




实验一 numpy创建全连接神经网络
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, datasets, optimizers
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
# 准备数据
def mnist_dataset():
(x, y), (x_test, y_test) = datasets.mnist.load_data()
x = x / 255.0
x_test = x_test / 255.0
return (x, y), (x_test, y_test)
# 定义矩阵乘法类
class Matmul():
def __init__(self):
self.mem = {}
def forward(self, x, W):
h = np.matmul(x, W)
self.mem = {"x": x, "W": W}
return h
def backward(self, grad_y):
x = self.mem["x"]
W = self.mem["W"]
grad_x = np.matmul(grad_y, W.T)
grad_W = np.matmul(x.T, grad_y)
return grad_x, grad_W
# 定义Relu类
class Relu():
def __init__(self):
self.mem = {}
def forward(self, x):
self.mem["x"] = x
return np.where(x > 0, x, np.zeros_like(x))
def backward(self, grad_y):
x = self.mem["x"]
return (x > 0).astype(np.float32) * grad_y
# 定义Softmax类
class Softmax():
def __init__(self):
self.mem = {}
self.epsilon = 1e-12
def forward(self, x):
x_exp = np.exp(x)
denominator = np.sum(x_exp, axis=1, keepdims=True)
out = x_exp / (denominator + self.epsilon)
self.mem["out"] = out
self.mem["x_exp"] = x_exp
return out
def backward(self, grad_y):
s = self.mem["out"]
sisj = np.matmul(np.expand_dims(s, axis=2), np.expand_dims(s, axis=1))
g_y_exp = np.expand_dims(grad_y, axis=1)
tmp = np.matmul(g_y_exp, sisj)
tmp = np.squeeze(tmp, axis=1)
softmax_grad = -tmp + grad_y * s
return softmax_grad
# 定义交叉熵类
class Cross_entropy():
def __init__(self):
self.epsilon = 1e-12
self.mem = {}
def forward(self, x, labels):
log_prob = np.log(x + self.epsilon)
out = np.mean(np.sum(-log_prob * labels, axis=1))
self.mem["x"] = x
return out
def backward(self, labels):
x = self.mem["x"]
return -1 / (x + self.epsilon) * labels
# 建立模型
class myModel():
def __init__(self):
self.W1 = np.random.normal(size=[28*28+1, 100])
self.W2 = np.random.normal(size=[100, 10])
self.mul_h1 = Matmul()
self.relu = Relu()
self.mul_h2 = Matmul()
self.softmax = Softmax()
self.cross_en = Cross_entropy()
def forward(self, x, labels):
x = x.reshape(-1, 28*28)
bias = np.ones(shape=[x.shape[0], 1])
x = np.concatenate([x, bias], axis=1)
self.h1 = self.mul_h1.forward(x, self.W1)
self.h1_relu = self.relu.forward(self.h1)
self.h2 = self.mul_h2.forward(self.h1_relu, self.W2)
self.h2_soft = self.softmax.forward(self.h2)
self.loss = self.cross_en.forward(self.h2_soft, labels)
def backward(self, labels):
self.loss_grad = self.cross_en.backward(labels)
self.h2_soft_grad = self.softmax.backward(self.loss_grad)
self.h2_grad, self.W2_grad = self.mul_h2.backward(self.h2_soft_grad)
self.h1_relu_grad = self.relu.backward(self.h2_grad)
self.h1_grad, self.W1_grad = self.mul_h1.backward(self.h1_relu_grad)
# 计算准确率
def compute_accuracy(prob, labels):
predictions = np.argmax(prob, axis=1)
truth = np.argmax(labels, axis=1)
return np.mean(predictions == truth)
# 迭代一个epoch
def train_one_step(model, x, y):
model.forward(x, y)
model.backward(y)
model.W1 -= 1e-5 * model.W1_grad
model.W2 -= 1e-5 * model.W2_grad
loss = model.loss
accuracy = compute_accuracy(model.h2_soft, y)
return loss, accuracy
# 计算测试集上的loss和准确率
def test(model, x, y):
model.forward(x, y)
loss = model.loss
accuracy = compute_accuracy(model.h2_soft, y)
return loss, accuracy
# 实际训练
train_data, test_data = mnist_dataset()
train_label = np.zeros(shape=[train_data[0].shape[0], 10])
test_label = np.zeros(shape=[test_data[0].shape[0], 10])
train_label[np.arange(train_data[0].shape[0]), np.array(train_data[1])] = 1
test_label[np.arange(test_data[0].shape[0]), np.array(test_data[1])] = 1
model = myModel()
for epoch in range(50):
loss, accuracy = train_one_step(model, train_data[0], train_label)
print(f'epoch {epoch} : loss {loss} ; accuracy {accuracy}')
# 测试
loss, accuracy = test(model, test_data[0], test_label)
print(f'test loss {loss} ; accuracy {accuracy}')

实验二 Pytorch 的CNN
1.虚拟机右键:cd / 然后 jupyter notebook --allow-root
进入终端后
(1)切换根目录 cd /
(2) pip install torch==1.12.1+cu102 torchvision==0.13.1+cu102 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu102
(3)进入jupyter: jupyter notebook --allow-root
按住Ctrl点击出来的html
2.在/mnt/cgshare下新建一个Folder,修改名为project,在project下新建一个python3开始编写代码。
3.提交代码 :确保前一步已经正确的放置文件/mnt/cgshare/project/ 即可直接提交代码。
实验结果截图
import torch
from torch import nn
import torchvision
from torchvision import datasets, transforms
from tqdm import tqdm
# Hyper parameters
BATCH_SIZE = 100
EPOCHS = 10
LEARNING_RATE = 1e-4
KEEP_PROB_RATE = 0.7
# Set device to use
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Data transformation
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
# Download and load dataset
path = './data/'
train_data = datasets.MNIST(path, train=True, transform=transform, download=True)
test_data = datasets.MNIST(path, train=False, transform=transform)
# Create DataLoader
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=BATCH_SIZE)
# Define the CNN model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=7, padding=3, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(in_features=7*7*64, out_features=1024),
nn.ReLU(),
nn.Dropout(1 - KEEP_PROB_RATE),
nn.Linear(in_features=1024, out_features=10),
nn.Softmax(dim=1)
)
def forward(self, input):
output = self.model(input)
return output
net = Net()
net.to(device)
print(net)
# Define loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=net.parameters(), lr=LEARNING_RATE)
# Training and testing process
history = {'Test Loss': [], 'Test Accuracy': []}
for epoch in range(1, EPOCHS + 1):
process_bar = tqdm(train_loader, unit='step')
net.train(True)
for step, (train_imgs, labels) in enumerate(process_bar):
train_imgs = train_imgs.to(device)
labels = labels.to(device)
# Forward pass
outputs = net(train_imgs)
loss = loss_fn(outputs, labels)
# Backward pass and optimization
net.zero_grad()
loss.backward()
optimizer.step()
# Compute accuracy
predictions = torch.argmax(outputs, dim=1)
accuracy = torch.sum(predictions == labels) / labels.shape[0]
# Update progress bar
process_bar.set_description(f"[{epoch}/{EPOCHS}] Loss: {loss.item():.4f}, Acc: {accuracy.item():.4f}")
# Evaluate on test set
net.train(False)
correct = 0
total_loss = 0
with torch.no_grad():
for test_imgs, labels in test_loader:
test_imgs = test_imgs.to(device)
labels = labels.to(device)
outputs = net(test_imgs)
loss = loss_fn(outputs, labels)
total_loss += loss
predictions = torch.argmax(outputs, dim=1)
correct += torch.sum(predictions == labels)
test_accuracy = correct / (BATCH_SIZE * len(test_loader))
test_loss = total_loss / len(test_loader)
history['Test Loss'].append(test_loss.item())
history['Test Accuracy'].append(test_accuracy.item())
process_bar.set_description(
f"[{epoch}/{EPOCHS}] Loss: {loss.item():.4f}, Acc: {accuracy.item():.4f}, Test Loss: {test_loss.item():.4f}, Test Acc: {test_accuracy.item():.4f}"
)
process_bar.close()

实验三 RNN


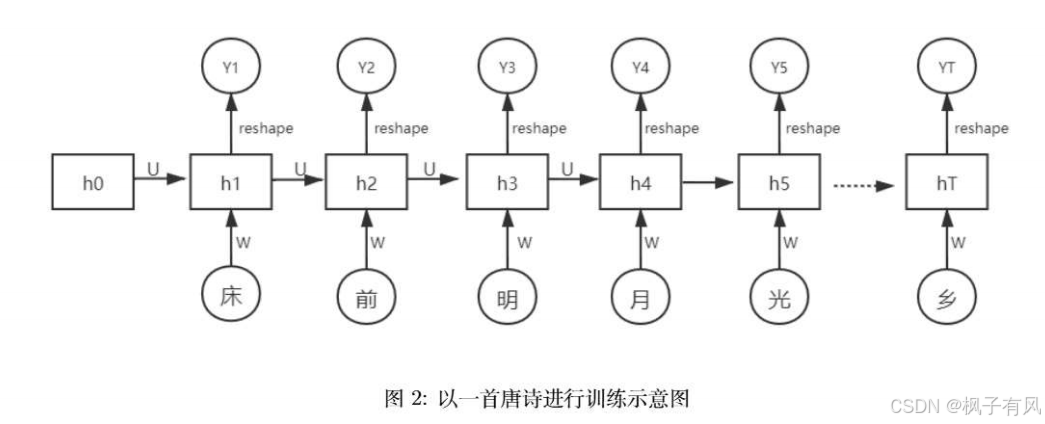
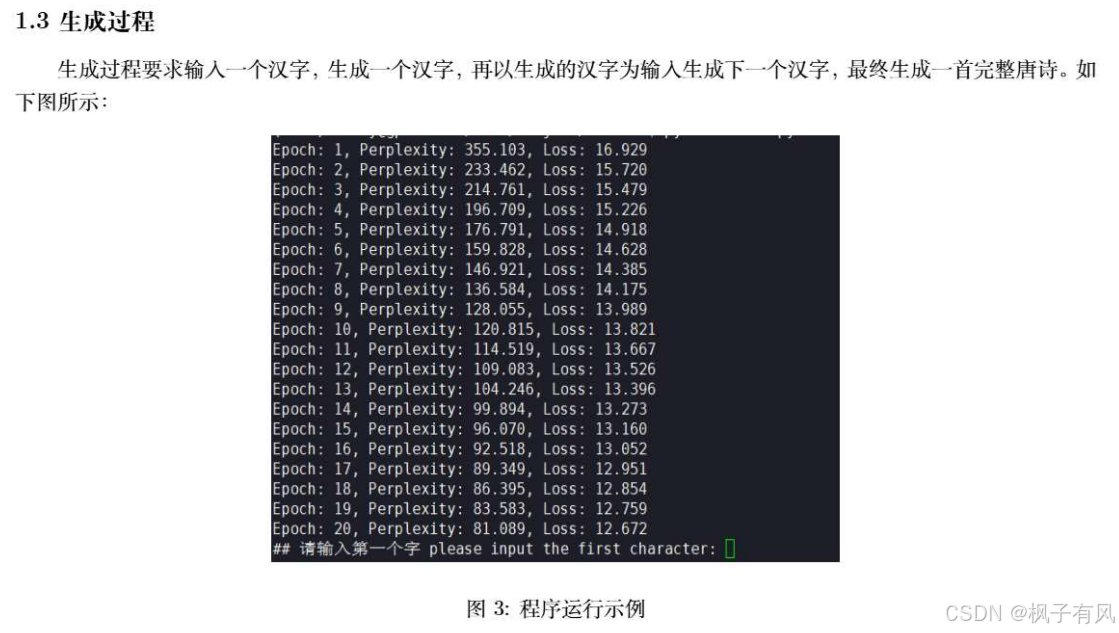

加载数据集
实验代码
import numpy as np
import re
import torch
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
# Hyperparameters
learning_rate = 1e-4
max_epoch = 20
batch_size = 128
use_gpu = True
# Load the poetry file
text_path = "./poetry.txt"
with open(text_path, 'r', encoding='utf-8') as f:
poetry_corpus = f.read()
# Clean the symbols in the poetry
poetry_corpus = poetry_corpus.replace('\n', '').replace('\r', '').replace('。', '').replace(',', '')
# Text to index conversion
class TextConverter(object):
def __init__(self, text_path, max_vocab=5000):
with open(text_path, 'r', encoding='utf-8') as f:
text = f.read()
text = text.replace('\n', '').replace('\r', '').replace('。', '').replace(',', '')
vocab = set(text)
vocab_count = {}
for word in vocab:
vocab_count[word] = 0
for word in text:
vocab_count[word] += 1
vocab_count_list = []
for word in vocab_count:
vocab_count_list.append((word, vocab_count[word]))
vocab_count_list.sort(key=lambda x: x[1], reverse=True)
if len(vocab_count_list) > max_vocab:
vocab_count_list = vocab_count_list[:max_vocab]
vocab = [x[0] for x in vocab_count_list]
self.vocab = vocab
self.word_to_int_table = {c: i for i, c in enumerate(self.vocab)}
self.int_to_word_table = {i: c for i, c in enumerate(self.vocab)}
@property
def vocab_size(self):
return len(self.vocab) + 1
def word_to_int(self, word):
if word in self.word_to_int_table:
return self.word_to_int_table[word]
else:
return len(self.vocab)
def int_to_word(self, index):
if index == len(self.vocab):
return '<unk>'
elif index < len(self.vocab):
return self.int_to_word_table[index]
else:
raise Exception("Unknown index")
def text_to_arr(self, text):
arr = []
for word in text:
arr.append(self.word_to_int(word))
return np.array(arr)
def arr_to_text(self, arr):
words = []
for index in arr:
words.append(self.int_to_word(index))
return ''.join(words)
# Initialize the text converter
convert = TextConverter(text_path, max_vocab=10000)
# Split the poetry file into sequences of length n_step
n_step = 20
num_seq = int(len(poetry_corpus) / n_step)
text = poetry_corpus[:num_seq * n_step]
arr = convert.text_to_arr(text)
arr = arr.reshape((num_seq, -1))
arr = torch.from_numpy(arr)
# Build the dataset
class TextDataset(object):
def __init__(self, arr):
self.arr = arr
def __getitem__(self, item):
x = self.arr[item]
y = torch.zeros(x.shape)
y[:-1], y[-1] = x[1:], x[0]
return x, y
def __len__(self):
return self.arr.shape[0]
train_set = TextDataset(arr)
# Build the model
class MyRNN(nn.Module):
def __init__(self, num_classes, embed_dim, hidden_size, num_layers, dropout):
super(MyRNN, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.word_to_vec = nn.Embedding(num_classes, embed_dim)
self.rnn = nn.RNN(embed_dim, hidden_size, num_layers, batch_first=True)
self.project = nn.Linear(hidden_size, num_classes)
def forward(self, x, hs=None):
batch = x.shape[0]
if hs is None:
hs = Variable(torch.zeros(self.num_layers, batch, self.hidden_size))
if use_gpu:
hs = hs.cuda()
word_embed = self.word_to_vec(x)
out, ho = self.rnn(word_embed, hs)
out = out.contiguous().view(-1, self.hidden_size)
out = self.project(out)
return out, ho
# Train the model
model = MyRNN(convert.vocab_size, 512, 512, 2, 0.5)
if use_gpu:
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
train_data = DataLoader(train_set, batch_size, shuffle=True, num_workers=4)
for e in range(max_epoch):
train_loss = 0
for data in train_data:
x, y = data
y = y.long()
if use_gpu:
x = x.cuda()
y = y.cuda()
x, y = Variable(x), Variable(y)
score, _ = model(x)
loss = criterion(score, y.view(-1))
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 5)
optimizer.step()
train_loss += loss.item()
print(f"Epoch: {e + 1}, Perplexity: {np.exp(train_loss / len(train_data)):.3f}, Loss: {train_loss / len(train_data):.3f}")
# Generate poetry
def pick_top_n(preds, top_n=3):
top_pred_prob, top_pred_label = torch.topk(preds, top_n, 1)
top_pred_prob /= torch.sum(top_pred_prob)
top_pred_prob = top_pred_prob.squeeze(0).cpu().numpy()
top_pred_label = top_pred_label.squeeze(0).cpu().numpy()
c = np.random.choice(top_pred_label, size=1, p=top_pred_prob)
return c
begin = input("Please input the first character: ")
text_len = 28
model.eval()
samples = [convert.word_to_int(c) for c in begin]
input_txt = torch.LongTensor(samples)[None]
if use_gpu:
input_txt = input_txt.cuda()
input_txt = Variable(input_txt)
init_state = None
result = samples
model_input = input_txt[:, -1].unsqueeze(1)
i = 0
while i < text_len - 2:
out, init_state = model(model_input, init_state)
pred = pick_top_n(out.data)
model_input = Variable(torch.LongTensor([pred[0]]))[None]
if use_gpu:
model_input = model_input.cuda()
if pred[0] != 0:
result.append(pred[0])
i += 1
text = convert.arr_to_text(result)
print(f"Output: {text}")
实验四 玉米基因表达式的预测
原理:
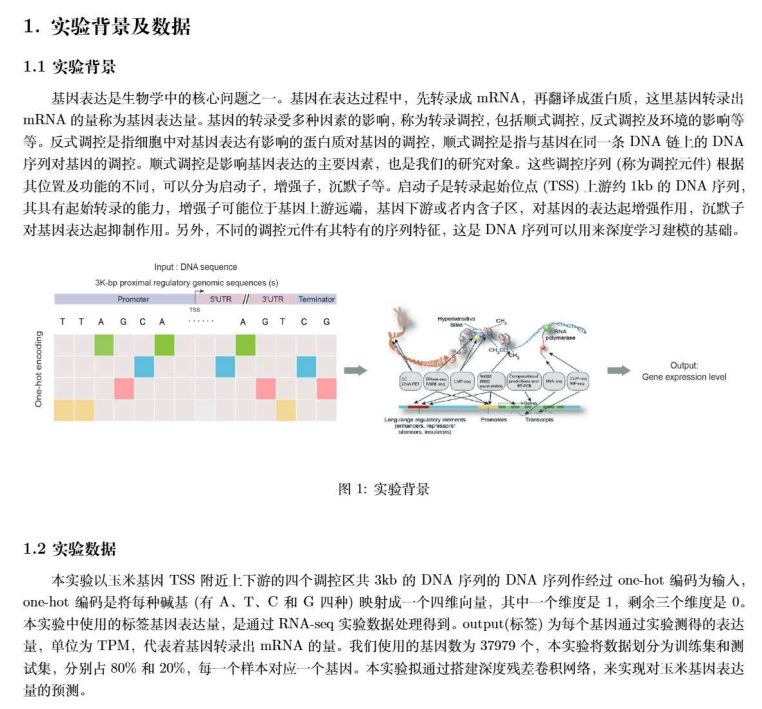

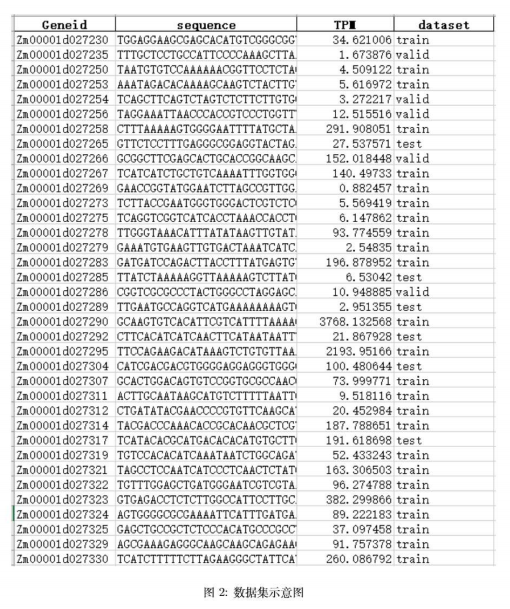
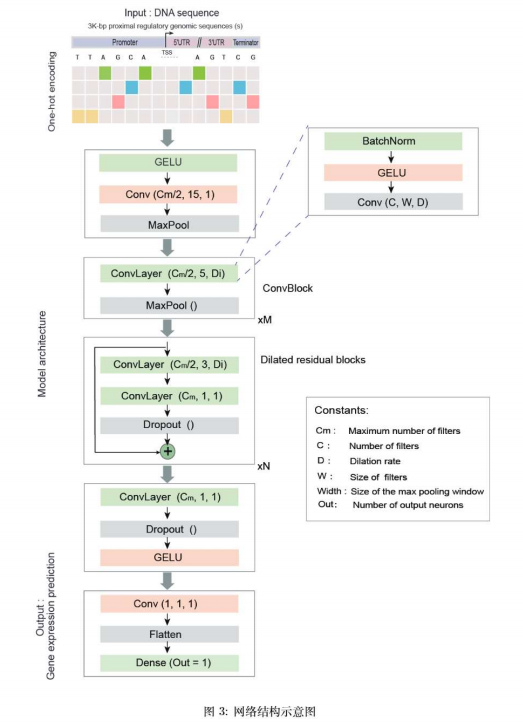
实验步骤同上:
需要先导入数据文件,然后运行下面的代码训练就行。
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
from torch import Tensor
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, ConcatDataset
import torch.nn.functional as F
from tqdm import tqdm
from scipy.stats import pearsonr
import matplotlib.pyplot as plt
from einops.layers.torch import Rearrange
from torchsummary import summary
def one_hot_encode_along_channel_axis(sequence):
to_return = np.zeros((4, len(sequence)), dtype=np.int8)
seq_to_one_hot_fill_in_array(zeros_array=to_return, sequence=sequence, one_hot_axis=0)
return to_return
def seq_to_one_hot_fill_in_array(zeros_array, sequence, one_hot_axis):
assert one_hot_axis == 0 or one_hot_axis == 1
if one_hot_axis == 0:
assert zeros_array.shape[1] == len(sequence)
elif one_hot_axis == 1:
assert zeros_array.shape[0] == len(sequence)
for i, char in enumerate(sequence):
if char == "A" or char == "a":
char_idx = 0
elif char == "C" or char == "c":
char_idx = 1
elif char == "G" or char == "g":
char_idx = 2
elif char == "T" or char == "t":
char_idx = 3
elif char == "N" or char == "n":
continue # leave that position as all 0's
else:
raise RuntimeError("Unsupported character: " + str(char))
if one_hot_axis == 0:
zeros_array[char_idx, i] = 1
elif one_hot_axis == 1:
zeros_array[i, char_idx] = 1
df = pd.read_excel('../dataset.xlsx')
print('genes number: ', df.shape[0])
df_train = df[df['dataset'] == 'train']
y_train = np.log2(df_train['TPM'].values + 1)
train_data = np.array([one_hot_encode_along_channel_axis(i.strip()) for i in df_train['sequence'].values])
df_valid = df[df['dataset'] == 'valid']
y_valid = np.log2(df_valid['TPM'].values + 1)
valid_data = np.array([one_hot_encode_along_channel_axis(i.strip()) for i in df_valid['sequence'].values])
df_test = df[df['dataset'] == 'test']
y_test = np.log2(df_test['TPM'].values + 1)
test_data = np.array([one_hot_encode_along_channel_axis(i.strip()) for i in df_test['sequence'].values])
class upd_GELU(nn.Module):
def __init__(self):
super(upd_GELU, self).__init__()
self.constant_param = nn.Parameter(torch.Tensor([1.702]))
self.sig = nn.Sigmoid()
def forward(self, input: Tensor) -> Tensor:
outval = torch.mul(self.sig(torch.mul(self.constant_param, input)), input)
return outval
class KerasMaxPool1d(nn.Module):
def __init__(
self,
pool_size=2,
padding="valid",
dilation=1,
return_indices=False,
ceil_mode=False,
):
super().__init__()
self.padding = padding
_padding = 0
if pool_size != 2:
raise NotImplementedError("MaxPool1D with kernel size other than 2.")
self.pool = nn.MaxPool1d(
kernel_size=pool_size,
padding=_padding,
dilation=dilation,
return_indices=return_indices,
ceil_mode=ceil_mode,
)
def forward(self, x):
if self.padding == "same" and x.shape[-1] % 2 == 1:
x = F.pad(x, (0, 1), value=-float("inf"))
return self.pool(x)
class Residual(nn.Module):
def __init__(self, module):
super().__init__()
self.module = module
def forward(self, x):
return self.module(x) + x
class ConvBlock(nn.Module):
def __init__(self, in_channels, filters, kernel_size=1, padding='same',
stride=1, dilation_rate=1, pool_size=1, dropout=0, bn_momentum=0.1):
super().__init__()
block = nn.ModuleList()
block.append(upd_GELU())
block.append(nn.Conv1d(in_channels=in_channels,
out_channels=filters,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=int(round(dilation_rate)),
bias=False))
block.append(nn.BatchNorm1d(filters, momentum=bn_momentum, affine=True))
if dropout > 0:
block.append(nn.Dropout(p=dropout))
if pool_size > 1:
block.append(KerasMaxPool1d(pool_size=pool_size, padding=padding))
self.block = nn.Sequential(*block)
self.out_channels = filters
def forward(self, x):
return self.block(x)
class ConvTower(nn.Module):
def __init__(
self,
in_channels,
filters_init,
filters_end=None,
filters_mult=None,
divisible_by=1,
repeat=2,
**kwargs,
):
super().__init__()
def _round(x):
return int(np.round(x / divisible_by) * divisible_by)
if filters_mult is None:
assert filters_end is not None
filters_mult = np.exp(np.log(filters_end / filters_init) / (repeat - 1))
rep_filters = filters_init
in_channels = in_channels
tower = nn.ModuleList()
for _ in range(repeat):
tower.append(
ConvBlock(
in_channels=in_channels, filters=_round(rep_filters), **kwargs
)
)
in_channels = _round(rep_filters)
rep_filters *= filters_mult
self.tower = nn.Sequential(*tower)
self.out_channels = in_channels
def forward(self, x):
return self.tower(x)
class DilatedResidual(nn.Module):
def __init__(
self,
in_channels,
filters,
kernel_size=3,
rate_mult=2,
dropout=0,
repeat=1,
**kwargs,
):
super().__init__()
dilation_rate = 1
in_channels = in_channels
block = nn.ModuleList()
for _ in range(repeat):
inner_block = nn.ModuleList()
inner_block.append(
ConvBlock(
in_channels=in_channels,
filters=filters,
kernel_size=kernel_size,
dilation_rate=int(np.round(dilation_rate)),
**kwargs,
)
)
inner_block.append(
ConvBlock(
in_channels=filters,
filters=in_channels,
dropout=dropout,
**kwargs,
)
)
block.append(Residual(nn.Sequential(*inner_block)))
dilation_rate *= rate_mult
dilation_rate = np.round(dilation_rate)
self.block = nn.Sequential(*block)
self.out_channels = in_channels
def forward(self, x):
return self.block(x)
class BasenjiFinal(nn.Module):
def __init__(
self, in_features, units=1, activation='linear', **kwargs
):
super().__init__()
block = nn.ModuleList()
block.append(Rearrange('b ... -> b (...)'))
block.append(nn.Linear(in_features=in_features, out_features=units))
self.block = nn.Sequential(*block)
def forward(self, x):
return self.block(x)
class BasenjiModel(nn.Module):
def __init__(self, conv1_filters=8, conv1_ks=15,
conv1_pad=7, conv1_pool=2, conv1_pdrop=0.4, conv1_bn_momentum=0.1,
convt_filters_init=16, filters_end=32, convt_repeat=2, convt_ks=5, convt_pool=2,
dil_in_channels=32, dil_filters=16, dil_ks=3, rate_mult=2, dil_pdrop=0.3, dil_repeat=2,
conv2_in_channels=32, conv2_filters=32,
conv3_in_channels=32, conv3_filters=1,
final_in_features=int(3000 / (2 ** 3))
):
super().__init__()
block = nn.ModuleList()
block.append(ConvBlock(
in_channels=4,
filters=conv1_filters,
kernel_size=conv1_ks,
padding=conv1_pad,
pool_size=conv1_pool,
dropout=conv1_pdrop,
bn_momentum=conv1_bn_momentum
))
block.append(ConvTower(
in_channels=conv1_filters,
filters_init=convt_filters_init,
filters_end=filters_end,
divisible_by=1,
repeat=convt_repeat,
kernel_size=convt_ks,
pool_size=convt_pool,
))
block.append(DilatedResidual(
in_channels=dil_in_channels,
filters=dil_filters,
kernel_size=dil_ks,
rate_mult=rate_mult,
dropout=dil_pdrop,
repeat=dil_repeat,
))
block.append(ConvBlock(
in_channels=conv2_in_channels,
filters=conv2_filters,
kernel_size=1
))
block.append(ConvBlock(
in_channels=conv3_in_channels,
filters=conv3_filters,
kernel_size=1
))
block.append(BasenjiFinal(final_in_features))
self.block = nn.Sequential(*block)
def forward(self, x):
return self.block(x)
class MyDataset(Dataset):
def __init__(self, input, label):
inputs = torch.tensor(input, dtype=torch.int8)
labels = torch.tensor(label, dtype=torch.float32)
self.inputs = inputs
self.labels = labels
def __getitem__(self, index):
return self.inputs[index], self.labels[index]
def __len__(self):
return len(self.labels)
BATCH_SIZE = 32
EPOCHS = 10
lr = 1e-3
# train_data = np.random.rand(100, 4, 3000)
# y_train = np.random.rand(100, 1)
# valid_data = np.random.rand(20, 4, 3000)
# y_valid = np.random.rand(20, 1)
# test_data = np.random.rand(20, 4, 3000)
# y_test = np.random.rand(20, 1)
train_dataset = MyDataset(train_data, y_train)
trainDataLoader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True)
valid_dataset = MyDataset(valid_data, y_valid)
validDataLoader = DataLoader(dataset=valid_dataset, batch_size=BATCH_SIZE)
test_dataset = MyDataset(test_data, y_test)
testDataLoader = DataLoader(dataset=test_dataset, batch_size=BATCH_SIZE)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
net = BasenjiModel()
net = net.to(device)
summary_device = "cuda" if "cuda" in device else "cpu"
summary(net, input_size=[(4, 3000)], batch_size=BATCH_SIZE, device=summary_device)
optimizer = optim.Adam(params=net.parameters(), lr=lr)
lossF = nn.MSELoss()
history = {'Valid Loss': [], 'Valid pcc': []}
for epoch in range(1, EPOCHS + 1):
processBar = tqdm(trainDataLoader, unit='step')
net.train(True)
epoch_loss_all = 0
for step, (inputs, labels) in enumerate(processBar):
inputs = inputs.to(device)
labels = labels.to(device)
net.zero_grad()
outputs = net(inputs)
loss = lossF(outputs.reshape(labels.shape), labels)
epoch_loss_all += loss * len(labels)
loss.backward()
optimizer.step()
processBar.set_description("[%d/%d] Loss: %.4f" %
(epoch, EPOCHS, loss.item()))
if step == len(processBar) - 1:
valid_totalLoss = 0
y_valid_pred_all = []
y_valid_true_all = []
train_loss = epoch_loss_all / len(train_data)
net.train(False)
with torch.no_grad():
for x_valid, y_valid in validDataLoader:
x_valid = x_valid.to(device)
y_valid = y_valid.to(device)
y_valid_pred = net(x_valid)
y_valid_pred_all.extend(y_valid_pred.flatten().tolist())
y_valid_true_all.extend(y_valid.tolist())
valid_batch_loss = lossF(y_valid_pred.reshape(y_valid.shape), y_valid)
valid_totalLoss += valid_batch_loss * len(y_valid)
validLoss = valid_totalLoss / len(valid_data)
pcc_valid, _ = pearsonr(y_valid_pred_all, y_valid_true_all)
history['Valid Loss'].append(validLoss.item())
# ô¥û pcc_valid 0h-
history['Valid pcc'].append(pcc_valid)
processBar.set_description("[%d/%d] Train Loss: %.4f, Valid Loss: %.4f, Valid pcc: %.4f" %
(epoch, EPOCHS, train_loss.item(), validLoss.item(), pcc_valid))
processBar.close()
net.train(False)
y_test_pred_all = []
y_test_true_all = []
with torch.no_grad():
for x_test, y_test in testDataLoader:
x_test = x_test.to(device)
y_test = y_test.to(device)
y_test_pred = net(x_test)
y_test_pred_all.extend(y_test_pred.flatten().tolist())
y_test_true_all.extend(y_test.tolist())
pcc, _ = pearsonr(y_test_pred_all, y_test_true_all)
print('pcc:', pcc)
plt.xlabel('y test predict')
plt.ylabel('y test true')
plt.scatter(y_test_pred_all, y_test_true_all, s=0.1)
plt.show()


















 4781
4781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









