




目录
本期我们将学习C++11中线程库相关的知识。
线程库
之前,在学习Linux时,我们已经学习过了线程库的概念,我们在Linux中使用的是Pthread线程库。在C++11中我们也引入了线程库的概念,不过C++11中的线程库是被封装在了一个thread的类里。


通过查看C++文档不难发现,thread线程对象可以调用无参构造创建,但是创建之后不进行任何操作,同时thread线程对象,不允许被拷贝构造生成,但是允许移动构造生成,通过thread线程对象不允许调用赋值运算符重载进行赋值,但是可以调用移动赋值进行赋值。
情景:创建一个全局变量,使得两个线程对其进行++操作。
代码如下。
int x = 0;
void handle(int n)
{
for (int i = 0; i < n; i++)
{
++x;
}
}
int main()
{
thread t1(handle,5000);
thread t2(handle,5000);
t1.join();
t2.join();
cout << x << endl;
return 0;
}运行结果如下。

两个线程分别对全局变量x,++5000次,最终打印出来的x的值是10000,貌似结果也没有什么问题,如果我们让每个线程都对x,++50000次呢?

按道理说此事的x应该是100000,但是打印出来的结果却是55330,很明显这出了问题,我们称之为线程安全问题,为什么会出现这种问题呢?其实在Linux系统编程中我们已经遇到了类似的问题,这是因为++操作分为三步,第一步,将寄存器中的x的值拿出来;第二步,CPU对x进行++操作;第三步,将++之后的x值放回寄存器,最后由操作系统将最终寄存器的值加载到内存中。 正是因为有了这三步,就增加了风险的概率,第一个线程加x值++之后还没有来的急放回寄存器,第二个线程就又对寄存器中的值进行了++,并且最终将++之后的x值返回到了寄存器中,并且更新到了内存中,此时第一个线程又将++之后的x的值放回寄存器,更新到了内存中,所以此时可能两次++操作,但是内存中x的值,只被++了一次。
互斥锁
怎么解决这样的线程安全问题呢?我们引入了互斥锁的概念,C++中也是有互斥锁的,文档如下。

所以我们就要对++操作进行加锁,但是问题又来了我们是加到for循环内部还是for循环外部呢?
我们建议将锁加在for循环的外面。


为什么要加在for循环的外面呢?
我们先简单分析一下,如果锁加在了for循环的外面,其实两个线程是串行运行的,如果锁加在了for循环的内部,其实两个线程是并行运行的,所以按照道理来说,应该是锁加在for循环内部效率更高,为什么还要加在for循环外呢?
这是因为虽然锁加在了内部是一个并行处理的过程,但是锁只有一把,当一把锁被一个线程占用时,另一个线程就只能被放入阻塞队列中去等待锁资源,与此同时操作系统要保存当前线程的上下文,当前线程获取到了锁资源时,就会从阻塞队列中剥离出来,然后操作系统会恢复其上下文,然后当前线程再去执行。正是因为如此,操作系统对上下文的保存和恢复也是需要耗费时间的,大量的加锁和解锁就意味着多次的上下文的保存和恢复,会去耗费额外大量的时间,所以我们推荐将锁加在for循环的外面。
原子操作
如果不使用锁,还有什么方法,可以避免上述隐患呢?
其实还有一种方法,就是原子操作。
先不使用原子操作,现在for循环外使用锁,我们查看代码的运行时间。
int main()
{
//atomic<int> x = 0;
int x = 0;
mutex mt;
int costime = 0;
thread t1([&x, &mt,&costime](int n)
{
int begin1 = clock();
mt.lock();
for (int i = 0; i < n; i++)
{
++x;
}
mt.unlock();
int end1 = clock();
costime += end1 - begin1;
},50000000);
thread t2([&x, &mt,&costime](int n)
{
int begin2 = clock();
mt.lock();
for (int i = 0; i < n; i++)
{
++x;
}
mt.unlock();
int end2 = clock();
costime += end2 - begin2;
}, 50000000);
t1.join();
t2.join();
cout<< x << endl;
cout << costime << endl;
return 0;
}运行结果如下。

不难发现,代码的运行时间没293毫秒。
如果我们使用原子操作,代码如下。
int main()
{
atomic<int> x = 0;
mutex mt;
int costime = 0;
thread t1([&x, &mt,&costime](int n)
{
int begin1 = clock();
for (int i = 0; i < n; i++)
{
++x;
}
int end1 = clock();
costime += end1 - begin1;
},50000000);
thread t2([&x, &mt,&costime](int n)
{
int begin2 = clock();
for (int i = 0; i < n; i++)
{
++x;
}
int end2 = clock();
costime += end2 - begin2;
}, 50000000);
t1.join();
t2.join();
cout<< x << endl;
cout << costime << endl;
return 0;
}运行结果如下。

虽然还是和加锁有差异,但是也是一种不错的避免加锁而实现线程安全的方法。
锁的进阶
情景:创建一个vector,两个线程分别往vector中插入元素,其中一个线程插入1000以上的数,总共插入1000个数。另一个线程插入2000以上的数,总共插入1000个数。
代码如下。
void func(vector<int>& v, int n, int base,mutex& mt)
{
for (int i = 0; i < n; i++)
{
mt.lock();
v.push_back(i + base);
mt.unlock();
}
}
int main()
{
vector<int> v;
mutex mt;
thread t1(func,ref(v),1000,1000,ref(mt));
thread t2(func,ref(v),1000,2000,ref(mt));
t1.join();
t2.join();
for (auto e : v)
{
cout << e << " ";
}
}运行结果如下。

加了互斥锁之后,我们也实现了对应元素的插入,但是上述代码是有一个严重的问题的,因为在加锁之后,vector的push_back操作是会出错抛异常的,异常知识我们 下期会讲到,此时我们只需要记得,一旦push_back操作抛出了异常,当我们捕获并处理异常时,push_back操作之后的解锁代码就不会再被执行。无法再解锁,这就造成了当前线程的死锁问题,这会导致另一个线程无法获取锁资源,造成线程饥饿问题。
为了解决这一问题,我们可以在捕获异常时进行解锁,但是这样子代码执行效率会被降低。因此我们又引入了两个锁,unique_lock和lock_guard,图示如下。

为了方便理解,我们模拟实现一下lock_guard。
template<class Lock>
class LockGuard
{
public:
LockGuard(Lock& lock)
:_lock(lock)
{
_lock.lock();
}
~LockGuard()
{
_lock.unlock();
}
private:
Lock& _lock;
};
unique_lock锁的模拟实现也是类似的,不过会多了些lock()和unlock()这些功能,因为也有可能在在代码的执行过程中有加锁完之后又解锁的场景。调整后的代码如下。
void func(vector<int>& v, int n, int base,mutex& mt)
{
for (int i = 0; i < n; i++)
{
LockGuard<mutex> lockguard(mt);
v.push_back(i + base);
//按道理我们会在这个里面捕获异常,但是由于异常知识下期讲解
//只需记住,一旦抛出了异常去处理异常,就会跳出这个for循环
//一旦跳出for循环,那么lockguard这个局部对象就会去调用析构函数
//最终解锁,也就意味着不会因为异常而导致死锁问题
}
}
当我们使用了LockGuard锁之后,就算最后出现了异常,就算之后的解锁代码不会执行,但是一旦抛出了异常,线程就会去捕获异常,捕获了异常就意味着出了for循环函数体的作用域,也就意味着LockGuard对象的声明周期结束,就会去调用其析构函数,最终解锁,不会导致死锁问题。
总的来说,unique_lock和lock_guard解决的就是死锁的问题。
条件变量
情景:有两个线程,第一个线程打印奇数,第二个线程打印偶数,两个线程交替打印,一次打印一个数。
第一种方法,采用互斥锁的方式进行,代码如下。
int main()
{
int n = 0;
int x = 2000;
mutex mt;
thread t1([&] {
while (n < 2000)
{
unique_lock<mutex> lock(mt);
cout << this_thread::get_id() << ":" << n << endl;
n++;
}
});
thread t2([&] {
while (n < 2000)
{
unique_lock<mutex> lock(mt);
cout << this_thread::get_id() << ":" << n << endl;
n++;
}
});
t1.join();
t2.join();
return 0;
}运行结果如下。

通过运行结果我们不难发现,明显不符合我们的预期,我们要求的是两个线程交替打印,但是我们的运行结果却是一个线程打印一会儿奇数和偶数,另一个线程有打印一会奇数和偶数。
这些是因为什么呢?
这是因为,每个线程运行时都有时间片(可以理解为线程占用cpu资源的时间),当第一个线程打印完偶数之后,因为其时间片还没有用完,所以会继续的进行打印,直到自己的时间片用完之后,第二个线程才会去进行打印。
那么有没有什么方法,去解决这个时间片问题和线程安全问题呢?有,就是条件变量。

这个conditon_variable重要的接口就是wait和notify_one和notify_all,这三个接口,第一个接口用于某个线程的阻塞,阻止这个线程运行,notify_one和notify_all用于唤醒一个和多个线程。
我们重点关注wait这个接口。
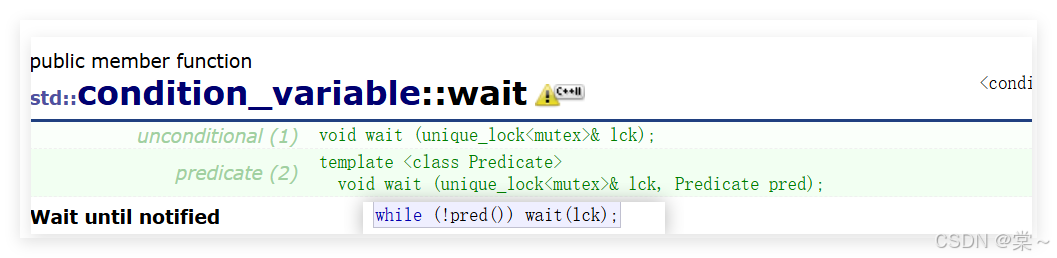
一般情况下使用地个人wait函数模板接口,这个函数模板的第一个参数为unique_lock锁,第二个参数为一个可调用对象,当可调用对象为false时,就阻塞当前线程,如果可调用对象是true,则不阻塞当前线程,阻塞线程时,如果加锁了会自动解锁。
我们对代码进行改造。
int main()
{
int n = 0;
int x = 2000;
mutex mt;
condition_variable cv;
bool flag = false;
thread t1([&] {
unique_lock<mutex> lock(mt);
while (n < 2000)
{
cv.wait(lock, [&] {
return !flag;
});
cout << this_thread::get_id() << ":" << n << endl;
n++;
flag = !flag;
cv.notify_one();
}
});
thread t2([&] {
unique_lock<mutex> lock(mt);
while (n < 2000)
{
cv.wait(lock, [&] {
return flag;
});
cout << this_thread::get_id() << ":" << n << endl;
n++;
flag = !flag;
cv.notify_one();
}
});
t1.join();
t2.join();
return 0;
}
运行结果如下。
我们发现,使用条件变量实现了两个线程交替打印奇数和偶数的功能,运行结果符合预期。
小tips:今后编程遇到多线程的处理场景,因为当今的计算机一般情况下都是多核,所以我们在处理多线程的场景时,一定要想着多线程是并行运行的。这对于理解时间片下多线程的运行原理分析是很有帮助的。
以上便是多线程的所有内容。
本期内容到此结束^_^



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











