






 AlexNet是2012年提出的深度学习模型,以其16.4%的ImageNetTop5错误率开启了深度学习的黄金时代。相比LeNet,AlexNet更深层,使用ReLU激活函数、Dropout防止过拟合,并结合数据增强等技术提高模型性能。此代码实现了一个简化版的AlexNet模型,用于CIFAR-10数据集。
AlexNet是2012年提出的深度学习模型,以其16.4%的ImageNetTop5错误率开启了深度学习的黄金时代。相比LeNet,AlexNet更深层,使用ReLU激活函数、Dropout防止过拟合,并结合数据增强等技术提高模型性能。此代码实现了一个简化版的AlexNet模型,用于CIFAR-10数据集。
AlexNet 网络诞生于 2012 年,其 ImageNet Top5 错误率为 16.4 %,可以说 AlexNet 的出 现使得已经沉寂多年的深度学习领域开启了黄金时代。
AlexNet 的总体结构和 LeNet 有相似之处,但是有一些很重要的改进:
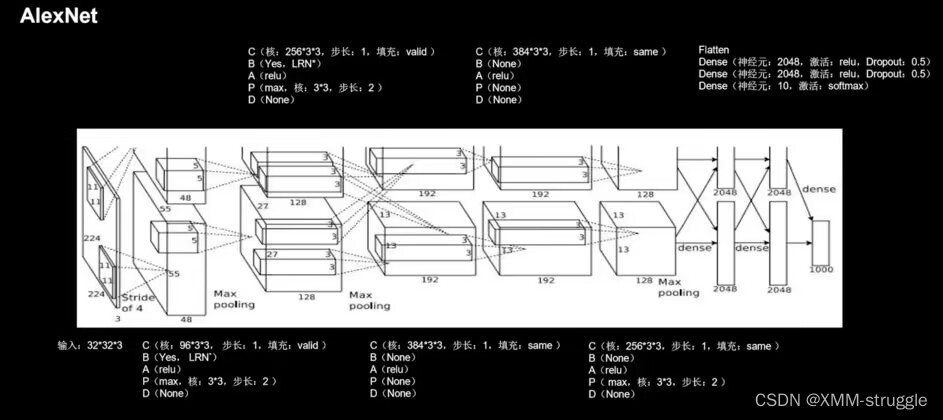
A 由五层卷积、三层全连接组成,输入图像尺寸为 x * x * 3,网络规模远大于 LeNet;
B 使用了 Relu 激活函数;
C 进行了舍弃(Dropout)操作,以防止模型过拟合,提升鲁棒性;
D 增加了一些训练上的技巧,包括数据增强、学习率衰减、权重衰减(L2 正则化)等。 AlexNet 的网络结构如图下 所示。
 借鉴点:激活函数使用 Relu,提升训练速度;Dropout 防止过拟合。
借鉴点:激活函数使用 Relu,提升训练速度;Dropout 防止过拟合。
对比来看,LeNet 总共5层,AlexNet总共8层,后者包括5个卷积层、3个全连接层,最终输出分类为1000。特别注意的是:2/4/5层卷积都只和同一GPU的上一层关联,但是第3层卷积是交叉的,全连接的时候也是如此;LRN接在1/2层卷积之后,最大池化层则接在LRN和第5个卷积之后。在防止过拟合时采用两种手段:数据增强(随机剪裁,利用PCA调整RGB值),dropout。
总结:
(1)文章最后说道:“减少网络中的任意一层都会降低模型的性能”,这其实也预示了深度神经网络的发展,越深的网络会拥有更好的表现。
(2)AlexNet的成功归结于几个方面:a. 百万级数据集,使用数据增强;b. 激活函数 ReLU 对抗梯度消失;c. Dropout 避免过拟合;d. LRN 的使用;e . 双GPU并行计算。
代码实现:
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
#############################################################与上不同####################################################
class AlexNet8(Model):
def __init__(self):
super(AlexNet8, self).__init__()
#1
self.c1 = Conv2D(filters=96, kernel_size=(3, 3))
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(3, 3), strides=2)
#2
self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
#3
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
# 4
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
#5
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
self.flatten = Flatten()
self.f1 = Dense(2048, activation='relu')
self.d1 = Dropout(0.5)
self.f2 = Dense(2048, activation='relu')
self.d2 = Dropout(0.5)
self.f3 = Dense(10, activation='softmax')
#################################################################################################################
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.c4(x)
x = self.c5(x)
x = self.p3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d1(x)
x = self.f2(x)
x = self.d2(x)
y = self.f3(x)
return y
model = AlexNet8()
optimizer = tf.keras.optimizers.Adam()
model.compile(optimizer=optimizer ,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











