



1.1 介绍部分:
文字提到常用的Web框架有Django和Flask,接下来将学习一个全球范围内流行的爬虫框架Scrapy。
1.2 内容部分:
Scrapy的概念、作用和工作流程
Scrapy的入门使用
Scrapy构造并发送请求
Scrapy模拟登陆
Scrapy管道的使用
Scrapy中间件的使用
Scrapy_redis概念作用和流程
Scrapy_redis原理分析并实现断点续爬以及分布式爬虫
Scrapy_splash组件的使用
Scrapy的日志信息与配置
Scrapyd部署Scrapy项目
1.2.1 原始爬虫工作流程
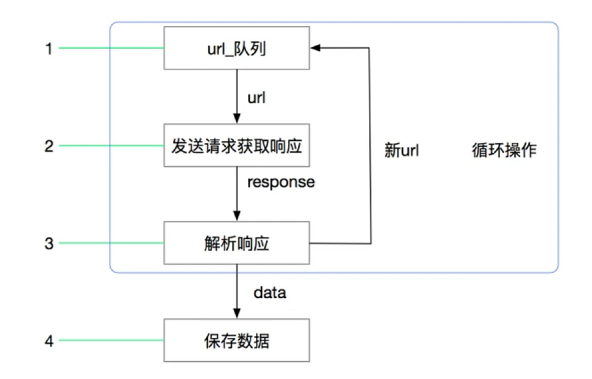
原始框架转换成矩形展示
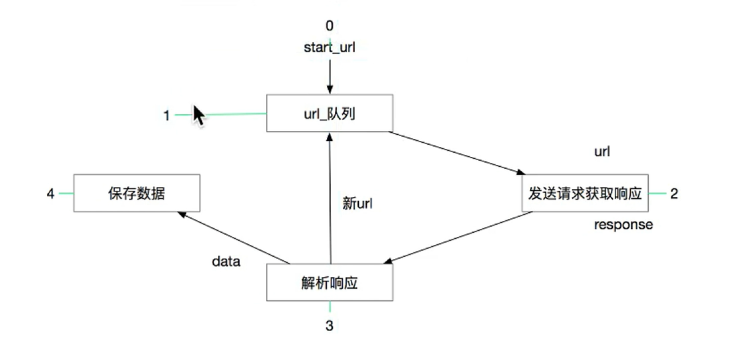
1.2.2 scrapy框架模型
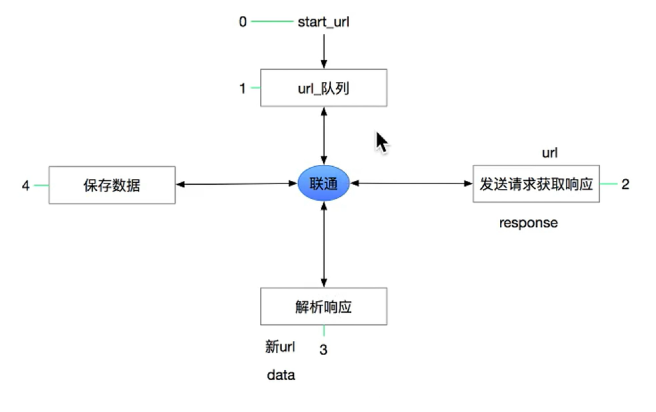
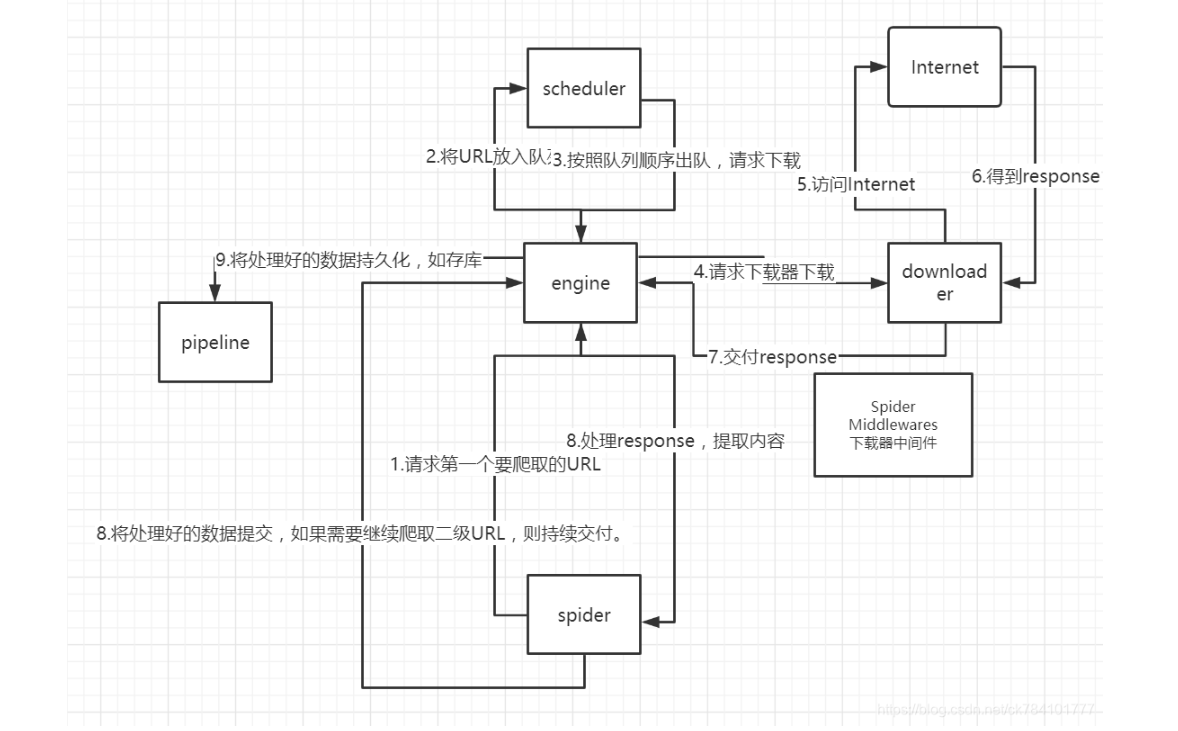
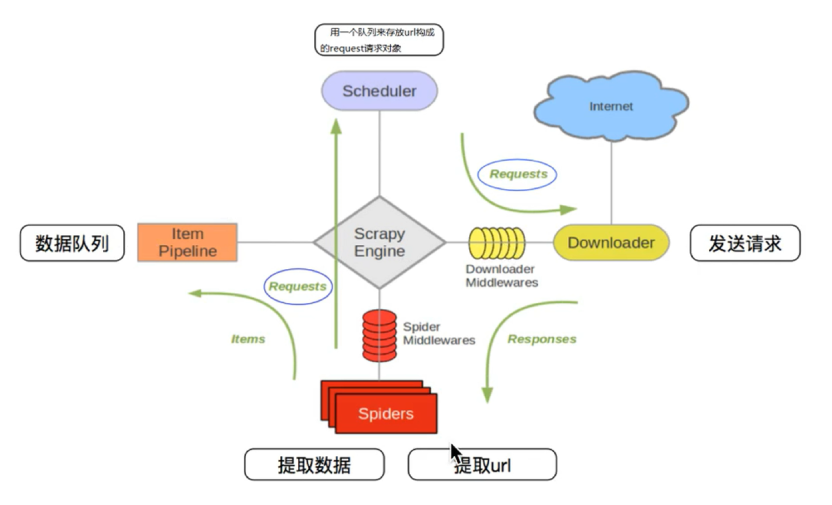
其流程可以描述如下:
爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
调度器把request–>引擎–>下载中间件–>下载器
下载器发送请求,获取response响应–>下载中间件–>引擎–>爬虫中间件–>爬虫
爬虫提取url地址,组装成request对象–>爬虫中间件–>引擎–>调度器,重复步骤2

















 8630
8630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









