




 这篇博客详细介绍了如何实现山羊拉丁文的转换,包括解析输入句子、判断元音和辅音、添加后缀以及附加字母'a'的过程。通过示例代码展示了两种不同的解决方案,分别是基于字符串操作和利用哈希集合判断元音的方法。此外,还提供了官方的解决方案,强调了在处理边界情况时的注意事项,以及算法的时间和空间复杂度分析。
这篇博客详细介绍了如何实现山羊拉丁文的转换,包括解析输入句子、判断元音和辅音、添加后缀以及附加字母'a'的过程。通过示例代码展示了两种不同的解决方案,分别是基于字符串操作和利用哈希集合判断元音的方法。此外,还提供了官方的解决方案,强调了在处理边界情况时的注意事项,以及算法的时间和空间复杂度分析。
题目描述
给你一个由若干单词组成的句子 sentence ,单词间由空格分隔。每个单词仅由大写和小写英文字母组成。
请你将句子转换为 “山羊拉丁文(Goat Latin)”(一种类似于 猪拉丁文 - Pig Latin 的虚构语言)。山羊拉丁文的规则如下:
- 如果单词以元音开头(
'a','e','i','o','u'),在单词后添加"ma"。
例如,单词
"apple"变为"applema"。
- 如果单词以辅音字母开头(即,非元音字母),移除第一个字符并将它放到末尾,之后再添加"ma"。
例如,单词
"goat"变为"oatgma"。
- 根据单词在句子中的索引,在单词最后添加与索引相同数量的字母
'a',索引从 1 开始。
例如,在第一个单词后添加
"a",在第二个单词后添加"aa",以此类推。
返回将 sentence 转换为山羊拉丁文后的句子。
示例 1:
输入:sentence = “I speak Goat Latin”
输出:“Imaa peaksmaaa oatGmaaaa atinLmaaaaa”
示例 2:
输入:sentence = “The quick brown fox jumped over the lazy dog”
输出:“heTmaa uickqmaaa rownbmaaaa oxfmaaaaa umpedjmaaaaaa overmaaaaaaa hetmaaaaaaaa azylmaaaaaaaaa ogdmaaaaaaaaaa”
提示:
- 1 <= sentence.length <= 150
- sentence 由英文字母和空格组成
- sentence 不含前导或尾随空格
- sentence 中的所有单词由单个空格分隔
答案
我的代码
/**
* @Author: Ljx
* @Date: 2022/4/21 8:04
* @role: https://leetcode-cn.com/problems/goat-latin/
*/
public class 山羊拉丁文 {
public static void main(String[] args) {
System.out.println(toGoatLatin("The quick brown fox jumped over the lazy dog"));
}
public static String toGoatLatin(String sentence) {
//定义返回结果
StringBuilder res = new StringBuilder();
//定义累加字符串
StringBuilder string = new StringBuilder("maa");
for (int i = 0; i < sentence.length(); i++) {
//将每个单词第一个字符转换为小写字符串
String s = String.valueOf(sentence.charAt(i)).toLowerCase();
//找到下一个空格位置
int i1 = sentence.indexOf(" ", i);
//判断每个单词第一个字符是否为元音字母
boolean judge = "a".equals(s) || "e".equals(s) || "i".equals(s) || "o".equals(s) || "u".equals(s);
if (i1 != -1) { //如果找到下一个空格位置执行以下操作
if (judge) { //如果是元音字母
res.append(sentence, i, i1);
} else { //如果不是元音字母
res.append(sentence, i + 1, i1);
//将单词第一个字母添加到末尾
res.append(sentence.charAt(i));
}
//添加后缀
res.append(string);
//指针移动到下一个字母
i = i1;
}else {
//如果没有找到下一个空格位置执行以下操作
if (judge) { //如果是元音字母
res.append(sentence.substring(i));
} else { //如果不是元音字母
res.append(sentence.substring(i+1));
//将单词第一个字母添加到末尾
res.append(sentence.charAt(i));
}
//添加后缀
res.append(string);
return res.toString();
}
// 结果加空格
res.append(" ");
//后缀加“a”
string.append("a");
}
return res.toString();
}
}
其他答案
class Solution {
public String toGoatLatin(String sentence) {
List list=Arrays.asList('a','e','i','o','u','A','E','I','O','U');
String[] str=sentence.split(" ");
int n=str.length;
StringBuffer sb=new StringBuffer();
for(int i=0;i<n;i++){
if(list.contains(str[i].charAt(0))){
sb.append(str[i]);
}
else{
sb.append(str[i].substring(1,str[i].length()));
sb.append(str[i].charAt(0));
}
sb.append("ma");
for(int j=0;j<i+1;j++) sb.append('a');
if(i!=n-1) sb.append(' ');
}
return sb.toString();
}
}
官网答案
找到每一个单词 + 模拟
思路与算法
我们可以对给定的字符串 sentence 进行一次遍历,找出其中的每一个单词,并根据题目的要求进行操作。
在寻找单词时,我们可以使用语言自带的 split() 函数,将空格作为分割字符,得到所有的单词。为了节省空间,我们也可以直接进行遍历:每当我们遍历到一个空格或者到达 sentence 的末尾时,我们就找到了一个单词。
当我们得到一个单词 w 后,我们首先需要判断 w 的首字母是否为元音字母。我们可以使用一个哈希集合 vowels 存储所有的元音字母 aeiouAEIOU,这样只需要判断 w 的首字母是否在 vowels 中。如果是元音字母,那么单词本身保持不变;如果是辅音字母,那么需要首字母移到末尾,这里使用语言自带的字符串切片函数即可。在这之后,我们需要在末尾添加 m 以及若干个 a,因此可以使用一个变量 cnt 记录需要添加的 a 的个数,它的初始值为 1,每当我们得到一个单词,就将它的值增加 1。
class Solution {
public String toGoatLatin(String sentence) {
Set<Character> vowels = new HashSet<Character>() {{
add('a');
add('e');
add('i');
add('o');
add('u');
add('A');
add('E');
add('I');
add('O');
add('U');
}};
int n = sentence.length();
int i = 0, cnt = 1;
StringBuffer ans = new StringBuffer();
while (i < n) {
int j = i;
while (j < n && sentence.charAt(j) != ' ') {
++j;
}
++cnt;
if (cnt != 2) {
ans.append(' ');
}
if (vowels.contains(sentence.charAt(i))) {
ans.append(sentence.substring(i, j));
} else {
ans.append(sentence.substring(i + 1, j));
ans.append(sentence.charAt(i));
}
ans.append('m');
for (int k = 0; k < cnt; ++k) {
ans.append('a');
}
i = j + 1;
}
return ans.toString();
}
}
复杂度分析
- 时间复杂度:O(n^2),其中 n 是字符串 sentence 的长度。虽然我们对字符串只进行了常数次遍历,但是返回的字符串长度的数量级是 O(n^2) 的。考虑最坏的情况,字符串 sentence 包含 7575 个单词 a,此时返回的字符串的长度为:
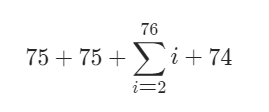
这四部分分别为:单词 a 的长度,添加的 m 的长度,添加的 a 的长度,空格的长度。
- 空间复杂度:O(n^2) 或 O(n),取决于使用的语言的字符串是否可修改。如果可以修改,我们只需要 O(n) 的空间临时存储字符串切片;如果不可以修改,我们需要 O(n^2) 的空间临时存储所有单词修改后的结果。注意这里不计入返回字符串使用的空间。

















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









