




自动补全
需要安装拼音分词器
https://github.com/medcl/elasticsearch-analysis-pinyin
安装方式:
1.解压
2.上传到虚拟机中,elasticsearch的plugin目录
/var/lib/docker/volumes/es-plugins/_data
3.重启elserticsearch
docker restart es
4.测试
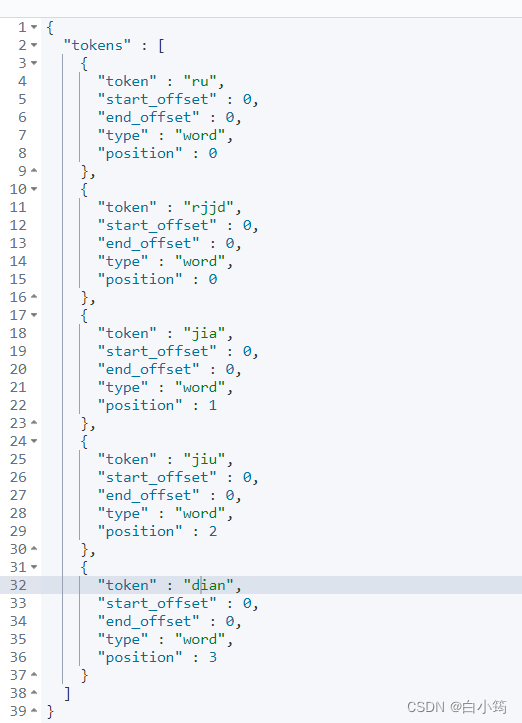
POST /_analyze
{
"text": ["如家酒店"]
, "analyzer": "pinyin"
}
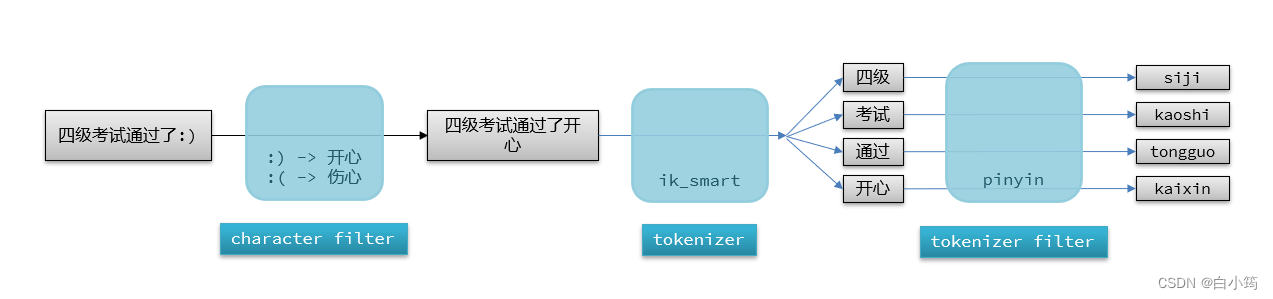
elasticsearch中分词器(analyzer)的组成包含三部分:
- lcharacter filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- ltokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- ltokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
我们在创建索引库时,通过setting来配置自定义的analyzer(分词器)
在创建索引时使用拼音分词器,但是在搜索时使用普通分词器
#自定义拼音分词器my_analyzer
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}
completion suggester查询
参与补全查询的类型必须是completion类型
字段内容一般是用来补全多个词条形成的数组
示例:
#自定义拼音分词器my_analyzer
PUT /test23
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
#自动补全的索引库
PUT test3
{
}
# 示例数据
POST /test23/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST tes23t/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test23/_doc
{
"title": ["Nintendo", "switch"]
}
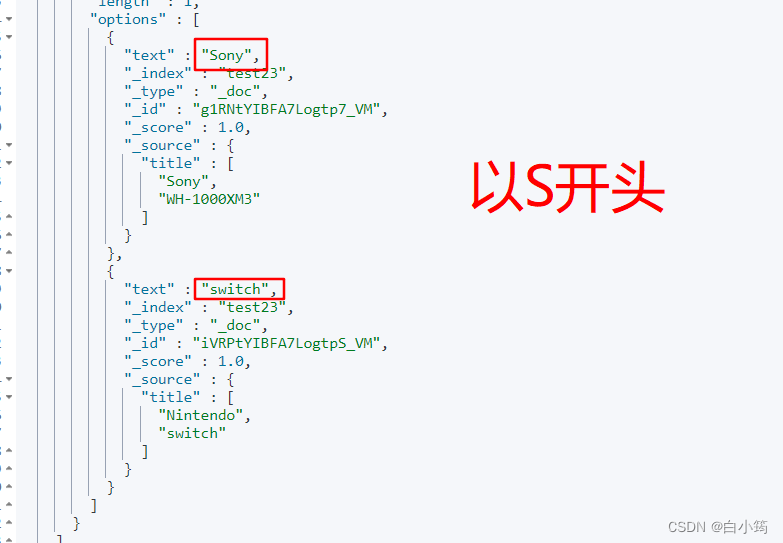
# 自动补全查询
POST /test23/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", //补全字段
"skip_duplicates": true, //跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
RestAPI实现自动补全查询
案例:
实现hotel索引库的自动补全、拼音搜索功能
重新创建酒店的索引
// 酒店数据索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
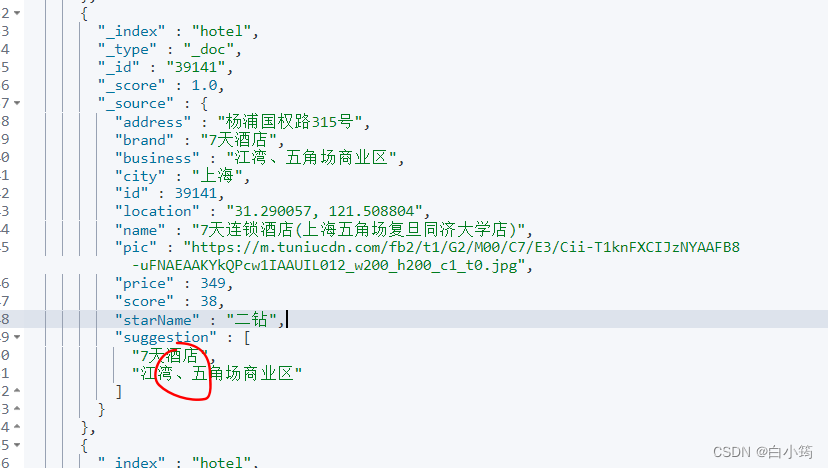
2、新增属性suggestion
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
private Boolean isAD;
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
if (this.business.contains("、")){
//需要切割
String[] arr = this.business.split("、");
this.suggestion=new ArrayList<>();
this.suggestion.add(this.brand);
Collections.addAll(this.suggestion,arr);
}
else {
this.suggestion = Arrays.asList(this.brand, this.business);
}
}
}
重新批量查询酒店数据

3、测试自动补全功能
sh
# 自动补全查询
POST /hotel/_search
{
"suggest": {
"title_suggest": {
"text": "sh",
"completion": {
"field": "suggestion",
"skip_duplicates": true,
"size": 10
}
}
}
}
RestAPI实现自动补全
@Test
void testSuggest() throws IOException {
//准备search
SearchRequest request=new SearchRequest("hotel");
//准备dsl
request.source().suggest(new SuggestBuilder().addSuggestion("suggestion" , SuggestBuilders.completionSuggestion("suggestion").prefix("h").skipDuplicates(true).size(10)));
//发起请求
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//结果解析
Suggest suggest = search.getSuggest();
CompletionSuggestion suggestion = suggest.getSuggestion("suggestion");
List<CompletionSuggestion.Entry.Option> options = suggestion.getOptions();
for (CompletionSuggestion.Entry.Option option : options) {
String s = option.getText().toString();
System.out.println(s);
}
}
实现前端
在Controller中
@GetMapping("suggestion")
public List<String> getSuggestion(@RequestParam("key") String prefix){
return hotelService.getSuggestions(prefix);
}
创建getSuggestions方法,将搜索框内的值传入进去
//自动补全
@Override
public List<String> getSuggestions(String prefix) {
try {
//准备search
SearchRequest request = new SearchRequest("hotel");
//准备dsl
request.source().suggest(new SuggestBuilder().addSuggestion
("suggestion", SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)));
//发起请求
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//结果解析
List<String> list=new ArrayList<>();
Suggest suggest = search.getSuggest();
// CompletionSuggestion
CompletionSuggestion suggestion = suggest.getSuggestion("suggestion");
List<CompletionSuggestion.Entry.Option> options = suggestion.getOptions();
for (CompletionSuggestion.Entry.Option option : options) {
String s = option.getText().toString();
list.add(s);
}
return list;
}catch (Exception e){
throw new RuntimeException(e);
}
}

















 9996
9996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









