



安装装环境的小插曲:安装了135版本的谷歌浏览器和对应135版本的驱动,运行demo程序时报错(打开谷歌,在百度网站进行搜索),原因就是selenium不使用我下载的135版本的谷歌浏览器,而是在C:\Users\wenyong\.cache\selenium\chrome\win64\140.0.7339.80下载一个140版本的谷歌浏览器,然后造成浏览器和驱动版本不一致!难怪第一次运行半天没动静,下东西去了。
关键是我代码里指定用我自己下载的浏览器它也还是报错(浏览器和驱动不兼容),禁用Selenium的自动管理貌似也没起到作用。包括降低selenuim版本。后来我卸载了自己下载的浏览器,就用它下载的吧,然后换了个和他匹配的驱动,成功运行了。(但是今天学习完毕后回过头反思,兼容性测试就是要测高版本和低版本的兼容性问题,你怎么办?考虑过没有?)
1.完整的多版本浏览器测试解决方案
1.使用配置文件管理不同浏览器版本
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.firefox.options import Options as FirefoxOptions
from selenium.webdriver.edge.options import Options as EdgeOptions
import pytest
import os
# 浏览器配置字典 - 可以轻松切换不同版本
BROWSER_CONFIGS = {
"chrome_140": {
"browser_type": "chrome",
"browser_path": r"C:\Program Files\Google\Chrome\Application\chrome.exe",
"driver_path": r"C:\WebDriver\chrome_140\chromedriver.exe"
},
"chrome_120": {
"browser_type": "chrome",
"browser_path": r"D:\Browsers\Chrome_120\chrome.exe",
"driver_path": r"C:\WebDriver\chrome_120\chromedriver.exe"
},
"chrome_100": {
"browser_type": "chrome",
"browser_path": r"D:\Browsers\Chrome_100\chrome.exe",
"driver_path": r"C:\WebDriver\chrome_100\chromedriver.exe"
},
"firefox_115": {
"browser_type": "firefox",
"browser_path": r"D:\Browsers\Firefox_115\firefox.exe",
"driver_path": r"C:\WebDriver\geckodriver.exe"
},
"edge_110": {
"browser_type": "edge",
"browser_path": r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe",
"driver_path": r"C:\WebDriver\msedgedriver.exe"
}
}
@pytest.fixture(scope="function", params=["chrome_140", "chrome_120", "chrome_100"])
def browser(request):
"""多版本Chrome浏览器测试"""
config_name = request.param
config = BROWSER_CONFIGS[config_name]
print(f"使用浏览器版本: {config_name}")
if config["browser_type"] == "chrome":
chrome_options = Options()
chrome_options.binary_location = config["browser_path"]
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
service = Service(executable_path=config["driver_path"])
driver = webdriver.Chrome(service=service, options=chrome_options)
elif config["browser_type"] == "firefox":
firefox_options = FirefoxOptions()
firefox_options.binary_location = config["browser_path"]
driver = webdriver.Firefox(executable_path=config["driver_path"], options=firefox_options)
elif config["browser_type"] == "edge":
edge_options = EdgeOptions()
edge_options.binary_location = config["browser_path"]
edge_options.use_chromium = True
driver = webdriver.Edge(executable_path=config["driver_path"], options=edge_options)
driver.implicitly_wait(10)
yield driver, config_name # 返回驱动和配置名称
driver.quit()
def test_compatibility(browser):
"""兼容性测试"""
driver, browser_version = browser
driver.get("https://hmshop-test.itheima.net/Home/user/login.html")
# 记录测试的浏览器版本
print(f"在 {browser_version} 上进行测试")
# 执行测试逻辑
# ...
assert "登录" in driver.title
print(f"{browser_version} 测试通过")
2.通过命令行参数选择浏览器版本
import pytest
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
def pytest_addoption(parser):
"""添加命令行选项"""
parser.addoption("--browser-version", action="store", default="chrome_140",
help="选择浏览器版本: chrome_140, chrome_120, chrome_100, firefox_115, edge_110")
@pytest.fixture(scope="function")
def browser(request):
"""根据命令行参数选择浏览器版本"""
browser_version = request.config.getoption("--browser-version")
# 浏览器配置
configs = {
"chrome_140": {
"path": r"C:\Program Files\Google\Chrome\Application\chrome.exe",
"driver": r"C:\WebDriver\chrome_140\chromedriver.exe"
},
"chrome_120": {
"path": r"D:\Browsers\Chrome_120\chrome.exe",
"driver": r"C:\WebDriver\chrome_120\chromedriver.exe"
},
# 添加更多版本...
}
config = configs.get(browser_version, configs["chrome_140"])
chrome_options = Options()
chrome_options.binary_location = config["path"]
# 完全禁用Selenium的自动管理
service = Service(
executable_path=config["driver"],
service_args=['--disable-build-check']
)
driver = webdriver.Chrome(service=service, options=chrome_options)
yield driver
driver.quit()
# 运行方式: pytest --browser-version=chrome_120
3.使用环境变量控制
import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
# 设置环境变量彻底禁用自动下载
os.environ['SE_DISABLE_AUTO_DOWNLOAD'] = 'true'
os.environ['SE_DONT_DOWNLOAD_CHROMEDRIVER'] = 'true'
os.environ['WD_BROWSER_PATH'] = '' # 清空自动检测
def get_browser(version="140"):
"""手动创建指定版本的浏览器实例"""
version_configs = {
"140": {
"browser": r"C:\Program Files\Google\Chrome\Application\chrome.exe",
"driver": r"C:\WebDriver\chrome_140\chromedriver.exe"
},
"120": {
"browser": r"D:\Browsers\Chrome_120\chrome.exe",
"driver": r"C:\WebDriver\chrome_120\chromedriver.exe"
},
"100": {
"browser": r"D:\Browsers\Chrome_100\chrome.exe",
"driver": r"C:\WebDriver\chrome_100\chromedriver.exe"
}
}
config = version_configs[version]
chrome_options = Options()
chrome_options.binary_location = config["browser"]
service = Service(executable_path=config["driver"])
return webdriver.Chrome(service=service, options=chrome_options)
@pytest.fixture(scope="function", params=["140", "120", "100"])
def multi_version_browser(request):
"""多版本浏览器测试"""
driver = get_browser(request.param)
yield driver
driver.quit()
2.元素定位的作用
版本问题不报错了,但是还是没有成功的让Python控制浏览器完成搜索任务(打开谷歌,在百度网站进行搜索)!这个代码网上有现成的代码,我把这个代码以及运行报错都发给了deepseek,当然很可能是我把有问题的源码(百度网页元素更改导致之前的代码不能用了)给到大模型,由于聊天记忆的原因,一直没有给我纠正这个错误!通过元素定位,发现原来的代码 "kw"、“su”不能进行元素定位了!其实大模型分析的时候就给说了有可能是网站跟新导致元素定位不准,我看这代码是前几个月的不可能网站就做了跟新,也没必要做这个跟新,就一直没有去元素定位往这方面想!在他给我的另外的几个可能的情况里扰!
"""
import webbrowser
search_query = "北京烤鸭"
baidu_url = f"https://www.baidu.com/s?wd={search_query}"
webbrowser.open(baidu_url)
"""
# 导包 webdriver
from selenium import webdriver
import time
# 实例化浏览器对象 谷歌 tab键
driver = webdriver.Chrome()
# 打开百度
driver.get("https://www.baidu.com")
from selenium.webdriver.common.by import By
# 输入北京烤鸭
driver.find_element(By.ID, "kw").send_keys("北京烤鸭")
# 点击搜索按钮
driver.find_element(By.ID, "su").click()
time.sleep(3)
# 关闭浏览器
driver.quit()
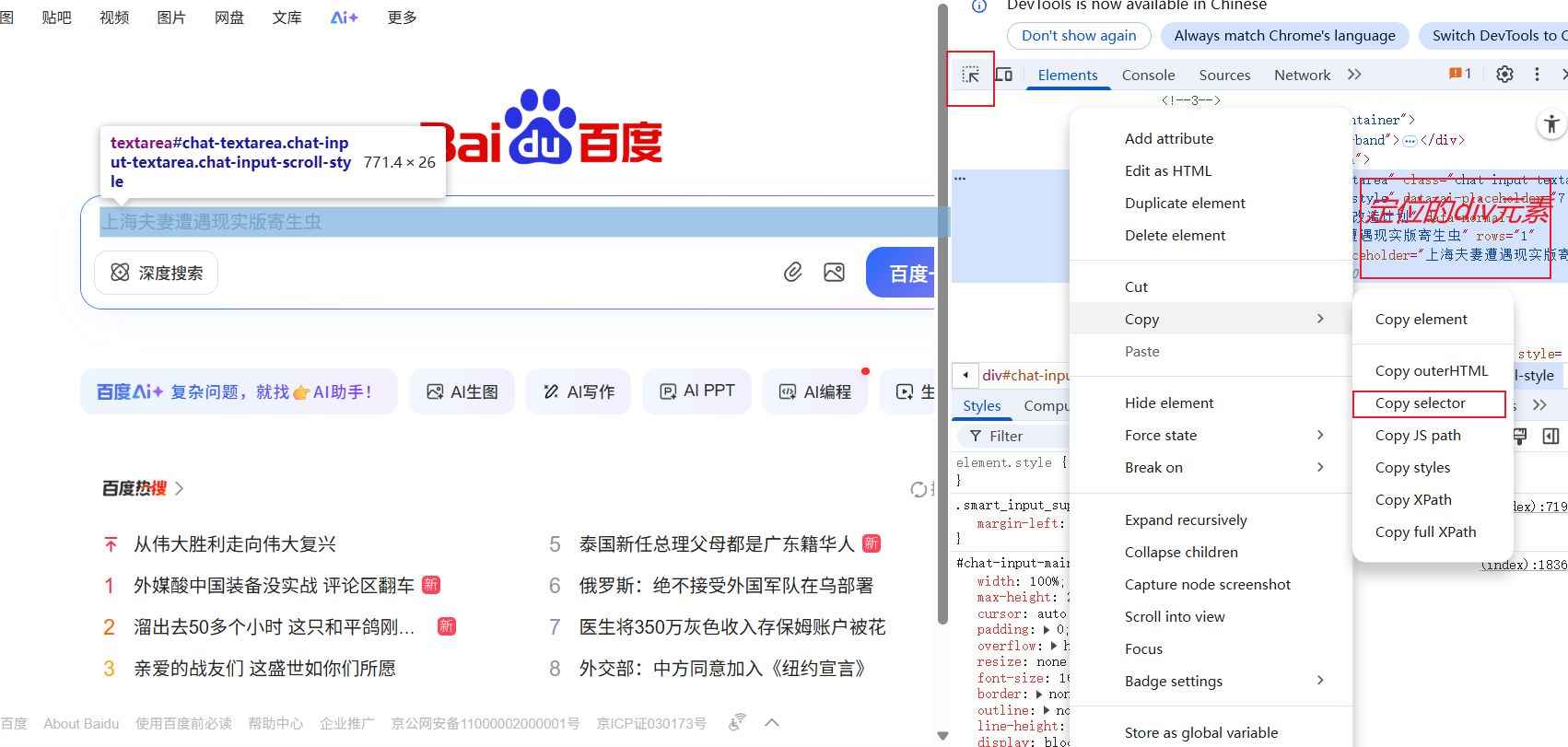
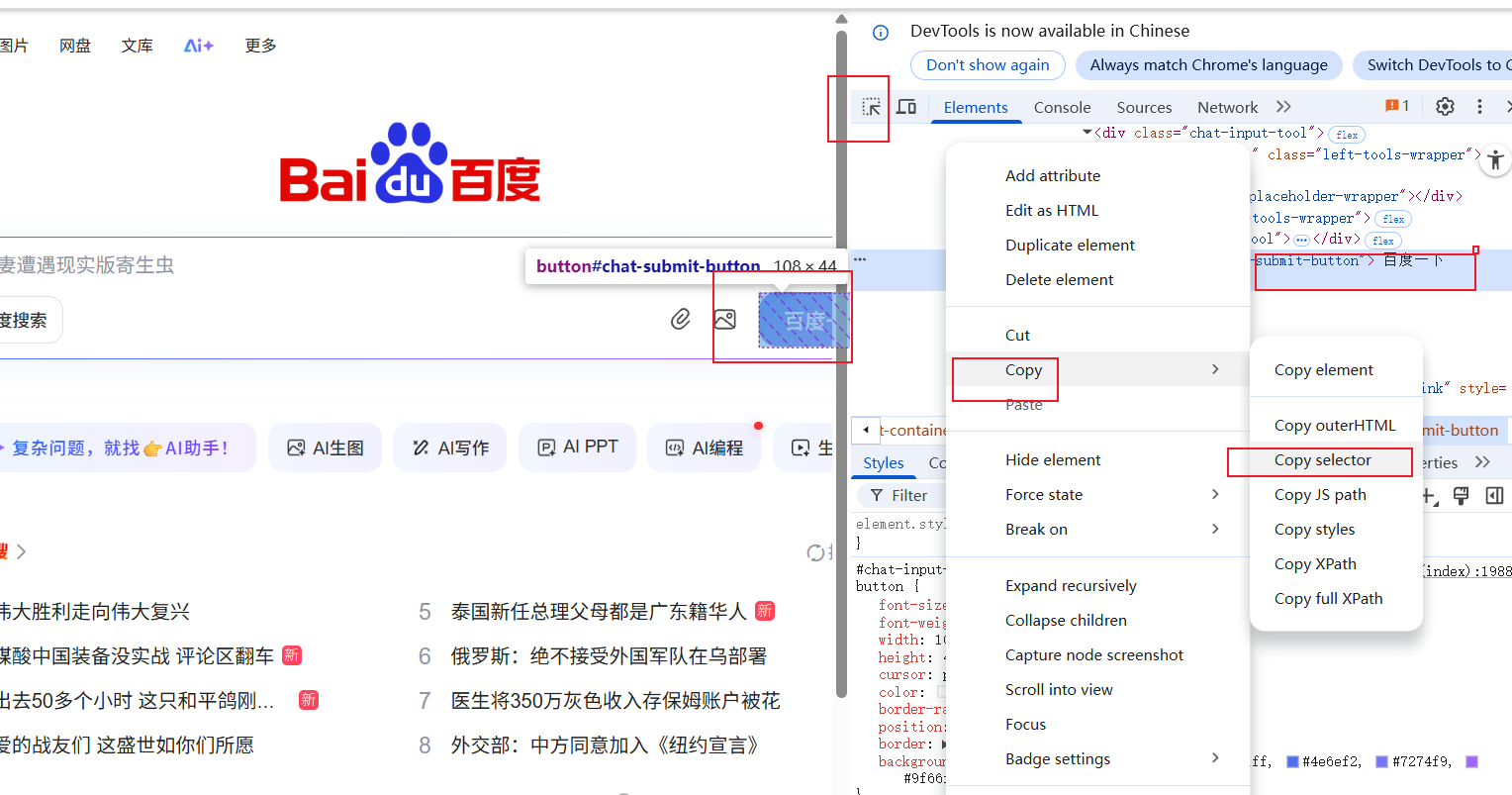
元素定位后很快实现了这个自动化操作,元素定位有几种方式,其中用id或者css_selector最常用。 发现搜索框和搜索按钮的css_selector变化了分别是:#chat-textarea #chat-submit-button
3.整合pytest
小白的疑惑,使用ython做web自动化测试时,有了selenium库,为什么还要用到pytest?
有个恰当的比喻:
-
Selenium = 演员(执行具体的浏览器操作)
-
pytest = 导演+制片人(组织、管理、报告测试)
| 功能维度 | Selenium | pytest |
|---|---|---|
| 主要职责 | 浏览器自动化操作 | 测试框架管理 |
| 功能 | 点击、输入、导航等 | 测试组织、断言、测试报告 |
| 定位 | 元素定位和交互 | 测试用例管理和执行 |
| 报告 | 无内置报告功能 | 丰富的报告生成 |
| 数据驱动 | 需要自己实现 | 内置数据驱动支持 |
没有pytest只能写脚本,有 pytest就能做结构化测试。
记住一些规则,pytest 就能自动发现并运行您的测试了!这是 pytest 的"约定优于配置"理念的体现。Java里的sprongboot也提到过这个理念!
| 项目 | 规则 | 示例 |
|---|---|---|
| 测试文件 | test_*.py 或 *_test.py | test_login.py, login_test.py |
| 测试函数 | 以 test_ 开头 | test_valid_login() |
| 测试类 | 以 Test 开头 | TestLogin |
| 类方法 | 以 test_ 开头 | test_login_success() |
我把登录和注册两个测试用例写在main方法里,结果运行就报错了!
Fixture (夹具)是 pytest 测试框架的核心机制,它通过依赖注入(spring里核心就是控制反转和依赖注入!)模式实现测试资源的声明式管理。其主要作用体现在三个维度:
-
资源生命周期治理 - 封装测试对象的创建、分配与销毁过程,确保资源使用的规范性和安全性
-
测试环境一致性保障 - 通过预设环境状态,消除测试间的相互干扰,保证测试用例的独立性与可重复性
-
测试代码重构优化 - 分离测试逻辑与基础设施代码,降低耦合度,提升测试套件的可维护性与可扩展性
说人话就是准备工作写在fixture修饰的方法里,看下面的代码就一目了然了
Scope 是 pytest 夹具中控制资源生命周期范围的核心参数,它定义了夹具实例在测试会话中的创建频率和共享范围。我当时的范围是module(同一模块内所有测试共享夹具实例),运行两个测试用例(登录和注册)会报错,哪怕我按照deepseek的建议在登录用例结束后不要调用 browser.quit(),给我的理由是测试函数中手动调用 browser.quit() 破坏了fixture的生命周期管理,第二个测试用例尝试使用已被关闭的浏览器实例! 但是我注释调这句话还是报错,注册用例依然不能正常运行,界面都打不开!把作用域改成function就没问题,哪怕登录用例加上browser.quit()也可以正确运行!
# 导入所需的库
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
import pytest
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.support.wait import WebDriverWait
# 定义 fixture 用于初始化和关闭浏览器
@pytest.fixture(scope="function")
def browser():
# 创建 ChromeOptions 对象
chrome_options = Options()
# 指定 Chrome 浏览器路径(使用你之前成功的路径)
chrome_binary_path = r"C:\Users\wenyong\.cache\selenium\chrome\win64\140.0.7339.80\chrome.exe"
chrome_options.binary_location = chrome_binary_path
# 添加其他选项
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])
chrome_options.add_experimental_option('useAutomationExtension', False)
# 1. 打开浏览器并访问登录页面
driver = webdriver.Chrome(options=chrome_options) # 初始化 Chrome 浏览器
driver.implicitly_wait(10) # 设置隐式等待时间为 10 秒
yield driver # 返回浏览器对象
driver.quit() # 测试结束后关闭浏览器
def test_login(browser):
# 打开登录页面
browser.get("https://hmshop-test.itheima.net/Home/user/login.html") # 打开登录页面
# 输入用户名
username_input = browser.find_element(By.CSS_SELECTOR, "#username") # 定位用户名输入框
username_input.clear() # 清空用户名输入框
username_input.send_keys("13600001111") # 输入用户名 13600001111
# 输入密码
password_input = browser.find_element(By.CSS_SELECTOR, "#password") # 定位密码输入框
password_input.clear() # 清空密码输入框
password_input.send_keys("123456") # 输入密码 123456
# 输入图片验证码
verify_code_input = browser.find_element(By.CSS_SELECTOR, "#verify_code") # 定位验证码输入框
verify_code_input.clear() # 清空验证码输入框
verify_code_input.send_keys("8888") # 输入验证码 8888
# 点击登录按钮
login_button = browser.find_element(By.CSS_SELECTOR, "#loginform > div > div.login_bnt > a") # 定位登录按钮
login_button.click() # 点击登录按钮
time.sleep(3)
# 关闭浏览器
#browser.quit()
#注册的测试用例
def test_register(browser):
# 1. 访问注册页面
browser.get("https://hmshop-test.itheima.net/Home/User/reg.html")
wait = WebDriverWait(browser, 20)
current_url = browser.current_url
print(f"当前URL: {current_url}")
print(f"页面标题: {browser.title}")
# 2. 输入用户名
username_input = browser.find_element(By.CSS_SELECTOR, "#username")
username_input.clear()
username_input.send_keys("19896257372")
# 3. 输入密码
password_input = browser.find_element(By.CSS_SELECTOR, "#password")
password_input.clear()
password_input.send_keys("1989625")
#4.输入验证码
verify_code_input = browser.find_element(By.CSS_SELECTOR, "#reg_form2 > div > div > div > div:nth-child(2) > div.liner > input")
# 5. 输入确认密码
confirm_password_input = browser.find_element(By.CSS_SELECTOR, "#password2")
confirm_password_input.clear()
confirm_password_input.send_keys("123456")
#点击同意协议并注册
agree_button = browser.find_element(By.CSS_SELECTOR, "#reg_form2 > div > div > div > div.line.liney.clearfix > div > a")
agree_button.click()
执行也不是run某个文件 ,而是在终端用pytest!
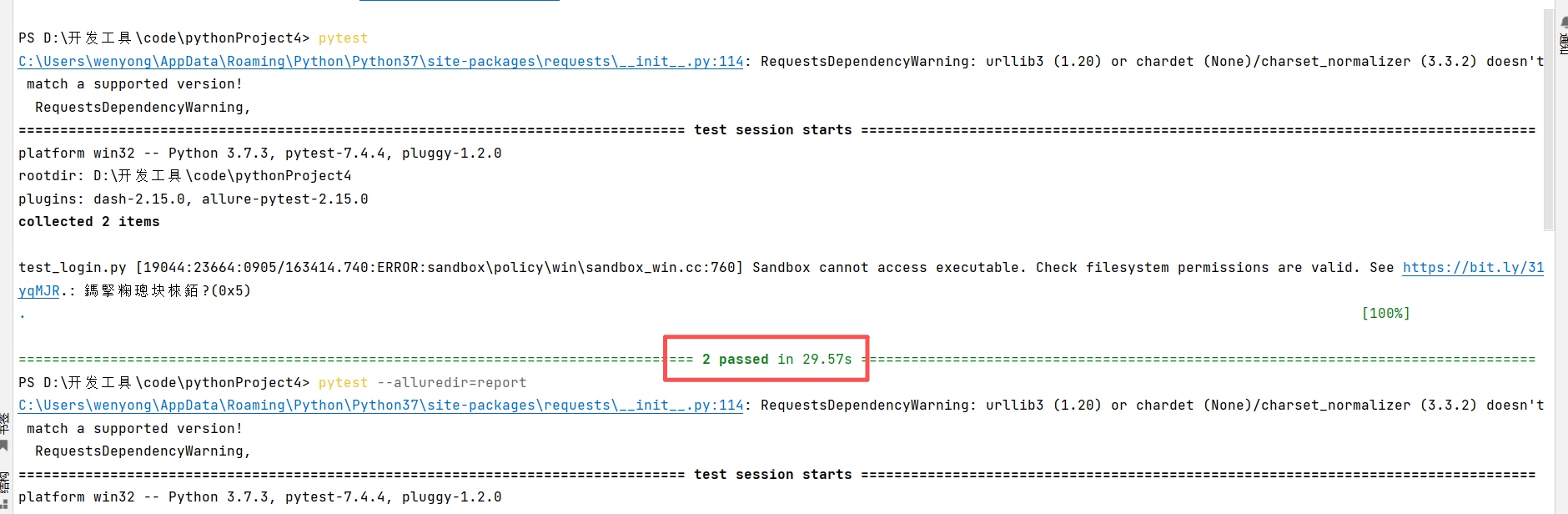
生成测试结果:pytest -–alluredir=report,将结果转为报告:allure serve report 需要两个环境:一是java运行环境(allure核心解析测试结果数据、生成报告的逻辑是java开发的),二是要node.js环境(npm包下载allure命令行工具,npm需要node环境,生成后的静态文件(HTML/CSS/JS写的Allure 报告的前端界面)本身不依赖 Node,直接用浏览器打开即可查看。)
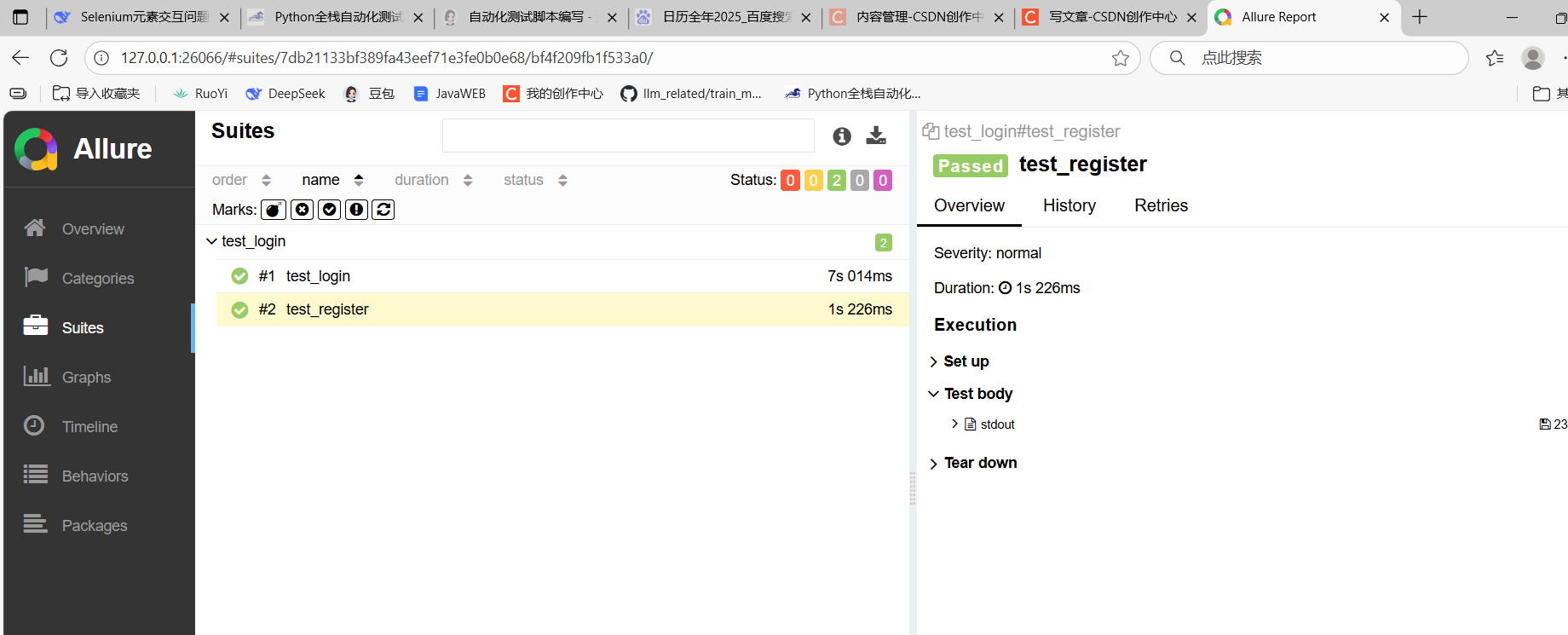
4.自动化测试的应用场景:
回归测试:包括缺陷修复后手动做的回归测试,还有Git push后通过cicd流水线自动触发的自动化测试套件。
冒烟测试:仅验证软件最核心、最基本的功能(如登录、主要流程操作、关键按钮响应等),不涉及复杂场景或细节功能。电商平台的冒烟测试可能包括 “打开首页→搜索商品→加入购物车→提交订单” 这一核心流程,可能不涉及测试优惠券使用、退款等细节。执行时间短(通常几分钟到一小时内),目的是快速反馈软件是否 “可测”,尽早发现严重问题!
数据驱动的参数化的测试也适合做自动化,比如登录,要考虑很多边界值,一个个手动执行不如把这些边界值参数都做成参数让程序一个个跑。
压力测试:高并发、大流量场景难以手动模拟!压力测试常需要持续数小时甚至数天(如验证系统的稳定性、内存泄漏问题),手动测试无法长时间保持高效、一致的操作,而自动化脚本可以 24 小时不间断执行。压力测试需收集响应时间、错误率、服务器 CPU / 内存占用等大量指标,自动化工具可实时记录并生成可视化报告(如 TPS 曲线、响应时间分布),手动记录不仅效率低,还易出错。 下一篇博客,我就要写python自动化测试做接口自动化、app自动化,web自动化看看还有什么可以补充!

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









