





IEEE GEOSCIENCE AND REMOTE SENSING LETTERS, VOL. 19, 2022 6009005
卷积变换网络用于高光谱图像分类
Zhengang Zhao, Dan Hu, Hao Wang, 和 Xianchuan Yu, IEEE高级会员
摘要 —— 卷积神经网络(CNNs)在高光谱图像(HSI)分类中取得了显著的性能。然而,现有的CNNs受到其在HSI分类中有限的感受野限制。最近,变换网络由于其全局感受野,在许多任务中显示出了希望,但它们容易忽略对HSI分类重要的局部信息。在这篇文章中,我们提出了一种名为卷积变换网络(CTN)的新颖方法,用于HSI分类。为了充分利用光谱信息和空间信息,该方法采用中心位置编码(CPE)来合并光谱特征和像素位置。此外,提出的方法引入了卷积变换(CT)块。它有效地结合了卷积和变换结构,以捕获HSI块的局部-全局特征,这对HSI分类是有益的。在公共数据集上的实验结果证明了我们方法与几种最先进的分类方法相比的优越性。这项工作的代码将在 https://github.com/sky8791 上提供,以便于可重复性。
索引术语 —— 中心位置编码(CPE)、卷积神经网络(CNN)、高光谱图像(HSI)分类、变换器。
I. 引言 高光谱图像(HSIs)在从可见光谱到红外光谱的数百个狭窄光谱带中捕获观察场景内的光谱信号(像素)。这些信号携带了丰富的光谱信息,反映了不同的遥感材料。凭借丰富的光谱信息,HSIs已在许多领域得到应用,如农业、环境监测和陆地场景分类[1]。在这些应用和研究中,HSI分类是一个重要步骤,已成为遥感和地球观测中的一个活跃研究课题[2]、[3]。
HSI分类的目标是为每个像素分配适当的类别标签[1]、[4]。在过去的十年中,许多利用机器学习的方法被提出来解决这一任务,如支持向量机[5]、随机森林[6]、k最近邻[7]和稀疏表示[8]。由于光谱带之间的信息冗余和高相关性,这些传统分类器的性能较低。此外,这些方法通常容易受到噪声的影响。最近,基于深度学习的卷积神经网络(CNNs)已成功应用于各种视觉任务,并在HSI分类中取得了显著的性能[1]、[9]。就是否使用空间信息而言,基于CNN的HSI分类方法主要分为两类:基于光谱的方法和基于光谱-空间的方法。通常,基于光谱的方法仅在分类HSIs时使用光谱特征。它们将高光谱数据视为一系列光谱签名的集合,并忽略了像素之间的空间结构。例如,1-D CNN[10]从HSI数据中随机选择一些标记像素作为训练集,并采用五层来提取HSI分类的光谱特征。尽管基于光谱的方法充分利用了光谱信息,但它们很难在分类性能上取得突破。相比之下,基于光谱-空间的方法结合了HSIs的光谱和空间信息。这些方法通常将目标像素及其邻域像素作为一个子立方体样本(即,一个补丁),其类别标签是其中心像素的标签。在[11]中,作者提出了一个深度特征融合网络(DFFN),使用2-D CNN提取HSI分类的光谱-空间特征,引入了残差学习以增加网络深度,并将不同层次层次的输出融合在一起。在[12]中,作者首先使用自编码器预处理HSI数据,然后采用带有1×1核的浅层CNN提取特征。此外,由于HSIs原本是3-D立方体数据,研究人员[13]直接采用3-D CNN进行HSI分类,同时探索HSI数据的空间和光谱信息。Zhong等人[14]设计了一个光谱-空间残差网络(SSRN),使用3-D卷积层从HSIs的光谱签名和空间上下文中学习区分特征。尽管CNNs凭借其强大的特征提取能力在HSI分类中取得了公认的性能,但它们仍然受到其有限感受野的阻碍[15]。通常,CNNs依赖于许多具有狭窄范围(例如,3×3和5×5)的卷积核来提取特征,这些核与图像局部连接。也就是说,CNNs提取的特征往往是局部特征。因此,小核限制了CNN的感受野。目前,变换网络在自然语言处理和视觉任务中显示出了有希望的性能[16]-[18]。它们主要由许多自注意力和前馈层组成,这些层继承了全局感受野,以捕获样本的全局依赖特征。在[17]中,作者将图像分割成固定大小的补丁,并将每个补丁线性地表示为带有位置编码的像素序列。Wu等人[18]引入了视觉变换器中的卷积,以提高性能和鲁棒性。然而,将HSI补丁展平成像素序列的操作破坏了补丁的内部空间信息。位置编码不能充分反映HSI样本的空间信息。此外,一些局部特征对HSI分类很有用,但它们不能很好地被提取。为了解决这些问题,我们提出了一种名为卷积变换网络(CTN)的新颖方法,用于HSI分类。CTN采用2-D中心位置编码(CPE)而不是1-D序列位置编码,以保留HSI样本的空间结构。同时,它通过卷积变换(CT)块有效地结合了局部特征和全局特征,这对提高HSI分类的性能是有益的。总之,本文的主要贡献如下:首先,我们提出了CPE,以获得HSI补丁的空间位置特征。其次,我们设计了用于提取HSI补丁局部-全局特征的CT块。最后,在两个基准HSI数据集上进行了一系列实验,结果表明,提出的CTN与几种最先进的方法相比,实现了最佳性能。
II. 提出的方法 本节介绍了我们的CTN用于HSI分类。图1展示了该方法的架构。II-A节介绍了CPE模块。II-B节展示了CT块。提出的详细工作流程在II-C节中。
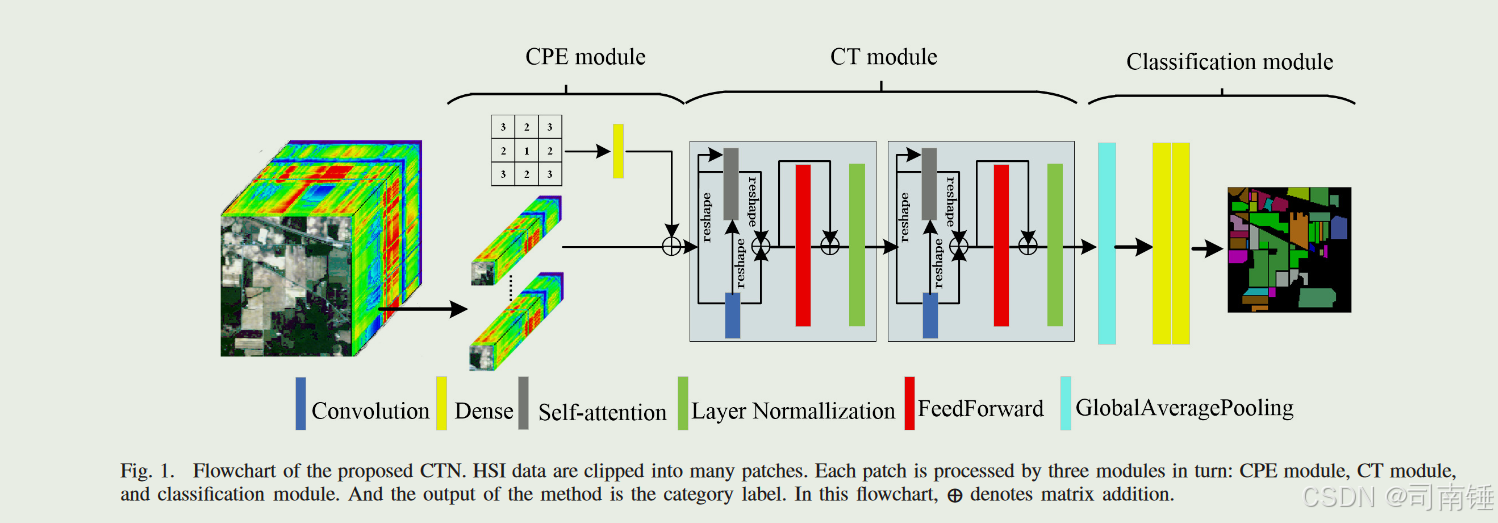
图1. 提出的CTN流程图。HSI数据被剪辑成许多补丁。每个补丁依次由三个模块处理:CPE模块、CT模块和分类模块。该方法的输出是类别标签。在这个流程图中,⊕表示矩阵加法。
A. 中心位置编码 空间信息对HSI分类很有用。为了更好地描述像素之间的相对位置并保持样本的旋转不变性,一个样本中的像素位置被定义为
pos(i, j) = |i − xc| + | j − yc| + 1 (1)
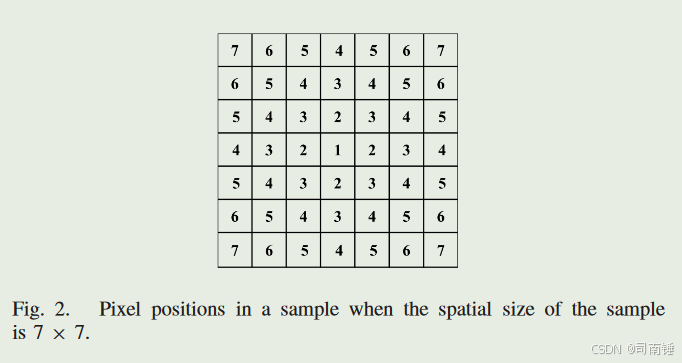
其中(xc,yc)表示样本的中心位置坐标,(i,j)表示样本中任意像素的坐标。为了可视化CPE,我们展示了一个样本的空间大小为7×7时的一个例子(见图2)。CPE旨在保留模型中HSI补丁的空间结构。它将像素位置转换为嵌入向量。这里,学习到的位置嵌入用于编码像素位置
cpe(x) = xW (2)
其中W是参数矩阵,x是位置矩阵。在获得位置嵌入向量后,它们被添加到高光谱数据中,然后传递到下一层。CPE结构如图1所示(见CPE模块)。
B. 卷积变换块 CT块是提出方法的核心部分。它用于提取局部-全局特征。它主要由2-D卷积层、自注意力层、前馈层和层归一化层组成。CT块的架构如图1所示(见CT模块)。
- 二维卷积:卷积层通常采用许多神经元(核)来计算特征图。每个核计算其权重与输入体积的一个小区域的点积。其公式如下[11]:
con(V) = J
j=1 δ V ∗ Wr1×r2 j + b j (3)
其中V是输入体积,Wr1×r2 j是第j个核,大小为r1×r2,b j是第j个偏置。||表示连接操作,∗表示卷积操作。δ(·)是非线性激活函数GELU[19]。核的数量J是64,核的大小是3×3。
- 自注意力:自注意力用于基于卷积特征提取全局特征。其输入是查询、键和值(即Q、K、V)[15]。值首先通过卷积函数处理。然后应用点积来计算查询与所有键的权重。然后使用softmax函数[15]来计算值上的权重。我们的自注意力定义如下:
SA(Q, K, V) = softmax QWQ KTWK con(V) (4)
其中WQ、WK是参数矩阵,{·}T是转置,con(·)是卷积函数[见(3)]。
- 前馈:前馈应用于通过全连接层进一步转换输出向量,并且它在所有输出向量之间共享。它包含两个线性变换,在中间有一个GELU[19]激活函数。其方程定义如下:
FF(x) = GELU(xW1 + b1)W2 + b2 (5)
其中W1、W2是参数矩阵,b1、b2是它们的偏置。
- 层归一化:层归一化是减少训练阶段内部协变量偏移和防止过拟合的有效方法[20]。它表示为
LN(xi) = g · xi − E(x)
∘
Var(x) + ε + b (6)
其中E(x)和Var(x)分别表示x的均值和标准差,g和b是学习到的参数,ε是一个非常小的常数值。
C. 卷积变换网络 如图1所示,提出的CTN主要由三个模块组成:CPE模块、CT模块和分类模块。在这项工作中,HSI数据首先通过主成分分析(PCA)预处理,并选择前64个分量。然后它们被剪辑成许多相同大小的补丁。在第一阶段,当给定一个以目标像素为中心的HSI补丁时,HSI补丁由CPE模型表示。输出包含光谱信息和空间信息。在第二阶段,输出被输入到由两个CT块组成的CT模块。CT块从输入补丁的光谱-空间特征中提取局部-全局特征。作为最后阶段,分类模块由一个全局平均池化(GAP)[21]层和两个密集层组成。第一密集层的激活函数是GELU,其神经元数量为32。另一个密集层的激活函数是softmax,其神经元数量是类别的数量。分类交叉熵被用作损失函数,定义为
Loss = −
c i=1 yilog(zi) (7)
其中c是类别的数量,zi是分类模块的输出,yi是标签值,yi ∈ {0, 1}(如果yi是第i个类别yi = 1,否则yi = 0)。Adam优化器在训练过程中被采用,以追求鲁棒性。
III. 实验和分析
为了验证所提出方法的分类性能,我们在两个广泛使用的HSI数据集上进行了一系列实验:Pavia大学(UP)和Indian Pines(IP)[2]、[15]。UP数据集的大小为610×340,包含42776个标记样本,分为九个类别。IP数据集的大小为145×145,包含10249个标记样本,分为16个类别。表I和表II分别展示了UP和IP数据集上的类别、名称和样本数量。此外,采用了四个评估指标来定量分析方法的性能,包括每类准确度、总体准确度(OA)、平均准确度(AA)和Kappa系数(κ)[1]、[13]。OA指的是所有正确分类样本的比例;AA指的是每个类别分类准确度的平均值;Kappa系数表明分类结果与地面真实数据的一致性。
A. 与其他方法比较 在本节中,所提出的CTN与几种最先进的分类方法进行了比较,包括DFFN[11]、3-D CNN[13]、MANF[22]和Transformer[23]。在这些实验中,HSI数据通过PCA预处理,保留了前64个分量。epoch设置为300,批量大小为32,补丁大小为15×15。权重参数通过Adam优化,学习率设置为0.001。比较方法的其他设置遵循原论文。特别是,Transformer的解码器网络被替换为CTN的分类模块,以实现HSI分类。对于UP数据集,1%的标记样本随机选择作为训练样本,其余标记样本为测试样本。对于IP数据集,我们从地面真实图随机选择10%的标记像素作为训练样本,其余为测试样本。我们在每个数据集上独立地执行这些方法十次,并记录了十次结果的平均准确度和标准差。不同方法的分类结果如表III和表IV所示。我们用粗体突出显示了最佳结果。如表III和表IV所示,在每类准确度方面,所提出的CTN在大多数类别中都取得了最佳结果。例如,在UP数据集中有五个类别获得了最高准确度,在IP数据集中所有类别都获得了最高准确度。从OA、AA和κ的角度来看,CTN的分类结果与其他方法相比有相对稳定的改进。
图3. 提出的CTN在UP和IP数据集上不同空间大小的OAs。
B. 空间大小的影响 补丁的空间大小对HSI分类有相当大的影响。在本节中,我们进行了一系列实验,以探索空间大小对分类性能的影响。对于UP数据集,1%的标记样本随机选择作为训练样本,而其他标记样本为测试样本。对于IP数据集,我们随机选择了10%的标记样本作为训练样本,而其他标记样本为测试样本。补丁的空间大小设置为9×9、11×11、13×13、15×15、17×17和19×19。图3显示了所提出的CTN在UP和IP数据集上不同空间大小的OAs。从图3中,我们发现补丁的空间大小对所提出的方法很重要。在UP和IP数据集上,OAs随着空间大小的扩展先增加然后减少。分类性能最初提高的原因是更大的空间大小使补丁包含更多有用的像素,其特征有助于对目标像素进行分类。但如果空间大小继续过度增长,分类性能会降低,因为会涉及许多干扰像素,其标签与目标像素周围的像素不同。这些干扰像素阻碍了分类性能的提高。因此,适当的空间大小对我们的方法很重要。在所提出的CTN中,空间大小设置为15×15。
C. CPE的有效性 CPE模块在所提出的方法中扮演了重要角色。它通过融合像素的光谱信息和位置信息来提高分类性能。为了验证CPE的必要性,我们在UP和IP数据集上应用了带和不带CPE的方法。在相同的配置下,方法的OAs、AAs和κs如表V所示。根据表V,很明显CPE提高了两个数据集上的分类性能。例如,带CPE的方法的OA在UP数据集上提高了+1.24,在IP数据集上提高了+0.36。此外,在标准差方面,带CPE的方法比不带CPE的方法更稳定。
D. CT块的有效性 本节的实验是为了证明CT块的有效性。在这些实验中,只使用变换器(Trm)块的方法和只使用CNN块的方法作为实验组,而其他条件保持不变。图4显示了带Trm、CNN和CT块的方法在UP和IP数据集上的OAs。从图4中,观察到带CNN块的方法的性能优于带Trm块的方法。它表明卷积提取的局部特征比变换器提取的全局特征对于我们模型中的HSI分类更有用。此外,带CT块的方法的OAs高于带CNN块的方法,这表明所提出方法中的CT块有效地结合了局部和全局特征,并提高了HSI分类的性能。
IV. 结论 在这篇文章中,我们提出了一种名为CTN的新颖方法,用于HSI分类。所提出的方法通过CPE获得空间特征,并通过CT块提取局部-全局特征,这被证明对HSI分类是有效的。与最先进的HSI分类方法相比,所提出的方法在分类准确度上表现更好。然而,其良好的性能依赖于许多标记样本。未来的研究是通过半监督模式在标记样本有限的情况下进一步提高其性能。
参考文献
[1] M. E. Paoletti, J. M. Haut, J. Plaza, and A. Plaza, “Deep learning classifiers for hyperspectral imaging: A review,” ISPRS J. Photogramm. Remote Sens., vol. 158, pp. 279–317, Dec. 2019.
中文翻译:[1] M. E. 帕奥莱蒂, J. M. 豪特, J. 普拉扎, 和 A. 普拉扎, “高光谱成像的深度学习分类器:综述,” 国际摄影测量与遥感学会会刊, 第158卷, 页279-317, 2019年12月.
[2] L. He, J. Li, C. Liu, and S. Li, “Recent advances on spectral-spatial hyperspectral image classification: An overview and new guidelines,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 3, pp. 1579–1597, Mar. 2017.
中文翻译:[2] L. 何, J. 李, C. 刘, 和 S. 李, “光谱-空间高光谱图像分类的最新进展:综述与新指南,” IEEE地球科学与遥感会刊, 第56卷, 第3期, 页1579-1597, 2017年3月.
[3] D. Hong et al., “More diverse means better: Multimodal deep learning meets remote-sensing imagery classification,” IEEE Trans. Geosci. Remote Sens., vol. 59, no. 5, pp. 4340–4354, Apr. 2021.
中文翻译:[3] D. 洪等, “更多样化意味着更好:多模态深度学习与遥感图像分类的结合,” IEEE地球科学与遥感会刊, 第59卷, 第5期, 页4340-4354, 2021年4月.
[4] A. Sellami and S. Tabbone, “Deep neural networks-based relevant latent representation learning for hyperspectral image classification,” Pattern Recognit., vol. 121, Jan. 2022, Art. no. 108224.
中文翻译:[4] A. 塞拉米和S. 塔博内, “基于深度神经网络的相关潜在表示学习用于高光谱图像分类,” 模式识别, 第121卷, 2022年1月, 文章编号108224.
[5] F. Melgani and L. Bruzzone, “Classification of hyperspectral remote sensing images with support vector machines,” IEEE Trans. Geosci. Remote Sens., vol. 42, no. 8, pp. 1778–1790, Aug. 2004.
中文翻译:[5] F. 梅尔加尼和L. 布鲁宗, “使用支持向量机对高光谱遥感图像进行分类,” IEEE地球科学与遥感会刊, 第42卷, 第8期, 页1778-1790, 2004年8月.
[6] J. Ham, Y. Chen, M. M. Crawford, and J. Ghosh, “Investigation of the random forest framework for classification of hyperspectral data,” IEEE Trans. Geosci. Remote Sens., vol. 43, no. 3, pp. 492–501, Mar. 2005.
中文翻译:[6] J. 哈姆, Y. 陈, M. M. 克劳福德, 和 J. 戈什, “随机森林框架在高光谱数据分类中的研究,” IEEE地球科学与遥感会刊, 第43卷, 第3期, 页492-501, 2005年3月.
[7] C. Cariou and K. Chehdi, “Unsupervised nearest neighbors clustering with application to hyperspectral images,” IEEE J. Sel. Topics Signal Process., vol. 9, no. 6, pp. 1105–1116, Sep. 2015.
中文翻译:[7] C. 卡里乌和K. 切迪, “无监督最近邻聚类及其在高光谱图像中的应用,” IEEE信号处理专题杂志, 第9卷, 第6期, 页1105-1116, 2015年9月.
[8] Y. Chen, N. M. Nasrabadi, and T. D. Tran, “Hyperspectral image classification using dictionary-based sparse representation,” IEEE Trans. Geosci. Remote Sens., vol. 49, no. 10, pp. 3973–3985, Oct. 2011.
中文翻译:[8] Y. 陈, N. M. 纳斯拉巴迪, 和 T. D. 陈, “使用基于字典的稀疏表示进行高光谱图像分类,” IEEE地球科学与遥感会刊, 第49卷, 第10期, 页3973-3985, 2011年10月.
[9] D. Hong, L. Gao, J. Yao, B. Zhang, A. Plaza, and J. Chanussot, “Graph convolutional networks for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 59, no. 7, pp. 5966–5978, Jul. 2021.
中文翻译:[9] D. 洪, L. 高, J. 姚, B. 张, A. 普拉扎, 和 J. 查努索, “用于高光谱图像分类的图卷积网络,” IEEE地球科学与遥感会刊, 第59卷, 第7期, 页5966-5978, 2021年7月.
[10] W. Hu, Y. Huang, L. Wei, F. Zhang, and H. Li, “Deep convolutional neural networks for hyperspectral image classification,” J. Sensors, vol. 2015, pp. 1–12, Jan. 2015.
中文翻译:[10] W. 胡, Y. 黄, L. 韦, F. 张, 和 H. 李, “用于高光谱图像分类的深度卷积神经网络,” 传感器杂志, 第2015卷, 页1-12, 2015年1月.
[11] W. Song, S. Li, L. Fang, and T. Lu, “Hyperspectral image classification with deep feature fusion network,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 6, pp. 3173–3184, Jun. 2018.
中文翻译:[11] W. 宋, S. 李, L. 方, 和 T. 陆, “使用深度特征融合网络进行高光谱图像分类,” IEEE地球科学与遥感会刊, 第56卷, 第6期, 页3173-3184, 2018年6月.
[12] H. Patel and K. P. Upla, “A shallow network for hyperspectral image classification using an autoencoder with convolutional neural network,” Multimedia Tools Appl., vol. 81, no. 1, pp. 695–714, 2021.
中文翻译:[12] H. 帕特尔和K. P. 乌普拉, “使用带有卷积神经网络的自编码器进行高光谱图像分类的浅层网络," 多媒体工具与应用, 第81卷, 第1期, 页695-714, 2021年.
[13] M. Ahmad, A. M. Khan, M. Mazzara, S. Distefano, M. Ali, and M. S. Sarfraz, “A fast and compact 3-D CNN for hyperspectral image classification,” IEEE Geosci. Remote Sens. Lett., vol. 19, pp. 1–5, 2022.
中文翻译:[13] M. 艾哈迈德, A. M. 汗, M. 马扎拉, S. 迪斯特法诺, M. 阿里, 和 M. S. 萨弗拉兹, “用于高光谱图像分类的快速紧凑3-D CNN," IEEE地球科学与遥感快报, 第19卷, 页1-5, 2022年.
[14] Z. Zhong, J. Li, Z. Luo, and M. Chapman, “Spectral-spatial residual network for hyperspectral image classification: A 3D deep learning framework,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 2, pp. 847–858, Feb. 2018.
中文翻译:[14] Z. 钟, J. 李, Z. 罗, 和 M. 查普曼, “用于高光谱图像分类的光谱-空间残差网络:一个3D深度学习框架," IEEE地球科学与遥感会刊, 第56卷, 第2期, 页847-858, 2018年2月.
[15] J. He, L. Zhao, H. Yang, M. Zhang, and W. Li, “HSI-BERT: Hyperspectral image classification using the bidirectional encoder representation from transformers,” IEEE Trans. Geosci. Remote Sens., vol. 58, no. 1, pp. 165–178, Jan. 2020.
中文翻译:[15] J. 何, L. 赵, H. 杨, M. 张, 和 W. 李, “HSI-BERT:使用来自变换器的双向编码器表示进行高光谱图像分类," IEEE地球科学与遥感会刊, 第58卷, 第1期, 页165-178, 2020年1月.
[16] C. Raffel et al., “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. Mach. Learn. Res., vol. 21, no. 140, pp. 1–67, 2020.
中文翻译:[16] C. 拉费尔等, “探索统一文本到文本变换器的迁移学习极限," 机器学习研究杂志, 第21卷, 第140期, 页1-67, 2020年.
[17] A. Dosovitskiy et al., “An image is worth 16×16 words: Transformers for image recognition at scale,” 2020, arXiv:2010.11929.
中文翻译:[17] A. 多索维茨基等, “一张图片值16×16个词:用于大规模图像识别的变换器," 2020年, arXiv:2010.11929.
[18] H. Wu et al., “CvT: Introducing convolutions to vision transformers,” 2021, arXiv:2103.15808.
中文翻译:[18] H. 吴等, “CvT:将卷积引入视觉变换器," 2021年, arXiv:2103.15808.
[19] D. Hendrycks and K. Gimpel, “Gaussian error linear units (GELUs),” 2016, arXiv:1606.08415.
中文翻译:[19] D. 亨德里克斯和K. 金佩尔, “高斯误差线性单元(GELUs)," 2016年, arXiv:1606.08415.
[20] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” 2016, arXiv:1607.06450.
中文翻译:[20] J. L. 巴, J. R. 基罗斯, 和 G. E. 辛顿, “层归一化," 2016年, arXiv:1607.06450.
[21] M. Lin, Q. Chen, and S. Yan, “Network in network,” 2013, arXiv:1312.4400.
中文翻译:[21] M. 林, Q. 陈, 和 S. 严, “网络中的网络," 2013年, arXiv:1312.4400.
[22] Z. Li et al., “Hyperspectral image classification with multiattention fusion network,” IEEE Geosci. Remote Sens. Lett., vol. 19, pp. 1–5, 2022.
中文翻译:[22] Z. 李等, “使用多注意力融合网络进行高光谱图像分类," IEEE地球科学与遥感快报, 第19卷, 页1-5, 2022年.
[23] A. Vaswani et al., “Attention is all you need,” in Proc. 31st Int. Conf. Neural Inf. Process. Syst., Red Hook, NY, USA: Curran Associates, 2017, pp. 6000–6010.
中文翻译:[23] A. 瓦斯瓦尼等, “注意力就是全部," 在第31届国际神经信息处理系统会议论文集中, 红钩, 纽约, 美国:Curran Associates, 2017年, 页6000-6010.



















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











