




模型部署RV11126的流程大致为:训练得到.pth模型、pth2onnx、onnx2rknn,最后在边缘计算设备上完成部署,本文旨在为零基础的初学者,训练所需模型提供一些借鉴。
一、所需条件
有以下两个条件之一即可:
- GPU:pc自带
- CPU:显卡(实验室提供或自购)
二、代码检索
开源代码,可以在github上进行检索(最好打开vpn),网站如下:
GitHub · Build and ship software on a single, collaborative platform · GitHub
在搜索框中,搜索想要训练的代码,就会出现各种相关项目: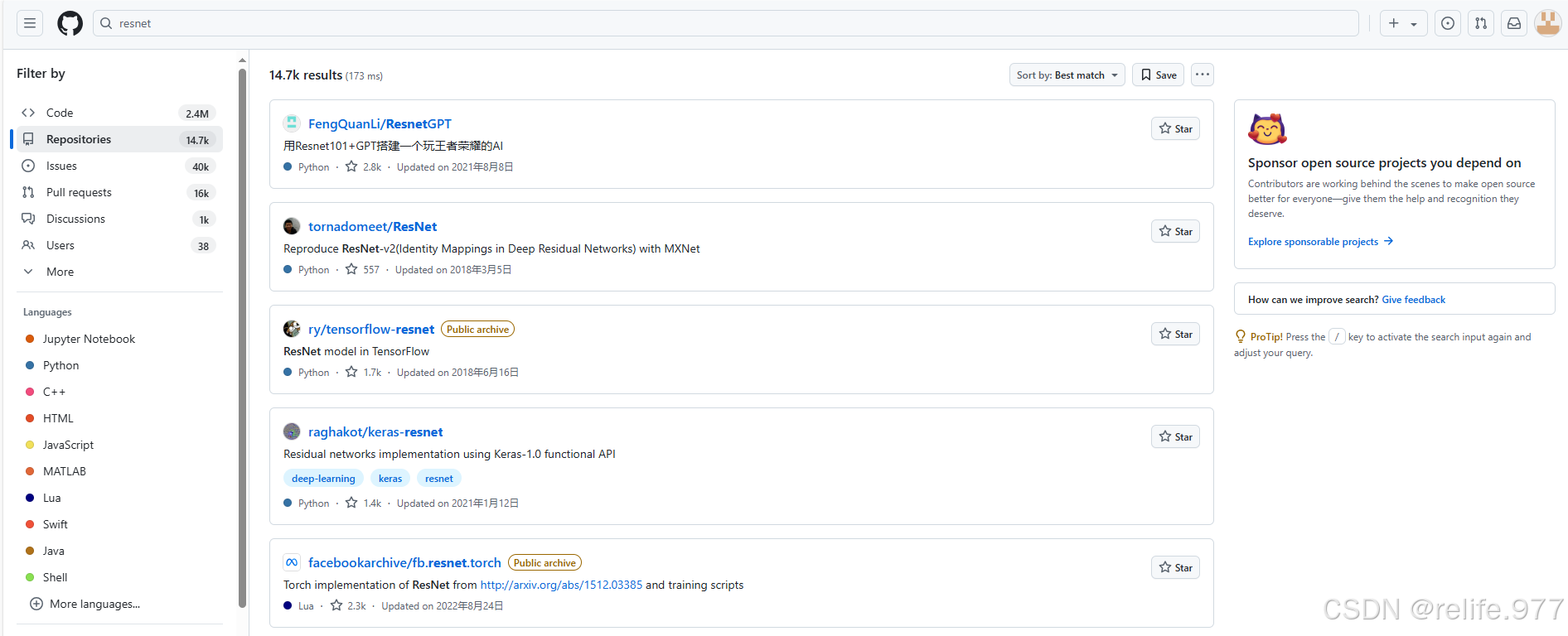
下载需要的项目后,在pycharm、vscode自己喜欢的ide中打开,进行训练。
三、训练步骤
以手写数字识别为例,参考:
基于卷积神经网络的手写数字识别(附数据集+完整代码+操作说明)-优快云博客
(1)安装anaconda3,并创建环境:

打开cmd(命令提示符)conda create -n 设置的环境名字 python=X.X
conda create -n hand_written python=3.8 //创建环境
activate hand_written //进入激活的环境
conda list //查看安装的文件信息
deactivate //退出环境(2)下载相应的下载相应的pytorch,cuda与cudnn版本(本项目不需要cuda、cudnn)
下载链接:
查询cuda对应版本:
如何判断自己的电脑里有没有cuda以及查看cuda版本-优快云博客
pytorch下载链接:
Previous PyTorch Versions | PyTorch
查看自己显卡适合的cuda与cudnn版本并下载:
GPU驱动、CUDA和cuDNN之间的版本匹配与下载_cudacudnn配对-优快云博客
(3)下载手写数字识别的代码以及数据集等,放置于相应文件夹中
下载链接:
Hurri-cane/Hand_wrtten at master (github.com)
2、下载pycharm,打开下载好的文件包
下载链接:
Download PyCharm: The Python IDE for data science and web development by JetBrains
新建项目,打开下载的对应文件:
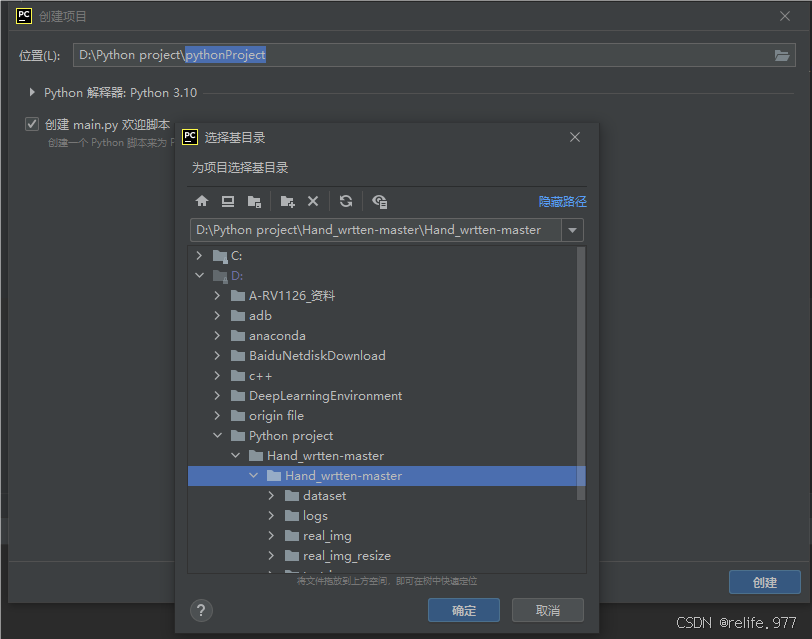
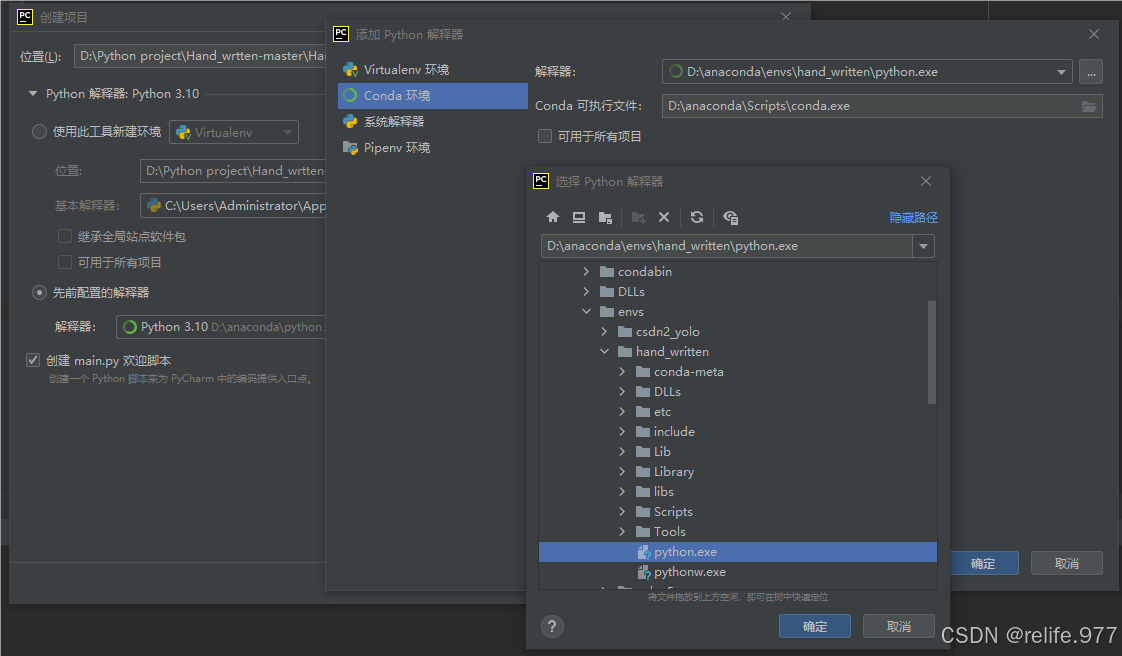
选择配置好的环境,然后创建:
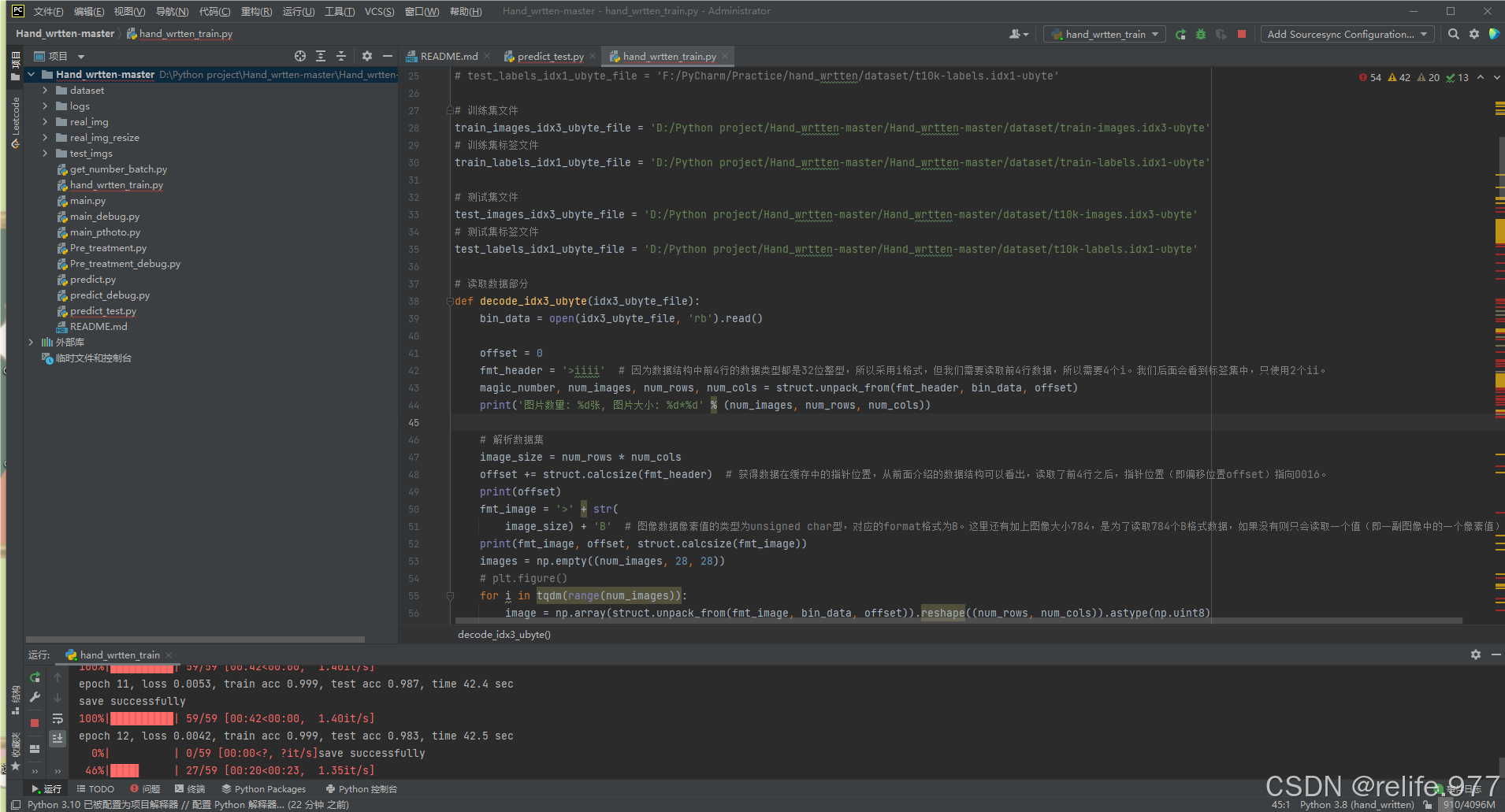
运行hand_written_train.py,在此过程中在终端用pip install命令配置好相关文件并修改数据集路径,最终进行训练:(main_pthoto.py、predict.py、main.py等文件中的路径也需要修改)
四、pth文件
.pth文件为训练之后模型的保存形式之一,也可以保存为.pth.tar,代码示例片段如下:
个人建议保存为pth即可,便后续onnx的转化。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









