




摘要:为解决实验室严格考勤问题,试行了弹性打卡制度,取得了不错的效果。本文档详细说明了制度细则、钉钉操作流程,并提供了原创的Python自动统计代码,可直接生成异常打卡值和总工时。
前言
现将制度详情及配套的自动统计方法公开,以便其他团队借鉴。弹性打卡制度刚试行不久,可能还有很多优化空间。欢迎大家有意见可以交流讨论。可以联系本人邮箱获得更快的反馈:211191511@qq.com。文章有很多自己生成的跳转链接,不知道怎么删掉,不用管。
一、实验室弹性作息制度
1. 概述
- 参与范围:实验室所有在读学生可自愿选择弹性打卡或沿用原先的打卡方式。
- 考勤周期:以周为单位统计,按月处理。每周按 6 个工作日计算。
- 时长要求:日均打卡至少 9 小时,即每周总时长需满足 54 小时。打卡时长不足者,津贴扣减 100元/周。
- 打卡规则:
- 每日需有偶数次打卡(即 2, 4, 6… 次),不能为奇数次。常规情况(
签到+签退)即为2次。 - 两次打卡前后间隔需超过20分钟(24:00前后时段除外)。
- 若签到后超过24:00离开,需在24:00前进行一次
签退,待超过24:00后,再进行一次签到,离开时最终签退。
- 每日需有偶数次打卡(即 2, 4, 6… 次),不能为奇数次。常规情况(
- 调整机制:同学可自主提出申请,经实验室老师评估上周科研推进情况后,可酌情调整打卡时限。
2. 打卡教程
(1)选择签到工具
在钉钉群内选择签到,不要选择打卡。


(2)签到
钉钉群内进行签到。签到类型需选择签到。

(3)签退
钉钉群内进行签退。签到类型需选择签退。

3. 补充条款
- 学校项目:参加新生心理测评、体检等学校要求的项目,不计入科研时长,需自行找补时间(该日打卡时长可灵活调整,但周总时长必须满足54小时)。
- 短时外出:前往其他教学楼递交个人材料(如综测表等),15分钟左右可返回的情况下,可以不签退。
- 接打电话:请在闻天楼内进行,避免随机抽查时不在场。
- 特殊情况处理:
- 出差/病假:按每天 9 小时计算。
- 事假:视具体情况而定。
- 周四晚运动:按 3 小时计算。
- 实验室会议、运动会、新生上课等:根据实际情况补打卡。
- 行为规范:严禁在实验室打游戏、听歌、看小说。违者:
- 一月内发现1次,本月按学校最低要求发放津贴;
- 一月内发现2次,本月取消津贴;
- 一月内发现3次,予以清退。
- 补卡:允许每周补卡1次。
- 作息建议:建议每日睡眠时间为 7±1 小时。
- 统计轮值:采用轮值制,每周由一名同学负责统计。有特殊情况可联系统计人说明。第
i周打卡情况在第i+1周内统计完毕即可。后续已修改为按月统计总时长达标即可。
4. 随机抽查
- 频次:不定时、不定次数。
- 方式:在微信群(为避免打扰,建议将钉钉群设置为免打扰)内随机抽取1名在场同学。该同学需在5分钟内,于钉钉群发送各屋现场照片,以核实在场情况。
- 造假处理:
- 签到后不在实验室科研,过后返回或以忘记签退为由辩解,均视为造假,违背诚信原则。
- 第1次:按学校要求发放津贴并警告;
- 第2次:予以清退。
- 设备号:后台会记录设备号,每人手机设备号唯一(从入学至毕业不变)。如更换新手机,务必提前说明。
- 备注:随机抽查如在原工作时间内,沿用旧打卡方式的同学也需出现在照片中(外出科研任务除外),否则按迟到/早退处理。
二、自动化统计流程
1.钉钉群管理员从钉钉导出“签到报表.xlsx”,只保留“已签到”的分表,只保留所需的四列即可。

2.统计微信群里所有补卡和请假的情况放到excel中,并在导出报表打卡明细中进行补卡。
<弹性打卡群>

<补卡备注>

3.将“签到报表.xlsx”重命名为input.xlsx,python代码与input文件在同一文件夹下,直接运行输出output,里面只需要看总时间和异常值两个分表即可。

4.修正异常值,对output中异常值的分表中有问题的信息发到微信群,通过反馈进行补卡,修复全部异常值再重新运行代码,导出新的output文件。
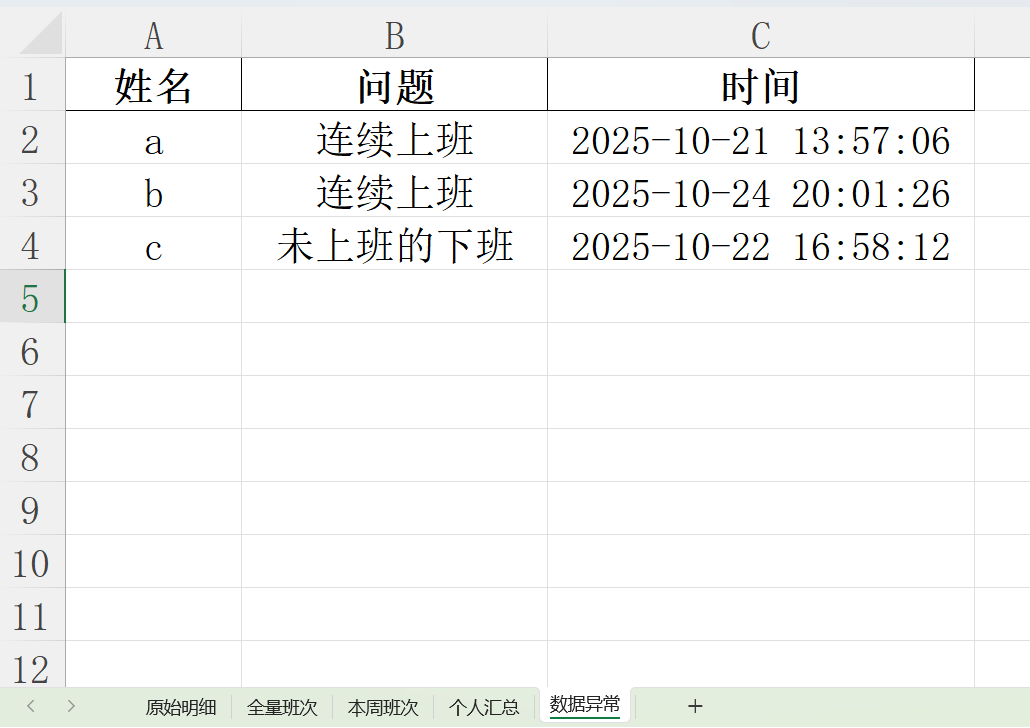
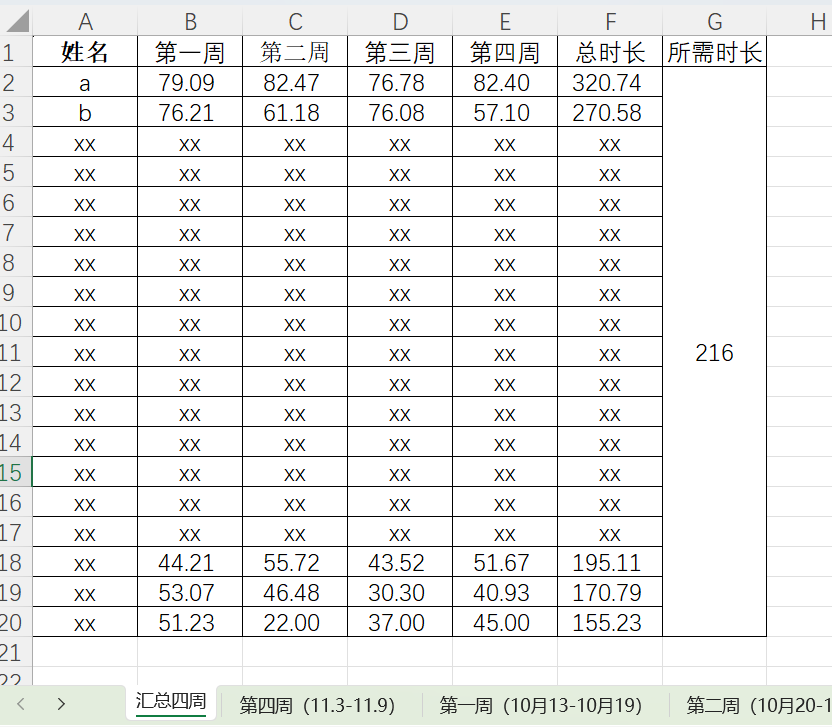
5.通过output文件中个人统计的分表中获取每个人打卡时长,再对请假和补时间的加进去,写一个“总时长统计.xlsx”(按姓名降序方便复制时间)
<每周明细>

<汇总四周数据>
三、python 代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
import re
from datetime import timedelta
# ========= 配置 =========
input_path = r"input.xlsx" # ← 改成你的输入文件(xlsx/csv/tsv,列:姓名 日期 时间 签到类型)
output_xlsx = "output.xlsx" # ← 想导出Excel就填路径,例如 r"weekly_times.xlsx";留空则不导出
# =======================
# ---------- 规范化 ----------
def normalize_time(t: str) -> str:
"""把 'H:MM'/'HH:MM'/'HH:MM:SS'(含全角冒号/隐藏空格)统一为 'HH:MM:SS'。"""
t = str(t).replace(':', ':').replace('\u00A0', ' ')
t = re.sub(r'\s+', ' ', t).strip()
m = re.match(r'^(\d{1,2}):(\d{2})(?::(\d{2}))?$', t)
if not m:
raise ValueError(f"非法时间: {t!r}")
hh, mm, ss = int(m.group(1)), int(m.group(2)), int(m.group(3) or 0)
return f"{hh:02d}:{mm:02d}:{ss:02d}"
def normalize_date(d: str) -> str:
"""把日期统一为 YYYY-MM-DD,容忍 '2025年10月20日'/'2025/10/20' 等格式。"""
d = str(d).replace('\u00A0', ' ')
d = d.replace('年', '-').replace('月', '-').replace('日', '')
d = re.sub(r'\s+', ' ', d).strip()
try:
pd.to_datetime(d, format="%Y-%m-%d")
return d
except Exception:
dt = pd.to_datetime(d, errors="raise")
return dt.strftime("%Y-%m-%d")
def hhmm_from_seconds(sec: int) -> str:
mins = int(round(sec / 60))
return f"{mins // 60:02d}:{mins % 60:02d}"
# ---------- 读取 ----------
def read_input(path: str) -> pd.DataFrame:
if path.lower().endswith(".csv"):
df = pd.read_csv(path, dtype=str)
elif path.lower().endswith((".tsv", ".txt")):
df = pd.read_csv(path, dtype=str, sep="\t")
else:
df = pd.read_excel(path, dtype=str)
need = {"姓名", "日期", "时间", "签到类型"}
if not need.issubset(set(df.columns)):
raise ValueError(f"缺少必要列:{need},实际列:{list(df.columns)}")
df = df[list(need)].copy().astype(str)
df["姓名"] = df["姓名"].str.replace('\u00A0', ' ', regex=False).str.strip()
df["签到类型"] = df["签到类型"].str.strip()
# 逐行规范
df["日期"] = df["日期"].apply(normalize_date)
df["时间"] = df["时间"].apply(normalize_time)
# 合成时间戳
dt_str = (df["日期"].str.replace('\u00A0', ' ', regex=False).str.strip()
+ " " +
df["时间"].str.replace('\u00A0', ' ', regex=False).str.strip())
dt_str = dt_str.str.replace(r"\s+", " ", regex=True).str.strip()
ts = pd.to_datetime(dt_str, format="%Y-%m-%d %H:%M:%S", errors="coerce")
bad = df[ts.isna()][["姓名", "日期", "时间", "签到类型"]]
if not bad.empty:
print("【警告】以下行无法解析为时间戳(已忽略):")
print(bad.to_string(index=False))
df = df[~ts.isna()].copy()
df["ts"] = ts[~ts.isna()]
return df
# ---------- 配对(全量) ----------
def pair_all_shifts(clean_df: pd.DataFrame):
"""在全量数据上,按人配对上/下班;连续上班=>自动闭合上一段。返回(班次df, 异常df)。"""
df = clean_df.sort_values(["姓名", "ts", "签到类型"]).copy()
dup_mask = df.duplicated(subset=["姓名", "ts", "签到类型"], keep="first")
dups = df[dup_mask]
base = df[~dup_mask]
anomalies = []
shift_rows = []
for name, g in base.groupby("姓名", sort=True):
g = g.sort_values("ts")
open_start = None
for _, r in g.iterrows():
ts, typ = r["ts"], r["签到类型"]
if typ == "上班":
if open_start is None:
open_start = ts
else:
# 自动闭合上一段
anomalies.append({"姓名": name, "问题": "连续上班(已自动闭合上一段)", "时间": ts})
shift_rows.append({
"姓名": name,
"开始时间": open_start,
"结束时间": ts,
"时长(秒)": int((ts - open_start).total_seconds())
})
open_start = ts
elif typ == "下班":
if open_start is None:
anomalies.append({"姓名": name, "问题": "无上班的下班(忽略)", "时间": ts})
else:
if ts >= open_start:
shift_rows.append({
"姓名": name,
"开始时间": open_start,
"结束时间": ts,
"时长(秒)": int((ts - open_start).total_seconds())
})
else:
anomalies.append({"姓名": name, "问题": "下班早于上班(忽略该对)", "时间": ts})
open_start = None
else:
anomalies.append({"姓名": name, "问题": f"未知签到类型: {typ}", "时间": ts})
if open_start is not None:
anomalies.append({"姓名": name, "问题": "存在未下班记录(未计入)", "时间": open_start})
for _, r in dups.iterrows():
anomalies.append({"姓名": r["姓名"], "问题": "重复记录(已去重)", "时间": r["ts"]})
shifts = pd.DataFrame(shift_rows)
anom_df = pd.DataFrame(anomalies).sort_values(["姓名", "时间"]) if anomalies else \
pd.DataFrame(columns=["姓名", "问题", "时间"])
return shifts, anom_df
# ---------- 周裁剪 ----------
def clip_shifts_to_week(shifts: pd.DataFrame, week_start: pd.Timestamp, week_end: pd.Timestamp) -> pd.DataFrame:
"""把班次裁剪到 [week_start, week_end) 区间,仅保留有交集的部分。"""
if shifts.empty:
return shifts.copy()
a = shifts.copy()
a["开始剪"] = a["开始时间"].where(a["开始时间"] >= week_start, week_start)
a["结束剪"] = a["结束时间"].where(a["结束时间"] <= week_end, week_end)
a = a[a["结束剪"] > a["开始剪"]].copy()
a["时长(秒)"] = (a["结束剪"] - a["开始剪"]).dt.total_seconds().astype(int)
a["日期"] = a["开始剪"].dt.date.astype(str)
return a[["姓名", "开始剪", "结束剪", "日期", "时长(秒)"]].rename(
columns={"开始剪": "开始时间", "结束剪": "结束时间"}
)
# ---------- 主流程 ----------
def main():
df = read_input(input_path)
if df.empty:
print("没有可统计的数据。")
return
# 全量配对
shifts_all, anom = pair_all_shifts(df)
# 自动确定“本周”区间(以最早日期所在周为周一~周日)
first_day = df["ts"].dt.floor("D").min().date()
week_start = pd.Timestamp(first_day) - timedelta(days=pd.Timestamp(first_day).weekday())
week_end = week_start + timedelta(days=7) # 半开区间上界
# 裁剪到本周
shifts = clip_shifts_to_week(shifts_all, week_start, week_end)
# 汇总
if shifts.empty:
print(f"本周({week_start.date()} ~ {(week_end - timedelta(days=1)).date()})无可统计班次。")
return
totals = shifts.groupby("姓名", as_index=False)["时长(秒)"].sum()
totals["时长(小时)"] = totals["时长(秒)"] / 3600.0
totals["总计(HH:MM)"] = totals["时长(秒)"].apply(hhmm_from_seconds)
totals = totals.sort_values("时长(秒)", ascending=False)
# 控制台输出
print("=== 本周区间 ===")
print(f"{week_start.date()} ~ {(week_end - timedelta(days=1)).date()}")
print("\n=== 本周个人总工时 ===")
for _, r in totals.iterrows():
print(f"{r['姓名']}: {r['总计(HH:MM)']} ({r['时长(小时)']:.2f} 小时)")
if not anom.empty:
# 仅提示条数;需要可改为打印前若干条
print(f"\n(提示)发现 {len(anom)} 条异常记录;如需导出查看请设置 output_xlsx。")
# 可选:导出 Excel
if output_xlsx:
with pd.ExcelWriter(output_xlsx) as w:
raw_export = df.sort_values(["姓名", "ts"]).rename(columns={"ts": "时间戳"})
raw_export.to_excel(w, sheet_name="原始明细", index=False)
shifts_all.sort_values(["姓名", "开始时间"]).to_excel(w, sheet_name="全量班次", index=False)
shifts.sort_values(["姓名", "开始时间"]).to_excel(w, sheet_name="本周班次", index=False)
totals.to_excel(w, sheet_name="个人汇总", index=False)
if not anom.empty:
anom.to_excel(w, sheet_name="数据异常", index=False)
print(f"\n已导出:{output_xlsx}")
if __name__ == "__main__":
main()


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









