




Improving Adversarial Transferability on Vision Transformers via Forward Propagation Refinement

本文 “Improving Adversarial Transferability on Vision Transformers via Forward Propagation Refinement” 提出通过前向传播优化(FPR)提升视觉 Transformer(ViTs)对抗样本迁移性的方法。FPR 由注意力图多样化(AMD)和动量 Token 嵌入(MTE)组成,AMD 通过随机加权多样化注意力图,隐式诱导梯度消失减轻过拟合,MTE 通过积累历史 Token 嵌入稳定更新。实验表明,FPR 在不同模型和防御机制下,平均攻击成功率比当前最佳的反向代理优化方法高7.0%,且与其他迁移方法兼容性强。
摘要-Abstract
Vision Transformers (ViTs) have been widely applied in various computer vision and vision-language tasks. To gain insights into their robustness in practical scenarios, transferable adversarial examples on ViTs have been extensively studied. A typical approach to improving adversarial transferability is by refining the surrogate model. However, existing work on ViTs has restricted their surrogate refinement to backward propagation. In this work, we instead focus on Forward Propagation Refinement (FPR) and specifically refine two key modules of ViTs: attention maps and token embeddings. For attention maps, we propose Attention Map Diversification (AMD), which diversifies certain attention maps and also implicitly imposes beneficial gradient vanishing during backward propagation. For token embeddings, we propose Momentum Token Embedding (MTE), which accumulates historical token embeddings to stabilize the forward updates in both the Attention and MLP blocks. We conduct extensive experiments with adversarial examples transferred from ViTs to various CNNs and ViTs, demonstrating that our FPR outperforms the current best (backward) surrogate refinement by up to 7.0% on average. We also validate its superiority against popular defenses and its compatibility with other transfer methods.
视觉Transformer(ViTs)已广泛应用于各种计算机视觉和视觉语言任务。为了深入了解其在实际场景中的稳健性,针对ViTs的可迁移对抗样本已得到广泛研究。提高对抗样本迁移性的一种典型方法是对代理模型进行优化。然而,现有的关于ViTs的研究将代理模型的优化局限于反向传播。在本研究中,我们聚焦于前向传播优化(FPR),并具体对ViTs的两个关键模块进行优化:注意力图和token嵌入。对于注意力图,我们提出了注意力图多样化(AMD)方法,该方法使特定的注意力图多样化,并且在反向传播过程中还能隐式地实现有益的梯度消失。对于token嵌入,我们提出了动量Token嵌入(MTE)方法,通过积累历史token嵌入来稳定注意力模块和多层感知器(MLP)模块中的前向更新。我们进行了大量实验,将从ViTs生成的对抗样本迁移到各种卷积神经网络(CNNs)和ViTs上,结果表明,我们的FPR平均比目前最优的(基于反向传播的)代理模型优化方法性能高出7.0%. 我们还验证了它在对抗流行防御方法时的优越性,以及与其他迁移方法的兼容性。
引言-Introduction
该部分主要介绍了研究背景、问题、方法及贡献,具体内容如下:
- 研究背景:深度神经网络(DNNs)在多领域表现出色,视觉Transformer(ViTs)在计算机视觉领域尤为突出。但ViTs易受对抗样本攻击,对抗样本是在干净图像中添加细微扰动得到的,其可迁移性引发了实际安全担忧。
- 问题提出:提升对抗样本可迁移性的方法中,代理模型优化是重要途径。现有针对ViTs的代理模型优化方法局限于反向传播,仅修改梯度信息,忽略了正向传播的潜在影响,限制了对抗样本可迁移性的进一步提升。
- 研究方法:本文提出前向传播优化(FPR),从正向传播角度优化ViT代理模型。具体通过修改注意力图和输出token嵌入这两个关键组件来实现。
- 注意力图多样化(AMD):发现ViTs中部分注意力图存在冗余,会降低对抗样本可迁移性。AMD通过随机加权适度多样化注意力图,模拟未知模型,减轻对代理模型的过拟合。且AMD能在反向传播时隐式诱导注意力图部分梯度消失,进一步缓解过拟合。
- 动量Token嵌入(MTE):生成对抗样本时易陷入局部最优,导致代理模型的token嵌入包含错误信息,降低可迁移性。MTE受动量蒸馏技术启发,在生成对抗样本时积累历史token嵌入信息,稳定token嵌入的更新。
- 主要贡献:
- 从正向传播视角探索ViT代理模型的优化,修改注意力图和输出token嵌入。
- 提出AMD,适度避免注意力冗余,诱导有益的梯度消失,减轻对代理模型的过拟合。
- 提出MTE,通过积累历史信息稳定token嵌入更新,提升对抗样本生成效果。
- 大量实验验证,包含AMD和MTE的FPR在对抗13个ViTs和CNNs时,平均性能比当前最佳的反向优化方法高出7.0%.
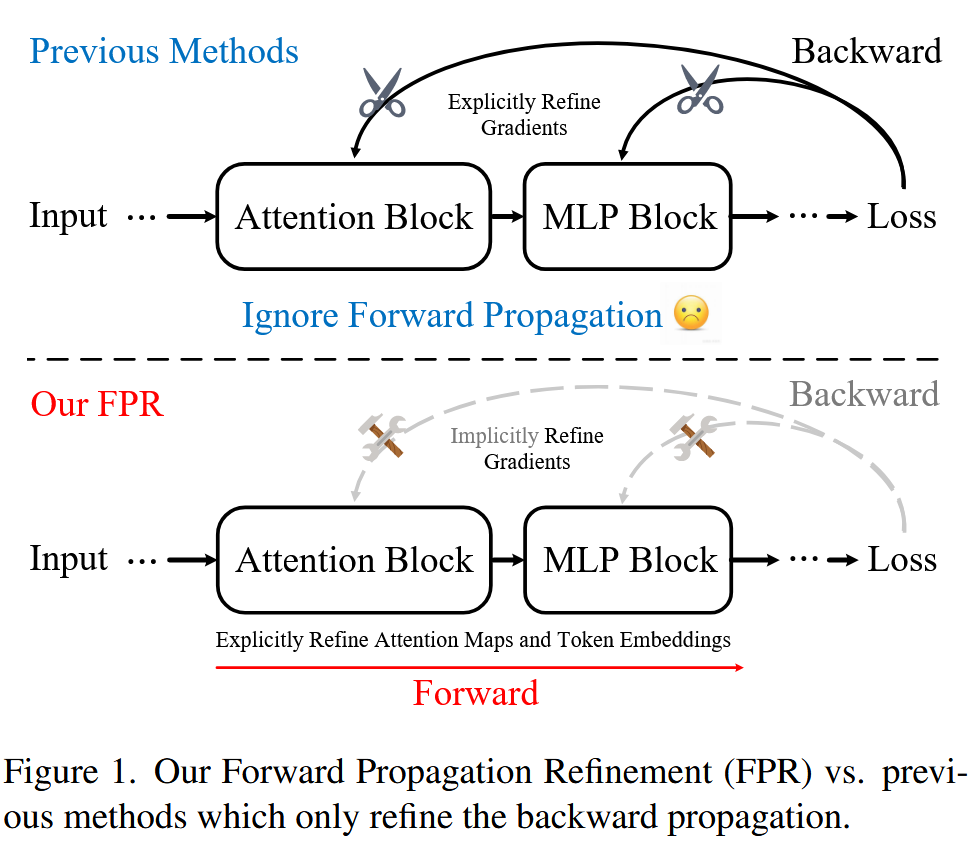
图1. 我们的前向传播优化(FPR)方法与仅优化反向传播的先前方法对比。
相关工作-Related Work
该部分主要介绍了与研究相关的三类工作,分别是代理优化攻击、其他基于迁移的攻击以及视觉Transformer,具体内容如下:
- 代理优化攻击:该部分详细介绍了属于代理优化的攻击方法。
- 基于CNN的方法:Skip Gradient Method(SGM)通过衰减穿越残差模块的梯度来减轻对代理模型的过拟合;Ghost Networks在代理模型的每个块中使用随机失活(dropout)并扰动跳跃连接以创建纵向集成;Backward Propagation Attack(BPA)针对ReLU和最大池化层梯度携带不准确信息的问题,采用非单调函数和带温度的softmax来恢复真实梯度以增强迁移性;Diversifying the High-level Features(DHF)通过随机变换修改高级特征;Clean Feature Mixup(CFM)在特征级别引入竞争以增强对抗样本的迁移性;还有方法通过重新训练代理模型来加强迁移性,但会显著增加攻击成本。
- 针对ViTs的方法:Pay No Attention and Patch Out(PNAPO)通过切断所有注意力图的梯度、随机更新特定数量的输入图块以及在交叉熵损失函数中添加额外项来增加对抗噪声范数,协同减轻对代理模型的过拟合;Token Gradient Regularization(TGR)去除QKV嵌入、注意力图和MLP块的极端梯度以减少梯度方差,缓解过拟合;Gradient Normalization Scaling(GNS)通过准确归一化和缩放温和梯度改进TGR,产生更强的迁移性。但上述方法都忽视了正向传播的更广泛影响。
- 其他基于迁移的攻击:回顾了不需要修改代理模型的基于迁移的攻击方法。如Fast Gradient Sign Method(FGSM)沿梯度符号方向一步创建对抗样本;Basic Iterative Method(BIM)通过多次迭代扩展FGSM;Momentum Iterative Method(MIM)引入动量项以实现更好的收敛;Nesterov Fast Gradient Sign Method(NIM)在每次迭代开始时多走一步并采用更远位置的样本计算梯度进行更新;Variance Tuning Method(VTM)在最后一次迭代中用方差修改当前梯度;Gradient Relevance Attack(GRA)利用从附近样本提取的相关信息稳定当前更新方向;Diversity Input Method(DIM)对输入进行填充和调整大小变换以减少过拟合;Scale Invariance Method(SIM)使用一组缩放副本增强输入;Structure Invariant Attack(SIA)对输入的每个块采用不同变换以提升转移性;Block Shuffle and Rotation(BSR)将输入图像划分为多个块,随机打乱和旋转以创建新图像集用于梯度计算 。
- 视觉Transformer:介绍了Transformer在自然语言处理和计算机视觉领域的应用。ViT将图像划分为图块并嵌入为token,采用多头自注意力机制捕获空间关系。此外,还列举了DeiT通过教师 - 学生蒸馏改进ViT;Swin采用分层结构和移位窗口有效处理多尺度注意力;PiT利用池化层简化计算过程和管理数据流;CaiT结合LayerScale稳定训练并使用类注意力层增强分类信息提取;Visformer结合卷积层和ViT有效整合空间特征和注意力机制;CoaT在分层架构中融合卷积和自注意力以平衡特征提取和交互。
方法-Methodology
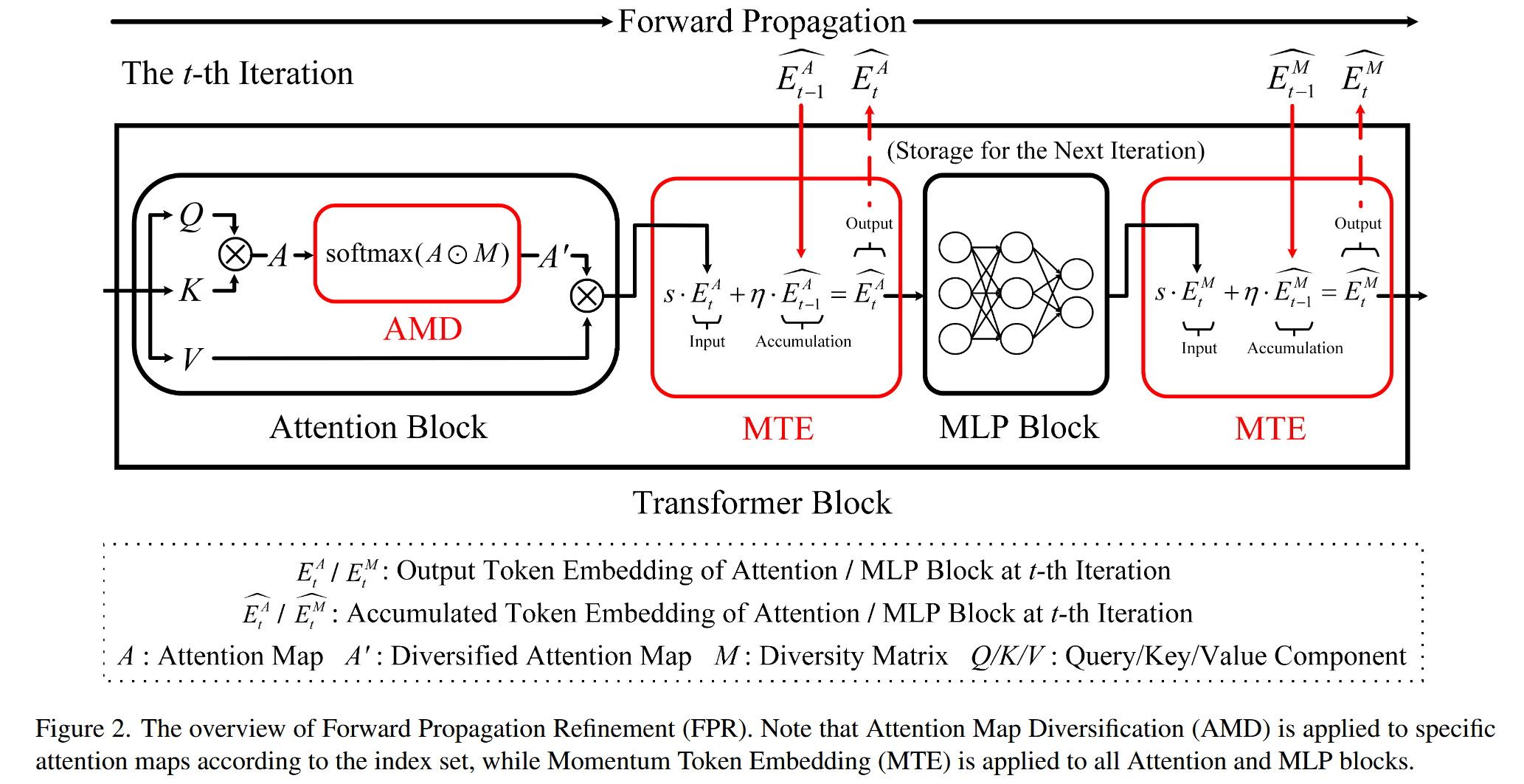
图2. 前向传播优化(FPR)概述。请注意,注意力图多样化(AMD)根据索引集应用于特定的注意力图,而动量Token嵌入(MTE)应用于所有注意力块和多层感知器(MLP)块。
预备知识-Preliminary
该部分主要介绍了基于迁移的攻击目标、图像在ViTs中的处理过程以及相关公式,为后续理解FPR方法奠定基础,具体内容如下:
- 基于迁移的攻击目标:假设存在图像 x x x(具有通道 c c c、高度 H H H、宽度 W W W)、真实标签 y y y 和代理模型 F F F,基于迁移的攻击目的是向输入 x x x 添加对抗扰动 δ \delta δ,生成对抗样本 x a = x + δ x^{a}=x+\delta xa=x+δ,并将其输入目标模型 F t F^{t} Ft 以诱导错误预测。该过程可表示为求解 δ ′ = a r g m a x δ L ( F ( x + δ ) , y ) , s . t . ∥ δ ∥ ∞ ≤ ϵ \delta'=\underset{\delta}{arg max } L(F(x+\delta), y), s.t. \| \delta\| _{\infty} \leq \epsilon δ′=δargmaxL(F(x+δ),y),s.t.∥δ∥∞≤ϵ,其中 L L L 是损失函数, ϵ \epsilon ϵ 是最大扰动界限。
- 图像在ViTs中的处理过程:在图像 x x x 输入ViTs之前,会被分割成 N = H ⋅ W P 2 N=\frac{H \cdot W}{P^{2}} N=P2H⋅W 个图块,每个图块的高度、宽度和通道维度分别为 P P P、 P P P 和 c c c. 这些图块随后被转换为token嵌入,并输入一系列Transformer块。每个Transformer块包含一个注意力(Attention)块和一个多层感知器(MLP)块。
- 注意力块的计算过程:注意力块的输入token嵌入会被转换为查询(Query, Q Q Q)、键(Key, K K K)和值(Value, V V V)组件,它们的形状均为 N × D N ×D N×D( D D D 是嵌入维度)。注意力块利用自注意力机制建立 Q Q Q、 K K K 和 V V V 之间的关系,注意力图 A A A 通过公式 A = s o f t m a x ( Q K T D ) A=softmax\left(\frac{Q K^{T}}{\sqrt{D}}\right) A=softmax(DQKT) 计算得出(softmax函数应用于每一行)。注意力图 A A A 用于对 V V V 进行加权,输出 Z Z Z 的计算公式为 Z = A V Z=A V Z=AV。
- MLP块的作用:MLP块紧跟注意力块,通常包含全连接层、GELU激活函数、随机失活(dropout)层和层归一化层,用于聚合所有令牌嵌入的信息。
注意力图多样化-Attention Map Diversification (AMD)
该部分主要介绍了注意力图多样化(AMD)提出的原因、具体方法,以及其对反向传播的影响,具体内容如下:
- 提出原因:以往研究表明ViTs注意力块存在冗余,丢弃少量注意力块不会显著降低分类准确率,且可能在生成对抗样本时导致对代理模型的过拟合。通过实验发现,随机丢弃少量注意力块能提高对抗样本的可迁移性,但丢弃过多会产生负面影响。直接应用注意力块随机失活(dropout)来避免冗余,虽有一定效果,但过于激进,会造成严重信息损失,对可迁移性提升有限。
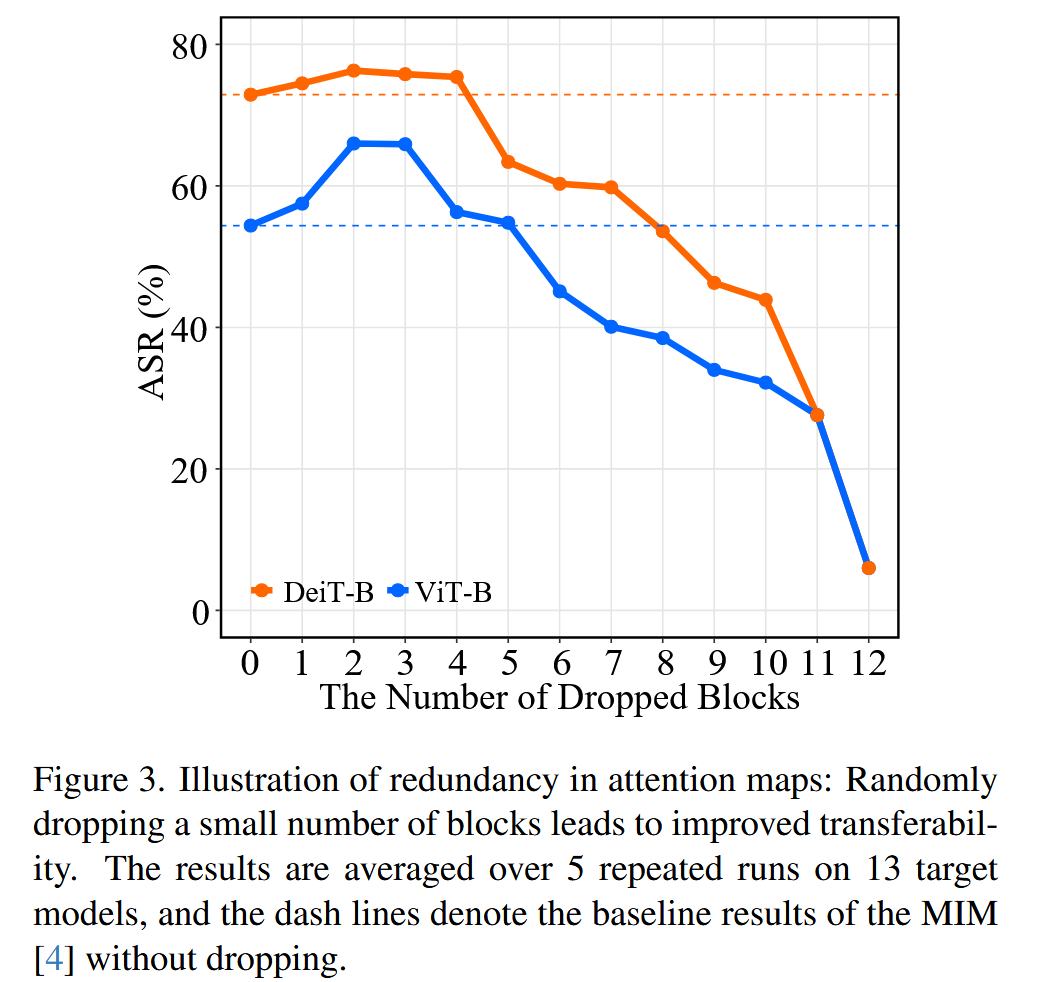
图3. 注意力图冗余的示例:随机丢弃少量模块会提高迁移性。结果是在13个目标模型上进行5次重复实验的平均值,虚线表示未进行丢弃操作的动量迭代法(MIM)的基线结果。 - 具体方法:提出注意力图多样化(AMD)方法,通过将原始注意力图 A A A 与多样性矩阵 M M M 相乘来变换注意力图。具体公式为 A ′ = s o f t m a x ( A ⊙ M ) A' = softmax(A \odot M) A′=softmax(A⊙M),其中 ⊙ \odot ⊙ 是逐元素相乘,softmax 函数应用于每一行。多样性矩阵 M M M 与 A A A 形状相同,其元素 M i , j ( 1 ≤ i , j ≤ N ) M_{i, j}(1 ≤i, j ≤N) Mi,j(1≤i,j≤N) 服从均匀分布 U ( 1 − d , 1 + d ) U(1 - d, 1 + d) U(1−d,1+d), d d d 是控制多样性水平的因子。AMD根据索引集 I I I 应用于指定 Transformer 块的注意力图。
- 对反向传播的影响:从理论上证明了AMD对反向传播的影响可以进一步提高对抗样本的可迁移性。当应用AMD时,随着多样性因子 d d d 增大,多样性矩阵 M M M 元素波动显著,使 A ′ A' A′ 元素趋近于0或1 ,根据softmax函数性质,其导数 ∂ A i , m ′ ∂ S i , n \frac{\partial A_{i, m}'}{\partial S_{i, n}} ∂Si,n∂Ai,m′( 1 ≤ m , n ≤ N 1 ≤m, n ≤N 1≤m,n≤N)会趋向于0,导致梯度消失。与直接丢弃注意力图梯度的PNAPO方法相比,AMD的梯度消失是隐式的,且发生在注意力图的行级别,更细粒度,能引入额外随机性,进一步减轻对代理模型的过拟合。
动量Token嵌入-Momentum Token Embedding (MTE)
该部分主要介绍了动量Token嵌入(MTE)方法提出的背景、具体做法及与其他方法的区别,旨在解决生成对抗样本时令牌嵌入信息不准确、收敛易陷入局部最优的问题,从而提升对抗样本的转移性,具体内容如下:
- 提出背景:在高维空间生成对抗样本时,难以确保收敛到全局最优解,通常会沿着不准确的路径收敛到局部最优,这使得代理模型的内部令牌嵌入在迭代过程中包含不准确信息,进而削弱了对抗样本的转移性。
- 具体方法:借鉴视觉与语言预训练(VLP)文献中的动量蒸馏(MoD)思想,提出动量Token嵌入(MTE)方法。在生成对抗样本时,通过积累历史Token嵌入信息来稳定当前的token嵌入更新。具体公式为 E t ^ = M T E ( E t ) = η ⋅ E t − 1 ^ + s ⋅ E t \hat{E_{t}} = MTE\left(E_{t}\right)=\eta \cdot \hat{E_{t - 1}}+s \cdot E_{t} Et^=MTE(Et)=η⋅Et−1^+s⋅Et,其中 t t t 是迭代索引, E t E_{t} Et 是第 t t t 次迭代时任何注意力块或MLP块的输出token嵌入, E t ^ \widehat{E_{t}} Et 是第 t t t 次迭代时相应的累积token嵌入, η \eta η 是衰减因子, s s s 是缩放因子。MTE应用于所有注意力块和MLP块。
- 与其他方法的区别:与MoD不同,MTE不需要模型训练,可看作是在时间维度上为输出token嵌入构建了一个残差结构。以往的工作也发现残差结构有助于提高迁移性,但通常是在每次迭代的反向传播过程中发挥作用,而MTE是在正向传播中通过积累历史信息稳定token嵌入更新来提升迁移性。
AMD和MTE的协同作用-Complementary AMD and MTE
该部分主要阐述了注意力图多样化(AMD)和动量Token嵌入(MTE)协同提升对抗样本迁移性的原因,以及给出了FPR算法的伪代码,具体如下:
- 协同提升迁移性的原因:AMD和MTE从两个互补的角度对ViT的前向传播进行优化。AMD属于“外部优化”,通过引入额外信息或扰动现有嵌入来增强代理模型,例如随机加权多样化注意力图,但这类方法相对激进,不适用于同时应用于所有块。而MTE属于“内部优化”,主要利用输入数据自身的信息,通过积累历史token嵌入来稳定更新,相对温和,可应用于所有块。二者虽然方式不同,但都有助于提升对抗样本的迁移性,这种互补效应进一步增强了对抗样本的转移性。
- FPR算法伪代码:提供了基于动量迭代法(MIM)的FPR算法伪代码(算法1)。在每次迭代中,首先在正向传播时,根据索引集
I
I
I 对特定的注意力图应用AMD,对所有注意力和MLP块的输出应用MTE;然后在反向传播时,计算当前对抗样本的梯度,并使用MIM更新对抗样本。伪代码还列出了算法的输入参数,包括代理模型、损失函数、干净图像及其真实标签、最大扰动界限、迭代次数、衰减因子、步长、索引集、多样性因子、缩放因子和衰减因子等,输出为最终生成的对抗图像。

实验-Experiments
实验设置-Experimental Settings
该部分主要介绍了实验所涉及的数据集、基线方法、模型、防御机制以及超参数设置等内容,为后续实验结果的对比和分析提供了基础,具体如下:
- 数据集和基线:遵循常见做法,从ILSVRC2012验证集中随机选取1000张图像作为实验数据。将FPR与其他专注于反向传播的代理优化方法进行对比,包括PNAPO、TGR和GNS,且这些方法都基于MIM构建。
- 模型和防御:
- 代理模型:选用了四种流行的ViTs,分别是ViT-Base(ViT-B)、CaiT-Small(CaiT-S)、PiT-Tiny(PiT-T)和Deit-Base(Deit-B)。
- 目标模型:涵盖了七种ViTs和六种CNNs,包括ViT-B、CaiT-S、PiT-Base、Visformer-Small、Swin-Tiny、Deit-Tiny、CoaT-Tiny、ResNet-18、VGG-16、DenseNet-121、EfficientNet-b0、MobileNetv3和ResNeXt-50。
- 防御机制:测试了五种流行的防御方法,分别是与RN-50结合的对抗训练(AT)、基于Inc-v3的高水平表示引导去噪器(HGD)、神经表示净化器(NRP)、比特深度减少(BDR)和JPEG压缩。此外,还纳入了百度云API和阿里云API这两个在线模型。
- 超参数设置:一般将迭代次数设为10,最大扰动界限
ϵ
\epsilon
ϵ 设为16,步长
α
\alpha
α 设为1.6,动量梯度衰减因子
μ
\mu
μ 设为1。所有基线方法采用默认参数,对于FPR,其最优超参数设置根据不同模型有所差异,如ViT-B对应的索引集
I
I
I 为0,1,4,9,11,多样性因子
d
d
d 为25,缩放因子
s
s
s 为0.8,衰减因子
η
\eta
η 为0.3等,详细的参数敏感性分析在4.3节进行讨论。所有实验均在配备8GB显存的单块RTX 4060 GPU上进行。
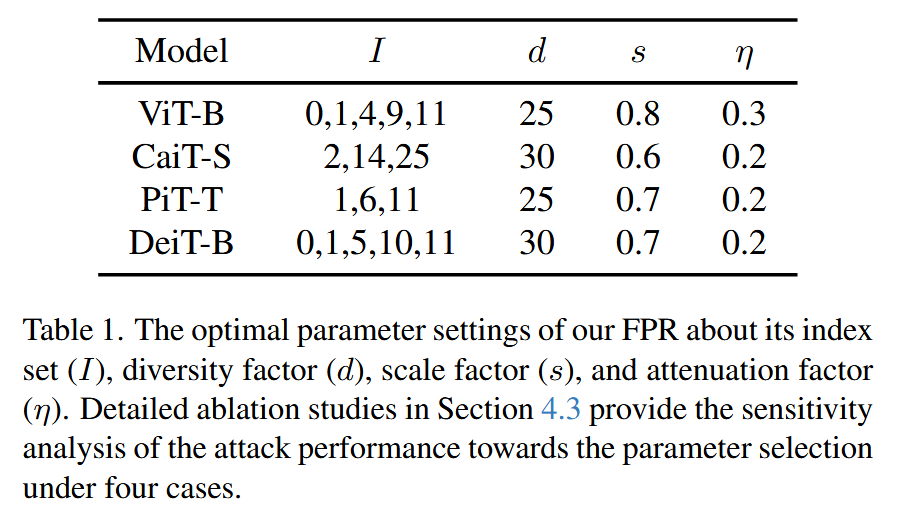
表1. 我们的前向传播优化(FPR)在索引集( I I I)、多样性因子( d d d)、缩放因子( s s s)和衰减因子( η η η)方面的最优参数设置。第4.3节中的详细消融研究针对四种情况下的参数选择提供了对攻击性能的敏感性分析。
实验结果-Experimental Results
该部分通过对比实验,验证了FPR方法在不同目标模型、防御机制下的有效性,以及与其他转移方法结合时的兼容性,具体内容如下:
-
不同目标模型:将FPR与其他基于反向传播的代理精炼方法(PNAPO、TGR、GNS)进行对比,评估从ViTs生成的对抗样本转移到不同ViTs和CNNs的攻击成功率。结果显示,FPR在所有情况下均优于基线方法。以在ViT-B上生成对抗样本攻击6个CNNs为例,FPR的平均攻击成功率达到84.3%,分别比GNS、TGR、PNAPO高出7.0%、7.4%和15.5%,相比基线MIM提升了33.4%,表明从正向传播角度优化代理模型可有效提升对抗样本转移性。
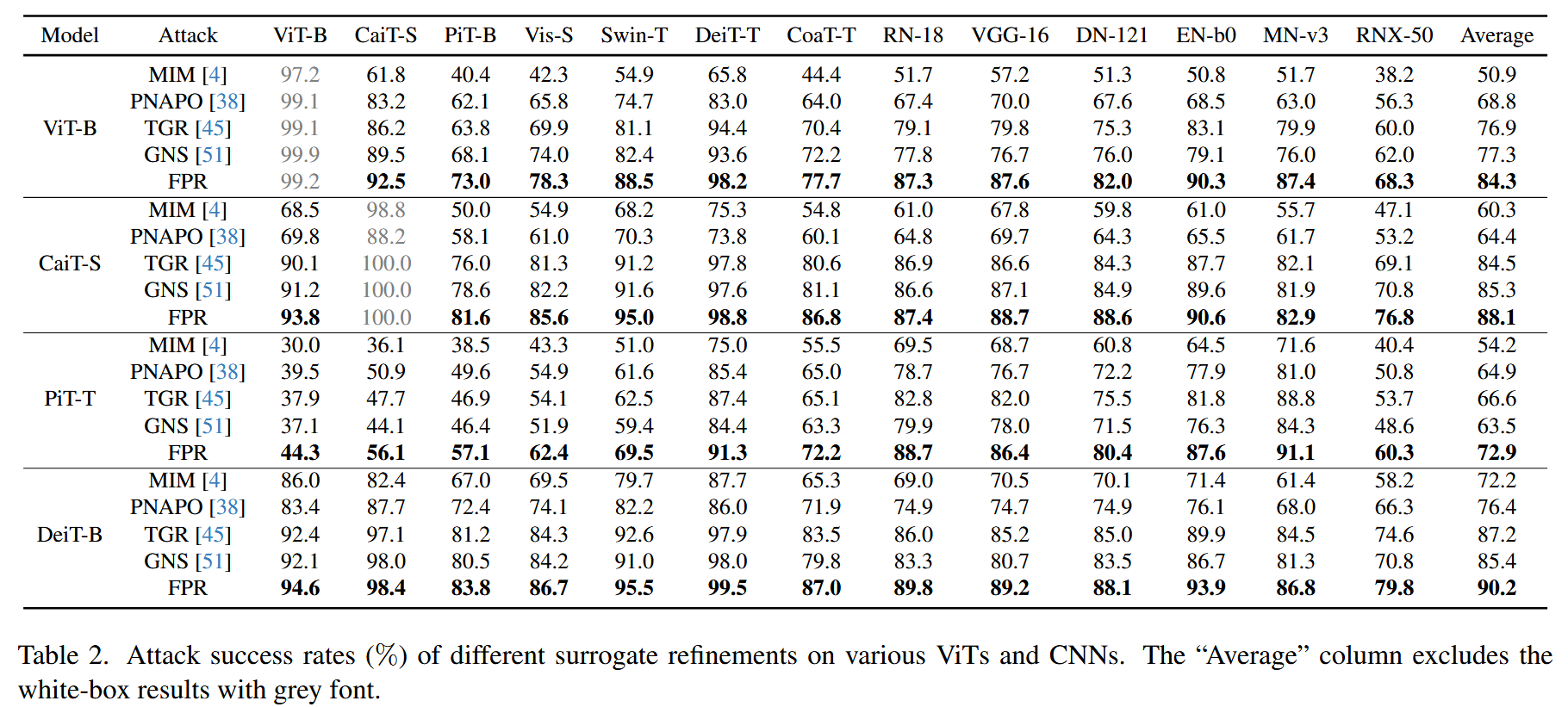
表2. 不同的代理模型精炼方法在各种视觉Transformer(ViTs)和卷积神经网络(CNNs)上的攻击成功率(%)。“平均值”列不包括灰色字体标注的白盒攻击结果。 -
不同防御机制:针对五种流行的防御机制(对抗训练AT、高水平表示引导去噪器HGD、神经表示净化器NRP、比特深度减少BDR、JPEG压缩),评估不同攻击方法的性能。FPR在这些具有挑战性的防御设置下仍保持优势。如在ViT-B上生成对抗样本,FPR在五种防御机制下的平均攻击成功率为70.8% ,分别比GNS、TGR、PNAPO高出5.7%、6.4%和12.4%,比普通基线MIM高出24.3%,证明FPR在对抗多种防御时表现出色。
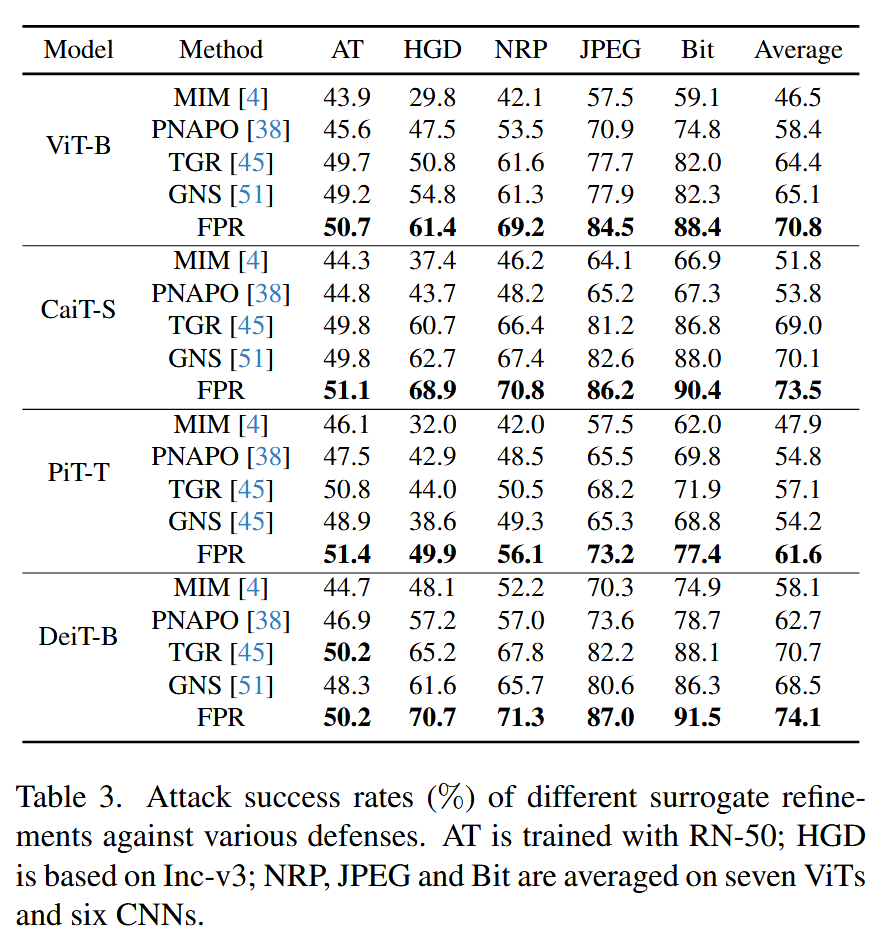
表3. 不同的代理模型精炼方法针对各种防御机制的攻击成功率(%)。对抗训练(AT)是使用RN-50进行训练的;高电平表示引导去噪器(HGD)是基于Inception-v3的;神经表示净化器(NRP)、JPEG压缩和比特深度减少(Bit)是在七种视觉Transformer(ViTs)和六种卷积神经网络(CNNs)上取的平均值。 -
结合其他转移方法:为测试FPR与其他转移方法的兼容性,将其集成到两种基于梯度校正的转移攻击(VTM、GRA)和两种基于输入增强的转移攻击(BSR、SIA)中。实验结果表明,FPR能有效提升这些方法的转移性。例如,VTM结合FPR后,在CNNs上的攻击成功率从57.3%提升至81.7%,说明FPR与其他转移方法结合可进一步增强攻击效果。
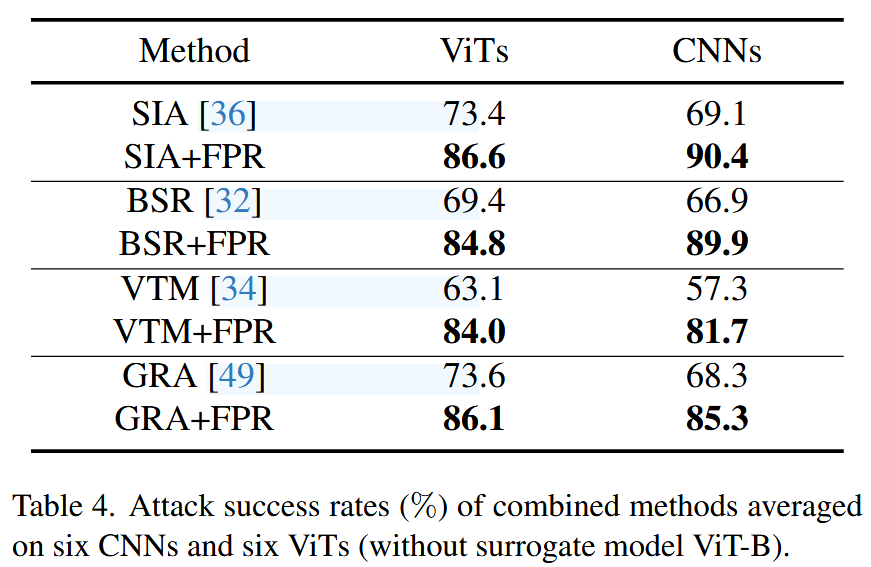
表4. 组合方法的攻击成功率(%),是在六种卷积神经网络(CNNs)和六种视觉Transformer(ViTs)(不包括代理模型ViT-B)上的平均值。 -
在线模型:在百度云API和阿里云API这两个在线模型上评估FPR,结果表明FPR的攻击成功率高于TGR和GNS。在百度云API上,FPR的攻击成功率达到86% ,在阿里云API上为80%,突出了FPR在欺骗商业模型方面的有效性。

表7. 两个商业API上的攻击成功率(ASR)是在50张原本被正确分类的图像上计算得出的。
消融实验-Ablation Studies
该部分主要对FPR方法进行消融研究,通过对比实验分析各组件的有效性、参数敏感性以及梯度消失的影响,具体内容如下:
-
组件有效性分析:将FPR的各个组件(AMD、MTE)分别与普通基线MIM以及表现较好的代理优化方法TGR、GNS进行比较,同时将Dropout作为AMD的对比方法。结果表明,AMD和MTE相结合能产生最佳的转移性效果。此外,Dropout的效果不如AMD,说明直接去除某些注意力图的方式过于激进,无法保留有用信息,而AMD通过多样化注意力图能更有效地提升对抗样本迁移性。
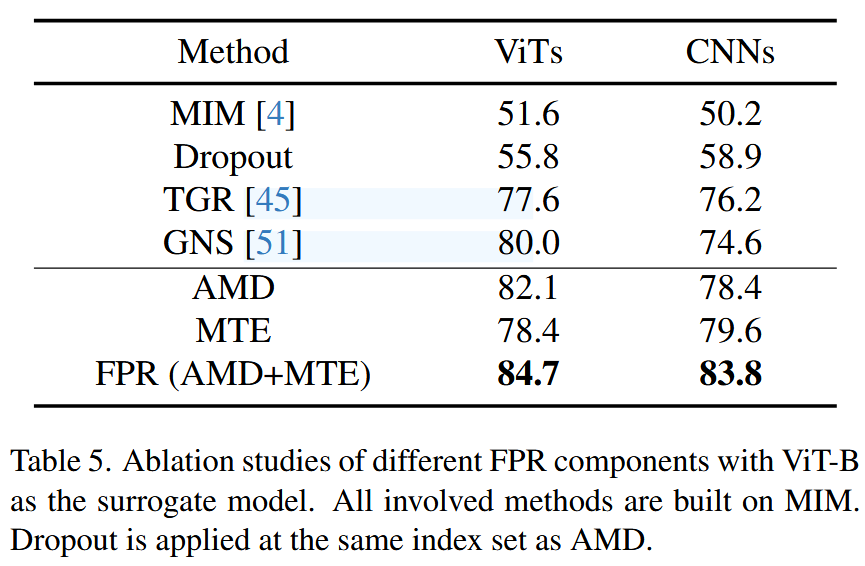
**表5. 以视觉Transformer-Base(ViT-B)作为代理模型,对前向传播优化(FPR)不同组件的消融研究。所有涉及的方法均基于动量迭代法(MIM)构建。随机失活(Dropout)应用于与注意力图多样化(AMD)相同的索引集。 ** -
参数敏感性分析:研究了FPR中三个主要参数(多样性因子 d d d、尺度因子 s s s、衰减因子 η η η)对攻击成功率的影响。结果显示,多样性因子 d d d 控制注意力图的多样性,当 d d d 在25到30之间时,FPR能取得令人满意的性能;尺度因子s代表当前令牌嵌入的重要性, s s s 在0.6到0.8之间时性能较好;衰减因子 η η η 表示历史令牌嵌入的重要性, η η η 在0.2到0.3之间时FPR性能较佳。在这个范围内,攻击成功率相对稳定。
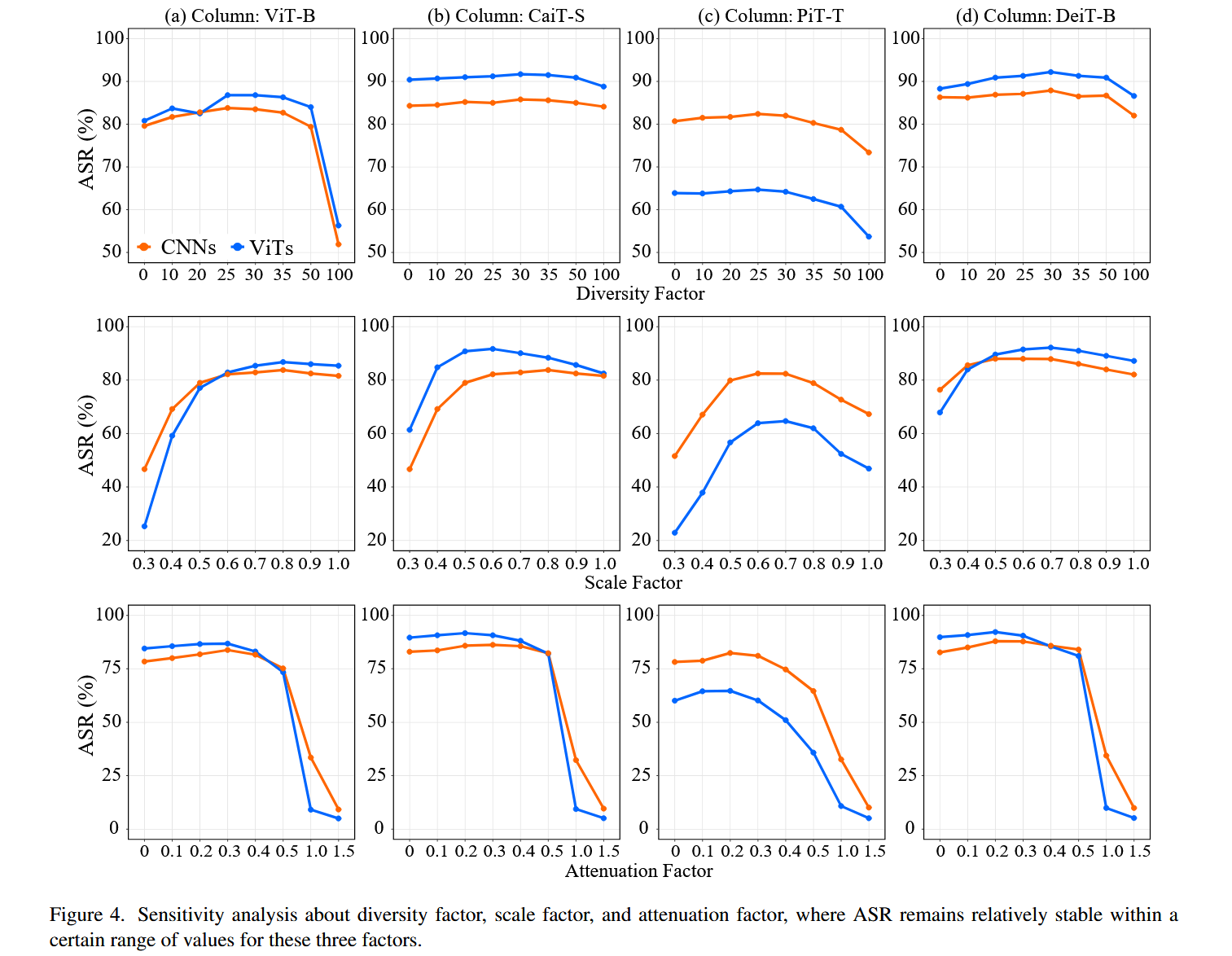
图4. 关于多样性因子、缩放因子和衰减因子的敏感性分析,其中在这三个因子的一定取值范围内,攻击成功率(ASR)保持相对稳定。 -
梯度消失比较:对不同方法中注意力图的输入梯度元素进行分析,比较梯度消失的程度。结果表明,梯度消失与转移性能之间并非简单的线性关系,但可以得出梯度消失有助于提升转移性能的结论,这也与AMD通过多样化注意力图隐式诱导梯度消失来提升转移性能的观点相符,强调了AMD中多样化注意力图在提升对抗样本转移性中的关键作用。

表6. 10次迭代中100张图像的注意力图输入梯度元素的均值。所有的代理模型精炼方法均采用索引集(0, 1, 4, 9, 11)。攻击成功率(ASR)是在13个模型上的平均值,且以视觉Transformer-Base(ViT-B)作为代理模型。
结论-Conclusion
该部分主要总结了研究的核心成果、方法的创新性以及研究的意义,具体如下:
- 研究成果:提出前向传播优化(FPR)方法,用于在视觉Transformer(ViTs)上生成高迁移性的对抗样本。该方法由注意力图多样化(AMD)和动量Token嵌入(MTE)两部分组成。
- 方法创新性:FPR是首个完全在前向传播中优化ViTs代理模型的方法。AMD通过多样化注意力图并隐式导致梯度消失来增强迁移性;MTE通过积累历史token嵌入稳定当前嵌入,实现更准确的更新。
- 研究意义:通过理论分析和大量实验,验证了FPR在提升对抗样本迁移性方面的优越性,为研究ViTs的安全性和对抗攻击提供了新的思路和方法,对后续相关研究具有重要的参考价值。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











