




 本文详细解释了在JDK1.7中,当两个线程并发扩容HashMap时,由于头插法操作可能导致链表顺序反转,从而引发死循环的情况。讨论了问题发生的条件和解决思路。
本文详细解释了在JDK1.7中,当两个线程并发扩容HashMap时,由于头插法操作可能导致链表顺序反转,从而引发死循环的情况。讨论了问题发生的条件和解决思路。
HashMap多线程扩容导致死循环解析(JDK1.7)
先上源码
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
// 1.保存下一次循环要操作的元素
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
// 2.采用头插法将e元素插入到链表头部
e.next = newTable[i];
newTable[i] = e;
// 3.遍历到下一个元素
e = next;
}
}
}
前提:
- 两个线程同时扩容同一个hashmap,并且两个线程都已经执行到获取第一个元素的next(步骤1)
- 前两个元素重新计算下标后没有改变位置
- 第一个线程将扩容执行完毕,另一个线程才开始下一步操作
由于头插法的原因,再次执行头插法的时候会将原来的链表顺序反过来,所以当第一个线程执行完扩容之后会将顺序从
1->2->3 到 3->2->1
线程二第一次执行插入结束后
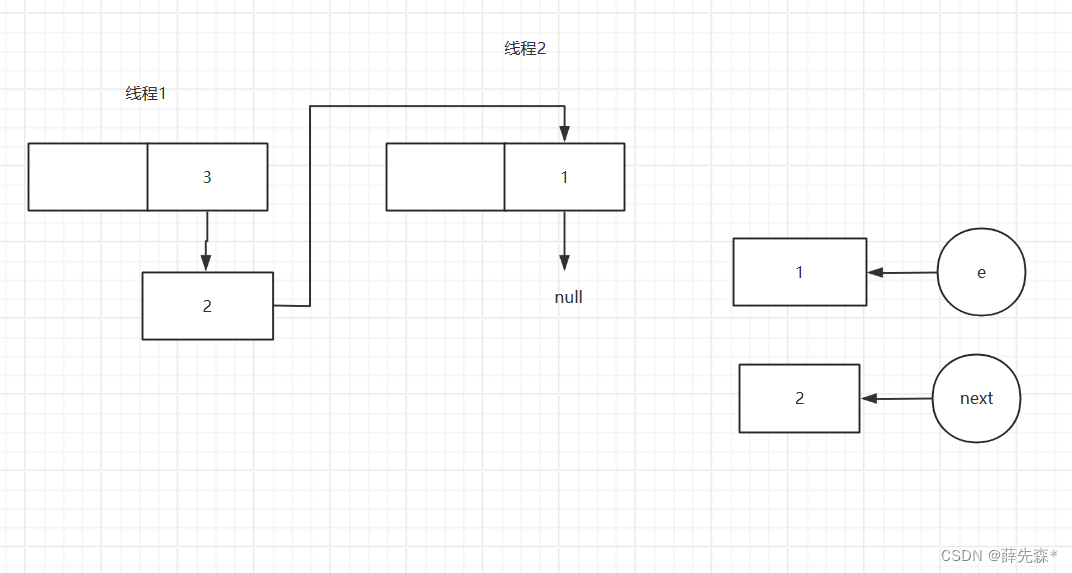
线程二准备第二次循环结束后
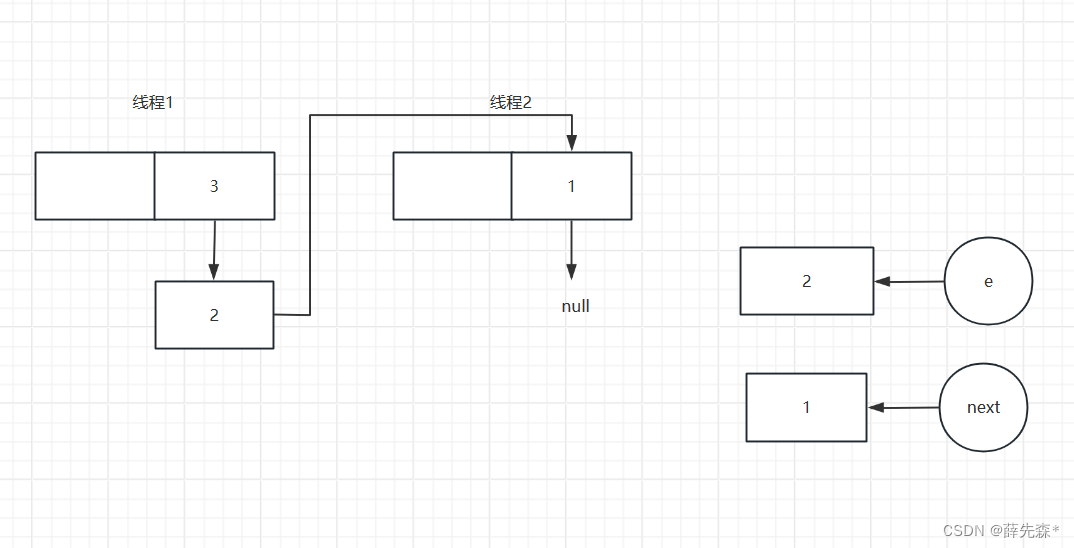
线程二第二次执行插入结束后
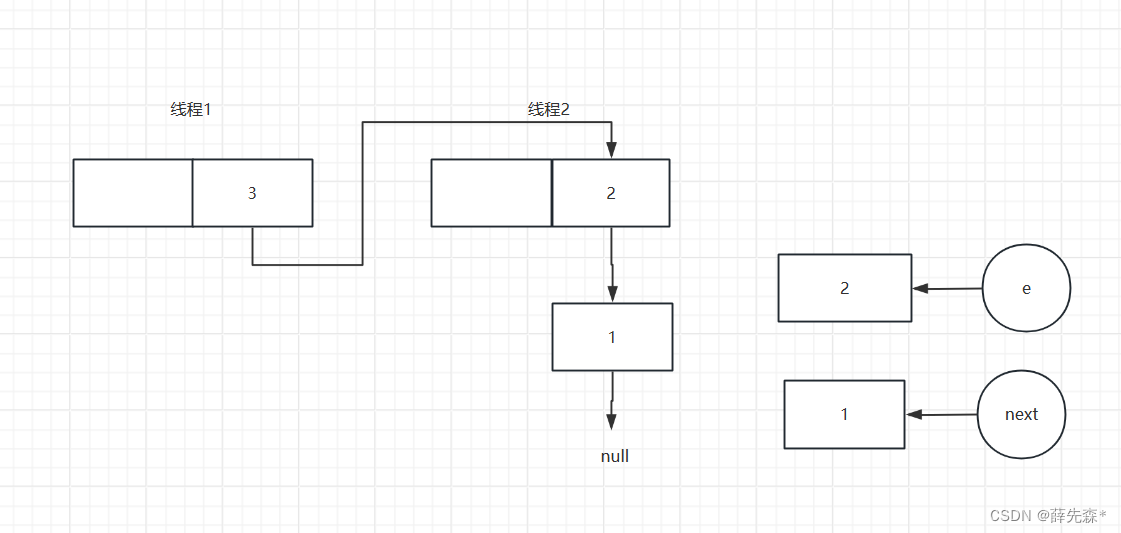
线程二准备第二次循环结束后
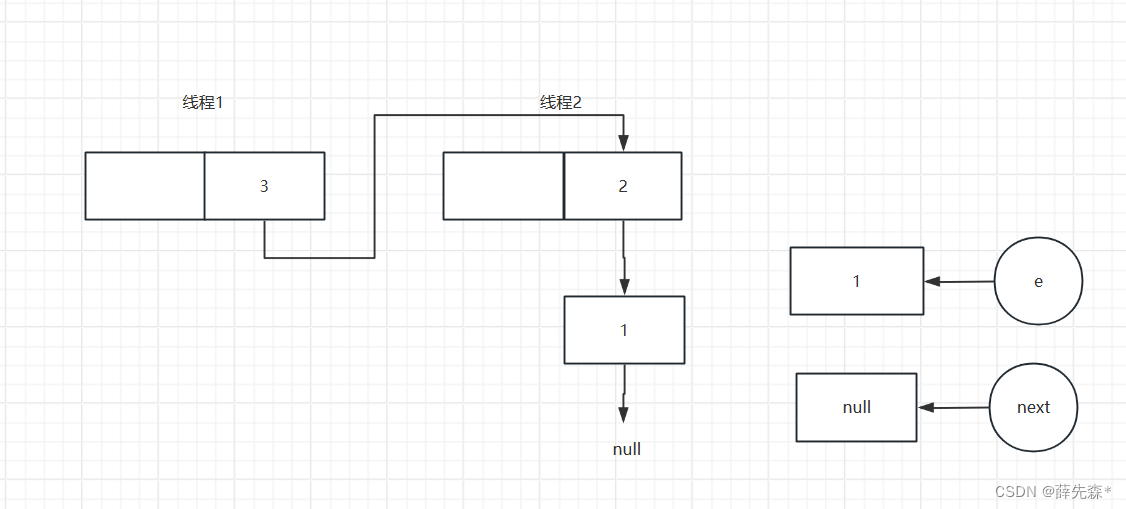
线程二第三次执行插入结束后
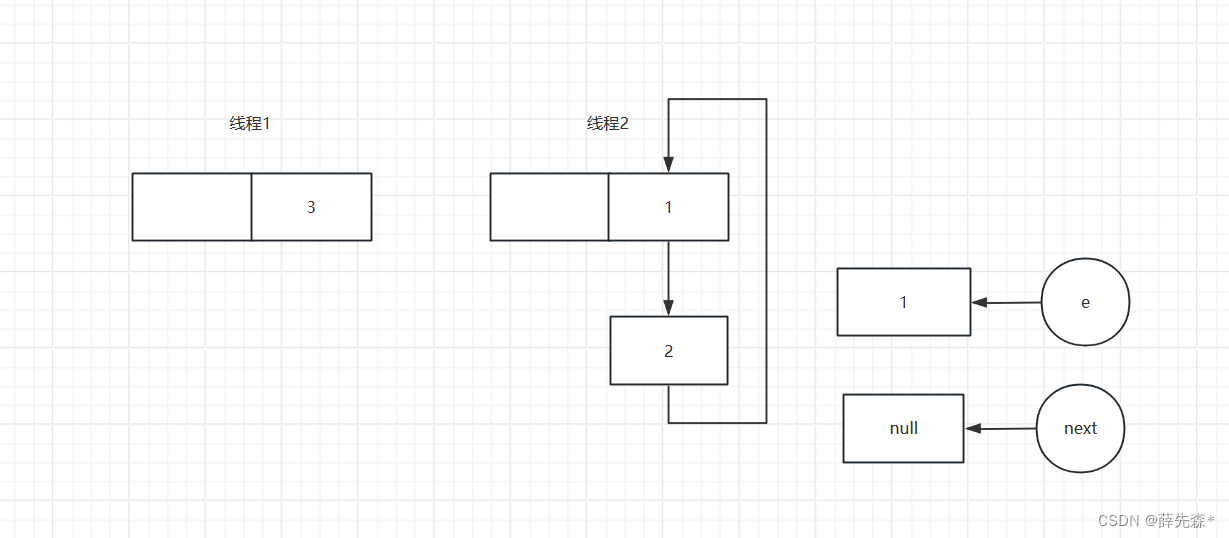
线程二准备第三次循环结束后
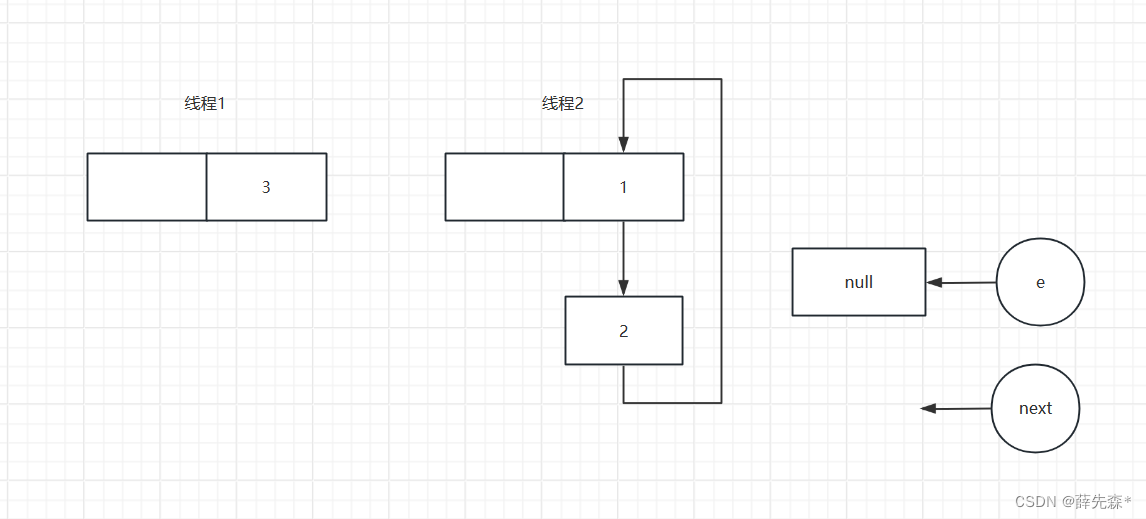
最后由于e等于null,退出循环,当下次遍历到该元素时就会进入死循环


















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











