



 本文详细介绍了Java集合框架中的HashSet和TreeSet。HashSet基于哈希表实现,不允许重复元素,存储时会根据hashCode和equals进行判断。而TreeSet采用二叉树结构,元素默认按自然排序,存储自定义类时需实现Comparable接口。同时,文章还讨论了如何通过Comparator实现自定义排序。
本文详细介绍了Java集合框架中的HashSet和TreeSet。HashSet基于哈希表实现,不允许重复元素,存储时会根据hashCode和equals进行判断。而TreeSet采用二叉树结构,元素默认按自然排序,存储自定义类时需实现Comparable接口。同时,文章还讨论了如何通过Comparator实现自定义排序。
简述
set 集合是顶级集合接口Collection的一个继承接口
set集合下有两个实现类HashSet、TreeSet
HashSet数据结构基于哈希表(散列表),HashSet特征有不可重复、无序(输出顺序与输入顺序不同)
TreeSet数据结构基于二叉树,特征为有序
HashSet类
HashSet类是Set集合的一个实现类,可以做到去重复
不可重复
将数据存入HashSet中时,会先调用hashCode方法判断存入数据的hash值,如果集合中没有hash值相同的元素,则会直接存入集合当中。如果有相同的hash值就会调用equals方法,若比较结果返回true就不会存入集合当中。
当存储类时,需要重写hasCode和equals方法
@Override
public int hashCode() {
return this.gage;
}
@Override
public boolean equals(Object obj) {
//如果名字和年龄相同认为是同一个
Dog d=(Dog)obj;
if(this.gname.equals(d.gname))//如果名字相同
return true;
return false;
}
HashSet<Dog> hs1=new HashSet<Dog>();
Dog d4=new Dog("葛二蛋", 2);
Dog d5=new Dog("葛二蛋", 2);
Dog d6=new Dog("王富贵", 4);
hs1.add(d4);//hash
hs1.add(d5);//hash+equals
hs1.add(d6);//hash
System.out.println(hs1.size());//不可重复,所以长度为2
TreeSet类
TreeSet类是Set的一个实现类,其数据结构为二叉树。
二叉树的结构
左小右大(左子树的键值小于根的键值,右子树的键值大于根的键值)
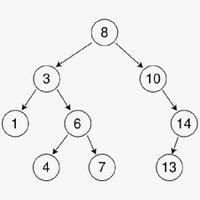
自然排序:里面的对象具备排序的方法
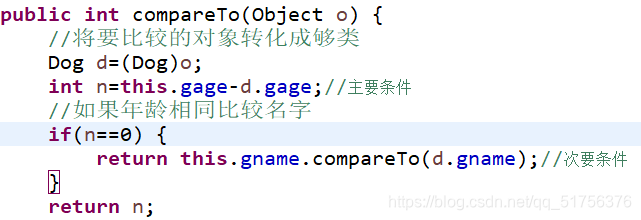
使用TreeSet存储类时,需要实现Comparable接口,否则输出集合会报错


当自定义的类重写Comparable接口里的方法后,在方法中只有一个条件时输出集合只会有一个对象,如按年龄从小到大输出,有相同年龄是只会输出一个

这时需要加上次要条件,以防数据丢失

选择器排序:对象不需要具备排序功能,给对象写一个排序的选择器
创建一个类实现Comparator,重写方法和重写自然排序方法大致相同
package com.util;
import java.util.Comparator;
import com.entity.Dog;
public class DogTools implements Comparator<Dog>{
@Override
public int compare(Dog o1, Dog o2) {
int n=o1.getGage()-o2.getGage();//主要条件
//如果年龄相同比较名字
if(n==0) {
return o1.getGname().compareTo(o2.getGname());//次要条件
}
return n;
//>0
//=0
//<0
}
}
实例化TreeSet时传入一个排序器
TreeSet<Dog> tsa=new TreeSet<Dog>(new DogTools());
Dog dd=new Dog("王婷", 2);
Dog de=new Dog("邓海焘", 2);
Dog df=new Dog("猴新品", 4);
tsa.add(dd);
tsa.add(de);
tsa.add(df);

















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









