




 布隆过滤器是一种概率型数据结构,用于高效地插入和查询元素,常用于判断元素是否存在。其通过多个哈希函数将数据映射到位图,节省内存但存在误判可能。文章展示了布隆过滤器的Java实现,并列举了网页爬虫URL去重、垃圾邮件过滤等应用场景。尽管存在误判和无法删除元素的缺点,但在处理大规模数据时,布隆过滤器仍具有显著优势。
布隆过滤器是一种概率型数据结构,用于高效地插入和查询元素,常用于判断元素是否存在。其通过多个哈希函数将数据映射到位图,节省内存但存在误判可能。文章展示了布隆过滤器的Java实现,并列举了网页爬虫URL去重、垃圾邮件过滤等应用场景。尽管存在误判和无法删除元素的缺点,但在处理大规模数据时,布隆过滤器仍具有显著优势。
1.概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
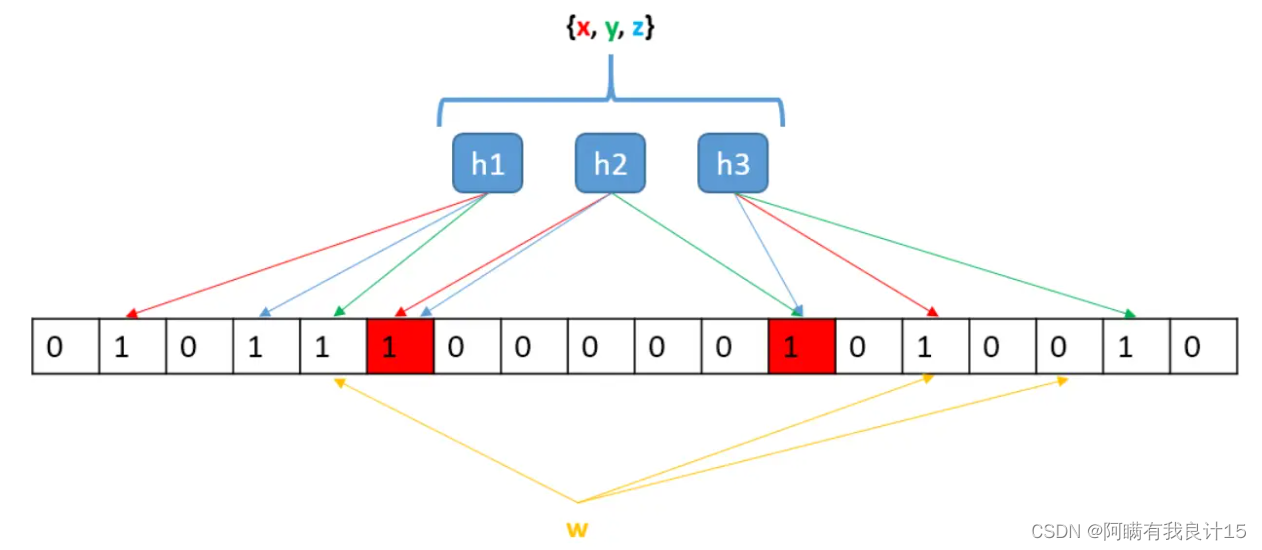
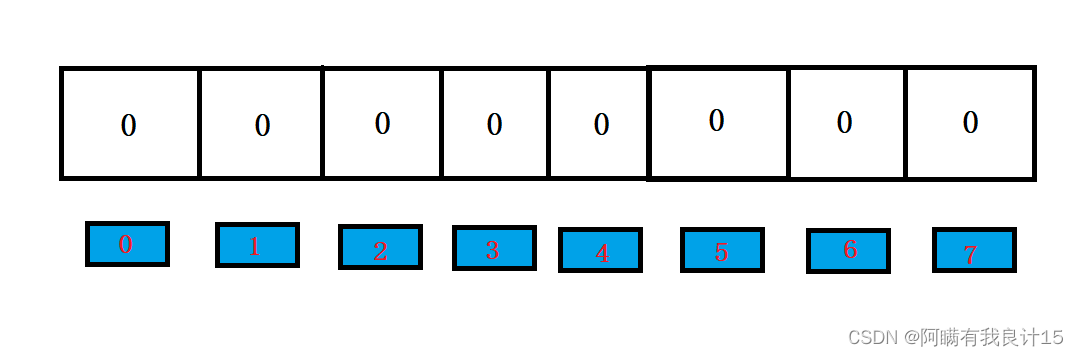
2.演示一下布隆过滤器的插入
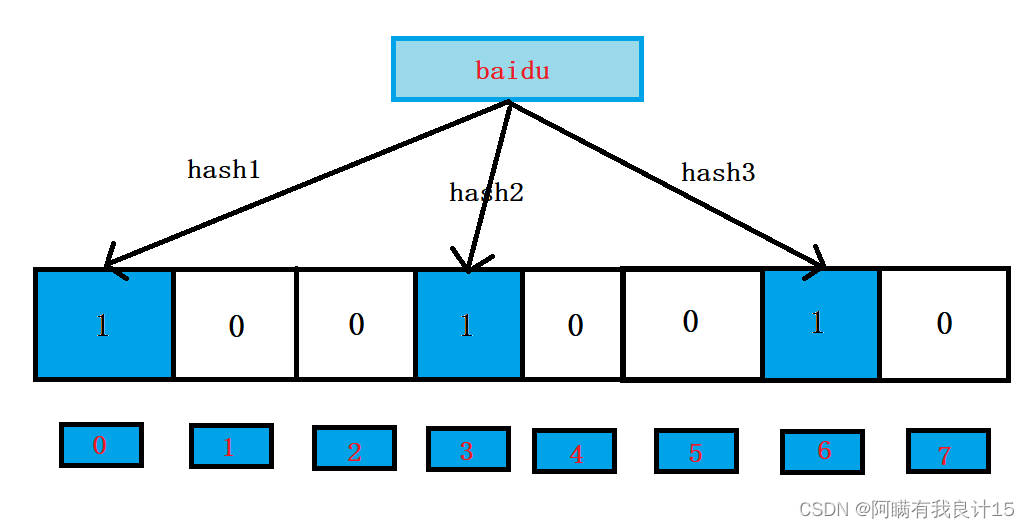
插入baidu
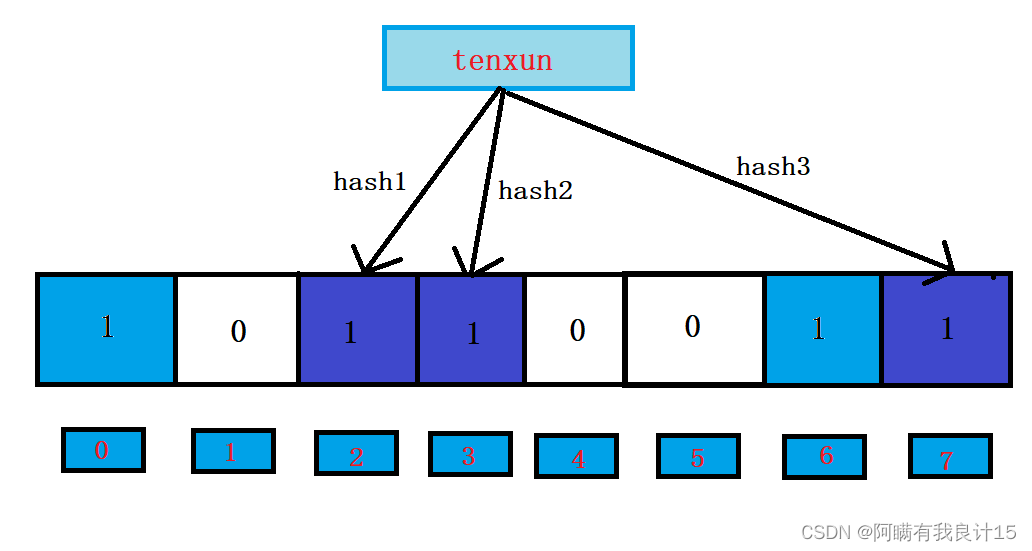
插入tenxun
3.具体实现
package test;
import java.util.BitSet;
class Hash {
public int cap;//容量
public int seed;//种子
public Hash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
//把当前字符串变成一个hash值
public int hash(String key) {
int h;
return (key == null) ? 0 : (seed * (cap - 1)) & ((h = key.hashCode()) ^ (h >>> 16));
}
}
public class MyBloomFilter {
public static final int DEFAULT_SIZE = 1 << 20;
public BitSet bitSet;
public int usedSize;
public static final int[] seeds = {5, 7, 11, 13, 27, 33};
public Hash[] hashes;
public MyBloomFilter() {
bitSet = new BitSet(DEFAULT_SIZE);
hashes = new Hash[seeds.length];
for (int i = 0; i < hashes.length; i++) {
hashes[i] = new Hash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String val) {
for (Hash hash : hashes) {
int index = hash.hash(val);
bitSet.set(index);
}
usedSize++;
}
public boolean contains(String val) {
for (Hash hash : hashes) {
int index = hash.hash(val);
boolean flag = bitSet.get(index);
if (!flag) {
return false;
}
}
return true;//会误判
}
public static void main(String[] args) {
MyBloomFilter myBloomFilter = new MyBloomFilter();
myBloomFilter.add("hello");
myBloomFilter.add("hello1");
myBloomFilter.add("haha");
System.out.println(myBloomFilter.contains("hello"));
System.out.println(myBloomFilter.contains("hello1"));
System.out.println(myBloomFilter.contains("hello2"));
}
}
4.应用场景:
1.网页爬虫对URL的去重,避免爬去相同的URL地址。
2.垃圾邮件过滤,从数十亿个垃圾邮件列表中判断某邮箱是否是垃圾邮箱。
3.解决数据库缓存击穿,黑客攻击服务器时,会构建大量不存在于缓存中的key向服务器发起请求,在数据量足够大的时候,频繁的数据库查询会导致挂机。
4. 秒杀系统,查看用户是否重复购买。
5. google的guava包中有对Bloom Filter的实现
5.优点
1. 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
2. 哈希函数相互之间没有关系,方便硬件并行运算
3. 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
4. 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
5. 数据量很大时,布隆过滤器可以表示全集(节省空间),其他数据结构不能
6. 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
6.缺点
1. 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白
名单,存储可能会误判的数据)
2. 不能获取元素本身
3. 一般情况下不能从布隆过滤器中删除元素
4. 如果采用计数方式删除,可能会存在计数回绕问题
7.误判率
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的 bit 位被多次映射且置 1。这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。


















 167万+
167万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











