



目录
JDK安装与配置
·由于Hadoop是由Java语言开发的,Hadoop集群的使用依赖于Java环境,因此安装Hadoop集群之前,需要先安装并配置好JDK。
1.下载JDK压缩包
·下载链接:https://www.oracle.com/webapps/redirect/signon?nexturl=https://download.oracle.com/otn/java/jdk/8u231-b10/424b9da4b48848379167015dcc250d8d/jdk-8u231-linux-i586.tar.gz
(需要登录Oracle官网才能下载)https://www.oracle.com/webapps/redirect/signon?nexturl=https://download.oracle.com/otn/java/jdk/8u231-b10/424b9da4b48848379167015dcc250d8d/jdk-8u231-linux-i586.tar.gz
2.上传到master虚拟机
·将JDK压缩包上传到master虚拟机/opt目录
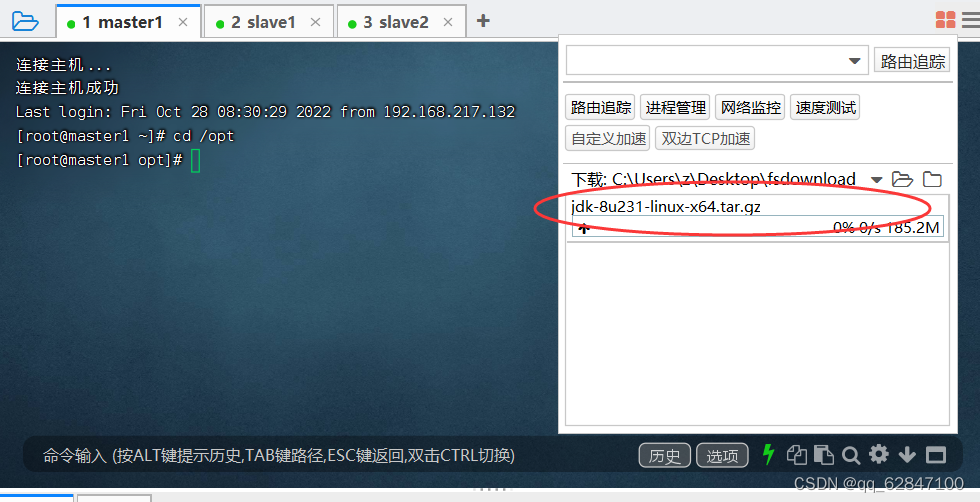
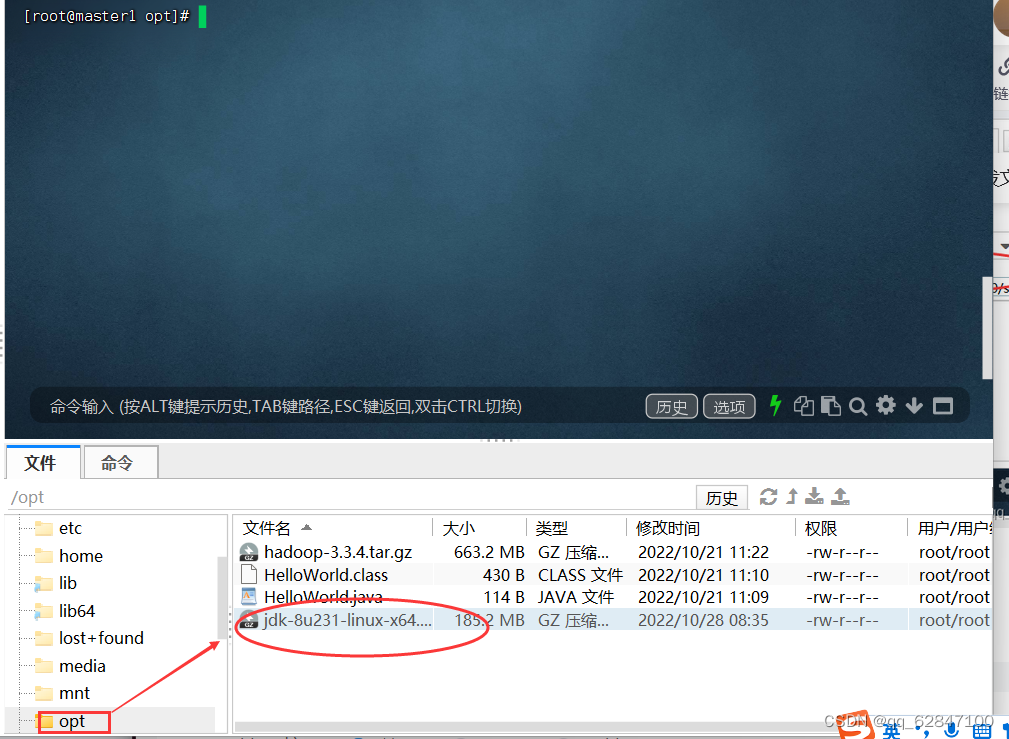
·查看上传的JDK压缩包
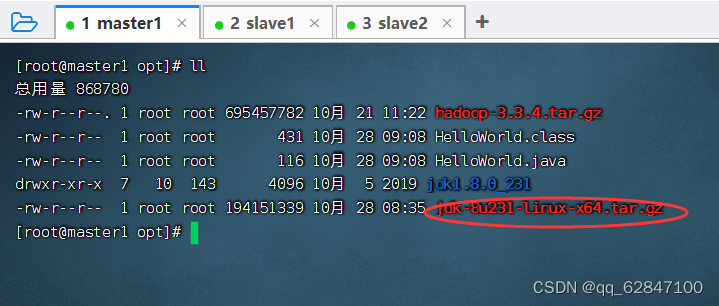
3、在master虚拟机上安装配置JDK
`执行命令:tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local,将JDK压缩包解压到指定目录

`执行命令:ll /usr/local/jdk1.8.0_231,查看解压之后的jdk1.8.0_231目录
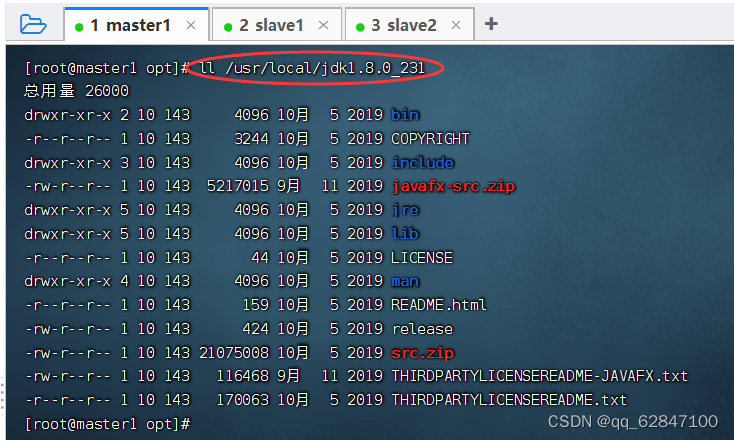
·执行命令:vim /etc/profile,配置环境变量
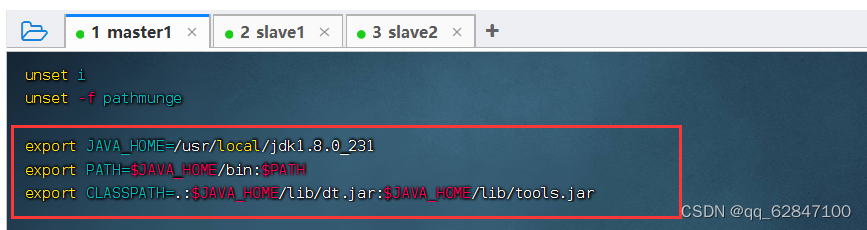
export JAVA_HOME=/usr/local/jdk1.8.0_231
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
·存盘退出,执行命令:source /etc/profile,让配置生效

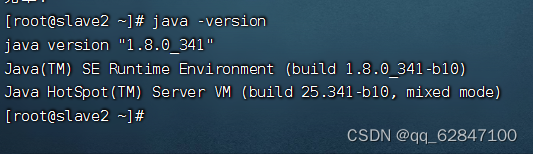
·查看JDK版本
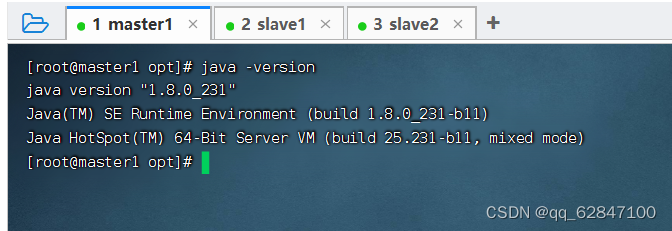
· 编写一个Java程序 vim HelloWorld.java
·存盘退出后,执行命令:javac HelloWorld.java,编译成字节码文件
·执行命令:java HelloWorld

4、将JDK分发到slave1和slave2虚拟机
·执行命令:scp -r $JAVA_HOME root@slave1:$JAVA_HOME (-r:recursive - 递归)
·在slave1虚拟机上查看JDK是否拷贝成功
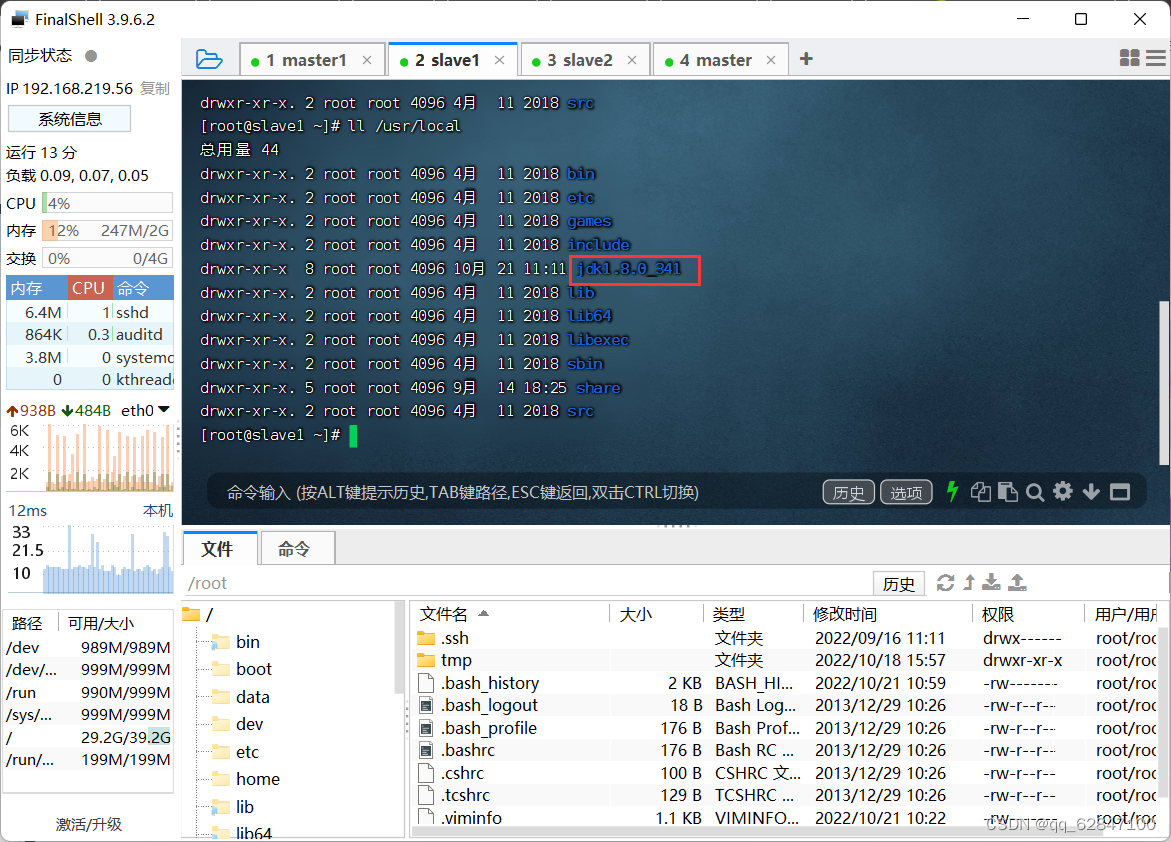 ·执行命令:
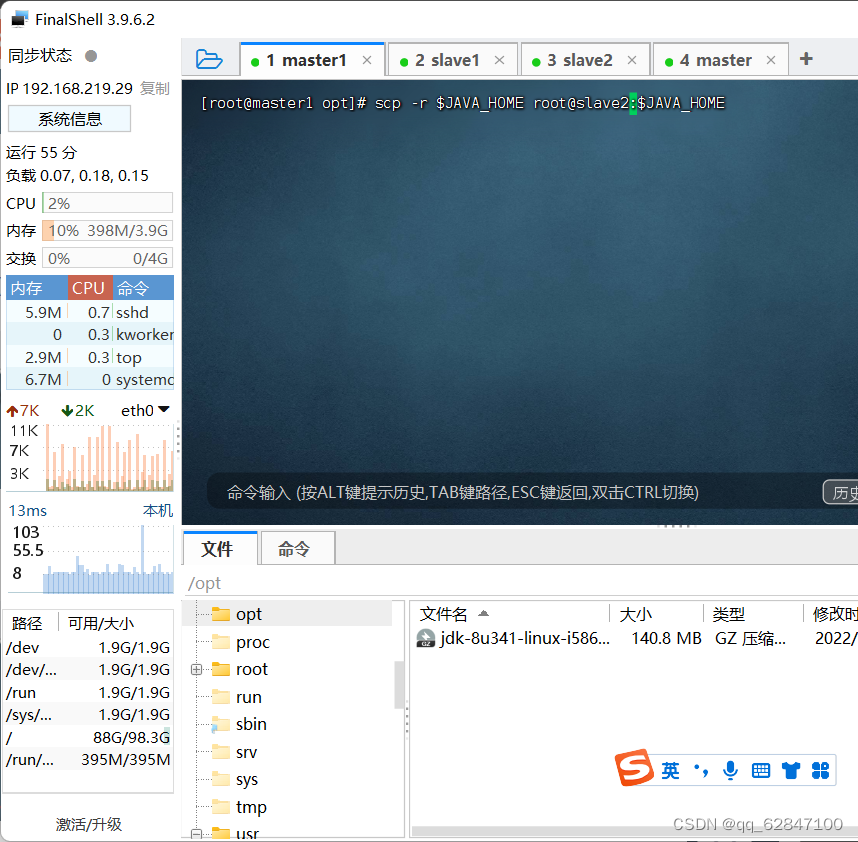
·执行命令:scp -r $JAVA_HOME root@slave2:$JAVA_HOME (-r recursive - 递归)
·在slave2虚拟机上查看JDK是否拷贝成功
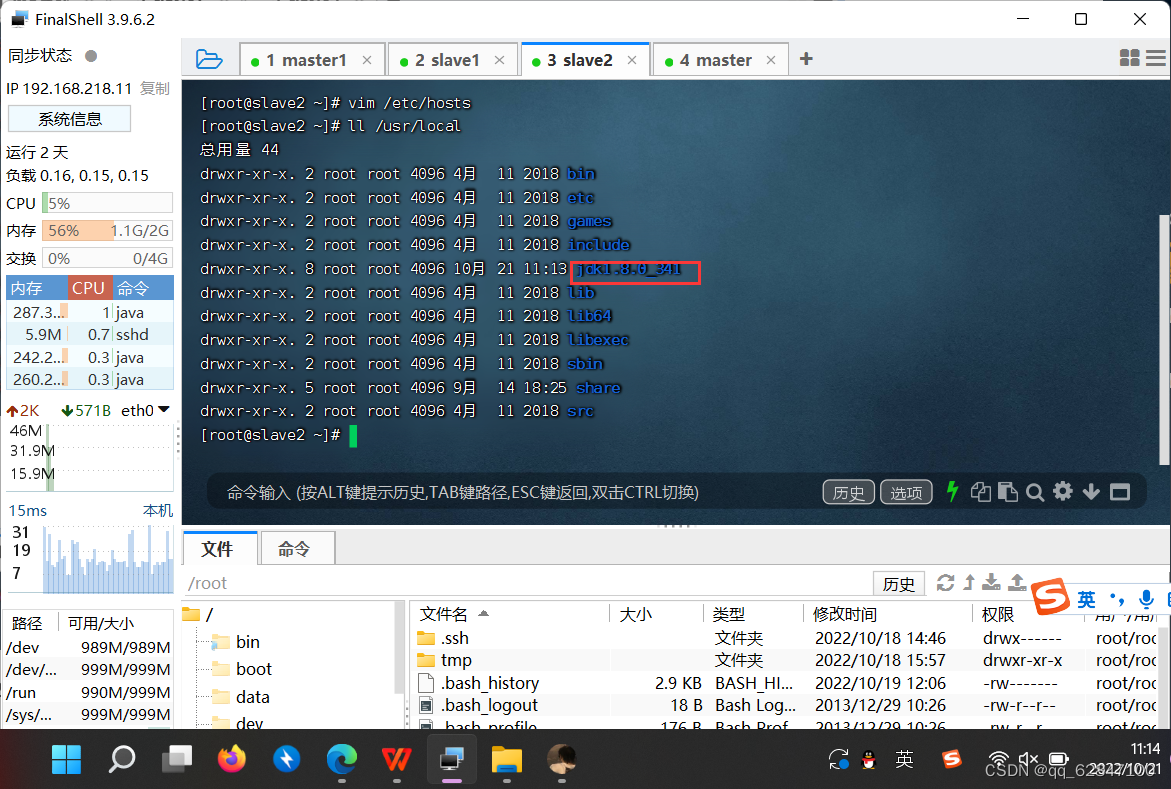
5、将环境配置文件分发到slave1和slave2虚拟机
·执行命令:scp /etc/profile root@slave1:/etc

·执行命令:scp /etc/profile root@slave2:/etc

·在slave1与slave2虚拟机上执行命令:source /etc/profile,让环境配置生效


·在slave1、slave2虚拟机上查看JDK版本
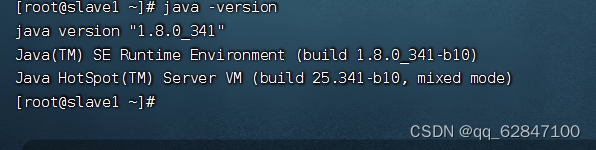
Hadoop安装
·Hadoop是Apache基金会面向全球开源的产品之一,任何用户都可以从Apache Hadoop官网下载使用。本次学习Hadoop,我们使用目前的最新版 - hadoop-3.3.4。
1、下载Hadoop压缩包
2、上传Hadoop压缩包到虚拟机
·将Hadoop压缩包上传到master虚拟机/opt目录
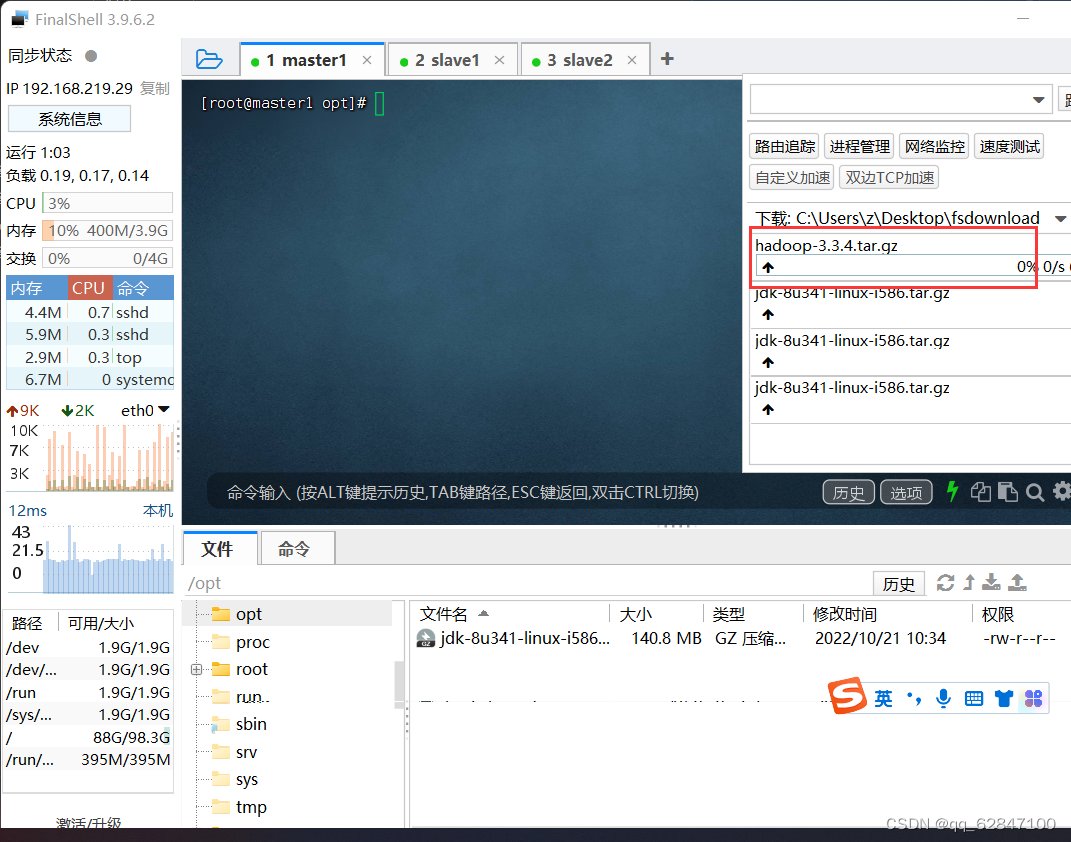
· 查看上传的Hadoop压缩包
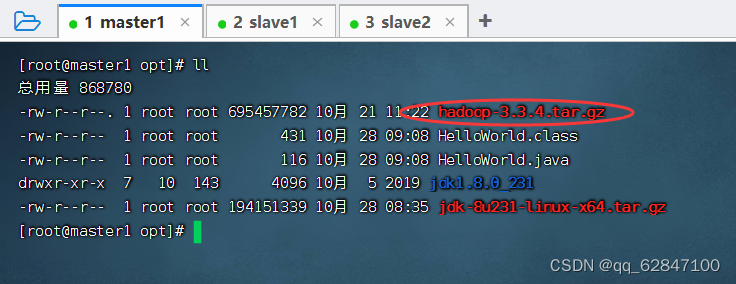
5、将Hadoop压缩包解压到指定目录
·执行命令:tar -xzvf hadoop-3.3.4.tar.gz -C /usr/local
·查看解压之后的hadoop目录
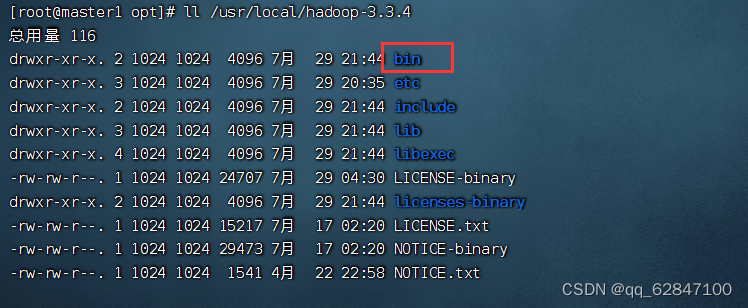
| 目录 | 作用 |
|---|---|
| bin目录 | 命令脚本 |
| etc/hadoop目录 | 存放hadoop的配置文件 |
| lib目录 | hadoop运行的依赖jar包 |
| sbin目录 | 存放启动和关闭hadoop等命令 |
| libexec目录 | 存放的也是hadoop命令,但一般不常用 |
·在配置Hadoop时,常用的就是bin、etc与sbin三个目录
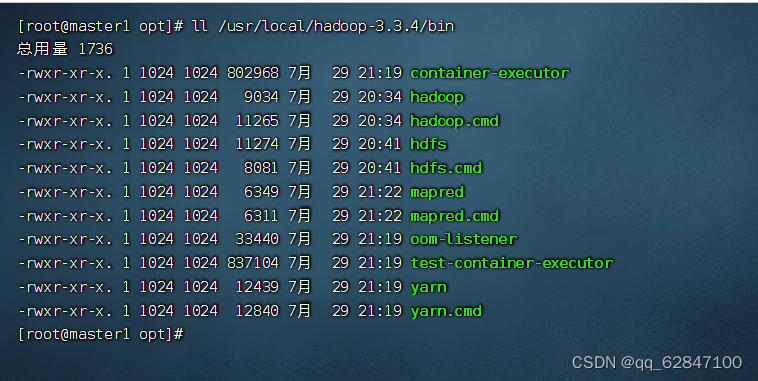
·查看bin目录
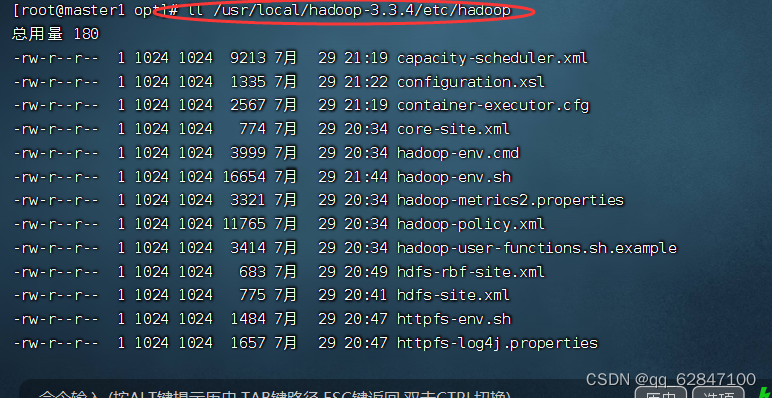
查看etc/hadoop目录,主要是hadoop配置文件
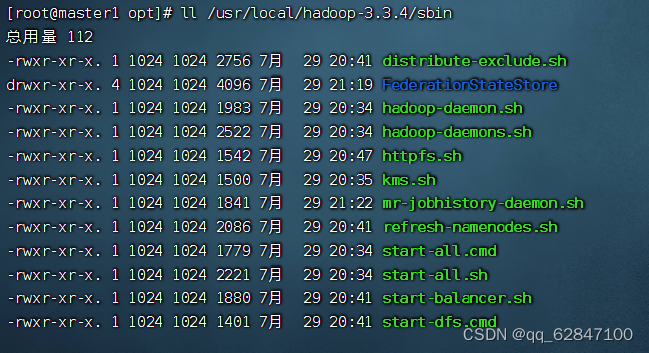
查看sbin目录
4、配置Hadoop环境变量
·执行命令:vim /etc/profile
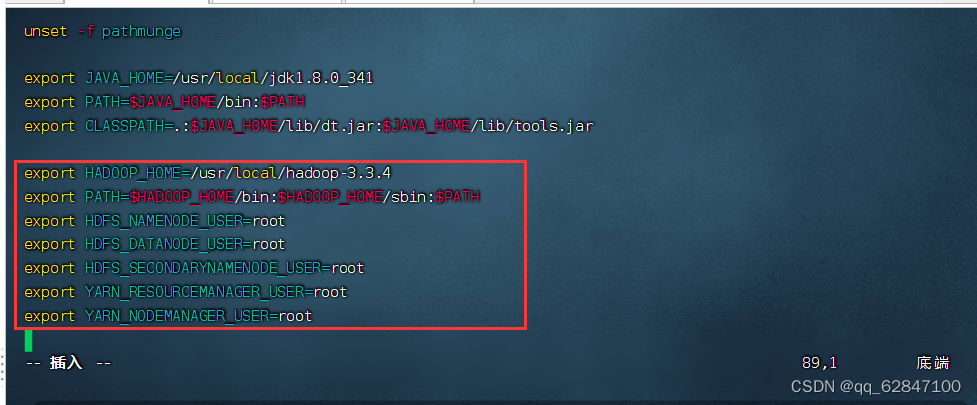
·说明:hadoop 2.x用不着配置用户,只需要前两行即可
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
·存盘退出,执行命令source /etc/profile,让配置生效
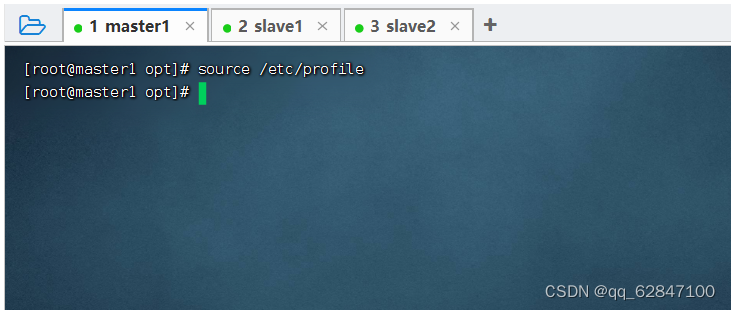
5、验证Hadoop环境
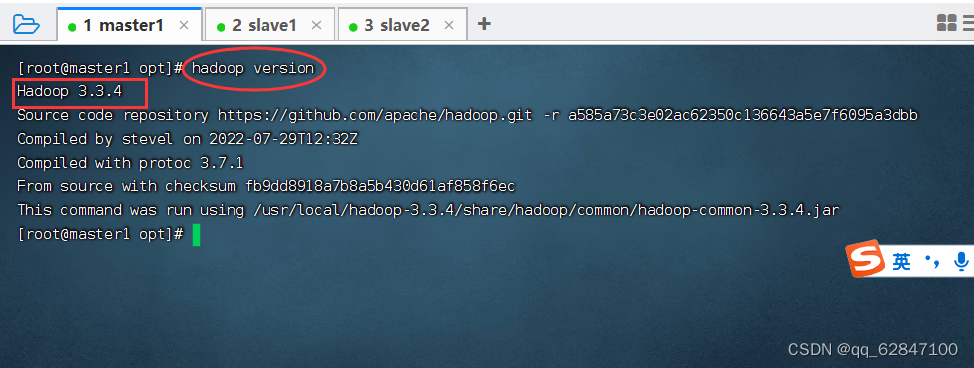
·执行命令:hadoop version,检查Hadoop安装是否成功

















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









