




Linux中select、poll 和 epoll的作用
在 Linux 服务器开发领域,高并发 I/O 处理是绕不开的核心话题。当需要同时管理多个文件描述符(如网络连接、本地文件、管道等)时,传统的 “一请求一进程 / 线程” 模型会因资源开销过大而面临性能瓶颈。此时,I/O 多路复用技术成为解决该问题的关键,而 select、poll 和 epoll 正是 Linux 系统中实现这一技术的三大核心接口。本文将从原理、作用、优缺点对比三个维度,带大家全面理解这三个接口的核心价值。
一、先搞懂:什么是 I/O 多路复用?
在讲解具体接口前,我们需要先明确 I/O 多路复用的本质。简单来说,I/O 多路复用允许单个进程 / 线程同时监控多个文件描述符(FD),当其中任意一个或多个 FD 处于 “就绪状态”(如可读、可写、发生异常)时,内核会通知进程 / 线程进行相应处理。
这种机制的核心优势在于:避免进程 / 线程因等待某个 FD 就绪而阻塞,同时减少多进程 / 线程切换的资源开销,尤其适合高并发场景(如 Web 服务器、即时通讯服务等)。而 select、poll、epoll 正是实现这一机制的三种不同 “工具”,它们在效率、接口设计、适用场景上各有差异。
二、select:最基础的 I/O 多路复用接口
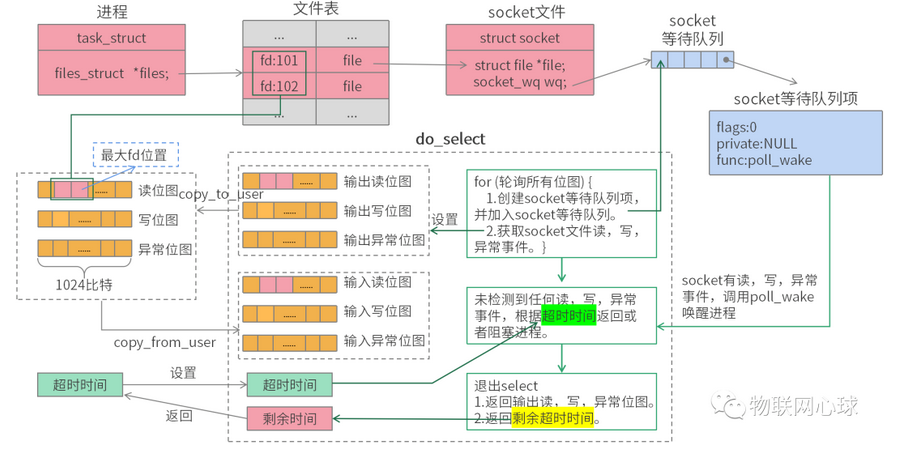
select 是 Unix 系统最早引入的 I/O 多路复用接口,Linux 完全兼容该标准接口,至今仍有部分老旧系统在使用。
1. 核心作用
通过将多个 FD 按 “可读”“可写”“异常” 三类事件分组,传递给内核,让内核监控这些 FD 的状态变化。当任意一组中存在 FD 就绪时,select 会返回就绪 FD 的数量,并标记出具体哪些 FD 就绪,进程 / 线程随后可对这些 FD 进行 I/O 操作。
2. 关键原理与限制
-
FD 集合传递方式:
select使用fd_set结构体(本质是位图)存储待监控的 FD,进程需要将fd_set拷贝到内核空间,内核遍历所有 FD 检查状态后,再将结果拷贝回用户空间。 -
最大 FD 限制:
fd_set的大小由FD_SETSIZE宏定义(默认 1024),这意味着select最多只能监控 1024 个 FD,无法满足高并发场景(如万级连接)。 -
效率问题:每次调用
select时,内核都需要遍历所有待监控的 FD(线性扫描),当 FD 数量较多时,遍历耗时会显著增加,导致性能下降。 -
FD 集合重置:
select返回后,fd_set中仅保留就绪的 FD,未就绪的 FD 会被清空,因此下次调用select前,需要重新初始化并添加所有待监控的 FD,操作繁琐。
3.用法示例
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(sockfd, &readfds);
struct timeval tv;
tv.tv_sec = 5; // 等待 5 秒
tv.tv_usec = 0;
int ret = select(sockfd + 1, &readfds, NULL, NULL, &tv);
if (ret > 0) {
if (FD_ISSET(sockfd, &readfds)) {
// sockfd 可读
}
} else if (ret == 0) {
// 超时
} else {
// 出错
}
三、poll:对 select 的改进与局限
poll 是为解决 select 的部分缺陷而设计的接口,在 Linux 2.1.23 版本中引入,接口设计更灵活,但核心原理仍未摆脱 “线性扫描” 的瓶颈。
1. 核心作用
与 select 类似,poll 也用于监控多个 FD 的就绪状态,但它通过 struct pollfd 结构体数组替代 fd_set,支持更灵活的事件管理,同时突破了 select 的 FD 数量限制。
2. 关键原理与改进
-
事件描述结构:
struct pollfd中包含三个核心字段:fd(待监控的文件描述符)、events(需要监控的事件,如POLLIN表示可读、POLLOUT表示可写)、revents(内核返回的就绪事件)。进程只需传递一个pollfd数组给内核,无需按事件类型分组。 -
突破 FD 数量限制:
poll没有FD_SETSIZE的限制,理论上可监控的 FD 数量仅受系统内存和进程文件描述符上限(RLIMIT_NOFILE)的约束,可支持更多连接。 -
避免 FD 集合重置:
pollfd数组中的events字段由用户设置,revents字段由内核填充,未就绪的 FD 不会被从数组中移除,因此下次调用poll时无需重新初始化数组,仅需调整events字段即可,比select更便捷。
3.用法示例
struct pollfd fds[10];
fds[0].fd = sockfd;
fds[0].events = POLLIN;
int ret = poll(fds, 1, 5000); // 等待 5 秒
if (ret > 0) {
if (fds[0].revents & POLLIN) {
// sockfd 可读
}
}
4. 仍未解决的痛点
poll 虽然改进了 select 的 FD 数量限制和接口灵活性,但核心效率问题未变:每次调用 poll 时,内核仍需遍历整个 pollfd 数组(线性扫描)检查 FD 状态,当 FD 数量达到万级甚至十万级时,遍历耗时会急剧增加,性能依然无法满足高并发需求。
四、epoll:高并发场景的 “最优解”
epoll 是 Linux 特有的 I/O 多路复用接口,在 Linux 2.5.44 版本中引入,专为高并发场景设计,彻底解决了 select 和 poll 的 “线性扫描” 效率问题,是目前 Linux 服务器开发(如 Nginx、Redis)的首选方案。
1. 核心作用
epoll 通过 “事件驱动” 机制,将 FD 的监控与就绪通知分离:进程只需一次性将待监控的 FD 注册到内核的 epoll 实例中,内核会维护一个 “就绪 FD 链表”,当 FD 就绪时,内核直接将其加入链表,进程无需遍历所有 FD,只需从链表中获取就绪 FD 即可,效率大幅提升。
2. 关键原理与核心优势
epoll 的核心机制依赖三个系统调用:epoll_create、epoll_ctl、epoll_wait,三者协同实现高效的 FD 监控:
(1)epoll_create:创建 epoll 实例
调用 epoll_create(size) 会在内核中创建一个 epoll 实例(本质是一个红黑树 + 就绪链表),其中:
-
红黑树:用于存储进程注册的所有待监控 FD,支持高效的插入、删除、查找操作(时间复杂度 O (log n))。
-
就绪链表:用于存储内核检测到的就绪 FD,当 FD 状态变化时,内核会将其移动到就绪链表中,避免遍历所有 FD。
(2)epoll_ctl:管理监控的 FD
epoll_ctl(epfd, op, fd, event) 用于向 epoll 实例中添加、删除或修改待监控的 FD 及其事件:
-
epfd:epoll_create返回的epoll实例文件描述符。 -
op:操作类型,如EPOLL_CTL_ADD(添加 FD)、EPOLL_CTL_DEL(删除 FD)、EPOLL_CTL_MOD(修改 FD 的监控事件)。 -
fd:待操作的文件描述符。 -
event:struct epoll_event结构体,指定监控的事件(如EPOLLIN、EPOLLOUT)及用户数据(用于关联业务逻辑)。
(3)epoll_wait:等待 FD 就绪
epoll_wait(epfd, events, maxevents, timeout) 用于阻塞等待 epoll 实例中的就绪 FD,当有 FD 就绪时,内核会将就绪 FD 的信息(如 revents、用户数据)填充到 events 数组中,并返回就绪 FD 的数量。
(4)核心优势总结
-
无 FD 数量限制:仅受系统内存和
RLIMIT_NOFILE约束,支持万级、十万级甚至百万级 FD 监控。 -
高效的事件通知:通过红黑树管理待监控 FD,就绪链表存储就绪 FD,无需线性扫描,时间复杂度稳定在 O (1)(获取就绪 FD)和 O (log n)(添加 / 删除 FD)。
-
内存拷贝优化:
epoll仅在epoll_ctl时将 FD 信息拷贝到内核,后续epoll_wait只需从内核的就绪链表中 “引用” 数据,无需重复拷贝整个 FD 集合(select和poll每次调用都需拷贝)。 -
支持边缘触发(ET)和水平触发(LT):
-
水平触发(LT):只要 FD 处于就绪状态,每次调用
epoll_wait都会返回该 FD,适合新手或需确保数据处理完整的场景(默认模式)。 -
边缘触发(ET):仅在 FD 状态从 “未就绪” 变为 “就绪” 时返回一次,需一次性读取 / 写入所有数据,效率更高,但对编程要求更严格(需避免数据残留)。
-
3.用法示例
int epfd = epoll_create(10);
struct epoll_event ev, events[10];
ev.events = EPOLLIN;
ev.data.fd = sockfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &ev);
int nfds = epoll_wait(epfd, events, 10, 5000);
for (int i = 0; i < nfds; i++) {
if (events[i].events & EPOLLIN) {
// sockfd 可读
}
}
五、三者核心差异对比与选型建议
为了更清晰地理解三者的适用场景,我们通过表格总结核心差异:
| 特性 | select | poll | epoll |
|---|---|---|---|
| 最大 FD 限制 | 受 FD_SETSIZE(1024)限制 | 无(受系统内存 / RLIMIT_NOFILE) | 无(同 poll) |
| 内核遍历方式 | 线性扫描(O (n)) | 线性扫描(O (n)) | 就绪链表(O (1) 获取) |
| 内存拷贝 | 每次调用拷贝整个 fd_set | 每次调用拷贝整个 pollfd 数组 | 仅 epoll_ctl 时拷贝 |
| 事件通知模式 | 水平触发(LT) | 水平触发(LT) | LT/ET 均可 |
| 接口灵活性 | 差(按事件分组) | 中(pollfd 数组) | 优(epoll_event + 用户数据) |
| 适用场景 | 低并发(<1024 FD) | 中低并发(< 万级 FD) | 高并发(万级 + FD) |
选型建议
-
若维护老旧系统:若代码基于
select开发且 FD 数量少(如嵌入式设备),可继续使用select,无需改造。 -
若需兼容多系统:
select和poll是 POSIX 标准接口,可跨 Unix/Linux 系统;epoll是 Linux 特有,若需跨平台(如 macOS、FreeBSD),需考虑kqueue(类 epoll 接口)。 -
若开发高并发服务:如 Web 服务器、消息队列、网关等,优先选择
epoll,并根据场景选择 LT(开发简单)或 ET(性能更高)模式。
六、总结
select、poll、epoll 都是 Linux 中实现 I/O 多路复用的核心接口,其演进路径清晰地反映了 “从低效率到高效率、从有限制到灵活扩展” 的技术趋势:
-
select是基础,但受 FD 数量和线性扫描限制,仅适用于低并发场景; -
poll改进了 FD 数量限制和接口灵活性,但仍未解决线性扫描的效率问题; -
epoll基于 “红黑树 + 就绪链表” 的事件驱动模型,彻底突破了效率瓶颈,成为高并发 Linux 服务的首选方案。
理解三者的核心差异和适用场景,是开发者设计高性能 I/O 服务的基础。在实际开发中,建议结合业务并发量、跨平台需求和编程复杂度,选择最合适的接口 —— 对于 Linux 高并发场景,epoll 几乎是必然选择。


















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









