




1、项目介绍:
实现的是一个高并发内存池,它的原型是Google的一个开源项目tcmalloc(Thread-Caching Malloc),实现了高效的多线程内存管理,用于替代系统的内存分配相关函数。
- 首先我们先把tcmalloc最核心的框架简化后拿出来,模拟实现一个自己的高并发内存池。
- 基于上述代码的理解,在阅读malloc的原码,看一下具体实现。
- 有了上面1、2两部分的理解之后,我们在来阅读tcmalloc的原码,进一步优化我们的内存池代码。
相信跟着我一起完成上面三个步骤,你一定对tcmalloc这个项目有了一定深度的了解。下面就开始吧:
备注:tcmalloc是全球⼤⼚Google开源的,可以认为当时顶尖的C++⾼⼿写出来的,他的知名度也 是⾮常⾼的,不少公司都在⽤它,Go语⾔直接⽤它做了⾃⼰内存分配器。
所以很多程序员是熟悉这个项⽬的,那么有好处,也有坏处。好处就是把这个项⽬理解扎实了,会很受⾯试官的认可。坏处就是 ⾯试官可能也⽐较熟悉项⽬,对项⽬会问得⽐较深,⽐较细。如果你对项⽬掌握得不扎实,那么就容易碰钉⼦。
我这里代码是基于Linux平台设计的,因为我想锻炼一下我的gdb调试能力,推荐新手用vs code来因为调试比较友好,当然了涉及到 Linux和Windows不同代码的部分我会说的。
2、整体架构
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。malloc本⾝其实已经很优秀,那么我们项⽬的原型tcmalloc就是在多线程⾼并发的场景下更胜⼀筹,所以这次 我们实现的内存池需要考虑以下⼏⽅⾯的问题。
1. 性能问题。
2. 多线程环境下,锁竞争问题。(主要是这个 ,malloc在1、3这部分还是很优秀的)
3. 内存碎⽚问题。
主要由以下3个部分构成:
1. thread_cache:线程缓存是每个线程独有的,⽤于⼩于256KB的内存的分配,线程从这⾥申请内存不需要加锁,每个线程独享⼀个cache,这也就是这个并发线程池⾼效的地⽅。
2. central_cache:中⼼缓存是所有线程所共享,thread_cache是按需从central_cache中获取一定量的对象。central_cache合适的时机回收thread_cache中的对象,避免⼀个线程占⽤了太多的内存,⽽其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的⽬的(负载均衡)。central_cache是存在竞争的,所以从这⾥取内存对象是需要加锁,⾸先这⾥⽤的是桶锁,其次只有thread_cache的没有内_存对象时才会找central_cache,所以这⾥竞争不会很激烈。
3. page_cache:⻚缓存是在central_cache缓存上⾯的⼀层缓存,存储的内存是以⻚为单位存储及分配的,central_cache没有内存对象时,从page_cache分配出⼀定数量的page,并切割成定⻓⼤⼩的⼩块内存,分配给central_cache。当⼀个span的⼏个跨度⻚的对象都回收以后,page_cache会回收central_cache满⾜条件的span对象,并且合并相邻的⻚,组成更⼤的⻚,缓解内存碎⽚的问题。
看到这里,大家可以自行去了解一下,内存碎片(内碎片、外碎片)
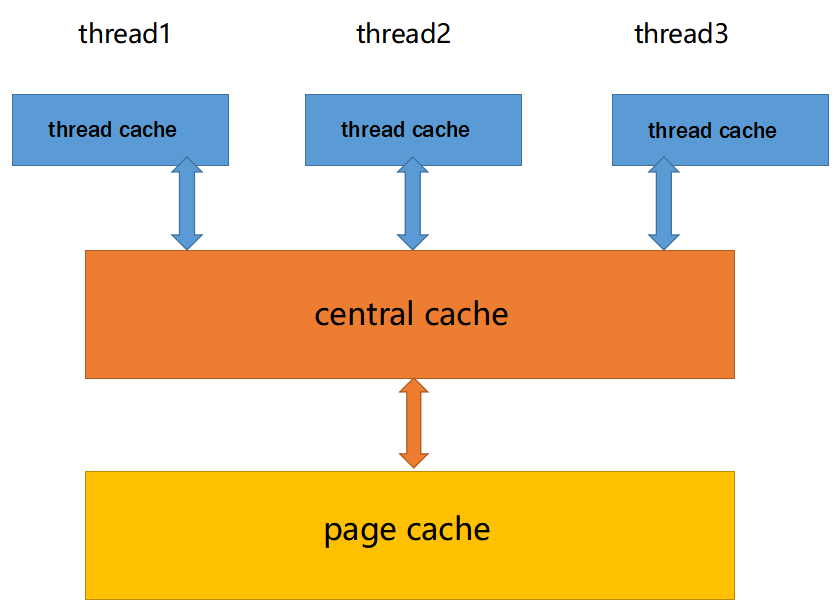
总的来说就是这三成架构
首先我们先从申请内存来进行设计,把三层都走一遍 , 然后再来进行内存释放的设计。
3、申请内存设计
先简单的说下,申请内存的流程,就是每个线程都有一个他自己的thread_cache(专用的),直接在thread_cache这里申请内存是不用加锁的直接拿
当thread_cache里面没有内存了,就去下一层central_cache里面拿,在没有就再去下一层page_cache里面拿,在没有,就去操作系统里面拿。
有了上述思想我们就来开始吧:
3.1 Thread_cache设计
3.1.1自由链表的概念:
其实很简单就是,链表都知道哈, 我们都知道数组在内存中是连续的,链表在内存中是不连续的。(这也就是一个可以拿下标 进行时间复杂度O(1) 的直接访问,另一个只能遍历 O(n) 的进行访问)
自由链表底层就是:内存中是连续 的链表 很多人就疑惑了?? 那为啥不用直接用数组
这里主要的就是内存好管理,且可以切成任意大小的单个内存。
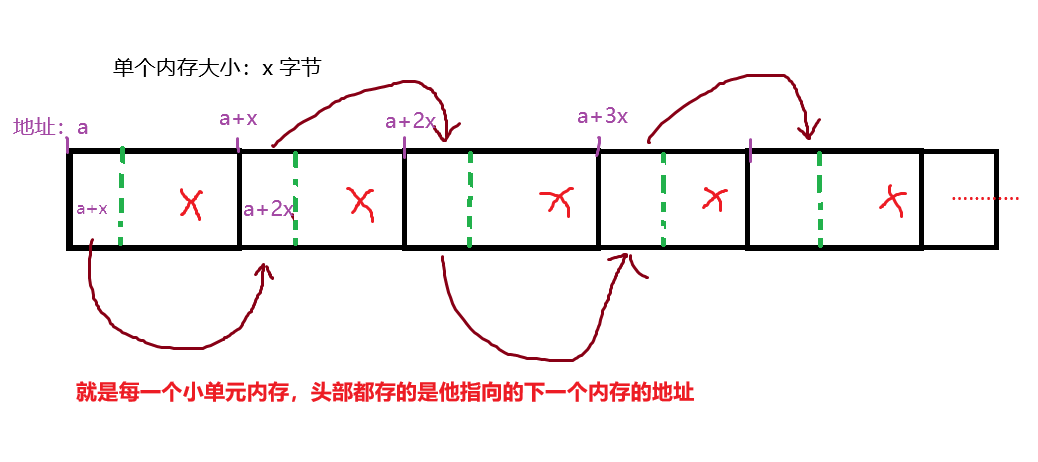
这里的优势就是 x可以任意设置 只要大于等于8字节 , 因为我们知道的指针大小为 4字节或者8字节
在者就是 中间任意拿走一个 直接改变一个 头部的指针这个链表依然是正常的
自由链表的结尾就是,最后一个单元 他是指向nullptr的来判断到结尾了
最后一个技巧: 就是如何访问他的头几个字节 来填入下一个单元的首地址 难点就是 指针大小和系统有关 可能4 可能8字节
*((void**)a)=a+x
a本来就是地址(void*)类型的 所以要强转(void**)类型 这样解引用 就是访问一个指针大小的位置 只要就能自动适应是4字节还是8字节了 当然了单个内存大小x 肯定是大于等与8字节的,因为这两种情况你都得满足。
3.1.2thread_cache设计
thread_cache是哈希桶结构,每个桶是⼀个按桶位置映射⼤⼩的内存块对象的⾃由链表。每个线程都 会有⼀个thread_cache对象,这样每个线程在这⾥获取对象和释放对象时是⽆锁的。
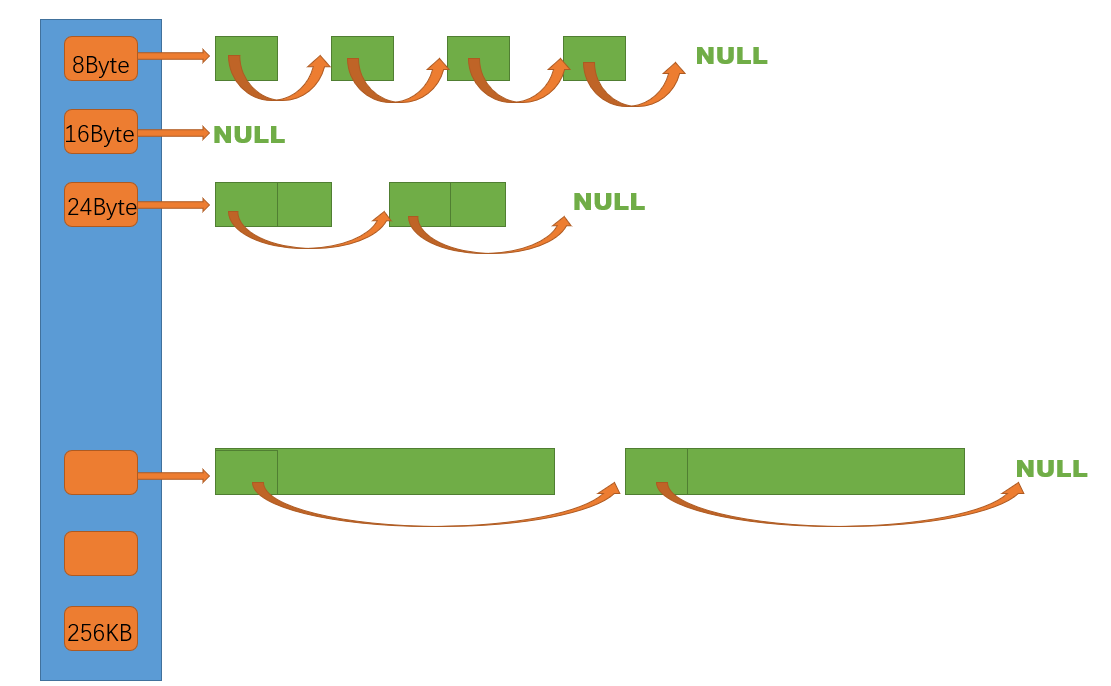
申请内存:
1. 当内存申请size<=256KB,先获取到线程本地存储的thread_cache 对象,计算size映射的哈希桶自由链表下标i。
2.如果⾃由链表_freeLists[i]中有对象,则直接Pop⼀个内存对象返回。
3. 如果_freeLists[i]中没有对象时,则批量从central_cache中获取⼀定数量的对象,插⼊到⾃由链表 并返回⼀个对象。
解释:这里为啥size<=256KB 这里你可以随便设置,200 300 500都行 其实在大多数编程的时候你一次性申请的空间都很小,所以这里设置256kb(256*1024字节)已经满足大多数场景的使用。
下面就是具体代码实现:
class Free_list
{
public:
Free_list() : _list_node(nullptr), _size(0) {}
void Push(void *node) // 头插 可能为一连串
{
void* left=node;
void* right=node;
int i=1;
while( *(void**)right )
{
right=*(void**)right;
i++;
}
(*(void **)right) = _list_node;
_list_node = left;
_size+=i;
}
void *Pop() // 头删
{
void *tem = _list_node;
_list_node = (*(void **)_list_node);
_size--;
return tem;
}
bool Empty()
{
return (_list_node == nullptr);
}
private:
void *_list_node;
size_t _size;
};
class Thread_cache
{
public:
Thread_cache()
{}
void *Allocate(size_t size) // 申请内存
{
if(size > MAX_Thread_memory)
{
throw std::invalid_argument("Thread_cache:: Allocate exceeds the limit");
}
int index=Calculate_index(size);
if( !_thread_cache[index].Empty())
{
return _thread_cache[index].Pop();
}
else
{
void* new_memory=Central_cache::Get_instance().Central_cache_Allocate(index,size); //这里传的要为实际分配的大小 而不是实际大小
_thread_cache[index].Push(new_memory);
return Allocate(index,size);
}
}
void *Allocate(size_t index ,size_t size) // 申请内存
{
return _thread_cache[index].Pop();
}
void Deallocate(void *ptr, size_t size) // 释放内存 size表示字节数
{
int index=Calculate_index(size);
_thread_cache[index].Push(ptr);
}
private:
Free_list _thread_cache[Hashi_Bucket_Size];
};不用完全看懂哈 理解了 我接下来说的点就行:
因为thread_cache是哈希桶结构,每一个桶下面是一个(固定大小的)自由链表
所以用一个类来封装了一下这个自由链表  方便我们从这个里面拿一个固定大小的内存,Push Pop操作
方便我们从这个里面拿一个固定大小的内存,Push Pop操作
然后它的成员就是 一个头节点_list_node指向自由链表的头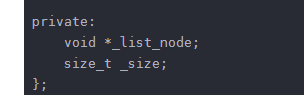
size用来记录 这个自由链表里面有挂了几个元素了(也就是 这个链表里面 有多少个 固定大小的内存)

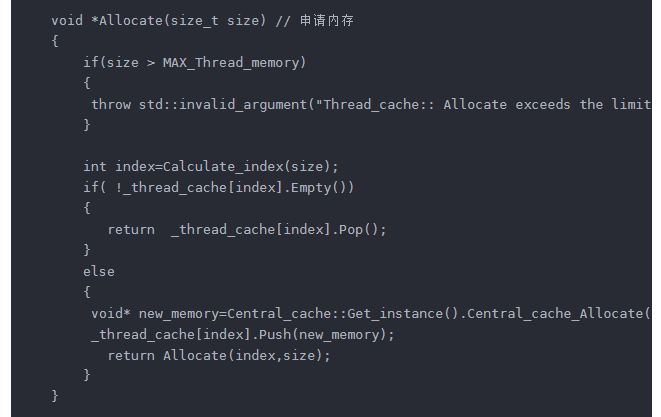
thread_cache 里面就是 用一个数组来存这些桶 这个数组的大小后面介绍(Hashi_Bucket_Size)
然后就是申请内存的函数了 Allocate 里面的MAX_Thread_memory 就是上面提到的258kb 因为我们设计的初衷就是 小于256kb的才在里面申请 所以用一个 抛异常的方式 来判断 这里设计为变量的形式(相当于用宏吧 但是不推荐) 就是方便后面你要改这个大小的话 直接在外面一个地方改就行 里面所有地方就都跟着改了哈
(刚开始学的时候 觉得直接写不就挺好 当你写一个项目 代码量上去之后 这种 常变量方式会好很多,不然你们去读源码的时候 为啥这么多宏定义 都是大佬一步一步走出来的经验 题外话哈)
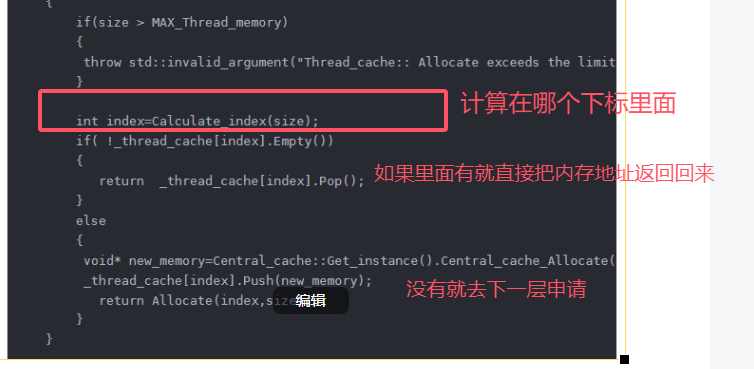
整体申请就是这个流程 很简单吧
现在一个新的问题就来了 这个![]() 数组放多少个合适,
数组放多少个合适, 这个下标是怎么计算的!!
这个下标是怎么计算的!!
这也就是第一层的关键了 当然了 tcmalloc这里的设计和我现在讲的不一样 他那边更复杂更精妙 当我们到读源码的阶段 再给大家介绍 (其实我也还没到这个步骤 等学完在来写博客 哈哈哈)
难点1:单位内存大小的设计
首先我们来考虑一个问题:申请的大小<=256kb 就是256*1024个字节
如果我们为每个大小 都设置一个内存块的话 就是 8~256*1024个桶
(也就是thread_cache  这个成员 数组下标为0的地方 挂的是单个大小为8字节的链表 下标为1的地方 挂的是大小为9字节的链表 ) 显然这是不科学的 这样来挂的话 得 256*1024- 7 26万多个个桶 你就按数组里面 Free_list大小为8字节(size_t的大小和一个指针大小) 也得256*1024*8除以1024 =1024M左右的空间 你为了挂这个内存池 得栈区打1G的内存才能用 这显然不科学
这个成员 数组下标为0的地方 挂的是单个大小为8字节的链表 下标为1的地方 挂的是大小为9字节的链表 ) 显然这是不科学的 这样来挂的话 得 256*1024- 7 26万多个个桶 你就按数组里面 Free_list大小为8字节(size_t的大小和一个指针大小) 也得256*1024*8除以1024 =1024M左右的空间 你为了挂这个内存池 得栈区打1G的内存才能用 这显然不科学
那你如果按 8来对齐的话 比如 Free_list[0]=8 Free_list[1]= 16 24 32 …… 这样下去
也得需要 256*1024/8= 128*256=32768个桶 换算过去 按一个桶8字节 也得256M 显然也不行
那如果取比较大 按 256 来对齐 也需要1024个桶 也就是8M 虽然空间我们可以接受 但是8M已经很大了 而且内存浪费的比较大 比方说 你实际需要100字节 而我们最小单位是 256字节 一下就浪费了156字节 比用的还多 显然是我们不能接受的
所以这里设计每个桶挂多大内存 也是一个技术难点 这里给出一种简单算法 除了小于8字节的空间 其他申请的空间 把内存浪费控制在了 12%以内
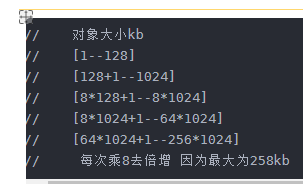
// 对象大小kb 对齐大小(其实就是下标每次加1 对应内存块增大多少) 哈希桶下标
// [1--128] 8kb(最小保证可以存储下指针) 2^3 [0-16) 128/8=16
// [128+1--1024] 16kb 2^4 [16-72) 56
// [8*128+1--8*1024] 128kb 2^7 [72-128) 56
// [8*1024+1--64*1024] 1024kb 2^10 [128-184) 56
// [64*1024+1--256*1024] 8*1024kb 2^13 [184-208) 24
// 每次乘8去倍增 因为最大为258kb 一共需要208个桶这种算法只需要208个桶 就能实现 好好琢磨一下
就是我 设置的单位内存 不是按固定大小增加的

这个数组小标 :
0下面挂的是8字节
1下面挂的是16字节
2下面挂的是24字节
……
15下面挂的是128字节 (从这往上 都是8字节的增长)
16下面挂的是128+16字节
17下面挂的是128+2*16字节
……
127下面挂的是128+56*16字节
在下面就是 128的增长 在下面就是 1024的增长 …………
这部分 每个部分对应的上限是 8倍的增长 最后是256的上限嘛 你如果要改 就8倍往上增长就行
这里可以带大家算一下整体 208*8 差不多1M的栈空间开销 可以接受
内存浪费问题上 除了 1-128 这个区间浪费的比较多点 架不住基数小嘛 128字节 随便浪费 反正不用了会回收回来
浪费率计算公式:(实际的大小-申请的大小)/ 实际的大小
申请的大小:就是你需要多少
实际的大小:就是操作系统给了你多少
[128+1 1024] 这个区间 实际大小可能为128+16 128+2*16 ……
显然实际大小越小 浪费了越大 所有分母就去128+16
为了使分子最大 那就申请的大小为129 实际分配了128+16 因为这里的内存对齐为16嘛
浪费率:15/144=10.412%
同理:
[8*128+1 8*1024] 127/(8*128+128)=11.024%
[8*1024+1 64*1024] 1023/(8*1014+1024)=11.1%
[64*1024+1 256*1024] (8*1024-1)/(64*1024+8*1024)=11.11%
显然这种处理方法是可以接受的 在合理的内存碎片内 而且所占空间不大
当然了这里 你们还可以继续优化 看这个变对齐大小还可以怎么设置 , 后面会介绍tcmalloc这个源码 看看大佬为啥叫大佬 他们是如何设计的
看到这里 大家 的第一层自己手写出来应该是没什么问题了 该讲的思路都讲了 只不过会有一些坑 我后面代码里会讲

有了上面的设计 这个函数的实现有很多 我这里就贴一下我的实现方式 不唯一哈
提供一个思路就是 你们可以对传进来的size 进行分区间 知道那个区间了 然后减掉区间 开始 除以对齐书 就知道这个区间的偏移量勒 然后加上下标 就可以算出来
// thread_cache
const static size_t MAX_Thread_memory = 258 * 1024;
const static size_t Hashi_Bucket_Size = 208; // Calculate_index(MAX_Thread_memory)+1 //数组下标从0开始的
size_t Calculate_index(size_t &size) // 把对齐之后的大小返回回去
{
if (size <= 0)
{
throw std::invalid_argument("Calculate_index size must be positive");
}
int i = 0;
int index = 0;
while (size - pow(8, i) * 128 > 0)
{
i++; // i表示 当前在第几层 也就是 pow(8,i)*128
}
int new_size; // 用来计算实际分配了多少内存的大小 就是对齐之后的大小 new_size>=size
if (i > 0)
new_size = pow(8, i - 1) * 128;
else
new_size = 0;
// std::cout << "i:" << i << std::endl;
if (i == 0)
{
if (size % 8 == 0)
index = size / 8 - 1;
else
index = size / 8;
new_size += (index + 1) * 8;
}
else
{
index += 16;
index += (i - 1) * 56;
int tem_size = size - pow(8, i - 1) * 128;
int base = pow(2, 3 * i + 1); // 对齐书
// cout << "tem_size:" << tem_size << endl;
// cout << "base:" << base << endl;
int index_add = 0;
if (tem_size % base == 0)
index_add += tem_size / base - 1;
else
index_add += tem_size / base;
new_size += (index_add + 1) * base;
index += index_add;
}
size=new_size;
return index;
}我这么写 不分区间 我想的是 通用性 就是我不设置最大范围256kb以内 按上面的对齐方法 依然可以用这个函数算 当然了这里无所谓哈
最重要的是 你要把你 对齐之后的大小 传出去 因为后面涉及到 大块内存 去切成 固定大小的小块内存 组成自由链表 所以你得知道 你对齐之后的大小 这里是个坑哈 后面切的时候一定注意!!!
这就是 thread_cache的全部设计 现阶段 你们先把申请的这三层打通 之后再去 释放 按这个思路来
这里再补充一下 TLS(Thread local storage) 线程的局部存储
场景介绍:
如上面我们创建了 thread_cache 我们线程在使用这个Allocate申请内存的时候,是不是得先有一个对象,才能调用 成员函数 而且每一个线程都有他自己 thread_cache 这显然不科学
我们在使用 new或者 malloc的时候 没有让你先创建一个对象吧 而是直接调用这个函数吧
我们第一想法是创建线程之前手动创建 thread_cache的实例 显然是行不通的 因为这样每一个线程都共用一个 就设计到锁的问题
那怎么做,才能像malloc 那样直接使用 , 这里就用到 TLS技术 不懂得 chatgpt一下 很简单的
(这里 Windows 和 Linux 的实现不一样 gpt一下 就行)
我这里以Linux为例:

两种方法 我就直接 thread_local来写了
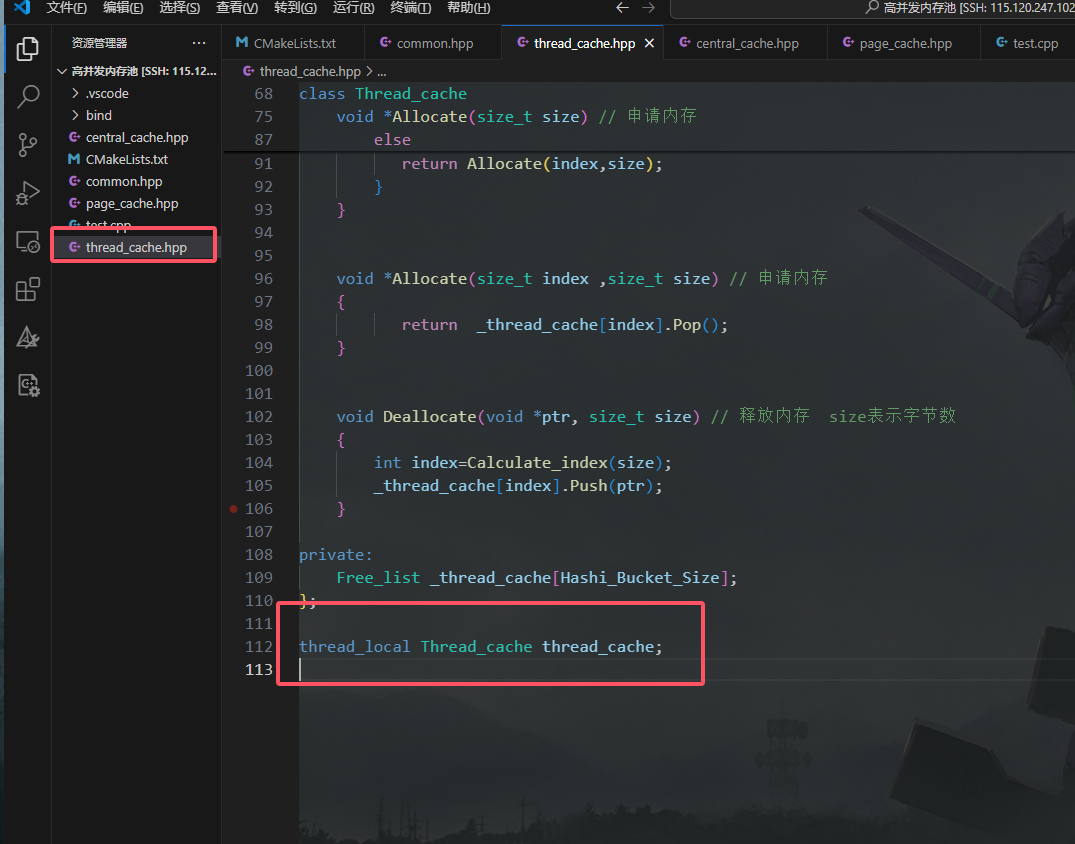
就在你thread_cache里面加一句这个就行了 就能实现
给大家测试一下 ,直接使用这个类就行 不用创建 变量
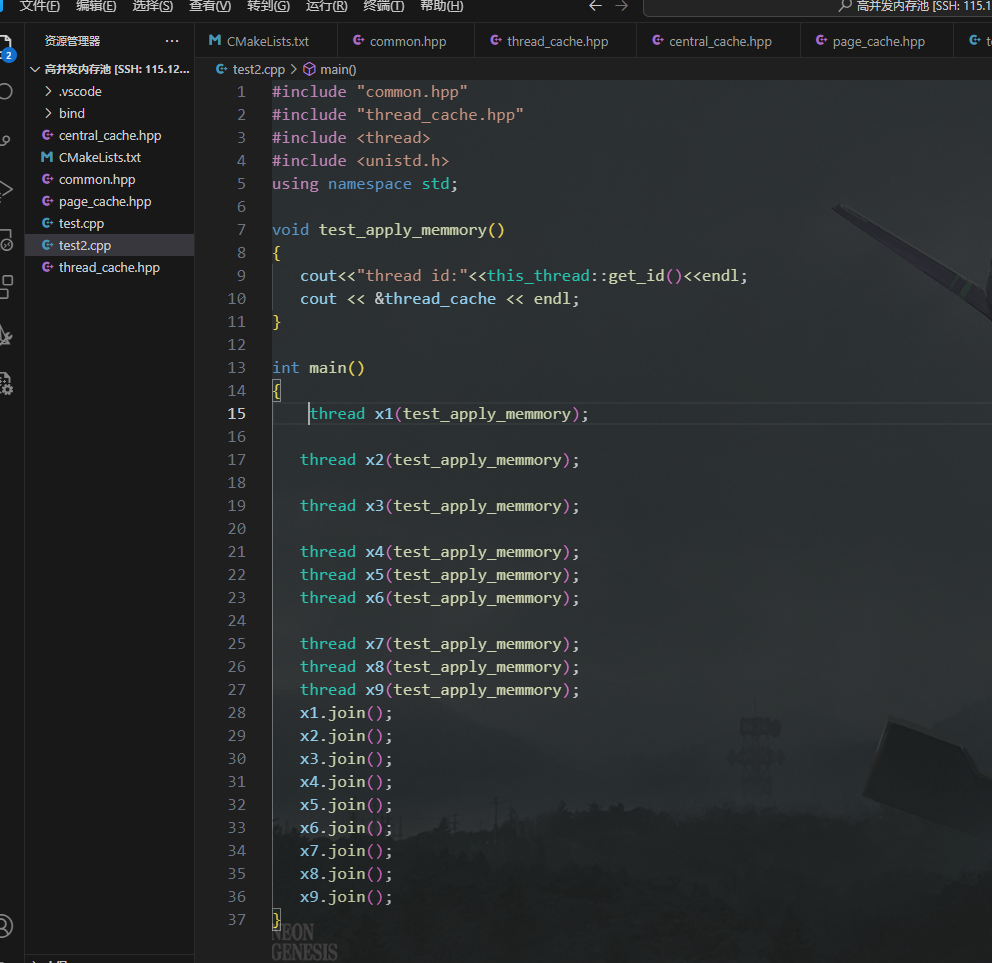
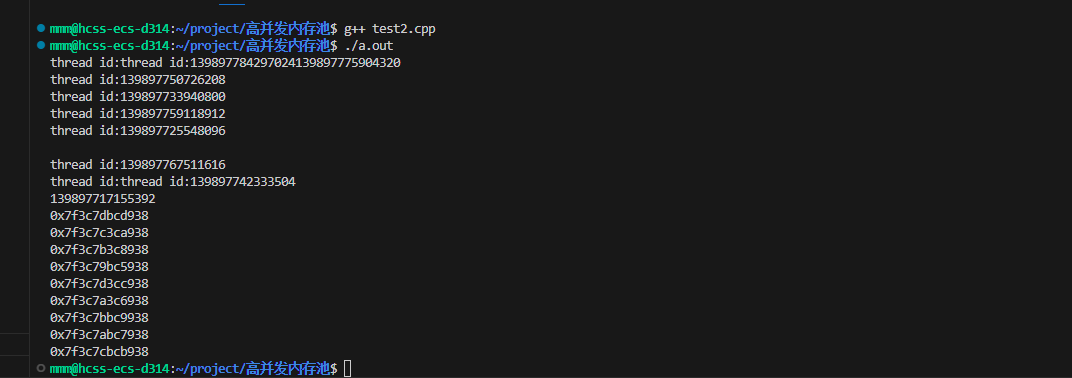
每一个地址都不一样 所以 这样就能像malloc那样 直接申请内存 而且每一个线程都用一个属于他自己的thread_cache 了
3.3 Central_cache设计
这个放在下一篇博客里面吧

















 6146
6146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









