




 该博客围绕使用积分法和蒙特卡洛法计算Pi值展开实验。介绍了串行和Windows环境OpenMP库并行编程两种方法,给出代码实现及编译运行命令。分析了不同方法的程序编写技巧、函数使用技巧和易出错点,还总结了并行计算优势、数值积分应用等实验心得。
该博客围绕使用积分法和蒙特卡洛法计算Pi值展开实验。介绍了串行和Windows环境OpenMP库并行编程两种方法,给出代码实现及编译运行命令。分析了不同方法的程序编写技巧、函数使用技巧和易出错点,还总结了并行计算优势、数值积分应用等实验心得。
一、实验题目:
使用两种编程方法实现积分法和蒙特卡洛法计算pi值
- 串行方法
- Windows环境OpenMP库并行编程
二、实验目的
熟悉 OpenMP 编程,加深对其编程的理解。
三、实验环境
Windows,VC+OpenMP
四、程序设计
1.实现思想
积分法:
这个程序是基于圆和圆的面积的数学定义来估计π的值的。我们知道,单位圆(半径为1)的面积是π。因此,如果我们可以计算出单位圆的面积,就可以得到π的值。
这个程序是通过积分方法来计算单位半圆(即,圆心在原点,半径为1,且只考虑x大于等于0的部分)的面积的。单位半圆的方程是y = sqrt(1 - x * x),这就是函数f(x)的定义。
然后,程序将单位半圆的面积分成N个小矩形,并对这些矩形的面积进行求和。每个小矩形的宽度是step,高度是f(x),所以面积是step * f(x)。程序对所有小矩形的面积求和,然后乘以4,就得到了π的估计值。
蒙特卡洛法:
这个程序是基于圆和正方形的几何关系来估计π的值的。单位圆的面积是π,边长为2的正方形的面积是4。如果在单位正方形内随机生成一个点,那么这个点落在单位圆内的概率就是π/4。
程序首先设置一个随机数种子,然后生成N个随机点。每个随机点的坐标x和y都是在0到1之间的随机数。然后,程序检查这个点是否落在单位圆内(即,x * x + y * y <= 1)。
最后,程序计算落在单位圆内的点的数量占总点数的比例,然后乘以4,就得到了π的估计值。
2.代码实现
(1)串行方法
积分法
//串行方法-积分法
#include <stdio.h>
#include <math.h>
double f(double x) {
return sqrt(1 - x * x); // 半圆的方程
}
// 使用数值积分方法计算 Pi 的近似值
double calculatePi(int N) {
double sum = 0.0;
double step = 1.0 / (double)N;
// 使用中点法进行数值积分
for (int i = 0; i < N; i++) {
double x = (i + 0.5) * step;
sum += f(x);
}
return 4.0 * sum * step; // 根据积分法的定义,乘以4
}
int main() {
int N = 10000000; // 积分的步数
double pi = calculatePi(N);
printf("Pi is approximately %.15f\n", pi);
return 0;
}
蒙特卡洛法
//串行方法-蒙特卡洛方法
//基于圆和正方形的几何关系来估计π的值
//在单位正方形内随机生成一个点,这个点落在单位圆内的概率就是π/4。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
double calculatePi(int N) {
int count = 0;
srand(time(0)); // 设置随机数种子
// 使用蒙特卡洛方法计算 Pi 的近似值
for (int i = 0; i < N; i++) {
double x = (double)rand() / RAND_MAX;
double y = (double)rand() / RAND_MAX;
// 判断随机点是否落在单位圆内
if (x * x + y * y <= 1) {
count++;
}
}
return 4.0 * count / N; // 根据蒙特卡洛法的定义,乘以4
}
int main() {
// int N = 10000000;
int N = 1000000000LL;// 随机点的数量
double pi = calculatePi(N);
printf("Pi is approximately %.15f\n", pi);
return 0;
}
(2)并行方法
积分法
//并行方法-蒙特卡洛法
#include <stdio.h>
#include <math.h>
#include <omp.h>
double f(double x) {
return sqrt(1 - x * x); // 半圆的方程
}
// 使用数值积分方法计算 Pi 的近似值
double calculatePi(int N) {
double sum = 0.0;
double step = 1.0 / (double)N;//计算积分步长(step):将单位半圆的面积分成N个小矩形,每个小矩形的宽度是step。
#pragma omp parallel for reduction(+:sum) // 使用OpenMP的并行for循环和reduction操作
for (int i = 0; i < N; i++) {
double x = (i + 0.5) * step;
sum += f(x);
}
return 4.0 * sum * step; // 根据积分法的定义,乘以4
}
int main() {
int N = 10000000; // 积分的步数
double pi = calculatePi(N);
printf("Pi is approximately %.15f\n", pi);
return 0;
}
蒙特卡洛法
//并行方法-蒙特卡洛法
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#include <omp.h>
double calculatePi(long long N) {
long long count = 0;
#pragma omp parallel
{
unsigned int seed = (int)time(NULL) ^ omp_get_thread_num(); // 每个线程的随机数种子
#pragma omp for reduction(+:count) // 使用OpenMP的并行for循环和reduction操作
for(long long i = 0; i < N; i++) {
double x = (double) rand_r(&seed) / RAND_MAX;
double y = (double) rand_r(&seed) / RAND_MAX;
if(x * x + y * y <= 1) {
count++;
}
}
}
return 4.0 * count / N; // 根据蒙特卡洛法的定义,乘以4
}
int main() {
long long N = 1000000000LL; // 随机点的数量
double pi = calculatePi(N);
printf("Pi is approximately %.15f\n", pi);
return 0;
}
2.编译运行命令
(1)串行方法
积分法
编译
gcc calculatePi_integral.c -o calculatePi_integral -lm
运行
./calculatePi_integral
蒙特卡洛法
编译
gcc calculatePi_monteCarlo.c -o calculatePi_monteCarlo
运行
./calculatePi_monteCarlo
(2)并行方法
积分法
编译:
gcc -fopenmp calculatePi_integral_parallel.c -o calculatePi_integral_parallel -lm
运行:
./calculatePi_integral_parallel
蒙特卡洛法
编译:
gcc -fopenmp calculatePi_monteCarlo_parallel.c -o calculatePi_monteCarlo_parallel
运行:
./calculatePi_monteCarlo_parallel
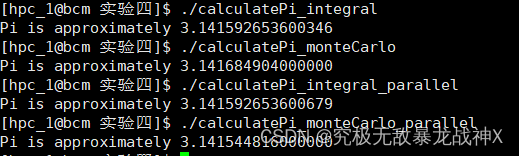
五、运行结果
六、实验心得
(1)串行方法
(i)积分法
程序编写技巧
- 函数的封装:代码将计算被积函数f(x)和计算Pi的逻辑封装在了两个函数中,提高了代码的可读性和模块化程度。通过将不同的功能封装成函数,可以更好地组织代码,使其更易于理解和维护。
- 数值积分方法:代码使用中点法(Midpoint Rule)进行数值积分计算。该方法将积分区间划分为多个小区间,在每个小区间上取中点进行函数值的采样,然后通过求和来近似积分结果。这种数值积分方法简单有效,适用于一些简单的函数积分。
- 循环和累加:通过循环来迭代计算每个小区间上的函数值,然后将函数值累加到sum变量中。这种方式允许逐步计算积分的近似值。
- 函数调用和返回值:在主函数中,调用
calculatePi函数来计算Pi的近似值。calculatePi函数接受积分步数N作为参数,并返回计算得到的Pi近似值。通过将计算和结果返回封装成一个函数,提高了代码的模块化程度和可复用性。 - 输出结果:通过
printf函数打印计算得到的Pi近似值。使用格式化字符串%.15f控制小数位数,以便输出更精确的结果。 - 常量定义:将积分步数N作为常量定义,并在代码中使用该常量。通过将常量进行定义,使得代码更具可读性和可维护性。
函数使用技巧
- 函数封装:将计算被积函数和计算Pi的逻辑封装成了两个函数,即
f和calculatePi。这样的封装提高了代码的可读性和模块化程度,使得代码更易于理解和维护。通过将不同的功能封装成函数,可以更好地组织代码,使其更易于复用和扩展。 - 函数参数传递:
calculatePi函数使用一个整型参数N来指定积分的步数。这样的设计允许在不修改函数代码的情况下,通过传递不同的参数值来进行不同精度的计算。通过合理使用函数参数,可以增加代码的灵活性和可扩展性。 - 函数返回值:
calculatePi函数返回一个double类型的值,即计算得到的Pi的近似值。通过使用函数返回值,可以将计算结果传递给调用方,并方便后续的处理或输出。合适的使用函数返回值可以提高代码的可读性和灵活性。 - 函数内局部变量:在
calculatePi函数中,使用了局部变量sum和step来存储中点法计算积分的过程中的临时结果。这种局部变量的使用有助于在函数内部封装计算逻辑,并且在不同的函数调用之间保持独立性,避免了变量冲突和命名空间污染。 - 函数命名:函数名
f和calculatePi能够清晰地表达函数的功能和用途。良好的函数命名可以提高代码的可读性和可维护性,让其他人能够快速理解函数的作用。
容易出错的地方
- 命令行参数处理:代码假设命令行参数的格式是正确的,即第一个参数是整数N。如果用户提供了不符合要求的参数格式,例如非整数参数或没有提供足够的参数,代码可能会出现错误。
- 整数溢出:在代码中,使用
long long类型的整数N来表示积分的步数。如果输入的N值超过了long long类型的表示范围,可能会导致整数溢出和计算错误。 - 数值积分精度:代码使用中点法进行数值积分来近似计算Pi的值。然而,中点法作为一种数值积分方法,在某些函数和积分区间上可能存在精度问题。对于某些函数或需要更高精度的计算,可能需要使用其他更精确的数值积分方法。
- 并发访问:这段代码是串行的,没有使用并行计算。但如果在代码中引入并行性,例如使用OpenMP或MPI等并行编程库,需要注意并发访问共享变量的问题。对于共享变量
sum的并发访问,需要使用适当的同步机制(如互斥锁)来保护共享资源的一致性。 - 数值计算误差:在使用数值积分方法近似计算Pi的过程中,会引入数值计算误差。这是由于数值积分是一种近似方法,无法完全准确地计算积分结果。因此,通过数值积分方法得到的Pi的近似值可能会与真实值有一定的误差。
- 积分区间:代码中使用的积分区间是[0, 1],即半圆的方程。如果需要计算其他函数或不同的积分区间,需要相应地修改代码。
(ii)蒙特卡洛法串行方法
程序编写技巧
- 随机数生成:使用
rand函数生成伪随机数。通过调用srand函数设置随机数种子,可以确保每次运行程序时生成的随机数序列是不同的。这样可以避免每次运行得到相同的随机数序列。 - 循环和计数:通过循环生成N个随机点,并使用计数器
count记录落在单位圆内的点的数量。通过循环和计数的方式,逐步计算随机点落在单位圆内的概率。 - 数学计算:在每次循环中,通过计算随机点的x和y坐标,判断这个点是否落在单位圆内。这里使用了简单的几何关系,判断点的距离是否小于等于1来确定点的位置。
- 数据类型转换:在计算随机点的x和y坐标时,将
rand()函数生成的整数值除以RAND_MAX,然后转换为double类型。这样可以将整数转换为浮点数,以得到范围在[0, 1]之间的随机数。 - Pi的估计值计算:通过将落在单位圆内的点数量
count除以总的随机点数量N,乘以4,得到Pi的近似值。这是蒙特卡洛方法的定义,基于单位圆和正方形的几何关系。 - 输出结果:通过
printf函数打印计算得到的Pi近似值。使用格式化字符串%.15f控制小数位数,以便输出更精确的结果。 - 随机数种子设置:使用
time(0)函数设置随机数种子,以当前时间作为种子值。这样可以在每次运行程序时生成不同的随机数序列。
函数使用技巧
- 随机数生成:使用
rand()函数生成伪随机数。通过调用srand()函数设置随机数种子,可以控制随机数的生成。在代码中使用了time(0)函数作为种子,以当前时间作为随机数种子,从而保证每次运行程序时生成不同的随机数序列。 - 循环和计数:使用
for循环迭代生成N个随机点,并使用计数器count记录落在单位圆内的点的数量。这种循环和计数的方式是一种常见的技巧,用于统计事件发生的次数或计算某个特定条件的数量。 - 数据类型转换:在计算随机点的x和y坐标时,将
rand()生成的整数值转换为double类型。这样可以将整数转换为浮点数,以获得范围在[0, 1]之间的随机数。通过合理的数据类型转换,可以确保随机数在适当的范围内。 - 数学计算:使用数学函数
sqrt()计算点的距离,并通过判断距离是否小于等于1来确定点是否落在单位圆内。这种数学计算的使用展示了如何利用数学函数来处理问题,以及如何使用条件判断来决定计算结果。 - 函数返回值:
calculatePi函数返回一个double类型的值,即计算得到的Pi的近似值。通过使用函数返回值,可以将计算结果传递给调用方,并方便后续的处理或输出。合适的使用函数返回值可以提高代码的可读性和灵活性。
容易出错的地方
- 随机数种子设置:代码中使用了
srand(time(0))来设置随机数种子,以当前时间作为种子值。然而,如果多次在同一秒内运行代码,种子值将是相同的,导致生成相同的随机数序列。这可能会导致结果不够随机或重复。可以考虑使用更精确的时间函数(如clock())或引入其他随机性因素来设置种子值。 - 随机数生成的均匀性:代码使用
rand()函数生成随机数。然而,rand()函数生成的随机数可能不是完全均匀的。在某些情况下,可能会出现随机数生成的分布不均匀或存在重复值的问题。这可能导致对于蒙特卡洛方法的准确性和稳定性产生影响。 - 数值精度:使用蒙特卡洛方法进行Pi的估计,结果受到随机采样的影响。估计结果的精度与采样点的数量有关。在处理大量随机点时,需要注意数值精度和数值稳定性,以获得更准确的结果。
- 运行时间:代码中的计算是以迭代次数N作为终止条件,但在某些情况下,可能需要根据运行时间来控制迭代的终止条件。如果计算时间过长或过短,可能会影响到结果的准确性或计算效率。
- 结果输出格式:代码中使用
printf函数打印计算得到的Pi的近似值。但是,需要注意输出结果的格式化和精度,以确保输出的结果符合预期并具有可读性。
(2)并行编程
(i)积分法
程序编写技巧
- 函数封装:将计算被积函数f(x)和计算Pi的逻辑封装在了两个函数中,即f和calculatePi。这样的封装提高了代码的可读性和模块化程度,使得代码更易于理解和维护。
- 并行计算:通过使用OpenMP的并行for循环和reduction操作,实现了计算的并行化。使用
#pragma omp parallel for指令将for循环并行化,使用reduction(+:sum)将每个线程的局部和sum进行求和操作,从而得到最终的总和。这样可以利用多个线程并行计算小矩形的面积。 - 并行化效果:通过将计算任务分配给多个线程进行并行计算,可以加速计算过程。对于大规模的计算和复杂的任务,合理利用并行计算可以显著提高计算效率。
- 数据共享和同步:在并行计算中,多个线程共享变量
sum,需要使用reduction操作确保正确的结果。这样可以避免多个线程同时写入sum导致数据竞争和错误的结果。OpenMP的reduction操作可以自动处理线程之间的同步和数据共享。 - 函数返回值:
calculatePi函数返回一个double类型的值,即计算得到的Pi的近似值。通过使用函数返回值,可以将计算结果传递给调用方,并方便后续的处理或输出。合适的使用函数返回值可以提高代码的可读性和灵活性。 - 输出结果:通过
printf函数打印计算得到的Pi近似值。使用格式化字符串%.15f控制小数位数,以便输出更精确的结果。
函数使用技巧
- 函数封装:代码中使用了两个函数,
f和calculatePi,将不同的功能封装成独立的函数。这种函数封装提高了代码的可读性和可维护性,使得代码更易于理解和修改。通过将不同的计算逻辑封装成函数,可以提高代码的模块化程度和可重用性。 - 函数参数传递:
calculatePi函数使用一个整型参数N来指定积分的步数。这样的设计允许在不修改函数代码的情况下,通过传递不同的参数值来进行不同精度的计算。通过合理使用函数参数,可以增加代码的灵活性和可扩展性。 - 并行计算指令:使用OpenMP指令来并行化计算过程。通过
#pragma omp parallel for指令,将for循环并行化执行,让多个线程同时计算小矩形的面积。这种并行计算指令能够简化并行化过程,提高代码的效率和性能。 - 局部变量和局部计算:在并行计算中,每个线程都有自己的局部变量
sum,用于存储局部计算的结果。这样可以避免不同线程之间的数据竞争问题,保证计算的正确性。通过合理使用局部变量,可以提高并行计算的效率和可靠性。 - 函数返回值:
calculatePi函数使用double类型的返回值,将计算得到的Pi的近似值返回给调用者。通过函数返回值的方式,可以方便地传递计算结果,让调用者可以进一步处理或输出。函数返回值的使用可以提高代码的可读性和灵活性。 - 数值计算方法:在
calculatePi函数中使用了数值积分的方法来计算Pi的近似值。通过将单位半圆划分成N个小矩形,计算每个小矩形的面积,并求和得到近似的积分值。这种数值计算方法在解决数学问题时很常见,可以灵活应用于不同的计算场景。
这些函数使用的技巧有助于提高代码的可读性、可维护性和性能。合理地使用函数封装、参数传递、并行计算指令、局部变量和函数返回值,可以使函数的功能和用途更加明确,代码逻辑更易于理解和调试。并行计算指令的使用可以提高代码的执行效率和性能。
容易出错的地方
- 并行计算的正确性:并行化计算过程涉及到多个线程同时执行任务,需要确保并行计算的正确性。在并行计算中,要注意共享变量的访问和修改,以及数据竞争和并发访问的问题。特别是在计算
sum时,使用了reduction操作来确保并行计算的正确性。但仍然需要注意并行计算引入的潜在错误。 - 随机数生成的均匀性:蒙特卡洛方法的准确性受到随机数生成的均匀性影响。在并行计算中,多个线程同时生成随机数,需要确保生成的随机数具有均匀性。如果随机数生成不均匀,可能导致计算结果的偏差。
- 运行时间和计算精度:代码中使用固定的积分步数
N来控制计算的精度。但需要注意计算的运行时间和计算精度之间的权衡。如果步数过大,可能会导致计算时间过长,而步数过小可能会导致计算精度不足。需要根据实际需求和计算资源进行适当的调整。 - 并行性能:并行计算的性能不仅取决于代码的并行化策略,还取决于计算资源的分配和负载平衡。如果线程数量过多或过少,或者任务负载不均衡,可能会导致并行计算的性能下降。需要对并行化的策略和资源配置进行合理的调整。
- 输出结果的格式:代码中使用
printf函数打印计算得到的Pi的近似值。需要注意输出结果的格式化和精度,以确保输出的结果符合预期并具有可读性。
(ii)蒙特卡洛法串行方法
程序编写技巧
- 并行化计算:通过使用OpenMP的并行化指令和操作,实现了计算的并行化。使用
#pragma omp parallel指令创建并行区域,让多个线程同时执行计算任务。使用#pragma omp for指令将for循环并行化执行,并使用reduction(+:count)将每个线程的局部计数器count进行求和操作。这样可以充分利用多个线程并行计算落在单位圆内的点的数量。 - 随机数生成:在并行计算中,每个线程都需要生成随机数。为了确保每个线程生成不同的随机数序列,使用了线程编号和时间种子的异或运算来设置每个线程的随机数种子。通过将时间种子与线程编号进行异或,可以保证每个线程有独立的随机数序列。
- 并行化效果和性能:通过将计算任务分配给多个线程进行并行计算,可以加速计算过程。对于大规模的计算和复杂的任务,合理利用并行计算可以显著提高计算效率。通过使用OpenMP进行并行化计算,可以简化并行计算的实现,并提高代码的可读性和维护性。
- 局部变量和局部计算:在并行计算中,每个线程都有自己的局部计数器
count,用于存储局部计算的结果。这样可以避免不同线程之间的数据竞争问题,保证计算的正确性。通过合理使用局部变量,可以提高并行计算的效率和可靠性。 - 函数返回值:
calculatePi函数使用double类型的返回值,将计算得到的Pi的近似值返回给调用者。通过函数返回值的方式,可以方便地传递计算结果,让调用者可以进一步处理或输出。函数返回值的使用可以提高代码的可读性和灵活性。 - 输出结果:通过
printf函数打印计算得到的Pi近似值。使用格式化字符串%.15f控制小数位数,以便输出更精确的结果。
函数使用技巧
- 并行计算指令:使用OpenMP指令来并行化计算过程。通过
#pragma omp parallel指令创建并行区域,在该区域内的代码将在多个线程中并行执行。使用#pragma omp for指令将for循环并行化执行,让多个线程同时处理不同的迭代。使用reduction(+:count)指令将每个线程的局部计数器count进行求和操作,以获得最终的总和。这样可以充分利用多个线程进行并行计算,提高计算效率。 - 随机数生成:在并行计算中,每个线程都需要生成随机数。为了确保每个线程生成独立的随机数序列,使用了线程编号和时间种子的异或运算来设置每个线程的随机数种子。这样可以保证每个线程生成不同的随机数序列,避免了随机数生成的冲突和重复。
- 并行化效果和性能:通过将计算任务分配给多个线程进行并行计算,可以加速计算过程。并行计算的效果和性能受多个因素影响,包括线程数量、任务负载平衡和通信开销等。通过合理调整并行化策略和资源配置,可以提高并行计算的效率和性能。
- 局部变量和局部计算:在并行计算中,每个线程都有自己的局部计数器
count,用于存储局部计算的结果。这样可以避免不同线程之间的数据竞争和冲突,确保计算的正确性和一致性。使用局部变量和局部计算可以提高并行计算的效率和可靠性。 - 函数返回值:
calculatePi函数使用double类型的返回值,将计算得到的Pi的近似值返回给调用者。通过函数返回值的方式,可以方便地传递计算结果,并在调用端进行后续处理或输出。函数返回值的使用可以提高代码的可读性和灵活性。 - 随机数种子:每个线程使用不同的随机数种子来生成独立的随机数序列。在代码中,使用线程编号和时间种子的异或运算来设置每个线程的随机数种子。这样可以保证每个线程生成不同的随机数序列,避免了随机数生成的冲突和重复。
容易出错的地方
- 并行计算的正确性:并行化计算涉及到多个线程同时执行任务,需要确保并行计算的正确性。在并行计算中,要注意共享变量的访问和修改,以及数据竞争和并发访问的问题。特别是在计算
count时,使用了reduction操作来确保并行计算的正确性。但仍然需要注意并行计算引入的潜在错误。 - 随机数生成的均匀性:蒙特卡洛方法的准确性受到随机数生成的均匀性影响。在并行计算中,每个线程都需要生成随机数,需要确保生成的随机数具有均匀性。如果随机数生成不均匀,可能导致计算结果的偏差。
- 并行性能:并行计算的性能不仅取决于代码的并行化策略,还取决于计算资源的分配和负载平衡。如果线程数量过多或过少,或者任务负载不均衡,可能会导致并行计算的性能下降。需要对并行化的策略和资源配置进行合理的调整。
- 随机数种子的设置:每个线程使用不同的随机数种子来生成独立的随机数序列。在代码中,使用线程编号和时间种子的异或运算来设置每个线程的随机数种子。需要确保随机数种子的设置是正确的,以确保每个线程生成独立的随机数序列。
- 输出结果的格式:通过
printf函数打印计算得到的Pi的近似值。需要注意输出结果的格式化和精度,以确保输出的结果符合预期并具有可读性。
并行计算的优势:在本次实验中,我使用了OpenMP库来实现多线程并行计算。通过将任务分配给多个线程并行执行,我能够显著提高计算效率。并行计算可以利用多核处理器的优势,将计算任务分解成更小的子任务,同时进行处理,从而加速整体计算过程。
数值积分的应用:本次实验中采用了数值积分的方法来近似计算π的值。数值积分是一种重要的数值计算技术,广泛应用于科学、工程和计算领域。通过将曲线分割成小区间,近似计算每个小区间的面积并将其累加,我们可以得到整个曲线下的面积近似值。这种方法在实际问题中具有广泛的应用,可以有效地处理复杂的数学问题。
近似算法的精度与效率权衡:在本次实验中,我使用矩形法来近似计算π的值。虽然矩形法是一种简单且易于实现的方法,但它的精度相对较低。在实际应用中,我们需要根据需求权衡精度和计算效率。如果需要更高的精度,可能需要使用更复杂的数值积分方法或增加计算资源。因此,在实际问题中,我们需要根据具体情况选择适当的算法和方法。
实践与理论的结合:本次实验使我将在学习中获得的理论知识应用到实际问题中。通过编写代码并进行实验,我更深入地理解了数值积分和并行计算的原理和实现方式。实践中遇到的挑战和问题也促使我加深对相关概念和技术的理解,并通过调试和改进代码来提高程序的正确性和性能。
总的来说,本次实验使我对并行计算和数值积分有了更深入的了解。通过实践和实验,我进一步掌握了并行计算的原理和技巧,以及数值积分的应用方法。这些经验将对我的学习和进一步的研究工作有所帮助,并为解决实际问题提供了有用的工具和思路。


















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









