










目录:LLM-GNN(ICLR2023)
摘要: 近年来,图神经网络(GNNS)取得了显著进步。但是,它们需要丰富的高质量标签,以确保有卓越的性能。相比之下,大型语言模型(LLMS)在文本属性图(TAG)上表现出令人印象深刻的零样本学习能力。然而,LLMs在有效处理结构数据面临挑战并且高推理成本高昂。鉴于这些观察结果,这项工作在LLMS Pipeline,LLM-GNN上引入了无标签的节点分类。它使GNN和LLM的优势融合在一起,同时减轻它们的局限性。具体而言,LLMS被杠杆化以注释一小部分节点,然后在LLMS的注释上训练GNN,以对剩余的大部分节点进行预测。 LLM-GNN的实施面临着一个独特的挑战:如何积极选择LLMs的节点来注释并因此增强GNN训练?如何利用LLM来获得高质量、代表性和多样性的注释,从而以较低的成本增强GNN的性能?为了应对这一挑战,文章开发了基于注释质量的启发式方法,并利用从LLM到高级节点选择的置信度得分。全面的实验结果验证了LLM-GNN的有效性。特别是,LLM-GNN可以在庞大的数据集OGBN-PRODUCTS中获得74.9%的精度,且成本低于1美元。
1 背景介绍
1.1 获取高质量图结构数据的问题
图神经网络(GNN)始终假设真实标签的即时可用性作为前提条件。值得注意的是,这种假设往往忽视了为图结构数据获取高质量标签的核心问题:
(1) 图结构数据的多样性和复杂性,人工标记本身就很困难。
(2) 现实世界图的庞大规模,注释很大一部分节点的过程变得既耗时又耗费资源。
1.2 GNN与LLM优缺点
(1)当存在充足的高质量标注时,GNN能有效利用图结构实现高效精准的预测。然而当缺乏足够优质标注时,其性能将受明显限制。
(2)相比之下,大语言模型(LLM)无需高质量标注即可获得满意效果,但需付出高昂计算成本。
1.3 LLM-GNN面临挑战
(1)如何在不牺牲多样性和代表性的情况下保证标注的高质量?
(2)如何设计适当的Prompt,以使 LLM 能够产生更准确的注释?
(3)如何策略性地选择一组训练节点,这些节点不仅要拥有高质量的标注,而且要表现出信息量和代表性?
为了克服这些挑战,我们提出了一种使用 LLM 对graph进行无标签节点分类通道 LLM-GNN。
1.4 文章贡献
(1)引入了一种新的无标签通道LLM-GNN,以利用LLM进行注释,为GNN提供训练信号以进行进一步预测。
(2)采用LLM来生成具有校准置信度的注释,并引入带有后置过滤的困难感知主动选择,以获得在注释质量和传统图主动选择标准之间进行适当权衡的训练节点。
(3)在大规模 OGBN-PRODUCTS 数据集上,LLM-GNN 无需人工标注即可达到 74.9% 的准确率。该性能与手动注释 400 个随机选择的节点相当,而通过 LLM 进行注释过程的成本低于 1 美元。
2 方法
2.1 模型框架
为了解决上述节点分类流程的局限性,文中提出了一种新的流程 LLM 图上的无标签节点分类:即LLM-GNN通道。
它的设计有四个组成部分:1、难度感知主动节点选择;2、置信度感知标注;3、后置过滤;4、GNN 模型训练和预测。
LLM-GNN架构如图:
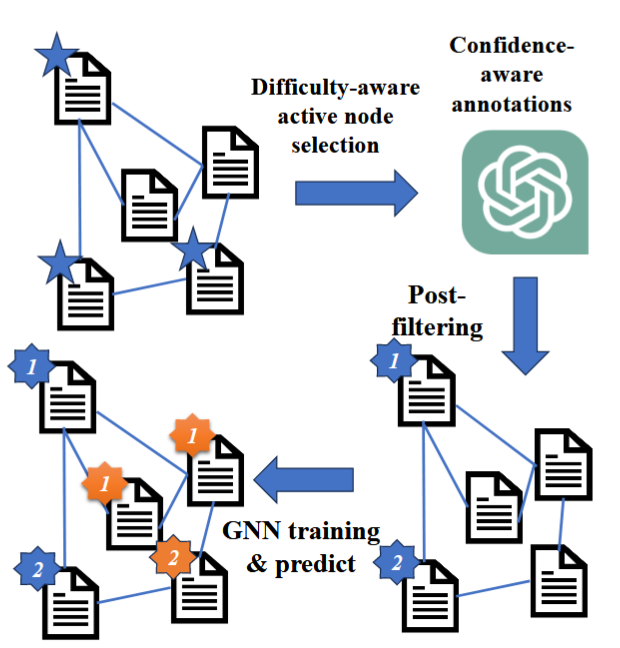
(1)难度感知主动节点选择是用于寻找LLM标注的候选节点集。该阶段不仅考虑多样性和代表性作为baseline,而且额外关注对注释质量的影响。具体来说,采用了一种难度感知启发式方法,将注释质量与特征密度相关联。
(2)对于选定的节点集,利用 LLM 强大的零样本能力,通过置信感知提示来注释这些节点。这个置信度分数可以帮助识别注释质量,并帮助我们从嘈杂的标签中过滤出高质量的标签。
(3)后过滤阶段旨在删除低质量的注释。在注释置信度的基础上,文中利用LLM的置信度分数进一步细化注释的质量,并从之前选择的集合中删除那些置信度较低的节点。
(4)最后使用过滤后的高质量注释集对GNN进行训练与预测。
2.2 难度感知主动节点选择
2.2.1 注释准确度与聚类密度的相关性
如何动态选择标注节点呢?文章发现LLM生成的注释的准确性与节点的聚类密度密切相关。为了证明这种相关性,文章在原始特征空间上采用 k 均值聚类,将聚类数量设置为等于不同类计数。从整个数据集中采样 1000 个节点,然后由 LLM 进行注释。随后根据它们到最近聚类中心的距离对它们进行排序并分为十个大小相等的组。如下图所示:
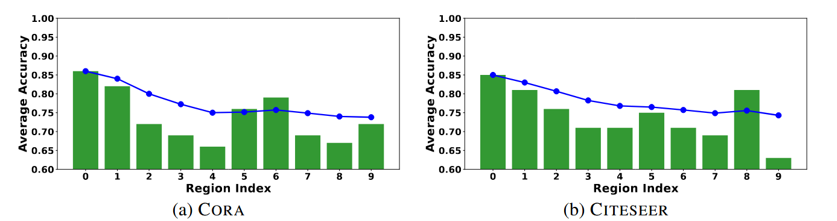
结果表明靠近聚类中心的节点通常表现出更好的注释质量,这表明注释难度较低。
【注:LLMs 的注释准确性与到最近聚类中心的距离的关系。条形代表每个选定组内的平均准确度,而蓝线表示累积平均准确度。在第 i 组,蓝线表示前面 i 组中所有节点的平均准确度】
2.2.2 启发式注释难度距离计算公式
由上结果表明靠近聚类中心的节点通常表现出更好的注释质量,这表明注释难度较低。因此作者提出了一个启发式注释难度距离计算公式为:
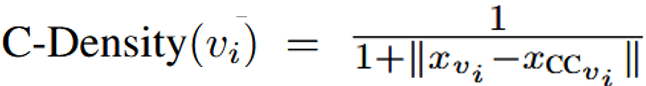
其中对于任何节点 vi 及其最近的簇中心 CCvi ,以及xvi表示节点vi的特征。
2.2.3 难度感知动态节点选择函数
为了提高训练模型的性能,所选节点应在注释难度和传统主动选择标准之间进行权衡,因此文章采用排名聚合方式将难度启发式集成到传统图主动选择中,提出难度感知动态节点选择函数fDA-act(vi),如下:
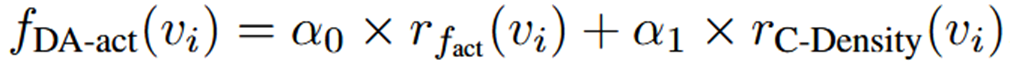
其中,fact(vi)是图主动学习的原始得分函数,rfact(vi)表示为从高到低的排名百分比,rC-Density(vi)是启发式注释难度距离的排名百分比。引入超参数α0和α1来平衡标注难度和传统图主动学习标准(例如代表性和多样性)。最后,选择fDA-act(vi)较大的节点vi供LLM进行注释,记为Vanno。
【注:传统图主动学习方法:Density-based selection基于密度的选择、GraphPart图部分、FeatProp、Degree-based selection基于度的选择、Pagerank-based selection基于PageRank的选择、AGE、RIM等】
2.3 置信度感知标注
为了从LLM标注的节点中获取高质量的节点,需要设置一个置信度的得分进一步筛选出可靠的节点。如何获取置信度呢?文中主要提出了五点获取置信度的策略:
(1)直接要求置信度,表示为“Vanilla (zero-shot)”。
(2)基于推理的提示生成注释,包括思路链和多步推理。
(3)TopK提示,要求LLM生成前K个可能的答案,并选择最可能的一个作为答案。
(4)基于一致性的提示,多次查询LLM并选择最常见的输出作为答案,记为“Most Voting”。
(5)混合提示,它结合了 TopK 提示和基于一致性的提示。
如下左边图是不同提示策略下标注的精度,右边图是置信度与精度的关系:

Prompt示例:

【注:1、使用 TopK 策略进行 1-shot 注释的完整提示示例。2、用于自我纠正的提示。】
2.4 后过滤阶段
直接过滤掉低置信度节点可能会导致标签分布偏移并降低所选节点的多样性,从而降低后续训练模型的性能。因此文中提出了一个简单的熵评分函数变化(COE)来测量从所选集合中删除节点时标签的熵变化,如下:
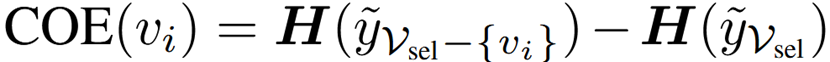
其中,y是大模型生成的注释,Vsel表示当前所选择集合的节点,H()是香农熵函数,COE(vi)表示去除节点vi后熵的变化。熵变化小的证明该节点对节点多样贡献不大,优先考虑除去。
为了平衡多样性和注释质量。COE 可以与置信度分数 fconf(vi) 结合使用,最终得到过滤得分函数ffilter:
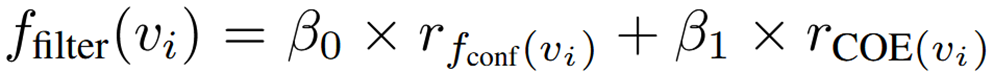
其中,rfconf(vi)是基于节点 vi 的置信度的排名百分比值。rCOE(vi) 是基于节点 vi 的熵变化(COE)的排名值。引入超参数β0和β1用来平衡标签多样性和注释质量。 rfconf 是置信度得分 fconf 的从高到低排名百分比。
为了进行后过滤,每次删除 ffilter 值最小的节点,直到达到预先定义的最大数量。
3 实验结果
文中主要研究以下研究问题:
(1)RQ1:主动选择和过滤后策略如何影响LLM-GNN的性能?
(2)RQ2: LLM-GNN的性能和成本与其他Labelfree节点分类方法相比如何?
(3)RQ3:不同的预算如何影响管道的性能?
(4)RQ4: LLMS的注释与真相标签相比如何?
3.1 基于GCN的不同主动学习策略(RQ1)
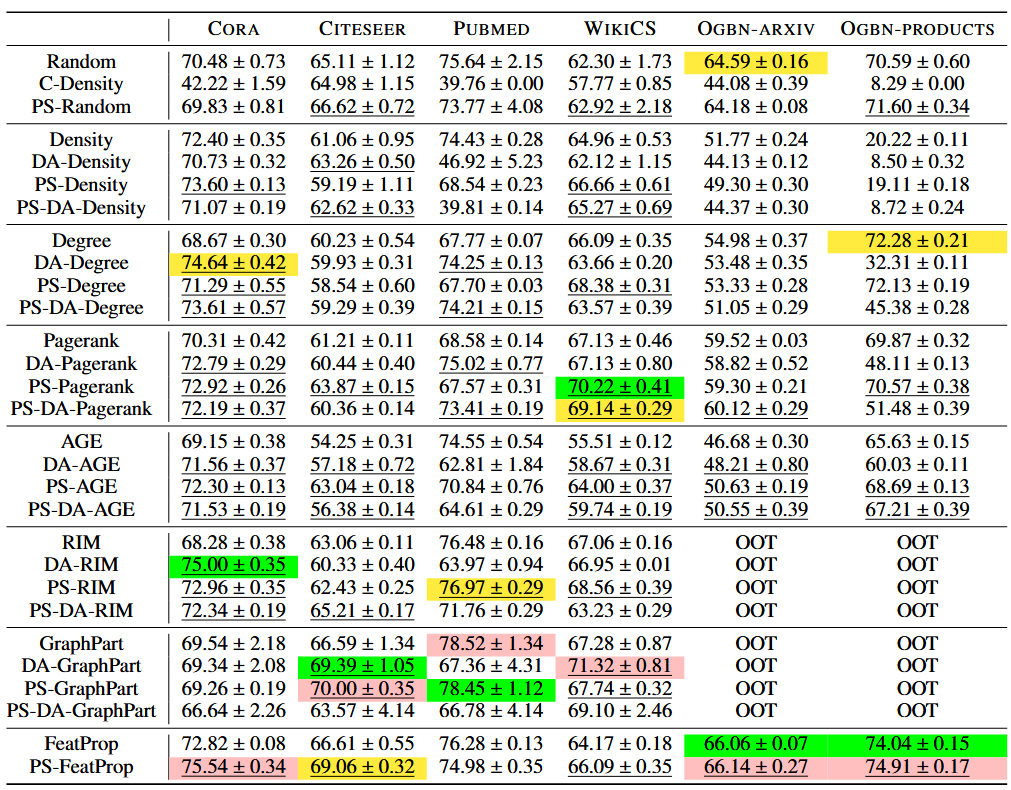
(1) 传统图主动选择:随机选择、基于密度的选择、GraphPart、FeatProp、基于程度的选择 、基于 Pagerank 中心性的、AGE 和 RIM 。
(2)难度感知主动节点选择:结合C-Density的传统图主动选择。为了表示这些选择,我们添加前缀“DA-”。例如,“DA-AGE”意味着将原始的AGE方法与我们提出的C-Density相结合。
(3)后过滤:传统的图主动选择结合置信度和基于COE的选择,我们添加前缀“PS-”。
(4)将困难感知主动节点选择与后过滤相结合:我们在这些方法中添加前缀“PS-DA”。
3.2 与其他无标签节点分类方法的比较(RQ2)
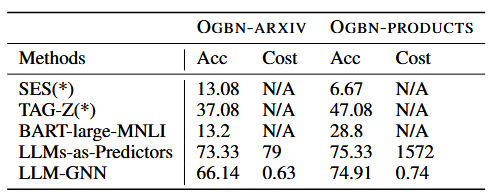
文中提出的管道LLM-GNN可以显着优于SES、TAG-Z和BART-large-MNLI。尽管LLMs-as-Predictors比LLM-GNN有更好的性能,但其成本却比LLM-GNN高得多。
3.3 预算对LLM-GNN的性能的影响(RQ3)
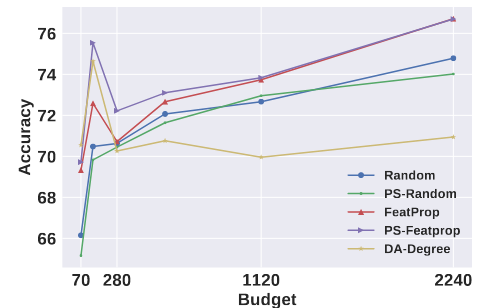
结果表明:随着预算的增加,精确度趋于逐渐提高。与使用ground Truth不同,随着预算的增加,性能增长相对有限。它表明在现实场景中,性能和成本之间存在权衡。
3.4 LLMS的注释与真相标签相比(RQ4)
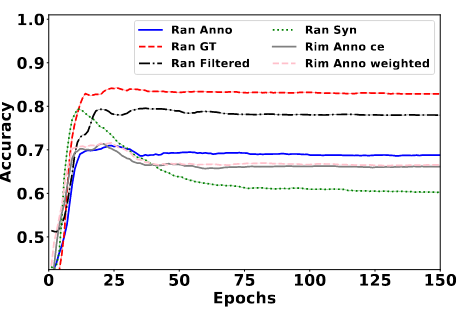
LLMS 注释的特点:
(1)LLM 的注释呈现出与合成噪声标签完全不同的训练动态。LLM 注释的过度拟合程度远小于合成噪声标签的过度拟合程度。
(2)比较加权损失和正常的交叉熵损失,我们发现用于处理合成噪声标签的加权损失对于LLM的注释效果有限。
【注:LLMs 的注释、真实标签和合成噪声标签之间的比较。 “Ran”表示随机选择,“GT”表示真实标签。 “ce”和“weighted”分别表示正常交叉熵和加权交叉熵损失。】
以上是本次分享的文章,希望对你有帮助,记得点赞加收藏下哦。我是小波,微信公众号:Wilber的技术分享,喜欢的话可以关注哦。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











