



总结:
问题:用GCN做推荐缺乏全面的消融分析,GCN中两种最常见的设计-特征转换 和非线性激活对协同过滤的性能贡献很小,另外,它们会增加训练的难度并降低推荐性能。
解决办法:为了简化GCN的设计,让它更适合做推荐,提出了一个新的模型叫LigthGCN,它只包括GCN中最重要的部分–领域聚合–用于协同过滤。
怎么做的:LightGCN通过在用户-物品交互图上线性传播用户和物品表征,并使用在所有层上学习到的表征的加权和作为最终的表征。
实验部分:我们先描述实验设置,然后与NGCF进行详细比较,为了验证LightGCN中的设计并揭示其有效性的原因,我们进行了消融研究和表征分析。
实验结果:我们通过实验证明了LightGCN在简单、易于训练、泛化能力强、效率高等方面的优势。
NGCF:
在初始步骤中,每个用户和物品都与ID表征相关联。
然后NGCF利用用户物品交互图传播表征,如下所示:
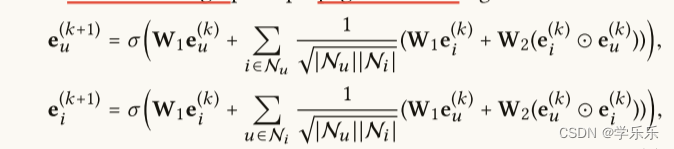 这里euk,eik分别表示在 k 层传播后用户 u 和物品i 的表征,
这里euk,eik分别表示在 k 层传播后用户 u 和物品i 的表征,
σ 是非线性激活函数
Nu表示用户u交互过的所用物品集
Ni表示物品i交互过的所有用户集
w1和w2是可训练的权重矩阵,用于在每一层中执行特征变换。
通过传播L层,NGCF获得L+1表征来描述用户(e(0)u,e(1)u,…,e(L)u)和物品(e(0)i,e(1)i,…,e(L)i)。然后将这些L+1表征连接起来,得到最终的用户表征和物品表征,使用内积生成预测得分。
(公式部分解释为借鉴,感觉他人解释的易于明白!!!)




疑惑点:
1.这里说到,在协同过滤中,用户物品交互图的每个节点只有一个ID作为输入,没有具体的语义。在这种情况下,进行多次非线性变换并不有助于更好地学习特征,那意思是如果节点有丰富的语义信息,非线性激活和特征转换就有用了?

答:是
2.获得最终表征的方式 为什么从拼接改为求和?

答:拼接会改变维度,求和不会改变维度

















 4509
4509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









