了MyBatis Plus的remove()方法。如果不熟悉可以直接手写sql。remove()方法里面要传一个wrapper来指定类型为follow。后边传条件,分别eq判断两参数对应的数据是否存在于数据库中。
//FollowController______________________
@RestController
@RequestMapping("/follow")
public class FollowController {
@Autowired
private IFollowService followService;
//关注/取关
@PutMapping("/{id}/{isFollow}")
public Result follow(@PathVariable("id") Long followUsereId,@PathVariable("isFollow")Boolean isFollow){
return followService.follow(followUsereId,isFollow);
}
}
//IFollowService_______________________
public interface IFollowService extends IService<Follow> {
Result follow(Long followUsereId, Boolean isFollow);
}
//FollowServiceImpl______________________
@Service
public class FollowServiceImpl extends ServiceImpl<FollowMapper, Follow> implements IFollowService {
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 获取当前登录用户的ID
Long userId = UserHolder.getUser().getId();
// 根据isFollow的值判断是执行关注操作还是取关操作
if (isFollow) {
// 关注:创建并保存新的关注关系
Follow follow = new Follow()
.setUserId(userId)
.setFollowUserId(followUserId)
.setCreateTime(LocalDateTime.now());
save(follow);
} else {
// 取关:删除已存在的关注关系
// 构建查询条件,匹配关注者ID和被关注者ID
remove(new QueryWrapper<Follow>()
.eq("user_id", userId) // 关注者ID等于当前登录用户ID
.eq("follow_user_id", followUserId)); // 被关注者ID等于参数中的followUserId
}
// 操作完成,返回成功结果
return Result.ok();
}
}
然后来实现查询是否关注指定id的用户。请求路径是“followOrNot/{id}。
//FollowController______________________
//是否关注该id的用户?
@GetMapping("or/not/{id}")
public Result isFollow(@PathVariable("id") Long followUsereId){
return followService.isfollow(followUsereId);
}
//IFollowService_______________________
Result isfollow(Long followUsereId);
//FollowServiceImpl______________________
@Override
public Result isfollow(Long followUserId) {
// 获取当前登录用户的ID
Long userId = UserHolder.getUser().getId();
// 检查当前用户是否关注了指定的用户
// SQL语句:select count(*) from tb_follow where user_id = ? and follow_user_id = ?
Long count = query()
.eq("user_id", userId) // 添加查询条件:当前用户的ID
.eq("follow_user_id", followUserId) // 添加查询条件:要检查的关注用户ID
.count(); // count返回查询到的数据个数,one则返回具体数据
// 如果count大于0,表示用户已经关注了指定用户,返回true;否则返回false
return Result.ok(count > 0);
}
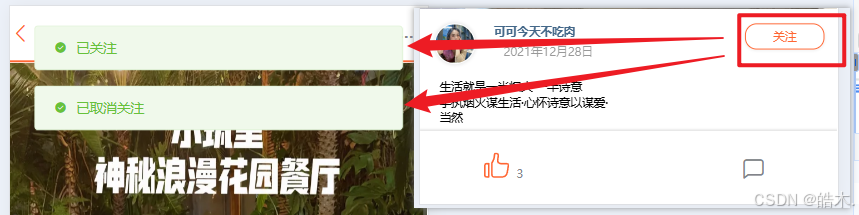
然后测试,到笔记详情页点击两次对应按钮,观察系统是否正确执行。
共同关注
然后来实现“共同关注”的功能。即查看用户和对方关注中有是否存在相同的人,想要查看共同关注,到对方的主页点击对应按钮即可查看,所以我们需先完成查看个人主页功能。
个人主页
在当前项目中,点击他人头像即可进入到目标用户的主页,主页包括用户的头像、用户的名称等个人信息,下方还会展示用户的笔记。
所以说查看个人主页需要发出两个请求:一个为查询指定用户信息,请求路径为user/{id},id为指定用户id。另一个为分页查询指定用户的所有的笔记,请求路径为blog/of/user?id={id}¤t=1,id为指定用户id,current为页数。所以说,我们需要去实现一下这两个功能,才能够进入到他的个人主页。
这两个功能主要是对数据库的增删改查,其实都是查询。所以直接复制即可。
// UserController__________________________________
// 根据id查询用户信息
@GetMapping("/{id}")
public Result queryUserById(@PathVariable("id") Long userId){
// 查询详情
User user = userService.getById(userId);
if (user == null) {
return Result.ok();
}
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 返回
return Result.ok(userDTO);
}
// BlogController——————————————————————————————————
// 分页查询该id用户的笔记
@GetMapping("/of/user")
public Result queryBlogByUserId(
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam("id") Long id) {
// 根据用户查询
Page<Blog> page = blogService.query()
.eq("user_id", id).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
return Result.ok(records);
}
然后测试,点击个人头像即可打开个人主页,各数据正常展示。但点击共同关注会报错。
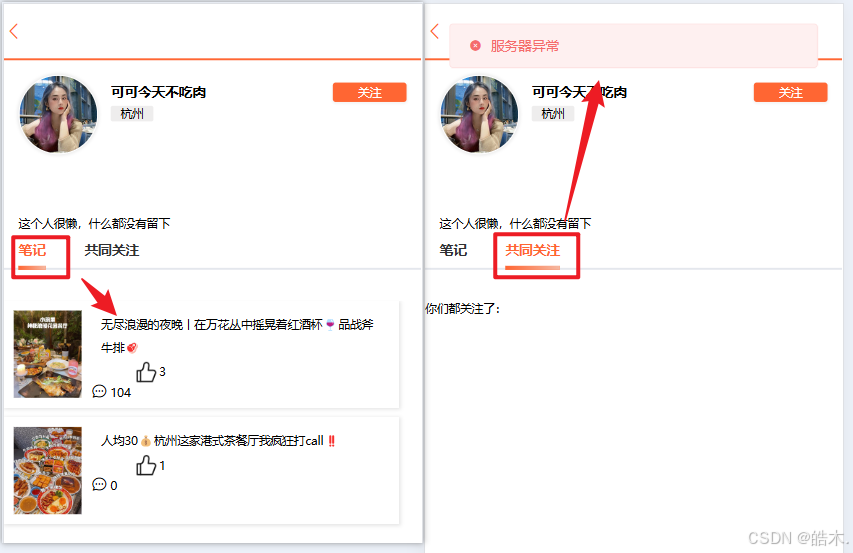
查看共同关注的请求方法为get,请求路径为/follow/common/{id},id就是指定用户的id。查看共同关注就是查看当前登录用户与指定用户,两者之间关注列表的一个交集。Redis里的set结构就能实现交集功能。
改造关注
SINTER key1 [key2 ...]:返回给定集合的交集。
> SADD key1 value1 value2
2
// 使用SADD命令向集合key1中添加了两个成员value1和value2。
// 命令返回2,表示成功添加了2个成员。
> SADD key2 value1 value2
2
// 使用SADD命令向集合key2中同样添加了两个成员value1和value2。
// 命令返回2,表示成功添加了2个成员。
> SINTER key1 key2
value1
value2
// 使用SINTER命令计算集合key1和key2的交集。
// 由于key1和key2中都有value1和value2,所以交集结果包含这两个成员。
// 结果按顺序返回了交集的成员value1和value2。
想要借助Redis实现共同关注,首先要把所有用户的关注列表保存到Redis的set集合中,这样直接求两个set集合的交集,即可得出共同关注列表。
所以说要想实现该功能,还需先改造之前的关注接口。每次发起关注请求时,都需将其存储到Redis的set集合里,方便后续查看共同关注。放到Redis中的key为当前用户id,值为关注的所有的用户的id。
操作数据库后,我们需要根据结果判断是否成功,成功后执行对Redis的set集合的增/删操作。
//FollowServiceImpl__________________________________________
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 构建key
String key ="follows:" + userId;
// 根据isFollow的值判断是执行关注操作还是取关操作
if (isFollow) {
// 关注:创建并保存新的关注关系
boolean isSuccess = save(follow);
if (isSuccess) {
// 将关注用户id存入Redis
stringRedisTemplate.opsForSet().add(key,followUserId.toString());
}
} else {
// 取关:删除已存在的关注关系
boolean isSuccess = remove......
// 移除Redis集合中的用户id
if (isSuccess) {
// 删除Redis中对应的数据
stringRedisTemplate.opsForSet().remove(key,followUserId.toString());
}
}
// 操作完成,返回成功结果
return Result.ok();
}
此时再测试,Redis和MySQL中就会存入对应的数据。
共同关注
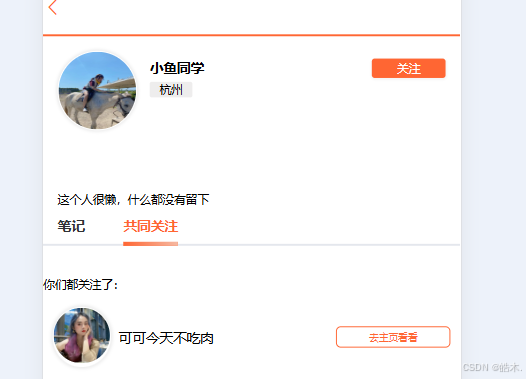
接下来实现共同关注的接口。该接口请求方式是GET,路径是follow/comments/{id},id为目标用户ID。返回值是List类型的UserDTO,表示你们两个人共同关注的所有用户。
为了规范的取交集,我们需要准备两个key,分别使用当前用户id和目标用户id拼接"follows:"而成。然后调用stringRedisTemplate.opsForSet().intersect(key, userKey)来求交集,内部传参为两个拼接而成的key。查完以后有可能为空,即两者没有交集。所以如果交集为空,就直接给一个空集合Collections.emptyList(),不为空则继续执行。
得到交集为两个用户共同关注的所有用户的ID,需要把它转换成UserDTO类型。可以通过Stream流、map映射,调用longValue,最后collect(Collectors.toList()收集,将ID集合从set变为list。
接着注入UserService,调用其listByIds()方法去查询用户。因为顺序不重要,所以我们不用像以前那样那么复杂,直接查询即可。查询到用户集合后,我们要把它转换成DTO类型。可以用一个stream流做处理,然后选择映射,映射的时候是利用BeanUtil.copyProperties(user, UserDTO.class)把User转换成UserDTO,将得到的集合返回即可。
//FollowController______________________
// 查看当前用户与该id用户的共同关注
@GetMapping("/common/{id}")
public Result followCommons(@PathVariable("id") Long id) {
return followService.followCommons(id);
}
//IFollowService_______________________
Result followCommons(Long id);
//FollowServiceImpl______________________
@Override
public Result followCommons(Long id) {
// 获取当前登录用户的ID
Long userId = UserHolder.getUser().getId();
// 构建当前用户关注的用户集合的Redis键
String userKey = "follows:" + userId;
// 构建目标用户关注的用户集合的Redis键
String key = "follows:" + id;
// 使用Redis的交集操作,获取当前用户和目标用户的共同关注用户集合
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, userKey);
// 如果共同关注的用户集合为空,返回空列表
if (intersect == null || intersect.isEmpty()) {
return Result.ok(Collections.emptyList());
}
// 将共同关注的用户ID从字符串转换为Long类型
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
// 根据共同关注的用户ID列表查询用户信息
List<UserDTO> userDTOS = userService.listByIds(ids)
.stream()
// 将用户信息复制到UserDTO对象中
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
// 返回共同关注的用户信息列表
return Result.ok(userDTOS);
}
重新部署并测试,页面正常展示:
关注推送
关注用户之后,如果该用户再发笔记,号主就能及时收到通知。这个功能就叫做“关注推送”,又叫做“feed流”,feed直译过来就是“投喂”,feed流就是可以无限下拉刷新来获取新的信息。这种模式就像在给用户投喂食物一样,因此叫做feed流。
这种获取信息的模式与传统模式区别较大。传统模式下,用户需要自行检索信息,通过搜索引擎、百度贴吧等去寻找各种各样的内容,然后寻找自己想要的内容。feed流则相反,其不需要用户去检索内容,而是由应用程序自动根据用户行为去匹配更适合用户的内容,直接推到给用户。这样用户就减少了自己查找、思考和分析的过程,可以大大节省时间。
feed流的实现有常见的两种常见模式:
- Timeline: 不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 优点: 信息全面,不会有缺失。并且实现也相对简单
- 缺点: 信息噪音较多,用户不一定感兴趣,内容获取效率低
- 智能排序: 利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息
- 优点: 投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点: 如果算法不精准,可能起到反作用
本项目的业务是在个人主页有一个"关注"的选项卡,里面会展示出关注的用户发布的探店笔记。所以应使用timeline模式,不做过滤,只按时间排序即可。
Timeline的三种方案
timeline模式的实现方案又有三种:
- 拉模式:每个博主都有一个“发件箱”,用于存储自己发布的所有内容。当用户需要查看关注的人的动态时,系统会从关注博主的发件箱中拉取内容并放到用户的收件箱中,然后按时间顺序排序并展示。因为每篇笔记发出时只有一份,只有在用户读取时才会获取副本,因此也叫做读扩散
- 优点:节省存储空间,新发出的消息只在发件箱中保存了一份,占内存较小。
- 缺点:延迟较高,用户每次查看都需重新拉取和排序,当关注人数较多时,操作耗时较长。
- 推模式:每个用户都有一个“收件箱”,用于接收关注对象发布的内容。当某个用户发布新内容时,系统会将该内容推送到其所有粉丝的收件箱中。用户查看动态时,直接从自己的收件箱中读取已排序的内容。同理,也叫做写扩散。
- 优点:延迟低,内容已经预先推送到收件箱,用户查看时无需再次拉取和排序。
- 缺点:存储压力大,对于粉丝数量众多的用户(如大V),每次发布内容都会导致大量数据写入,增加系统存储负担。
- 推拉结合:也叫读写混合模式,结合推和拉模式的优点,根据用户活跃度和粉丝数量灵活选择推送方式。
- 对于普通用户或粉丝数量较少的用户,采用推模式,将内容直接推送到粉丝的收件箱中。
- 对于大V的活跃粉丝采用推模式,保障粉丝收件箱会实时接收大V的最新内容。不活跃粉则采用拉模式,将内容存储在大V的发件箱中,不活跃粉丝查看时再按需拉取。
| 拉模式 | 推模式 | 推拉结合 | |
|---|---|---|---|
| 写比例 | 低 | 高 | 中 |
| 读比例 | 高 | 低 | 中 |
| 用户读取延迟 | 高 | 低 | 低 |
| 实现难度 | 复杂 | 简单 | 很复杂 |
| 使用场景 | 很少使用 | 用户量少、没有大V | 过千万的用户量,有大V |
只要粉丝数在千万级别以下,都适用于推模式。在当前项目中,因为用户不多且没有大V,所以使用推模式是最合适的。
修改项目为推模式
需要满足:
- 修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
- 收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
- 查询收件箱数据时,可以实现分页查询
之前我们实现的新增探店笔记的业务,是直接写到数据库中。但现在还需推送到收件箱,所以需要对该业务进行修改。当然这并不意味着抛弃保存数据库的逻辑,因为数据库相对来讲更加持久和安全。因为数据库中存储了笔记的完整内容,所以在推送到粉丝收件箱时,可以只推笔记id,用户再根据ID到数据库中查询详细信息,这样可以进一步节省内存空间。
为了提升性能,收件箱选择使用Redis实现。且还要按照时间戳排序。在Redis的数据结构中,能排序的有两个:list、sortedSet。这两个都可以满足排序需求,因为list类似链表,可以按照插入顺序排序;sorted set按照score值(如果存在是时间戳)同样可以排序。
两者都能实现的情况下,我们再来看需求三:在查询收件箱数据时,要求分页查询。分页往往要指定起始的索引,也就是page和size,方便系统计算出该页需要展示哪些数据。Redis里的list是一个链表,底层有索引,所以可以按索引查询实现分页。sortedSet没有索引,但它按照score排列,排名从零开始,跟索引类似,也能实现分页。
虽然两者都能满足排序和分页,但仍存在一定的差异。在feed流的场景中,数据是会不断变化的,因为不断有人在发新的消息并进入队列,排名和索引就会不断变化。因为传统分页模式是按索引,但数据变化会导致索引变化,查询就会出现重复读取或混乱的情况。所以这时候传统的分页模式就不适用了。
因此只能采用滚动分页模式。滚动分页就是记录每一次查询的最后一条,下一次从该位置开始查。因为我们这里的顺序是有序的,所以完全可以按照顺序,每次记住最后一条,下一次从它往后查。因为按照倒序从大到小排列,所以第一次查询时可以把起始的ID指定成无穷大(或者时间戳指定成无穷大),然后查五条,然后依次向下查询。
list显然不支持滚动查询,因为list里查询数据只能按照索引查询,首尾查询更不行。所以list不支持滚动分页。而sortedSet会按照score值排序形成排名,如果将score值设为时间戳,并按照从大到小的顺序排列,查询时按照score值范围进行查询,每次查询时都将最小的时间戳记录下来,下次查询时再从该时间戳往下查找,这样就实现了滚动分页,数据也就不会重复。
因此我们选择使用sortedSet。当数据会有变化的情况下,尽量不要使用list这种队列去做分页,而是使用sortedSet。
接下来去修改代码。原来的逻辑是在controller里进行的,现在因为逻辑变复杂,所以放到放到Impl里执行:在保存探店笔记成功以后,需将该笔记(博客的ID)发送给粉丝。需先查询笔记作者的所有粉丝,即从tb_follow表中查询follow_user_id等于作者ID的所有id集合。操作tb_follow表需要注入IFollowService。
拿到粉丝后,就开始用for循环依次推送到每个粉丝的收件箱,类型为sortedset,key是粉丝的ID加上前缀,value就是推送的笔记ID,score是时间戳。
@Override
public Result saveBlog(Blog blog) {
......
// 保存探店博文到数据库
boolean isSuccess = save(blog);
// 检查博文是否保存成功
if (!isSuccess) {
// 如果保存失败,返回失败结果
return Result.fail("新增笔记失败!");
}
// 查询当前笔记作者的所有粉丝
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 遍历所有粉丝
for (Follow follow : follows) {
// 获取每个粉丝的用户ID
Long userId = follow.getUserId();
// 构造用于存储推送博文的Redis键
String key = FEED_KEY + userId;
// 将博文ID和当前时间戳添加到对应粉丝的Feed流中
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 博文保存成功,返回包含博文ID的成功结果
return Result.ok(blog.getId());
}
滚动分页查询介绍
当我们点击“关注”选项卡时,这个功能还不能实现,因为相关的请求接口还没有做。但在实现该接口之前,我们会先回顾一下sortedset(有序集合)的一些相关命令。因为我们将要实现的是滚动分页,滚动分页实现起来相对复杂,命令也比较繁琐。
提前准备一个sortedset集合,里面有六个元素,它们对应的分数分别是1到6,名称也恰好是1到6,这样方便我们观察规律。这里的分数可以当成是时间戳,时间戳越大的数据就越新,排名也就越靠前。然后进行分页查询,比如每页查三条,那么查第一页的时候就是查6、5、4,第二页是3、2、1,这是我们期望的目标。
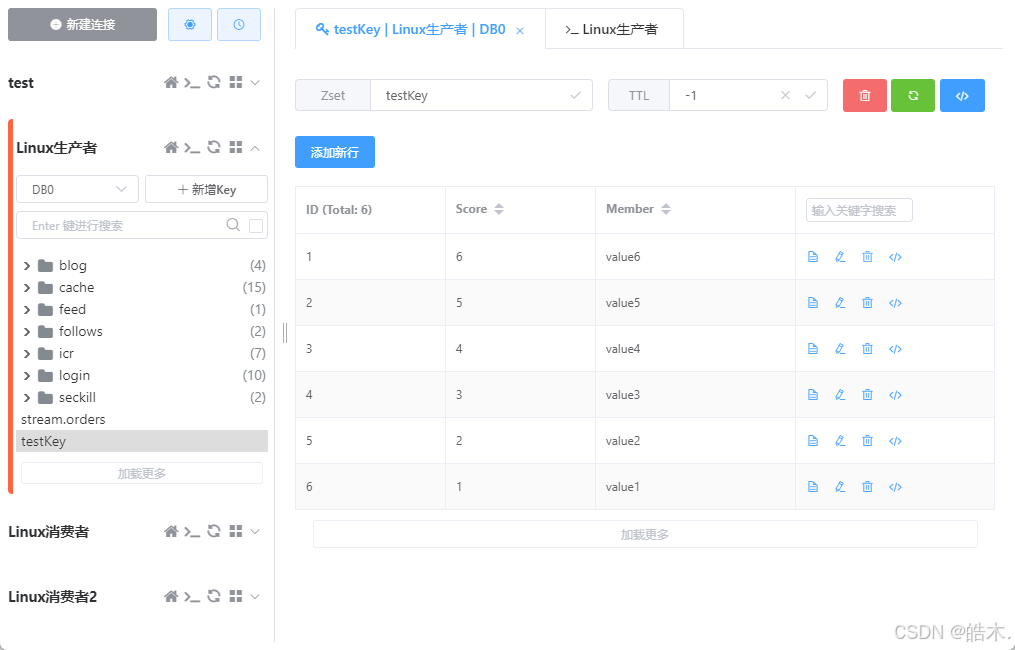
sortedset中按排名查询的命令为ZRANGE。ZRANGE命令要指定key,然后指定min和max,即排名的最小值和最大值。该命令默认按照升序排序,而我们的项目中时间戳越大排名越靠前,所以应该按降序查询,需要在RANGE命令前加上reverse(反转),于是命令就变成了ZREVRANGE。此时如果查询角标从0到2的数据,自然能查出时间戳最大的三条数据,可以带上WITHSCORES使返回结果包含分数:
192.168.88.111:6379> ZREVRANGE testKey 0 2 WITHSCORES
1) "value6"
2) "6"
3) "value5"
4) "5"
5) "value4"
6) "4"
此时插入一条新的数据,来模拟新增笔记导致数据混乱的情况。此时如果仍按照上述思路查询,就会导致查出重复的值:
192.168.88.111:6379> zadd testKey 7 value7
(integer) 1
192.168.88.111:6379> ZREVRANGE testKey 3 5 WITHSCORES
1) "value4"
2) "4"
3) "value3"
4) "3"
5) "value2"
6) "2"
这就是按角标查询存在的问题。为解决此问题,需要按分数查询代替按角标查询。即第一次查询从最大的分数开始查三条,并记录查询到哪了,下次查询只需从该分数往下查询即可。这样就能避免因为角标变化导致的混乱。
按分数查询的命令是ZREVRANGEBYSCORE,指定key后需要指定的是分数的最大值和最小值。然后还要指定偏移量(offset)和总共要查几条(count)。
首先需要确定最大值。如果是第一次查询,此时没有上一次查询的结果,所以最大值可以设为当前时间戳(当前时间戳就是最大的时间戳)。案例中使用的是456这样的数字来模拟时间戳,那就给一个足够大的值,比如1000来表示最大的时间戳即可。最小值则并不重要,直接给0即可(因为时间没有负数)。滚动查询的思路是记住上一次查到哪了,然后从该处开始向下查询指定条数即可。所以我们只关心两件事:从哪儿开始,以及总共查几条。
指定要查几条取决于 limit 参数里的 offset 和 count。offset 代表从最大值开始的第几个元素查询,这里的最大值和最小值都是包含关系。如果是第一次来,offset 给0,就是从小于等于最大值的第一个元素开始查。count 就是总共查几条,比如查三条就给3。
192.168.88.111:6379> ZREVRANGEBYSCORE testKey 1000 0 WITHSCORES LIMIT 0 3
1) "value7"
2) "7"
3) "value6"
4) "6"
5) "value5"
6) "5"
此时模拟第一次查询,查到了765,再查下一页时期望查到432。但此时插入一条新的数据8,它变成了最大的。如果按照角标查,可能会混杂,但按照分数查就不会。执行ZREVRANGEBYSCORE并指定最大值和最小值,最大值是上一次查询的最小值(因为是按分数倒序,我只要找比它小的即可),最小值仍保持0。LIMIT之后也不再是0,因此0表示包含当前的最大值,但该最大值已经在上次查询时查出,此时应该查下一个,所以偏移量应改为1,count不变仍为3,表示查三条数据。
192.168.88.111:6379> ZADD testKey 8 value8
(integer) 1
192.168.88.111:6379> ZREVRANGEBYSCORE testKey 5 0 WITHSCORES LIMIT 1 3
1) "value4"
2) "4"
3) "value3"
4) "3"
5) "value2"
6) "2"
这样,每一次查询都记住上一次查询的最小值,就能避免重复查询,不用关心前边的排名有没有变化。因此得出实现滚动查询,需要传入四个参数:分数的最大值、分数的最小值、偏移量 offset 以及查的数量 count。
其中,最小值和查询数量是固定不变的,可以写死。变化的是最大值 max,它是每一次查询时要找上一次查询的那个最小的分数。第一次除外,第一次给时间戳的最大值(当前时间)。
limit 的 offset 第一次给0,因为第一次来肯定是从第一条开始。但之后的查询因为要从上一次查询的最小值的下一个开始,所以 offset 给1。
然而,还有一种特殊情况。如果列表中有两个元素的分数是一样的,就会出现问题。比如,如果我们把7号元素的值改成6,那么列表中就有两个6了。当我们再次做滚动查询时,可能会再次查到上一次已经查过的元素。因此从第二次查询开始,offset 是几个取决于上一次查询的最小值有几个跟它的值一样的元素。比如,如果上一次查询的最小值是6,且有两个6,那么 offset 就是2。
滚动分页查询实现
来看前端发起的请求,请求方式是GET,路径是/block/of/follow。因为每次查询的时候都要带上上一次查询的时间戳,所以请求参数里会有一个叫做lastId的参数用于记录,第一次查询时由前端直接计算出当前时间的时间戳。另一个参数为offset(第一次查询时不需要传)。
因此每次查询的返回值里包含三个部分:
- 笔记数据List<Blog>,小于指定时间戳的笔记集合。
- minTime,是本次查询的结果中的最小时间戳,该值会作为下次查询的最大值。
- offset,偏移量,也就是和最小时间戳相同的值的数量。
接下来实现这个接口。dto中的ScrollResult类包含data、meanTime(或叫lastId)、offset,可以当作滚动分页的结果。
在BlogController中处理该请求。方法名queryBlogOfFollow(),参数有两个:一个是lastId,上一次查询的最小时间,也是本次查询的最大时间,所以起名为max;第二个是offset,就是要跳过的元素的个数。注意两参数不是基于@PathVariable,在前端发起的请求中,两参数是通过问号拼接的,所以像这样的参数我们需要用@RequestParam注解来传递。第一次查询时offset为空的,所以还需为其指定默认值为0,避免出现控制异常等情况。
然后创建并调用BlogService.queryBlogsOfFollow,传入max和offset。整个查询的逻辑稍微有点复杂,首先查询的是收件箱里边所有的笔记,然后做一个滚动分页。为找到对应的收件箱,我们需先获取用户id并构建用于查询的Redis键。
然后是解析数据,从Redis中查询到的数据包含该博客的id,和对应的时间戳,即对应的分数score。除了这两个参数以外,还需要找出最小时间戳的,也就是minTime(或lastId)。还有offset,即上次查询的最小时间戳一样的元素的个数。
最后再根据id查询博客,将查询到的博客封装并返回即可。
分析完思路后来实现上述逻辑。
首先获取当前用户,调用Holder.getUser().getId()即可,构建用于查询的Redis键和当时保存到收件箱的键格式保持一致即可。
然后是滚动分页查询。调用StringRedisTemplate.opsForZSet().rangeByScoreWithScores()。因为是按照score查,所以ByScore。另外还需带上分数,这样才能找到本次查询的分数的最小值。key直接传入根据id构建的key;最小值不重要,指定0即可;最大值为前端传入的最大值;offset也是前端传入的值;count相查几页写几即可,本文查3篇。
查完后得到的Set中的数据较复杂,其名为TypedTuple(元组),内部包含一个value、一个score。对应的值为博客id,和时间戳分数。每条数据就是一个元组,多个元组组成集合。但集合中是否有值并不能确定,可能有多个,也可能为空。所以需多做个非空判断,为空则直接return。
接下来从数据中提取所需信息。可以通过for循环遍历这些数据,首先从TypedTuple的value中获取id字符串。然后从TypedTuple的Score中获取分数(时间戳),其会以double类型返回,但我们需要的是long类型,可以通过longValue()方法转换,得到我们的时间戳time。同时需要在for循环中将结果保留下来。我们需要保留的是id、minTime和offset这三个信息。
由于id不止一个,我们可以使用ArrayList来存储,每提取出一个id,就将其添加到该列表中。接下来处理TypedTuple的Score,需要从一系列结果中找到最小的时间戳。可以初始化一个minTime,然后每次遍历集合时,都用当前元素的时间来更新这个变量。确保循环结束时,这个变量中存储的一定是集合中最后一个元素的时间,即最小时间。
offset为集合中分数值等于最小时间的所有元素的个数。由于不确定具体有几个,所以需要计数。初始化offset为1(因为至少有一个元素的时间是最小的),然后每找到一个时间等于最小时间的元素,offset就加1。在判断过程中,如果当前时间等于最小时间,则offset加1;如果不等,就用新的time替换minTime,并重置offset为1。
最后根据id列表查询,得到blog列表,MyBatis Plus提供的listByIds方法批量查询无法根据id顺序返回对应顺序的数据,因此需要使用基于MySQL的IN语句,并加上ORDER BY来保持顺序。此时就查到了Blog的基础信息,但有关笔记相关用户信息,当前用户是否点赞都不清楚。所以还需对每个Blog做两件事:一、查询博客相关用户信息,二、查询当前用户是否点赞该博客。这样blog数据才完整。
查询成功后,将blog集合、offset、minTime,封装到ScrollResult对象中并返回即可。
//BlogController——————————————————
@GetMapping("/of/follow")
public Result queryBlogOfFollow(
@RequestParam("lastId")Long max,
@RequestParam(value = "offset",defaultValue = "0")Integer offset) {
return blogService.queryBlogOfFollow(max,offset);
}
//IBlogService————————————————————
Result queryBlogOfFollow(Long max, Integer offset);
//BlogServiceImpl—————————————————
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 获取当前用户的ID
Long userId = UserHolder.getUser().getId();
// 构造用于查询的Redis键
String key = FEED_KEY + userId;
// 从Redis中查询当前用户收件箱的数据,使用ZREVRANGEBYSCORE命令逆序获取分数在0到max之间的元素,限制返回的数量为3,并跳过offset个元素
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 3);
// 检查查询结果是否为空
if (typedTuples == null || typedTuples.isEmpty()) {
// 如果为空,直接返回
return Result.ok();
}
// 初始化用于存储博客ID的列表,以及用于记录最小时间戳和相同时间戳数量的变量
List<Object> ids = new ArrayList<>(typedTuples.size());
long minTime = max; // 初始最小时间戳设为最大时间戳
int sameNum = 1; // 初始相同时间戳数量为1
// 遍历查询结果,解析数据
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
// 将博客ID添加到列表中
ids.add(Long.valueOf(typedTuple.getValue()));
// 获取当前元素的时间戳(分数)
long time = typedTuple.getScore().longValue();
// 如果当前时间戳与最小时间戳相同,增加相同时间戳数量
if (time == minTime) {
sameNum++;
} else {
// 否则,更新最小时间戳并重置相同时间戳数量
minTime = time;
sameNum = 1;
}
}
// 根据解析出的博客ID查询博客详情,并按照ID的顺序排序
String idStr = StrUtil.join(",", ids); // 将ID列表转换为逗号分隔的字符串
List<Blog> blogs = query()
.in("id", ids).last("ORDER BY FIELD(id," + idStr + ")") // 使用FIELD函数按照指定顺序排序
.list(); // 执行查询并获取结果列表
// 遍历博客列表,填充每篇博客的详细信息
for (Blog blog : blogs) {
// 查询并设置与博客相关的用户信息
queryBlogUser(blog);
// 查询并设置博客是否被当前用户点赞
isBlogLike(blog);
}
// 创建滚动结果对象,设置博客列表、偏移量和最小时间戳
ScrollResult scrollResult = new ScrollResult();
scrollResult.setList(blogs);
scrollResult.setOffset(sameNum); // 更新偏移量
scrollResult.setMinTime(minTime); // 设置最小时间戳
// 封装滚动结果并返回成功的结果
return Result.ok(scrollResult);
}
测试,程序正常运行,如有多篇笔记,滚动时前端还会再次发起请求:

















 1962
1962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









