



Hive的数据导入与导出
Hive导入数据有以下三种情况:
从本地系统linux导入数据
从hdfs导入数据
从查询操作的结果导入数据,可以是单表查询,也可以是多表查询结果
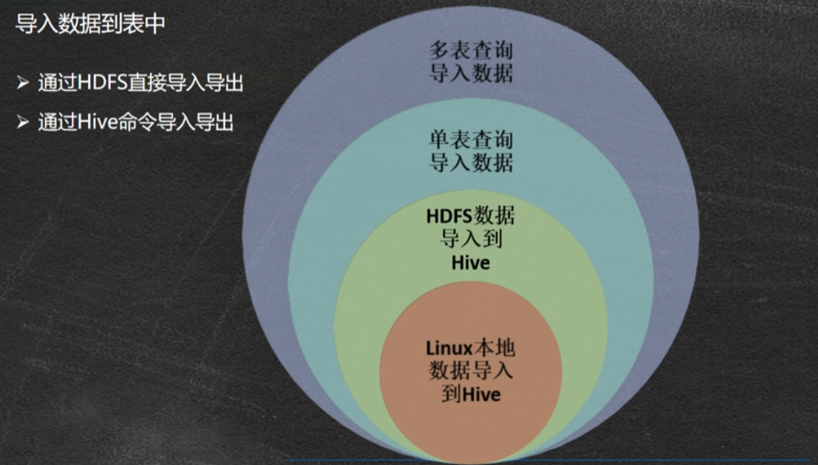
数据导入hive语法:

Hive导入数据的方法:
命令:load data local inpath '/opt/train.csv' overwrite into table tidanic;
从hdfs导入数据的方法:

hive> load data local inpath '/opt/train.csv' overwrite into table tidanic;
Loading data to table taitan.tidanic
OK
Time taken: 3.273 seconds
hive> dfs -rm -r /user/hive/warehouse/taitan.db/tidanic/train.csv
> ;
Deleted /user/hive/warehouse/taitan.db/tidanic/train.csv
hive> dfs -put /opt/train.csv /user/root;
hive> load data inpath '/user/root/train.csv' overwrite into table tidanic;
Loading data to table taitan.tidanic
OK
Time taken: 2.119 seconds
hive>
Hive查询
Hive查询语言(HiveQL)是一种查询语言,Hive处理在Metastore分析结构化数据。
SELECT语句用来从表中检索的数据。 WHERE子句中的工作原理类似于一个条件。它使用这个条件过滤数据,并返回给出一个有限的结果。内置运算符和函数产生一个表达式,满足以下条件。

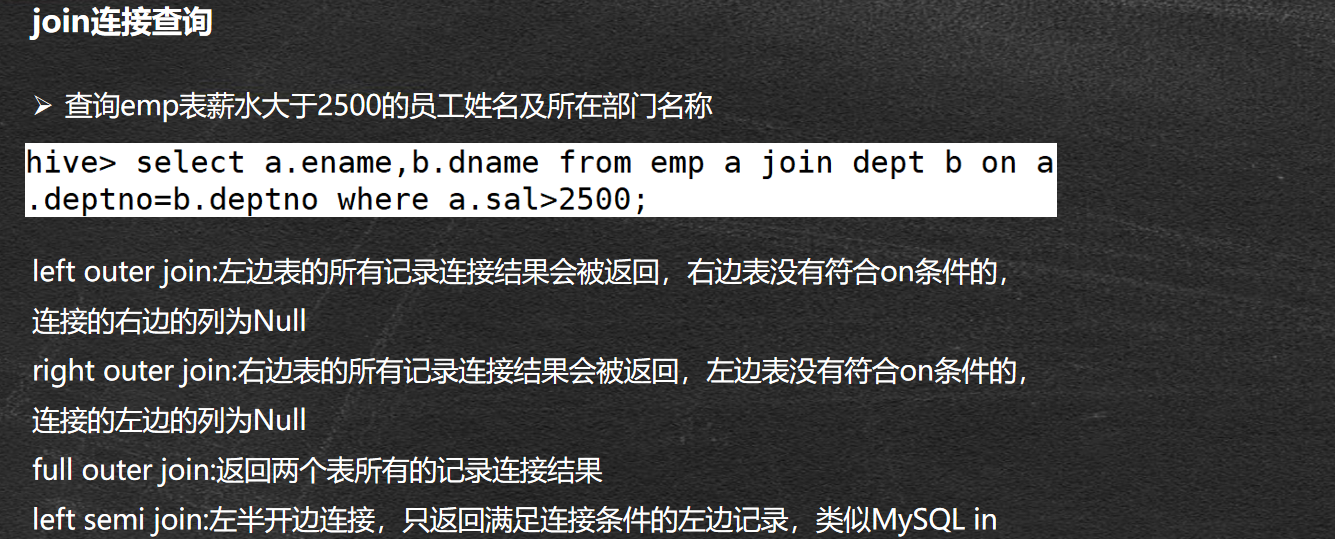
查询操作实例:
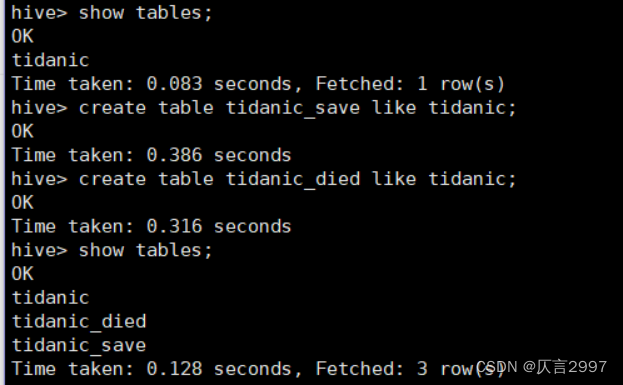
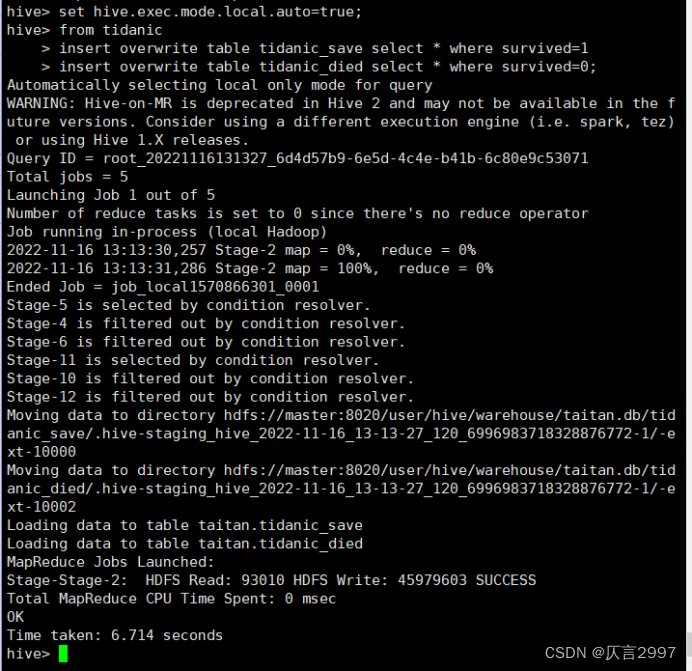
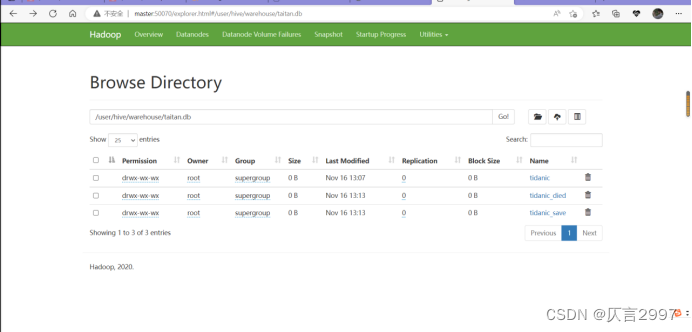
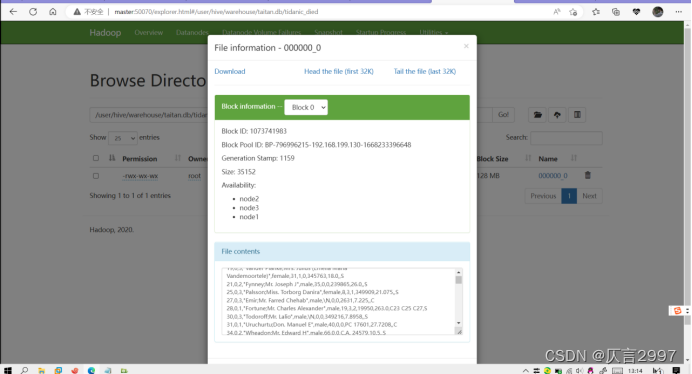
上传tidanic_save到虚拟机下面:
insert overwrite local directory '/opt/tidanic_save' row format delimited fields terminated by ',' select * from tidanic_save; 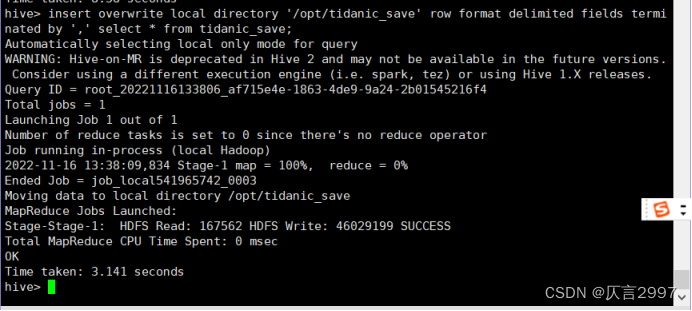
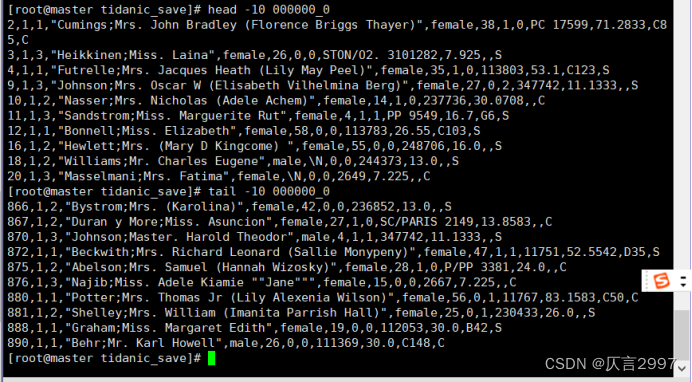
[root@master tidanic_save]# head -10 000000_0
[root@master tidanic_save]# tail -10 000000_0
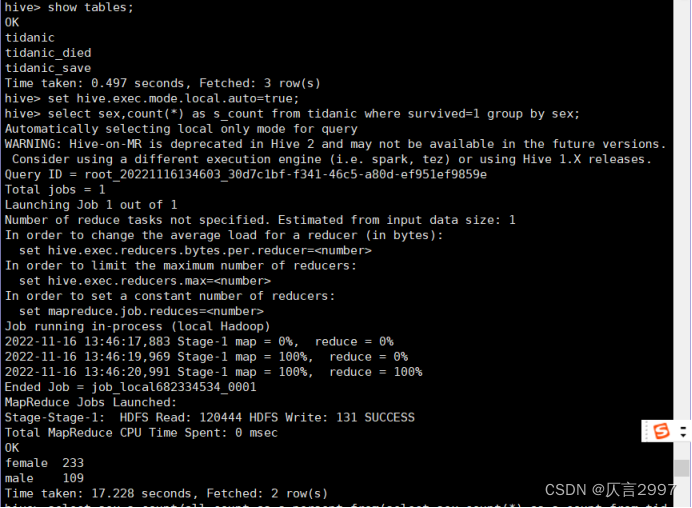
统计female和male的人数
命令:select sex,count(*) as s_count from tidanic where survived=1 group by sex;
命令:set hive.mapred.mode=nonstrict;
命令:set hive.exec.mode.local.auto=true;
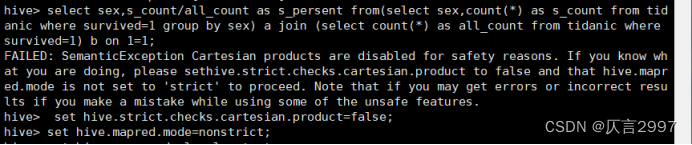
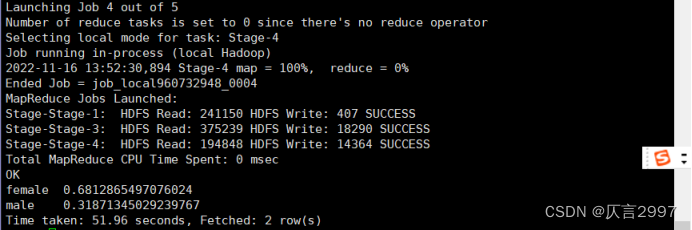
1、统计性别与生存率的关系
命令: select sex,s_count/all_count as s_persent from(select sex,count(*) as s_count from tidanic where survived=1 group by sex) a join (select count(*) as all_count from tidanic where survived=1) b on 1=1;
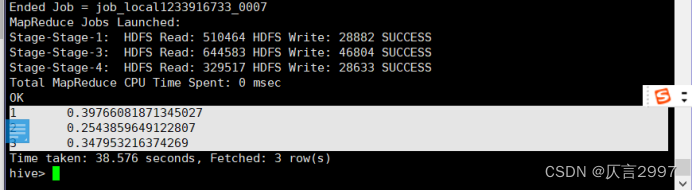
2、统计客舱等级与生存率的关系
命令:select pclass,s_count/all_count as s_persent from(select pclass,count(*) as s_count from tidanic where survived=1 group by pclass) a join (select count(*) as all_count from tidanic where survived=1) b on 1=1;
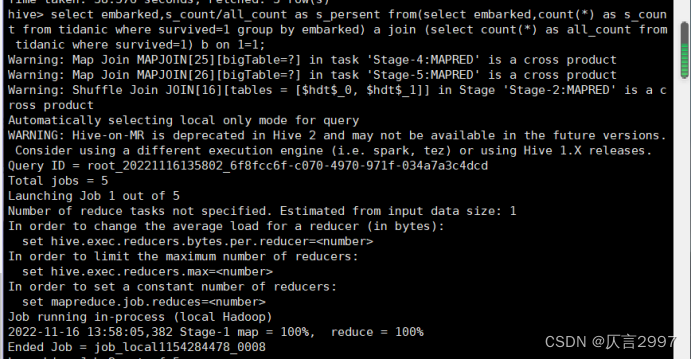
3、统计登船港口与生存率的关系
命令:select embarked,s_count/all_count as s_persent from(select embarked,count(*) as s_count from tidanic where survived=1 group by embarked) a join (select count(*) as all_count from tidanic where survived=1) b on 1=1;
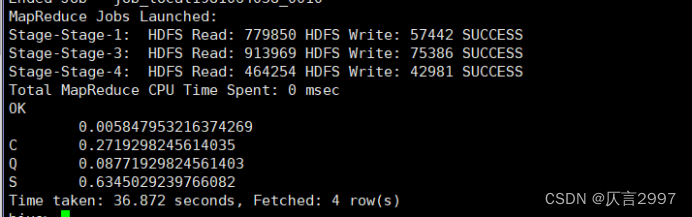

















 1374
1374


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








