




- 文章题目:Robust knowledge distillation based on feature variance against backdoored teacher model
- code: https://github.com/Xming-Z/RobustKD.git
背景知识
随着深度神经网络(DNNs)的广泛应用,模型压缩技术如知识蒸馏(KD)变得尤为重要,尤其是在资源受限的边缘设备上。知识蒸馏通过从一个训练有素的教师模型中提取知识来训练一个轻量级的学生模型。然而,如果教师模型被植入了后门,这些后门可能会在知识蒸馏过程中传递给学生模型。尽管已有多种知识蒸馏方法被提出,但大多数方法都未考虑鲁棒性,即如何在教师模型被攻击的情况下仍能保持学生模型的性能。
文章提出的RobustKD方法为知识蒸馏在面对后门攻击时提供了一种有效的防御手段,同时保持了模型压缩的效率和学生模型的性能。这对于在资源受限的设备上部署大型模型具有重要意义,尤其是在第三方模型平台的安全性无法保证的情况下。
研究方法
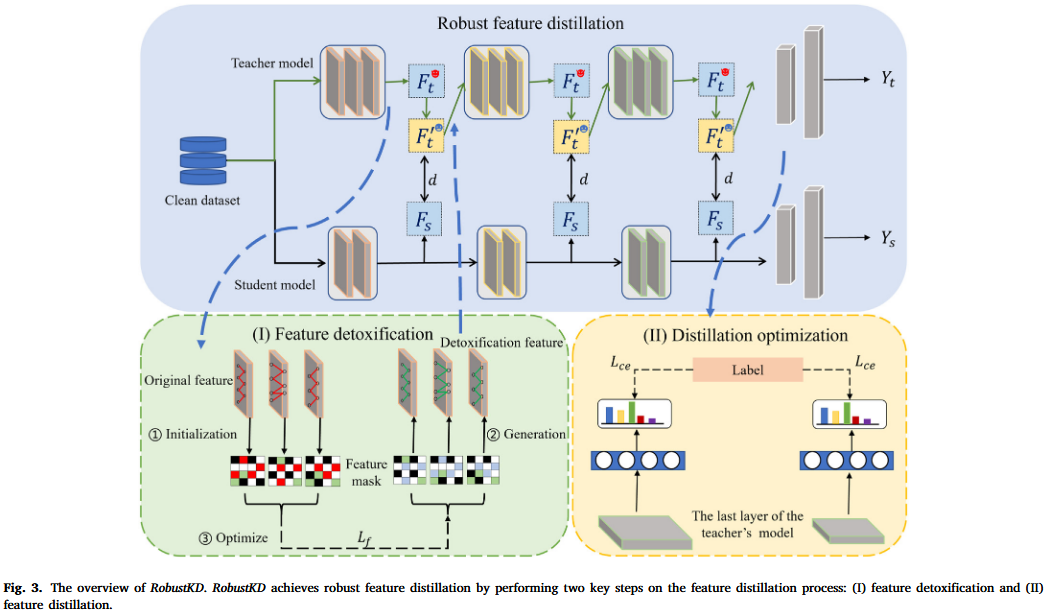
文章提出的RobustKD方法主要包含两个关键步骤:特征解毒(feature detoxification)和特征蒸馏(feature distillation)。
-
特征解毒:
-
特征初始化(Feature Initialization)
- 从干净数据集中选择特定数据 :选取干净数据集中的特定数据样本,将其输入教师模型,获取每层的输出特征。
- 使用这些输出特征作为初始化的特征掩码(feature mask) :将获取到的每层输出特征作为初始化的特征掩码。
- 初始化的特征掩码通过计算多个样本在每层的平均特征值来确定 :对多个样本在每层的特征值进行计算,取平均值,以此来确定初始化的特征掩码。
-
解毒特征生成(Detoxification Feature Generation)
通过将特征掩码与原始特征结合,生成解毒特征。解毒特征的生成公式为:
A i ′ = A i + α ⋅ m A_i' = A_i + \alpha \cdot m Ai′=Ai+α⋅m
其中, A i A_i Ai 是原始特征, m m m 是特征掩码, α \alpha α 是掩码阈值。-
解毒特征优化(Detoxification Feature Optimization)
-
设计一个解毒损失函数 :构建用于解毒的损失函数,目的是通过优化掩码阈值来最小化解毒特征的方差。 解毒损失函数定义为
$
L_{detox} = Var(A_i’)
$
其中, A i ′ A_i' Ai′ 是解毒后的特征。 -
通过迭代优化掩码阈值,直到达到最优的解毒效果 :不断迭代调整掩码阈值,使得解毒损失函数值最小,从而达到最优的解毒效果。
-
-
-
特征蒸馏:
- 使用解毒后的特征进行知识蒸馏,确保学生模型从教师模型中学习到干净的特征。
- 设计了一个交叉熵损失函数,结合了解毒后的特征和样本标签,以确保学生模型的性能。

实验
文章在四个数据集(CIFAR-100、GTSRB、ImageNet-1k、Flower-17)上进行了实验,使用了六种模型(WRN 16-2、WRN 16-4、WRN 28-2、WRN 28-4、ResNet 56、Pyramid-110、Pyramid-200)和两种蒸馏方法(FKD、RobustKD),以及两种后门攻击方法(CKD、LBA)。
基线比较
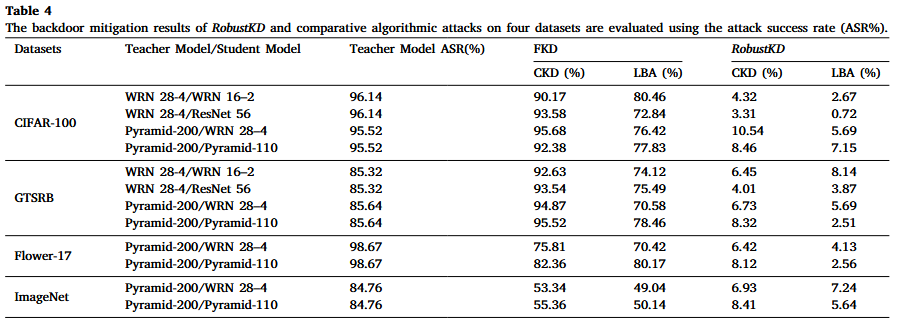
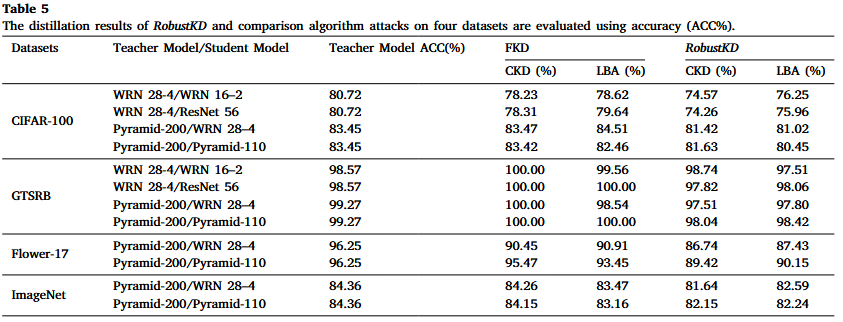
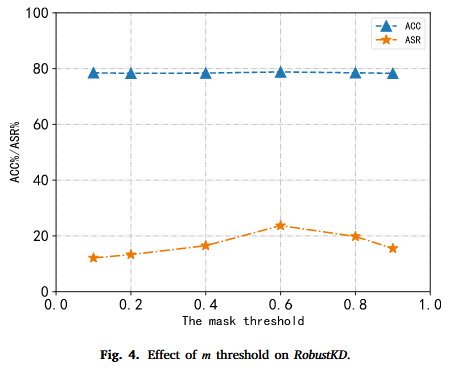
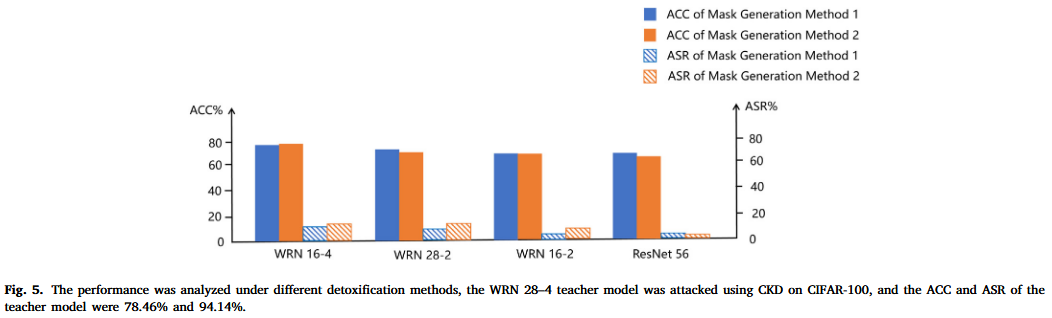
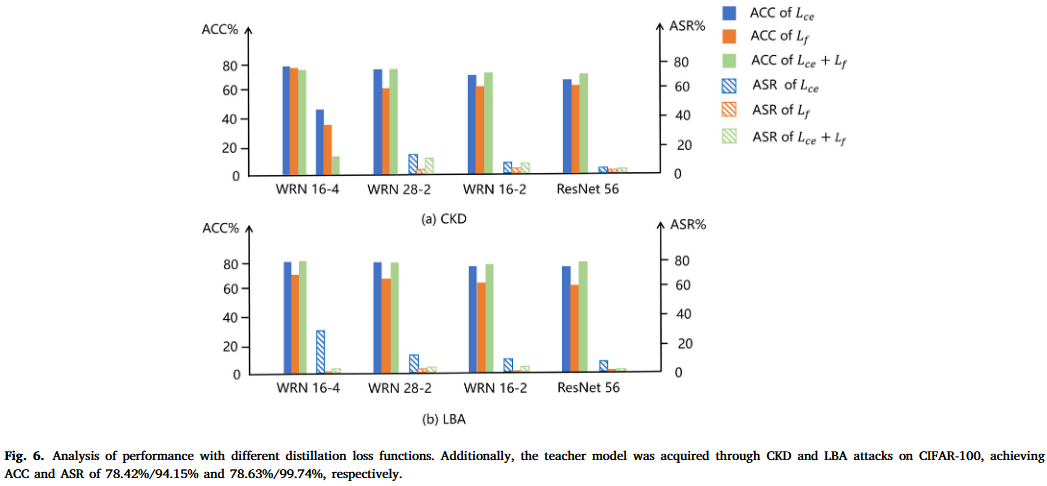
关键结论
- 鲁棒性:RobustKD在面对CKD和LBA攻击时,能够有效减轻后门攻击的影响,平均后门移除率达到85%,比现有方法提高了75%。
- 性能保持:尽管RobustKD在解毒过程中会带来一定的性能损失,但学生模型的主要任务性能与正常蒸馏方法相比仅下降了约3%。
- 参数敏感性:RobustKD对不同的掩码阈值和解毒方法表现出一定的鲁棒性,较小的掩码阈值有助于提高解毒效果。
- 蒸馏设置:使用更多的蒸馏层和适当的损失函数组合可以更有效地移除后门,同时保持模型性能。
- 适应性攻击防御:即使在适应性攻击下,RobustKD仍能移除75%的后门,显示出良好的鲁棒性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









