




目录
一、同一张图片不同位深度BMP文件对比
1、生成图片
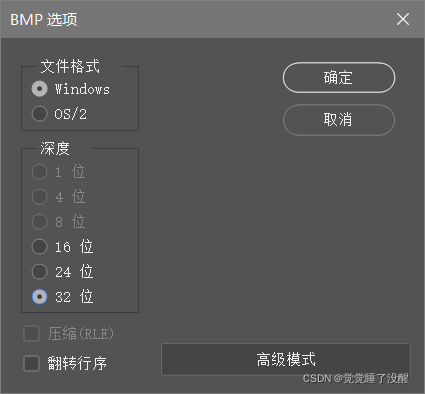
- 用photoshop打开一张图片,存储为不同位深的BMP文件
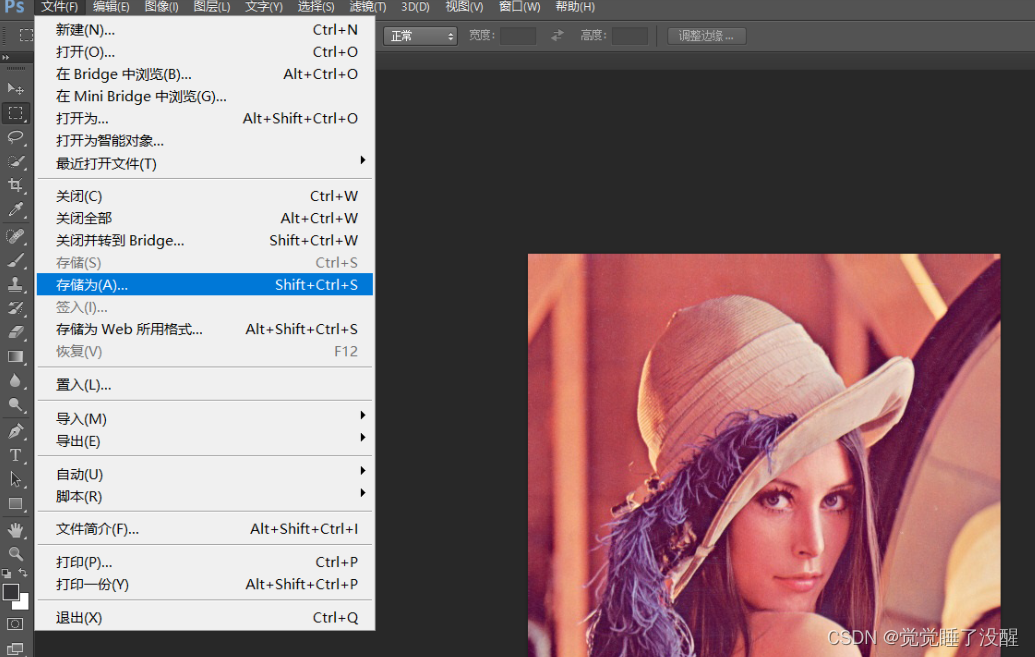
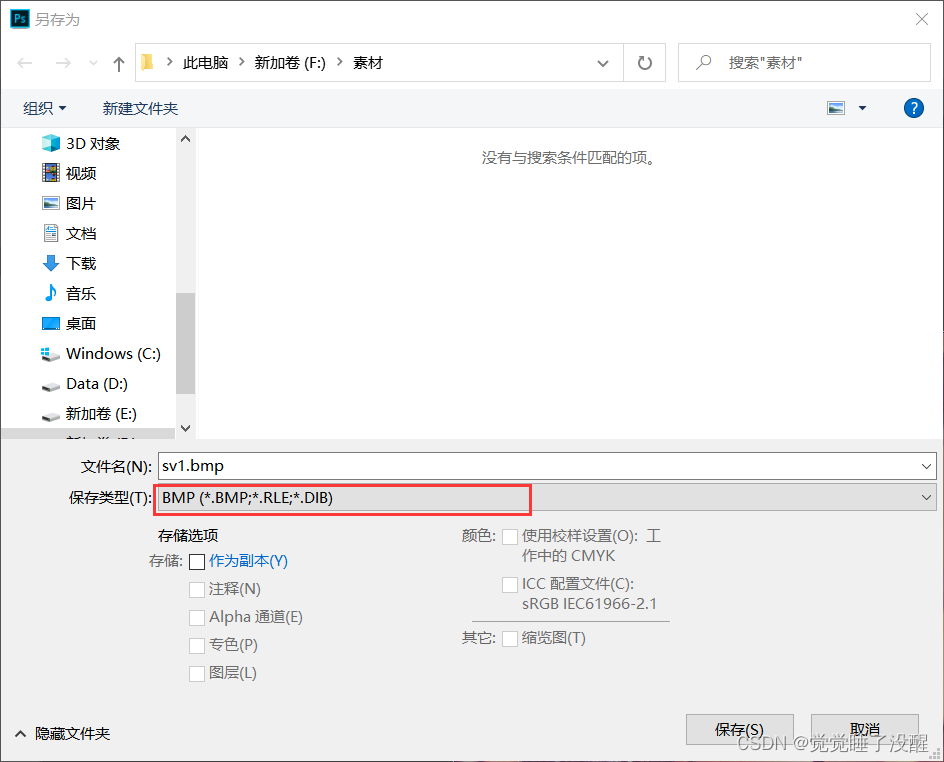
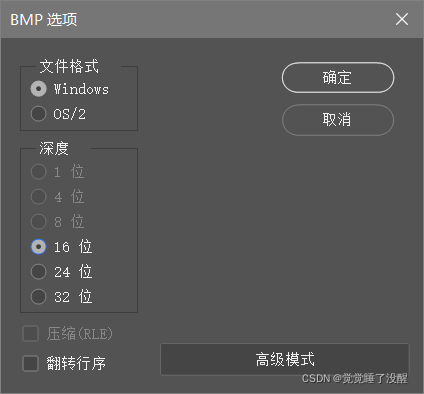
结果:

结果:

肉眼看的话是没什么区别的。
- 用电脑自带的画图工具生成256色、16色、单色的位图(BMP)文件
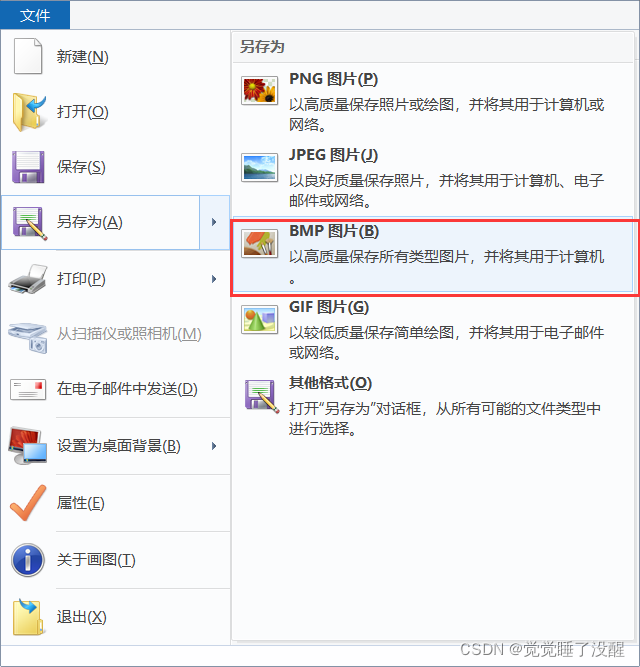
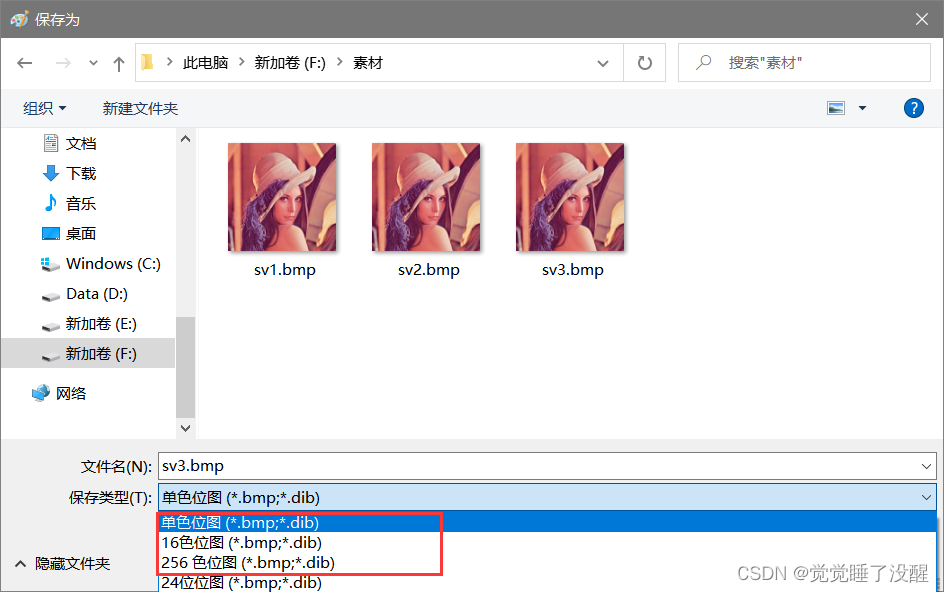
单色:

16色:

256色:

2、图片分析
- BMP文件结构
1.位图文件头(bitmap-file header)
2.位图信息头(bitmap-informationheader)
3.颜色表(color table)
4.颜色点阵数据(bits data)
24位真彩色位图没有颜色表,所以只有1、2、4这三部分。
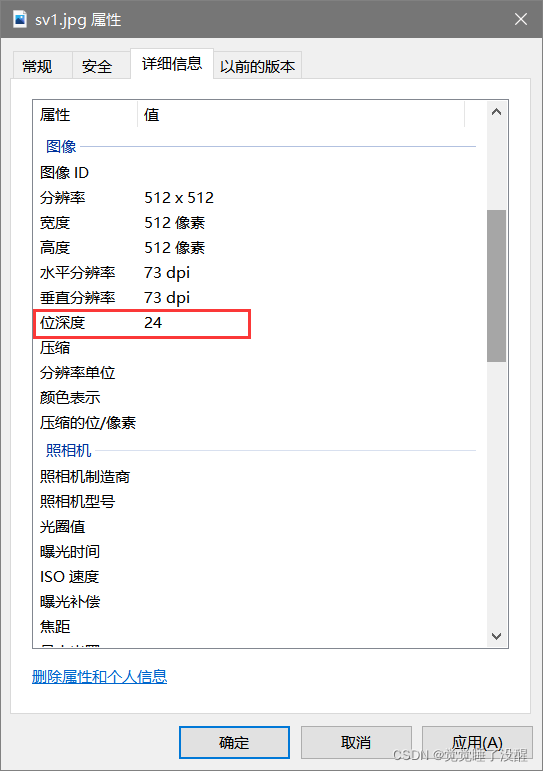
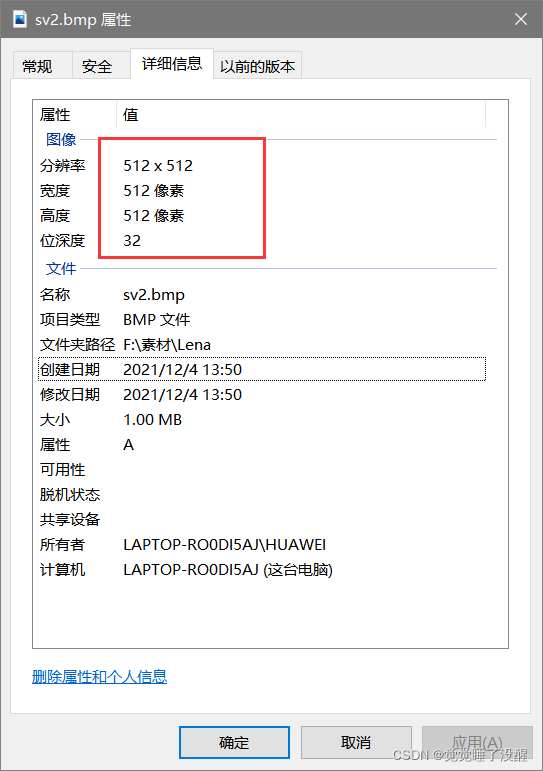
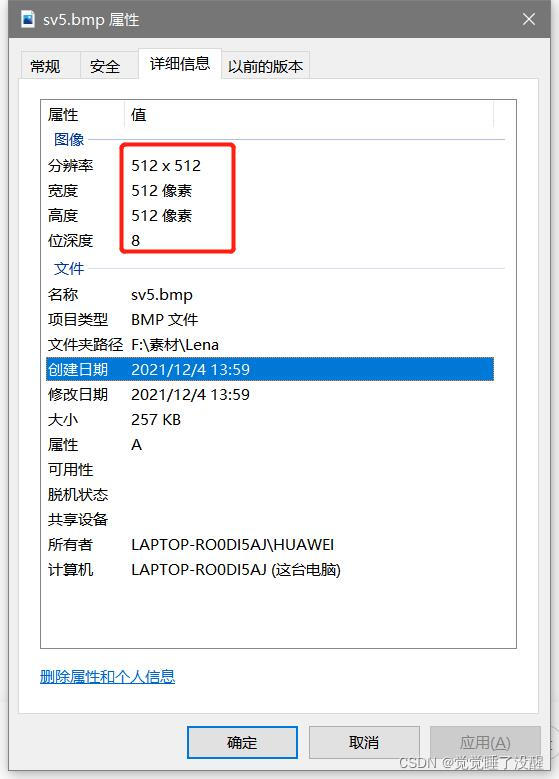
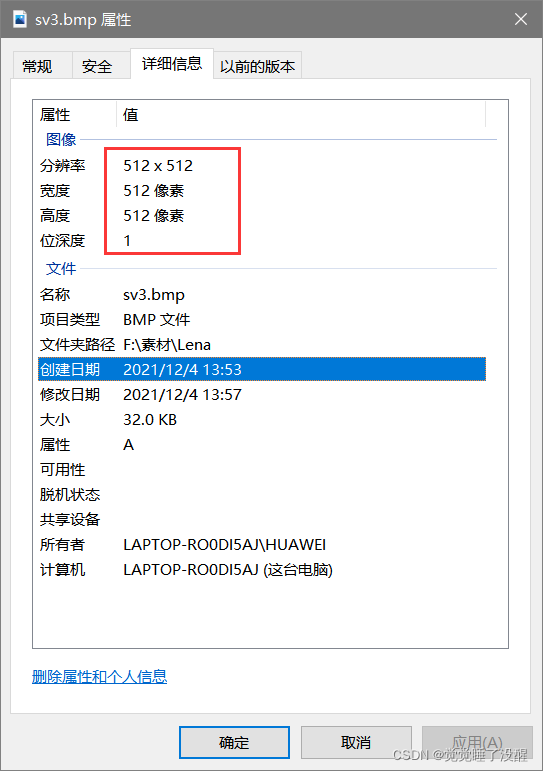
- 看图像属性,位深度,如果是24,就说明图片是24位真彩色
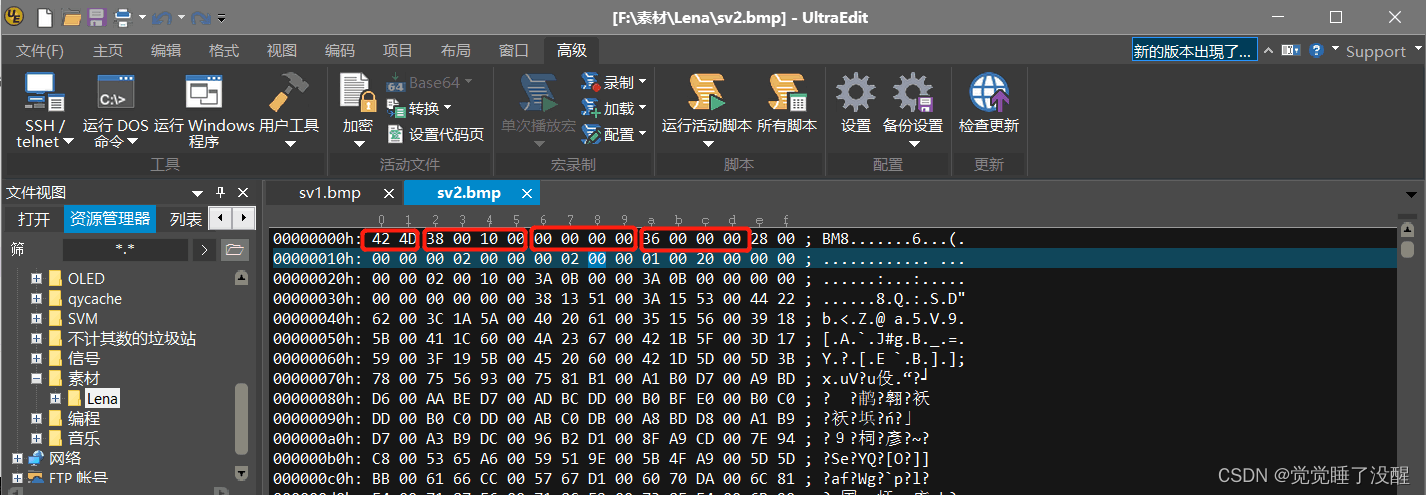
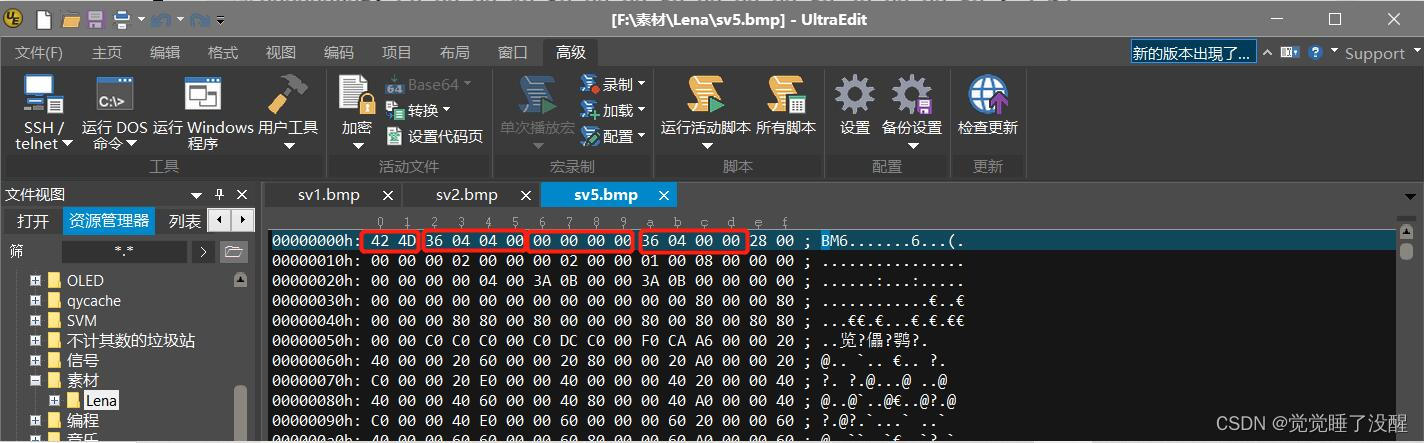
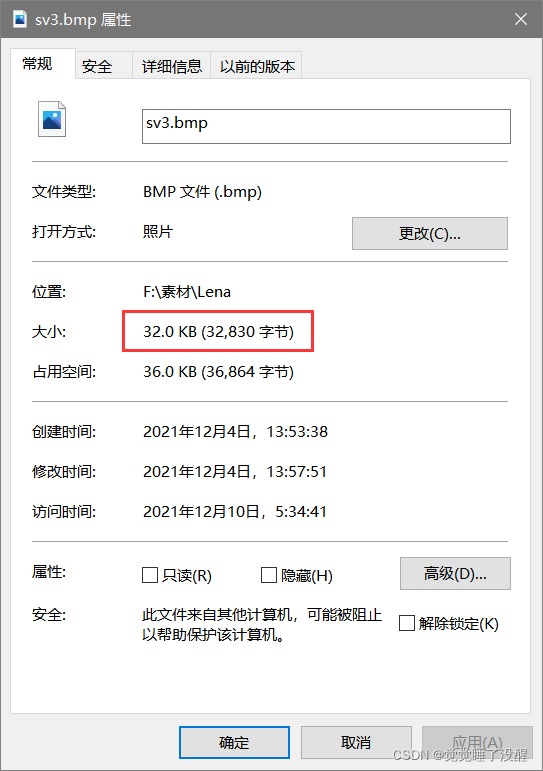
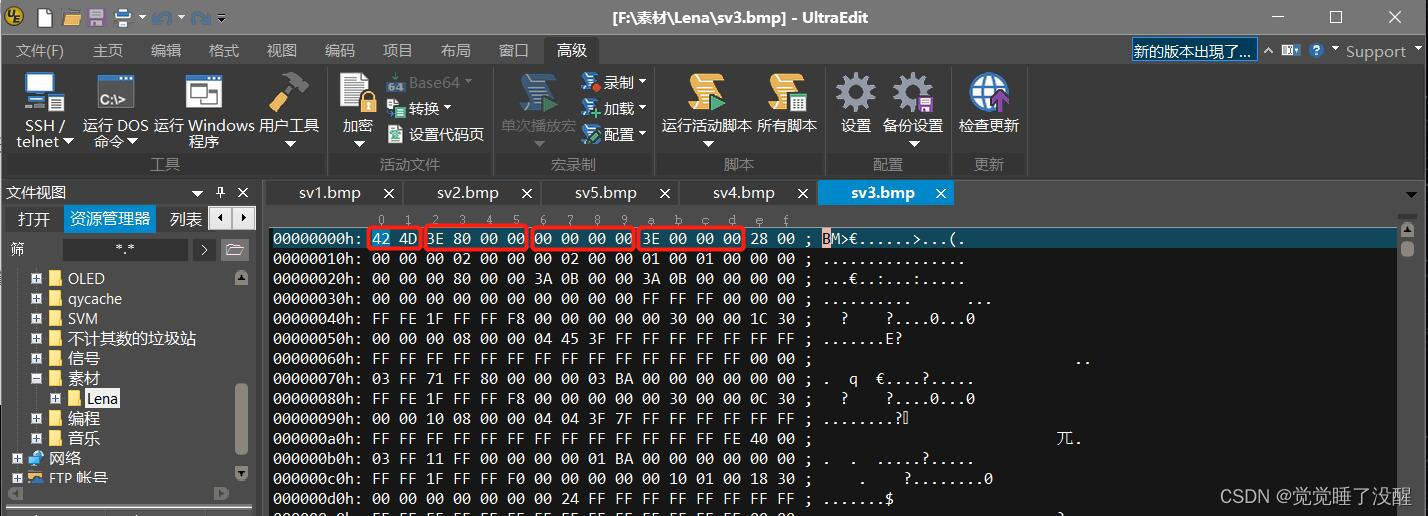
- 用UltraEdit打开一张BMP的图片(以16位彩色为例),可以看到这个文件的数据如下图所示:
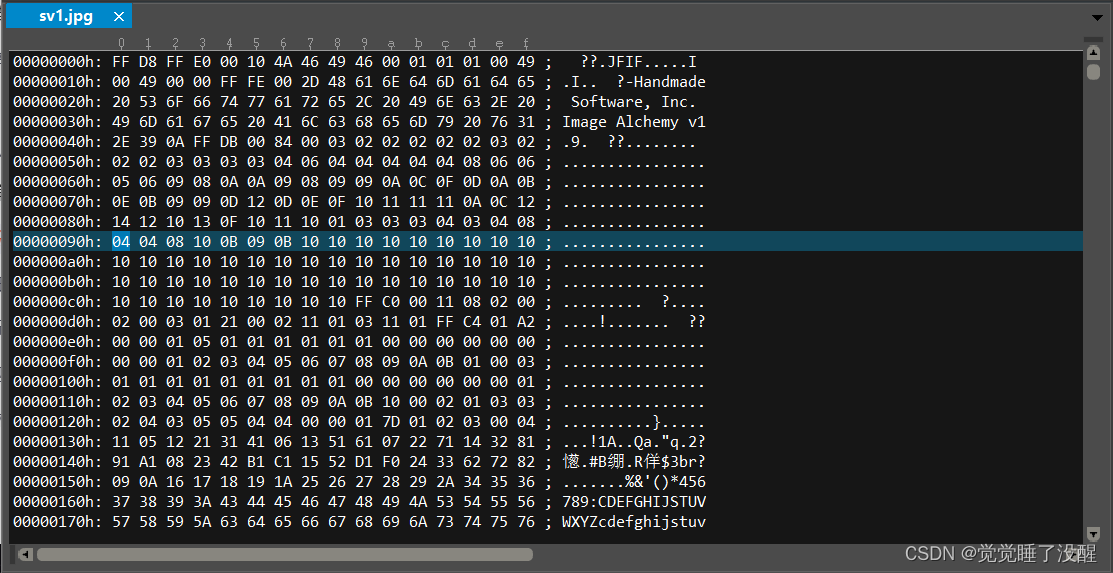
- 位图文件头分为4部分,一共14个字节:
| 名称 | 占用空间 | 内容 | 实际数据 |
|---|---|---|---|
| bfType | 2字节 | 标识,就是“BM”两字母 | BM |
| bfSize | 4字节 | 整个BMP文件的大小 | 0x00080038(524,344)【与右键查看图片属性里面的大小值一样】 |
| bfReserved1/2 | 4字节 | 保留字 | 0 |
| bfOffBits | 4字节 | 偏移数,即位图头文件+位图信息头+调色板的大小 | 0x36(54) |
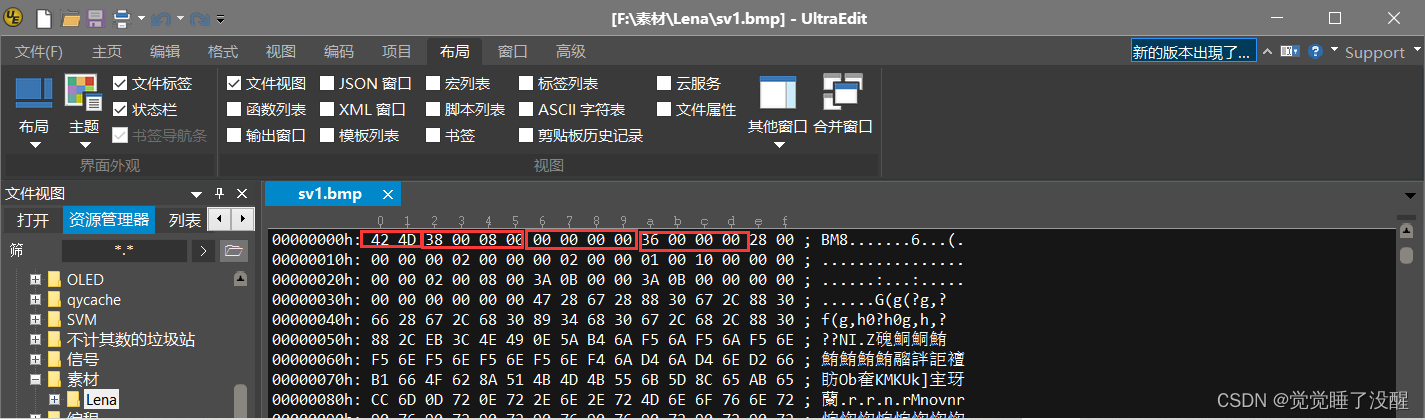
注意,Windows的数据是倒着念的,这是PC电脑的特色。如果一段数据为50 1A 25 3C,倒着念就是3C 25 1A50,即0x3C251A50。因此,如果bfSize的数据为38 00 08 00,实际上就成了0x00080038,也就是0x80038。
- 位图信息头共11部分,占40字节:
| 名称 | 占用空间 | 内容 | 实际数据 |
|---|---|---|---|
| biSize | 4字节 | 位图信息头的大小,为40 | 0x28(40) |
| biWidth | 4字节 | 位图的宽度,单位是像素 | 0x200(512) |
| biHeight | 4字节 | 位图的高度,单位是像素 | 0x200(512) |
| biPlanes | 2字节 | 固定值1 | 1 |
| biBitCount | 2字节 | 每个像素的位数1-黑白图,4-16色,8-256色,24-真彩色) | 0x10(16) |
| biCompression | 4字节 | 压缩方式,BI_RGB(0)为不压缩 | 0 |
| biSizeImage | 4字节 | 位图全部像素占用的字节数,BI_RGB时可设为0 | 0x080002(524290) |
| biXPelsPerMeter | 4字节 | 水平分辨率(像素/米) | 0x0B39(2873) |
| biYPelsPerMeter | 4字节 | 垂直分辨率(像素/米) | 0x0B39(2873) |
| biClrUsed | 4字节 | 位图使用的颜色数 如果为0,则颜色数为2的biBitCount次方 | 0 |
| biClrImportant | 4字节 | 重要的颜色数,0代表所有颜色都重要 | 0 |
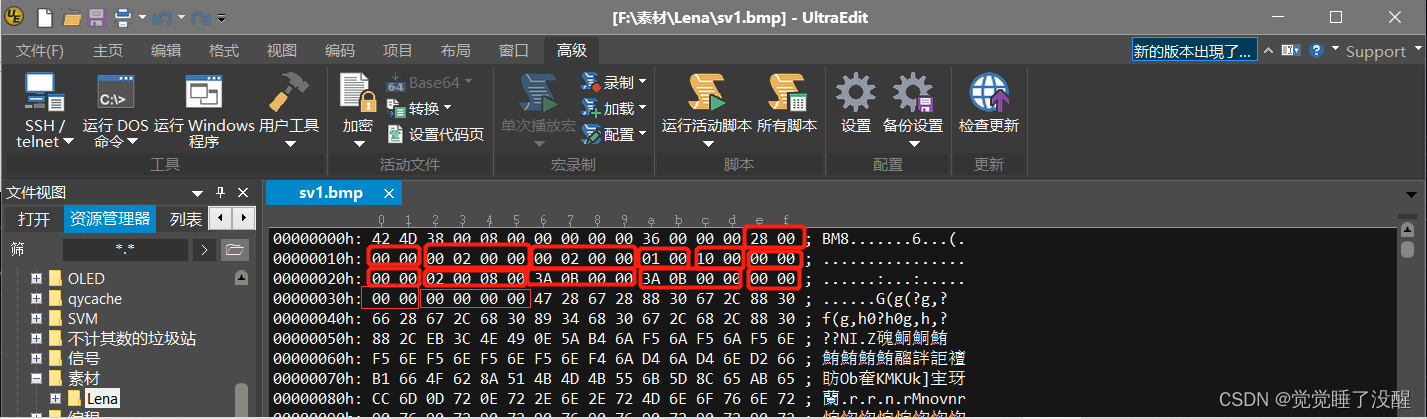
作为真彩色位图,主要关心的是biWidth和biHeight这两个数值就够了,两个数值告诉我们图像的尺寸。biSize,biPlanes,biBitCount这几个数值是固定的。
- 调色板
位图是16位、24位和32位色,则图像文件中不保留调色板,即不存在调色板,图像的颜色直接在位图数据中给出。 16位图像使用2字节保存颜色值,常见有两种格式:5位红5位绿5位蓝和5位红6位绿5位蓝,即555格式和565格式。
1,4,8位图像才会使用调色板数据,16,24,32位图像不需要调色板数据,即调色板最多只需要256项(索引0 - 255)。
颜色表的大小根据所使用的颜色模式而定:2色图像为8字节;16色图像位64字节;256色图像为1024字节。其中,每4字节表示一种颜色,并以B(蓝色)、G(绿色)、R(红色)、alpha(32位位图的透明度值,一般不需要)。即首先4字节表示颜色号1的颜色,接下来表示颜色号2的颜色,依此类推。 - 颜色点阵数据
颜色表接下来位为位图文件的图像数据区,在此部分记录着每点像素对应的颜色号,其记录方式也随颜色模式而定,既2色图像每点占1位(8位为1字节);16色图像每点占4位(半字节);256色图像每点占8位(1字节);真彩色图像每点占24位(3字节)。所以,整个数据区的大小也会随之变化。究其规律而言,可的出如下计算公式:图像数据信息大小=(图像宽度图像高度记录像素的位数)/8。
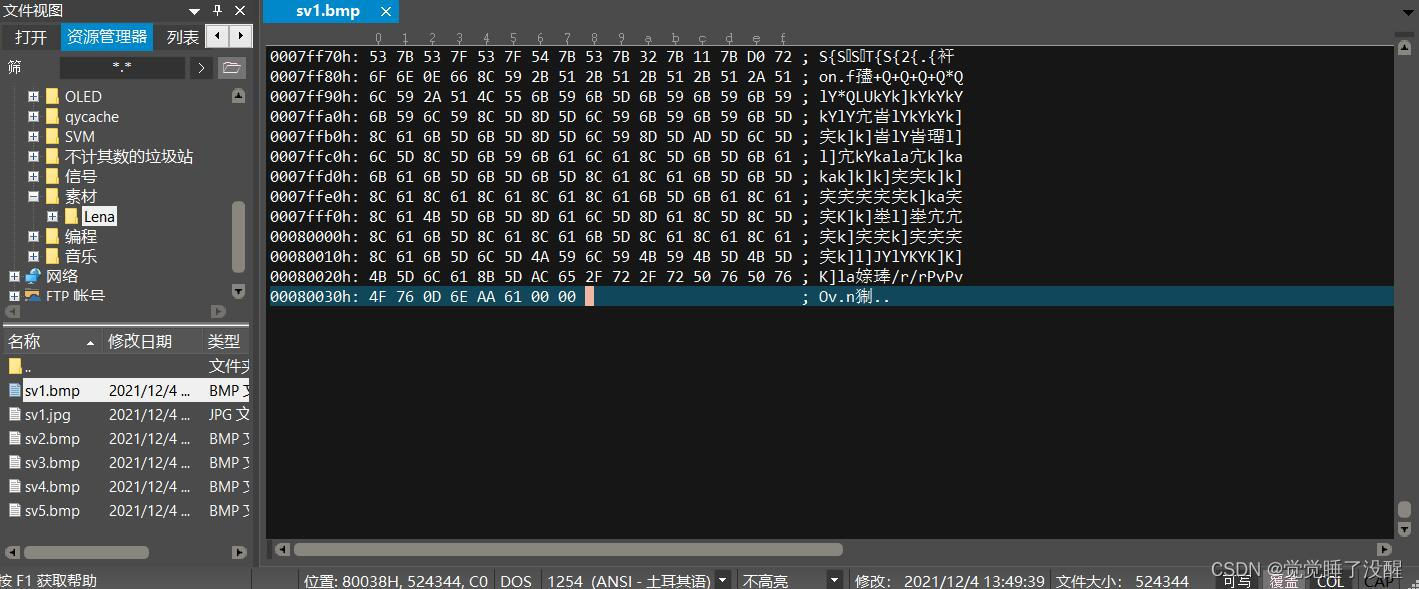
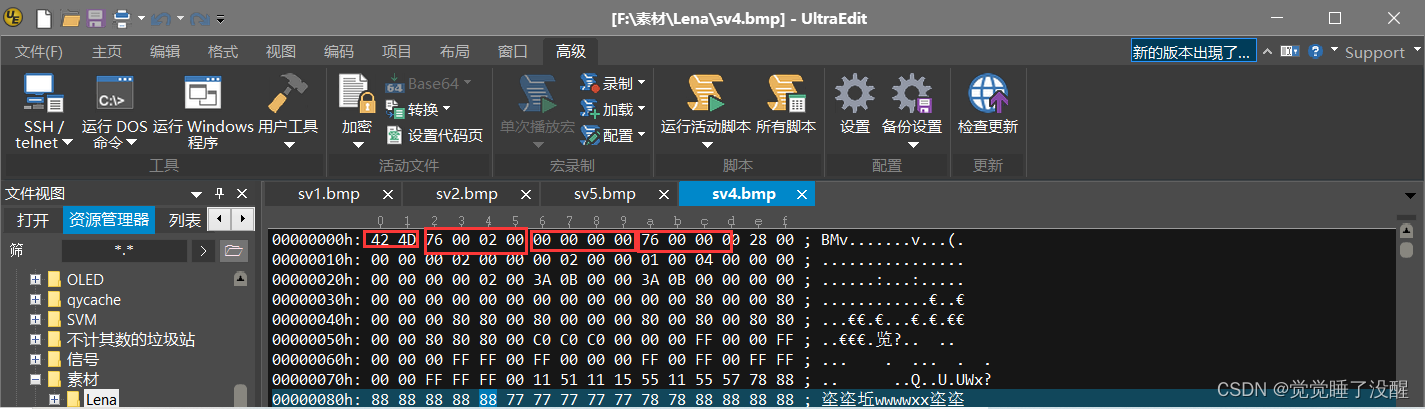
该16位位图大小计算方法:位图文件头(14字节00000000h开始到0000000Dh)+位图信息头(40字节0000000Eh开始到00000035h)+实际像素点占内存(512×512×2字节)=524342字节(Byte)。与真实值相差2个字节,将UltraEdit文件翻到末尾,可以看到有两个为0字节,前面的都是位图图像数据,所以该文件的大小应该在刚才算出来的基础上+2=524344字节,与真实值一致。
- 其余图片信息:
32位彩色:
可以看到除了 文件头除了bfSize都是相同的:bfSize=0x100038=1048432正好是该图的大小。
256色的位图:
16色:
单色:
- 将彩色照片分别保存为BMP、JPG、GIF和PNG格式,对比它们的文件大小比,判断图像的压缩保存后的压缩比率
使用PS随便画了一张图,分别保存为BMP(24位)

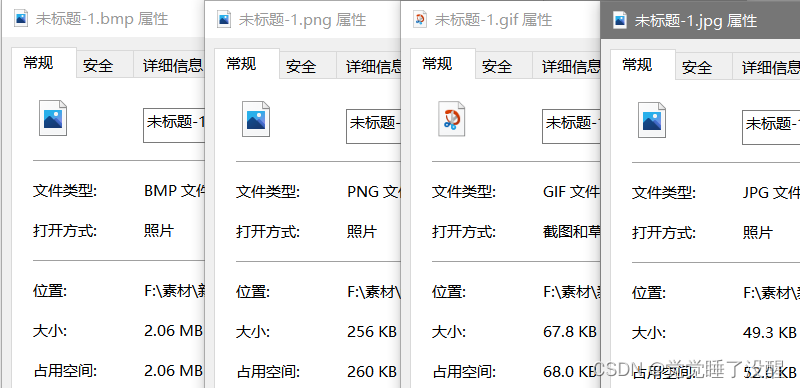
文件大小:
BMP:2.06M
JPG:49.3k
GIF:67.8k
PNG:256k
图像的压缩保存后的压缩比率(由于BMP是不压缩的,所以以它为基准):
JPG:97.6%
GIF:96.7%
PNG:87.5%
二、用奇异值分解对一张图片进行降维处理
代码:
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib as mpl
from pprint import pprint
def restore1(sigma, u, v, K): # 奇异值、左特征向量、右特征向量
m = len(u)
n = len(v[0])
a = np.zeros((m, n))
for k in range(K):
uk = u[:, k].reshape(m, 1)
vk = v[k].reshape(1, n)
a += sigma[k] * np.dot(uk, vk)
a[a < 0] = 0
a[a > 255] = 255
# a = a.clip(0, 255)
return np.rint(a).astype('uint8')
def restore2(sigma, u, v, K): # 奇异值、左特征向量、右特征向量
m = len(u)
n = len(v[0])
a = np.zeros((m, n))
for k in range(K+1):
for i in range(m):
a[i] += sigma[k] * u[i][k] * v[k]
a[a < 0] = 0
a[a > 255] = 255
return np.rint(a).astype('uint8')
if __name__ == "__main__":
A = Image.open("lena.jpg", 'r')
print(A)
output_path = r'F:/jupyter/SVD_Output'
if not os.path.exists(output_path):
os.mkdir(output_path)
a = np.array(A)
print(a.shape)
K = 50
u_r, sigma_r, v_r = np.linalg.svd(a[:, :, 0])
u_g, sigma_g, v_g = np.linalg.svd(a[:, :, 1])
u_b, sigma_b, v_b = np.linalg.svd(a[:, :, 2])
plt.figure(figsize=(11, 9), facecolor='w')
mpl.rcParams['font.sans-serif'] = ['simHei']
mpl.rcParams['axes.unicode_minus'] = False
for k in range(1, K+1):
print(k)
R = restore1(sigma_r, u_r, v_r, k)
G = restore1(sigma_g, u_g, v_g, k)
B = restore1(sigma_b, u_b, v_b, k)
I = np.stack((R, G, B), axis=2)
Image.fromarray(I).save('%s\\svd_%d.png' % (output_path, k))
if k <= 12:
plt.subplot(3, 4, k)
plt.imshow(I)
plt.axis('off')
plt.title('奇异值个数:%d' % k)
plt.suptitle('SVD与图像分解', fontsize=20)
plt.tight_layout()
# plt.subplots_adjust(top=0.9)
plt.show()
随着奇异值的减少图片变得模糊

三、采用图像的开闭运算检测出2个样本图像中硬币、细胞的个数
- 样本一:硬币
import cv2
import numpy as np
def stackImages(scale, imgArray):
"""
将多张图像压入同一个窗口显示
:param scale:float类型,输出图像显示百分比,控制缩放比例,0.5=图像分辨率缩小一半
:param imgArray:元组嵌套列表,需要排列的图像矩阵
:return:输出图像
"""
rows = len(imgArray)
cols = len(imgArray[0])
rowsAvailable = isinstance(imgArray[0], list)
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
if rowsAvailable:
for x in range(0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape[:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]),
None, scale, scale)
if len(imgArray[x][y].shape) == 2: imgArray[x][y] = cv2.cvtColor(imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank] * rows
hor_con = [imageBlank] * rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None, scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor = np.hstack(imgArray)
ver = hor
return ver
#读取图片
src = cv2.imread("coin.png")
img = src.copy()
#灰度
img_1 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#二值化
ret, img_2 = cv2.threshold(img_1, 127, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
#腐蚀(腐蚀主要为了把每个硬币区分开。过大会造成缺失,过低会无法区分开。参数可以自己设置以达到合适。)
kernel = np.ones((17, 17), int)
img_3 = cv2.erode(img_2, kernel, iterations=1)
#膨胀(膨胀到合适的值,这样每一个白色区域就是一个硬币。)
kernel = np.ones((3, 3), int)
img_4 = cv2.dilate(img_3, kernel, iterations=1)
#找到硬币中心
contours, hierarchy = cv2.findContours(img_4, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)[-2:]
#标识硬币
cv2.drawContours(img, contours, -1, (0, 0, 255), 5)
#显示图片
cv2.putText(img, "count:{}".format(len(contours)), (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(src, "src", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_1, "gray", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_2, "thresh", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_3, "erode", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_4, "dilate", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
imgStack = stackImages(1, ([src, img_1, img_2], [img_3, img_4, img]))
cv2.imshow("imgStack", imgStack)
cv2.waitKey(0)
结果:

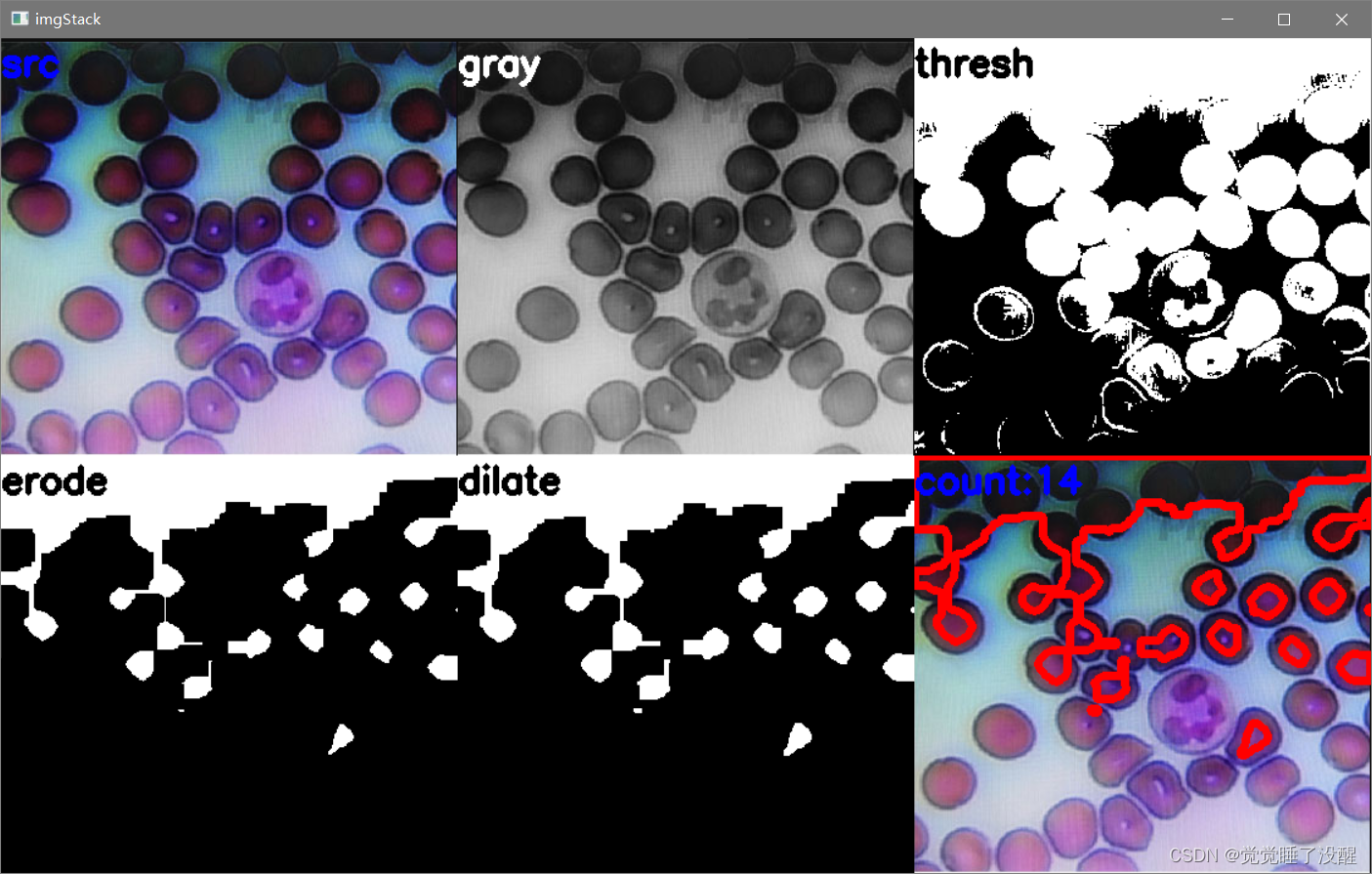
样本二:细胞
import cv2
import numpy as np
def stackImages(scale, imgArray):
"""
将多张图像压入同一个窗口显示
:param scale:float类型,输出图像显示百分比,控制缩放比例,0.5=图像分辨率缩小一半
:param imgArray:元组嵌套列表,需要排列的图像矩阵
:return:输出图像
"""
rows = len(imgArray)
cols = len(imgArray[0])
rowsAvailable = isinstance(imgArray[0], list)
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
if rowsAvailable:
for x in range(0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape[:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]),
None, scale, scale)
if len(imgArray[x][y].shape) == 2: imgArray[x][y] = cv2.cvtColor(imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank] * rows
hor_con = [imageBlank] * rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None, scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor = np.hstack(imgArray)
ver = hor
return ver
#读取图片
src = cv2.imread("cell.png")
img = src.copy()
#灰度
img_1 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#二值化
ret, img_2 = cv2.threshold(img_1, 127, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
#腐蚀
kernel = np.ones((20, 20), int)
img_3 = cv2.erode(img_2, kernel, iterations=1)
#膨胀
kernel = np.ones((3, 3), int)
img_4 = cv2.dilate(img_3, kernel, iterations=1)
#找到硬币中心
contours, hierarchy = cv2.findContours(img_4, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)[-2:]
#标识硬币
cv2.drawContours(img, contours, -1, (0, 0, 255), 5)
#显示图片
cv2.putText(img, "count:{}".format(len(contours)), (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(src, "src", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_1, "gray", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_2, "thresh", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 0), 3)
cv2.putText(img_3, "erode", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 0), 3)
cv2.putText(img_4, "dilate", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 0), 3)
imgStack = stackImages(1, ([src, img_1, img_2], [img_3, img_4, img]))
cv2.imshow("imgStack", imgStack)
cv2.waitKey(0)
结果:
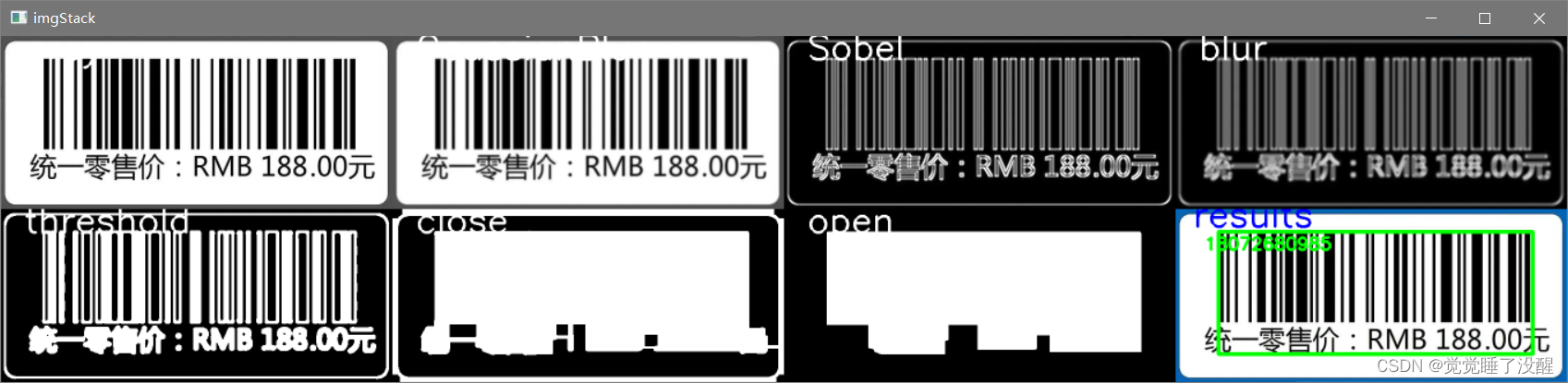
四、采用图像梯度、开闭、轮廓运算对图片中的条形码进行定位提取并调用条码库获得条码字符
代码:
import cv2
import numpy as np
import imutils
from pyzbar import pyzbar
def stackImages(scale, imgArray):
"""
将多张图像压入同一个窗口显示
:param scale:float类型,输出图像显示百分比,控制缩放比例,0.5=图像分辨率缩小一半
:param imgArray:元组嵌套列表,需要排列的图像矩阵
:return:输出图像
"""
rows = len(imgArray)
cols = len(imgArray[0])
rowsAvailable = isinstance(imgArray[0], list)
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
if rowsAvailable:
for x in range(0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape[:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]),
None, scale, scale)
if len(imgArray[x][y].shape) == 2: imgArray[x][y] = cv2.cvtColor(imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank] * rows
hor_con = [imageBlank] * rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None, scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor = np.hstack(imgArray)
ver = hor
return ver
#读取图片
src = cv2.imread("price.png")
img = src.copy()
#灰度
img_1 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#高斯滤波
img_2 = cv2.GaussianBlur(img_1, (5, 5), 1)
#Sobel算子
sobel_x = cv2.Sobel(img_2, cv2.CV_64F, 1, 0, ksize=3)
sobel_y = cv2.Sobel(img_2, cv2.CV_64F, 0, 1, ksize=3)
sobel_x = cv2.convertScaleAbs(sobel_x)
sobel_y = cv2.convertScaleAbs(sobel_y)
img_3 = cv2.addWeighted(sobel_x, 0.5, sobel_y, 0.5, 0)
#均值方波
img_4 = cv2.blur(img_3, (5, 5))
#二值化
ret, img_5 = cv2.threshold(img_4, 127, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
#闭运算
kernel = np.ones((18, 18), int)
img_6 = cv2.morphologyEx(img_5, cv2.MORPH_CLOSE, kernel)
#开运算
kernel = np.ones((100,100), int)
img_7 = cv2.morphologyEx(img_6, cv2.MORPH_OPEN, kernel)
#绘制条形码区域
contours = cv2.findContours(img_7, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
c = sorted(contours, key = cv2.contourArea, reverse = True)[0]
rect = cv2.minAreaRect(c)
box = cv2.cv.BoxPoints(rect) if imutils.is_cv2() else cv2.boxPoints(rect)
box = np.int0(box)
cv2.drawContours(img, [box], -1, (0,255,0), 6)
#显示图片信息
cv2.putText(img, "results", (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_1, "gray", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_2, "GaussianBlur",(40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_3, "Sobel", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_4, "blur", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_5, "threshold", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_6, "close", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
cv2.putText(img_7, "open", (40, 40), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (255, 0, 0), 3)
#输出条形码
barcodes = pyzbar.decode(src)
for barcode in barcodes:
barcodeData = barcode.data.decode("utf-8")
cv2.putText(img, barcodeData, (50, 70), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 3)
#显示所有图片
imgStack = stackImages(0.5, ([img_1, img_2,img_3,img_4],[img_5,img_6,img_7,img]))
cv2.imshow("imgStack", imgStack)
cv2.waitKey(0)
结果:
五、总结
可以看到这个算法对于数细胞不太准确,数硬币还行。
六、参考链接
数字图像与机器视觉基础1
识别硬币和细胞数量+条形码检测(python+opencv)
数字图像与机器视觉基础补充(1)
Python制作二维码和条形码扫描器 (pyzbar)
ModuleNotFoundError: No module named 'imutils’解决方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









