




 本文介绍了PyTorch中用于图像预处理的Transforms模块,包括ToTensor用于将PIL图像转换为张量,Normalize进行归一化处理,Resize进行图像尺寸调整,Compose组合多个变换,以及RandomCrop进行随机裁剪。示例代码展示了这些变换的使用方法,并利用tensorboard进行可视化。
本文介绍了PyTorch中用于图像预处理的Transforms模块,包括ToTensor用于将PIL图像转换为张量,Normalize进行归一化处理,Resize进行图像尺寸调整,Compose组合多个变换,以及RandomCrop进行随机裁剪。示例代码展示了这些变换的使用方法,并利用tensorboard进行可视化。
目录
1. 基本知识
图片引用来自b站up主:我是土堆
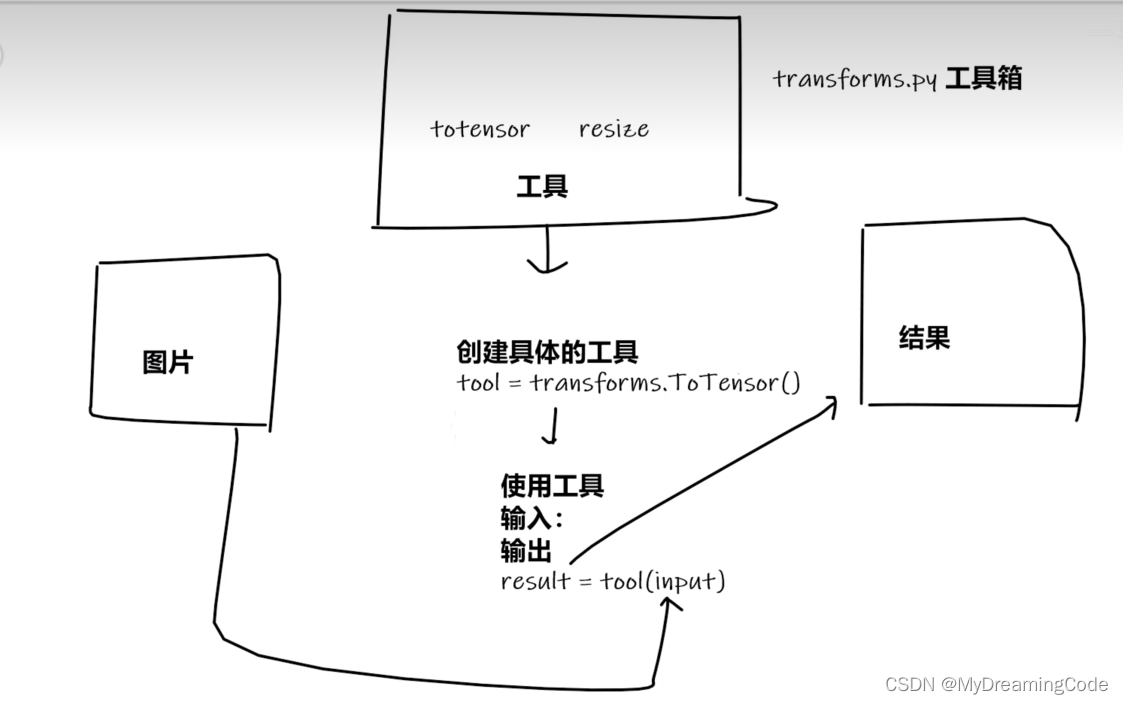
tf.py(如何使用transforms里面的工具)
具体的工具还是要看里面的类是如何去定义的,然后再使用。
from PIL import Image
from torchvision import transforms
img_path = 'data/train/ants_image/0013035.jpg'
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)
result:
tensor([[[0.3137, 0.3137, 0.3137, ..., 0.3176, 0.3098, 0.2980],
[0.3176, 0.3176, 0.3176, ..., 0.3176, 0.3098, 0.2980],
[0.3216, 0.3216, 0.3216, ..., 0.3137, 0.3098, 0.3020],
...,
[0.3412, 0.3412, 0.3373, ..., 0.1725, 0.3725, 0.3529],
[0.3412, 0.3412, 0.3373, ..., 0.3294, 0.3529, 0.3294],
[0.3412, 0.3412, 0.3373, ..., 0.3098, 0.3059, 0.3294]],[[0.5922, 0.5922, 0.5922, ..., 0.5961, 0.5882, 0.5765],
[0.5961, 0.5961, 0.5961, ..., 0.5961, 0.5882, 0.5765],
[0.6000, 0.6000, 0.6000, ..., 0.5922, 0.5882, 0.5804],
...,
[0.6275, 0.6275, 0.6235, ..., 0.3608, 0.6196, 0.6157],
[0.6275, 0.6275, 0.6235, ..., 0.5765, 0.6275, 0.5961],
[0.6275, 0.6275, 0.6235, ..., 0.6275, 0.6235, 0.6314]],[[0.9137, 0.9137, 0.9137, ..., 0.9176, 0.9098, 0.8980],
[0.9176, 0.9176, 0.9176, ..., 0.9176, 0.9098, 0.8980],
[0.9216, 0.9216, 0.9216, ..., 0.9137, 0.9098, 0.9020],
...,
[0.9294, 0.9294, 0.9255, ..., 0.5529, 0.9216, 0.8941],
[0.9294, 0.9294, 0.9255, ..., 0.8863, 1.0000, 0.9137],
[0.9294, 0.9294, 0.9255, ..., 0.9490, 0.9804, 0.9137]]])Process finished with exit code 0
tensor数据类型包含了反向传播理论基础的一些参数
tf.py
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import cv2
writer = SummaryWriter('logs')
img_path = 'data/train/ants_image/0013035.jpg'
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image('tensor_img', tensor_img)
writer.close()
2. 常见的Transforms
一些图片返回类型:
Image.open() -- PIL
ToTensor() -- tensor
cv.imread() / np.array() -- narrays
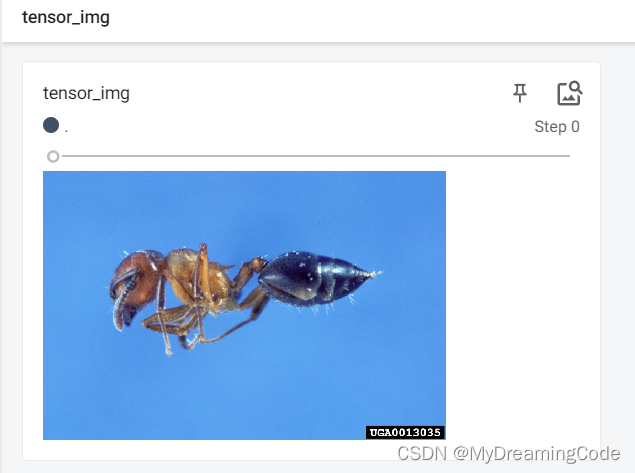
2.1 ToTensor的使用
目的:Convert a 'PIL Image' or 'numpy.ndarray' to tensor.
useful_tf.py
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter('logs')
img = Image.open('data/train/ants_image/5650366_e22b7e1065.jpg')
trans_tensor = transforms.ToTensor()
img_tensor = trans_tensor(img)
writer.add_image('ToTensor', img_tensor)
writer.close()
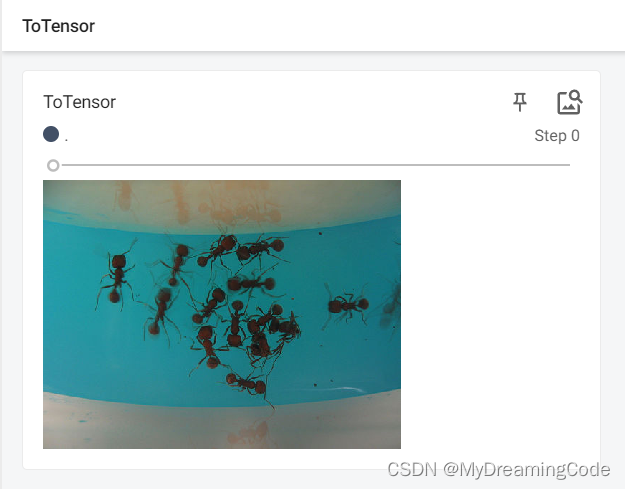
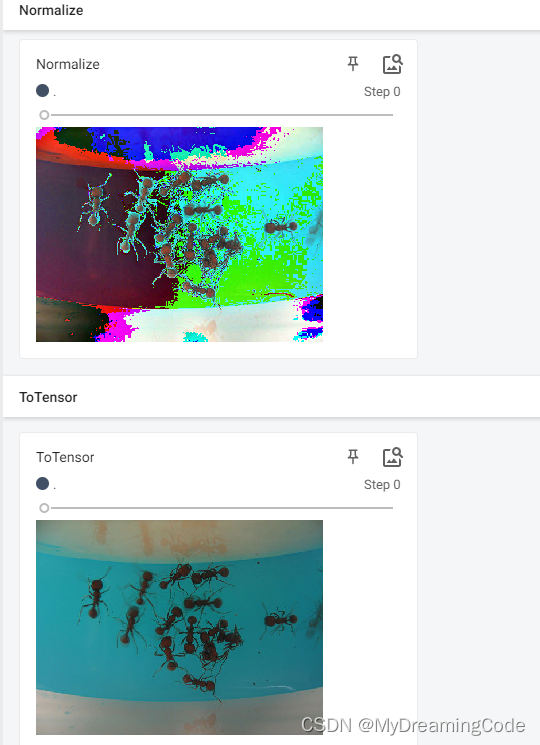
2.2 Normalize的使用
目的:Normalize a tensor image with mean and standard deviation.
useful_tf.py
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter('logs')
img = Image.open('data/train/ants_image/5650366_e22b7e1065.jpg')
# ToTensor
trans_tensor = transforms.ToTensor()
img_tensor = trans_tensor(img)
writer.add_image('ToTensor', img_tensor)
# Normalize
# output[channel] = (input[channel] - mean[channel]) / std[channel]
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image('Normalize', img_norm)
writer.close()
tensor(0.3804)
tensor(-0.2392)
2.3 Resize的使用
目的:Resize the input image to the given size.
useful_tf.py
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter('logs')
img = Image.open('data/train/ants_image/5650366_e22b7e1065.jpg')
# ToTensor
trans_tensor = transforms.ToTensor()
img_tensor = trans_tensor(img)
writer.add_image('ToTensor', img_tensor)
# Resize
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> PIL -> tensor
img_resize = trans_tensor(trans_resize(img))
print(img_resize.size)
writer.add_image('Resize', img_resize)
writer.close()
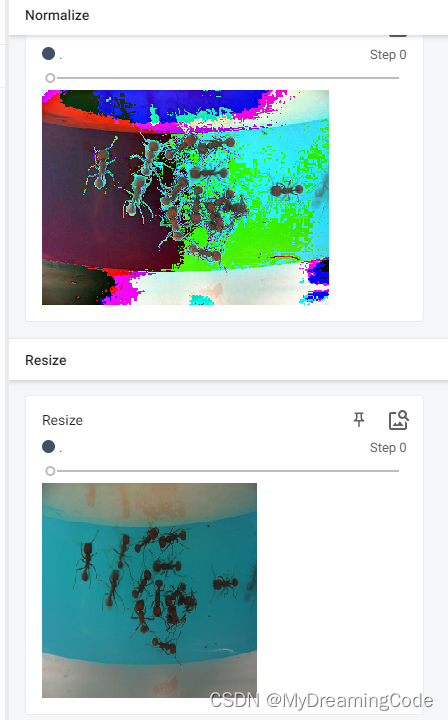
2.4 Compose的使用
目的:Compose several transforms together.
useful_tf.py
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter('logs')
img = Image.open('data/train/ants_image/5650366_e22b7e1065.jpg')
# ToTensor
trans_tensor = transforms.ToTensor()
img_tensor = trans_tensor(img)
writer.add_image('ToTensor', img_tensor)
# Resize
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> PIL -> tensor
img_resize = trans_tensor(trans_resize(img))
writer.add_image('Resize', img_resize)
# Resize2
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2, trans_tensor])
img_resize_2 = trans_compose(img)
writer.add_image('Resize-2', img_resize_2)
writer.close()
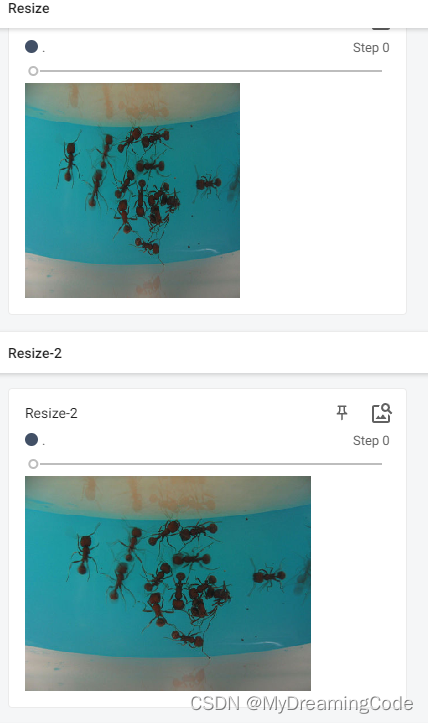
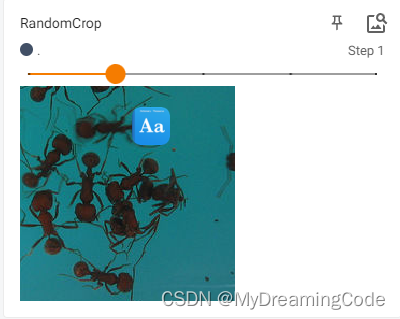
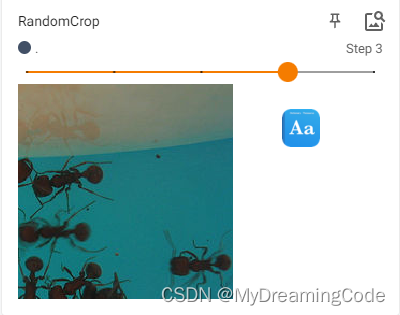
2.5 RandomCrop的使用
目的:Crop the given image at a random location.
useful_tf.py
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter('logs')
img = Image.open('data/train/ants_image/5650366_e22b7e1065.jpg')
# ToTensor
trans_tensor = transforms.ToTensor()
img_tensor = trans_tensor(img)
writer.add_image('ToTensor', img_tensor)
# Resize
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> PIL -> tensor
img_resize = trans_tensor(trans_resize(img))
writer.add_image('Resize', img_resize)
# Resize2
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2, trans_tensor])
img_resize_2 = trans_compose(img)
writer.add_image('Resize-2', img_resize_2)
# RandomCrop
trans_random = transforms.RandomCrop(200)
trans_compose_2 = transforms.Compose([trans_random, trans_tensor])
for i in range(5):
img_crop = trans_compose_2(img)
writer.add_image('RandomCrop', img_crop, i)
writer.close()


















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









