




目录
PYTorch使用 torch.nn.CrossEntropyLoss()交叉熵实现softmax层和loss计算
1、基础知识
softmax层解释
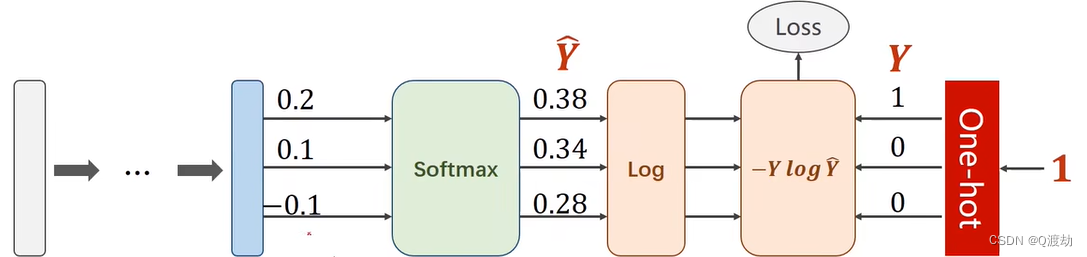
softmax层先对0.2、0.1、-0.1分别取对数,得到e^0.2 = 1.2, e^0.1 = 1.1,e^-0.1 = 0.9,然后sum = e^0.2 + e^0.1 + e^-0.1 = 3.2,因此 Y^1 = e^0.2/(e^0.2 + e^0.1 + e^-0.1) = 1.2 / 3.2 = 0.38,以此类推其他的,得到 Y^2 = 0.34,Y^3 = 0.28
softmax层和loss计算代码实现
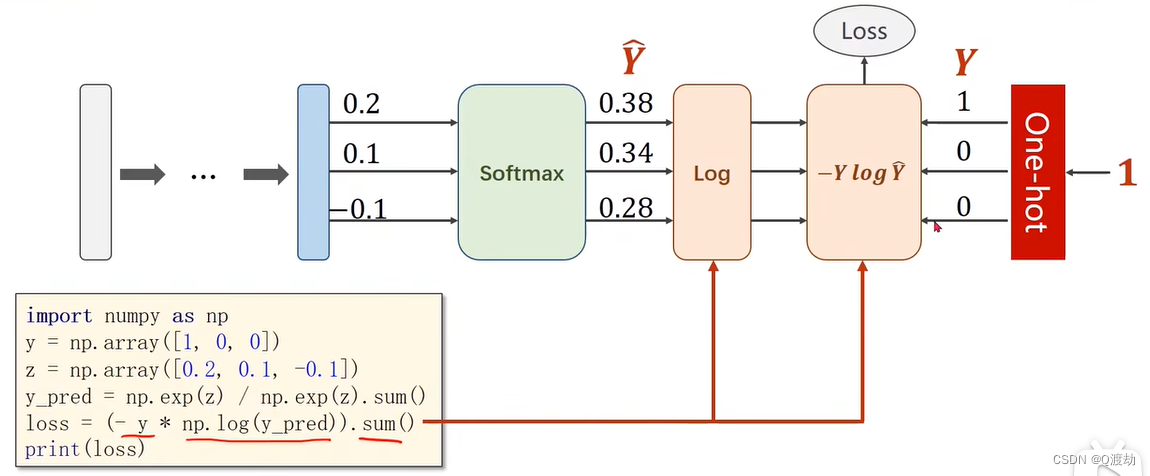
PYTorch使用 torch.nn.CrossEntropyLoss()交叉熵实现softmax层和loss计算
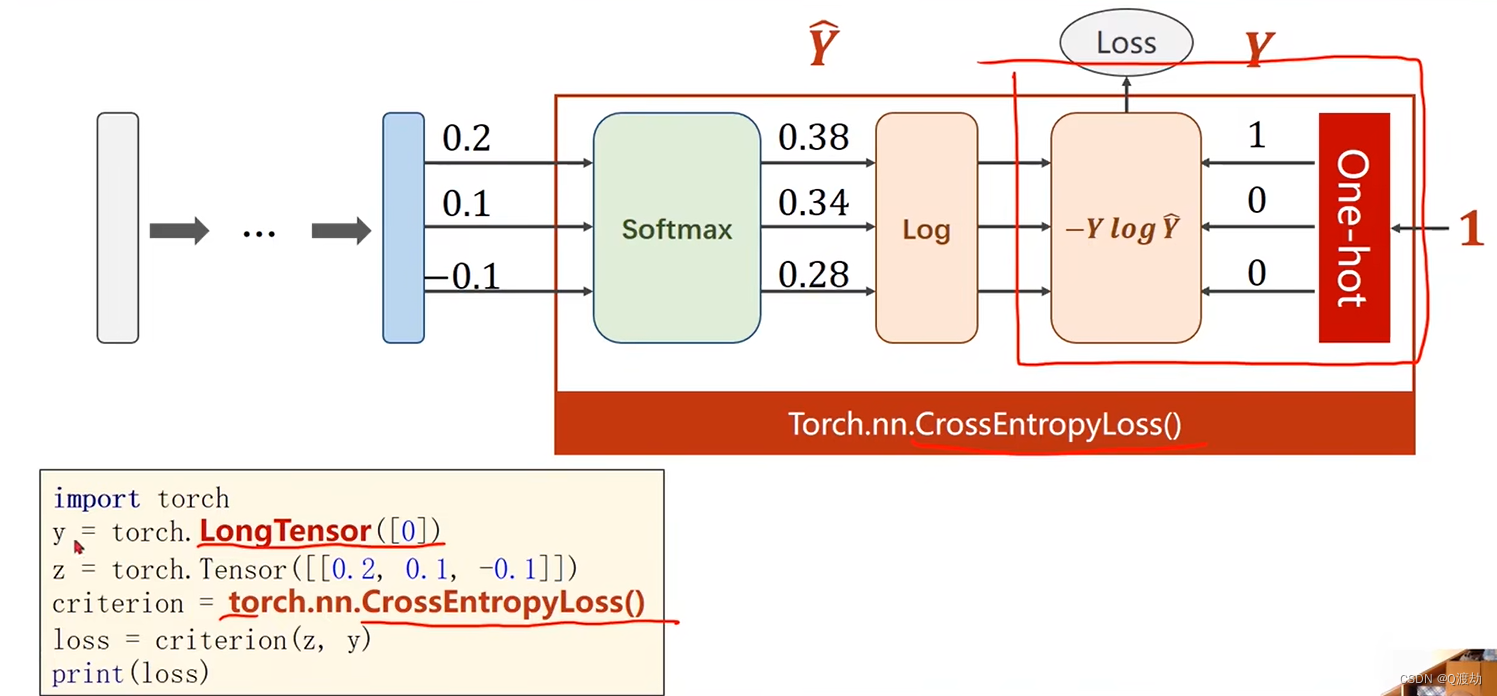
代码测试

准备数据集

-
from torch.utils.data import Dataset 导入数据集
-
from torch.utils.data import DataLoader 加载数据
-
transforms 进行图像处理
激活函数和优化器

WHC ——>CWH,像素值压缩

transforms.ToTensor()是单通道变为多通道
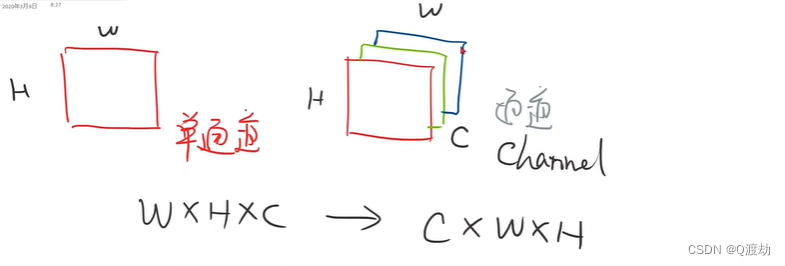

拿到图像,先把它变为 PyTorch中的tensor,也即把维度由 28 * 28 变为 1 * 28 * 28 ,因为原来的通道数 C 在 W 和 H 的后面,所以通过ToTensor将通道数 C 放在 W 和 H 的前面,这样做是为了PyTorch把图像变为一个张量以提高处理速度,张量中图像的表示为(N,C,W,H),而非张量图像时(N,W,H,C),其中N是批量处理样本数量的大小。然后使用归一化,将[0~255]的像素值压缩到[0~1](就是下面说到的归一化处理)
归一化 (数据标准化)
![]()
第一个参数是均值,第二个参数是标准差
均值和标准差是所有对所有样本计算得到的,并不是随意写的
归一化是为了让我们输入的值也满足 N(0,1) 分布,因为神经网络喜欢(0,1)分布的数据

模型(每一层都是全连接层,忽略了局部信息)

x.view(-1,784)中是将(N,1,28,28)的N个样本转化到一个矩阵中,转化之后的矩阵大小是(N,28*28),也即一个样本占一行。x.view(-1,784)中的 -1 代表的是 批处理样本大小是多少,底层自己计算,不需要人为指定
最后一层不需要使用激活函数激活,而是直接使用torch.nn.CrossEntropyLoss()交叉熵实现softmax层和loss,所以是原模原样返回最后一层
前面的输入图像不是一个图像中有多个数据,经过实际测试,train_dataset中的一张图片中只有一个数字,并不是下面的情况

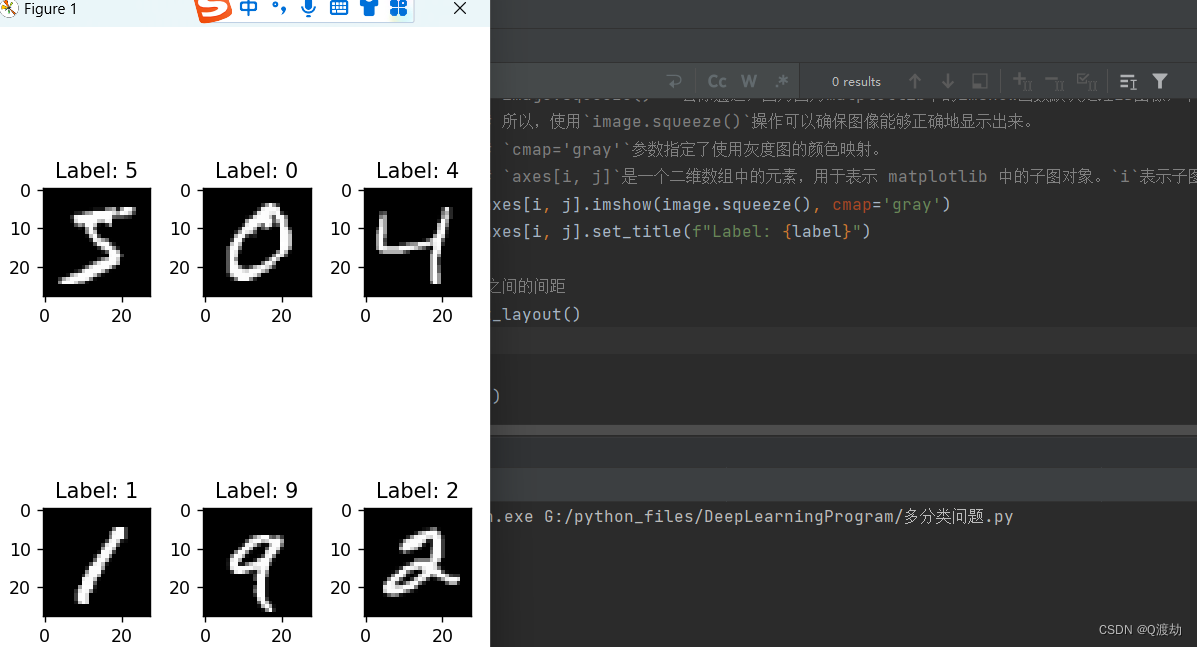
def print_pictures():
# 设置子图的行数和列数
rows = 2
cols = 3
# 创建一个图画,并指定子图的布局
fig, axes = plt.subplots(rows, cols, figsize=(4, 6))
# 遍历多个图像,并在相应的子图中显示
for i in range(rows):
# print(i) 0 1
for j in range(cols):
index = i * cols + j
image, label = train_dataset[index]
# image.squeeze() 去除通道,因为因为matplotlib中的imshow函数默认处理2D图像,不需要包含通道维度。
# 所以,使用`image.squeeze()`操作可以确保图像能够正确地显示出来。
# `cmap='gray'`参数指定了使用灰度图的颜色映射。
# `axes[i, j]`是一个二维数组中的元素,用于表示 matplotlib 中的子图对象。`i`表示子图在第 `i` 行,`j` 表示子图在第 `j` 列。这种方式可以方便地将多个子图组织在一个图画中
axes[i, j].imshow(image.squeeze(), cmap='gray')
axes[i, j].set_title(f"Label: {label}")
# 调整子图之间的间距
plt.tight_layout()
# 显示图画
plt.show()
2、代码实现
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import matplotlib.pyplot as plt
import torch.optim as optim
from torch.utils.data import Dataset
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
print("第一个数据集", train_dataset[0])
data, label = train_dataset[0]
print("data", data)
print("label", label)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # -1其实就是自动获取mini_batch
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活,不进行非线性变换
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
print(data)
inputs, target = data
optimizer.zero_grad()
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# print("outputs.data.shape:",outputs.data.shape)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
# print("共有多少批:",batch_idx) # 共有 937 批
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
# print("images :",outputs.data.shape) # torch.Size([64, 10])..... torch.Size([64, 10])、torch.Size([16, 10]) 这个矩阵中的每一行表示一个输入样本在0~9这10个类别上的得分或概率。这意味着模型会为每个输入样本计算出对应于10个类别的得分或概率
# print("labels :",labels.data.shape) # torch.Size([64]).....torch.Size([64])、torch.Size([16])
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度 ,求每一行最大值的下标,一行一个样本
# print("images数据 :", outputs.data)
# print("predicted数据:",predicted.data)
total += labels.size(0) # 总的样本数量的和
print("labels.size", labels.size)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print("correct:", correct)
print("total:", total)
print('accuracy on test set: %d %% ' % (100 * correct / total))
def print_pictures():
# 设置子图的行数和列数
rows = 2
cols = 3
# 创建一个图画,并指定子图的布局
fig, axes = plt.subplots(rows, cols, figsize=(4, 6))
# 遍历多个图像,并在相应的子图中显示
for i in range(rows):
# print(i) 0 1
for j in range(cols):
index = i * cols + j
image, label = train_dataset[index]
# image.squeeze() 去除通道,因为因为matplotlib中的imshow函数默认处理2D图像,不需要包含通道维度。
# 所以,使用`image.squeeze()`操作可以确保图像能够正确地显示出来。
# `cmap='gray'`参数指定了使用灰度图的颜色映射。
# `axes[i, j]`是一个二维数组中的元素,用于表示 matplotlib 中的子图对象。`i`表示子图在第 `i` 行,`j` 表示子图在第 `j` 列。这种方式可以方便地将多个子图组织在一个图画中
axes[i, j].imshow(image.squeeze(), cmap='gray')
axes[i, j].set_title(f"Label: {label}")
# 调整子图之间的间距
plt.tight_layout()
# 显示图画
plt.show()
if __name__ == '__main__':
print_pictures()
for epoch in range(10):
train(epoch)
test()
最后精确度到达 97% 是因为该模型的每一层都是全连接层,忽略了图片的局部信息,所以导致训练的准确率只有 97%
注:
1、第8讲 from torch.utils.data import Dataset,第9讲 from torchvision import datasets。该datasets里面init,getitem,len魔法函数已实现
2、torch.max的返回值有两个,第一个是每一行的最大值是多少,第二个是每一行最大值的下标(索引)是多少。
3、全连接神经网络
4、torch.no_grad() Python中with的用法
5、代码中"_"的说明 Python中各种下划线的操作 ,在 Python 解释器里面, _ 会指向你最后一次执行的表达式。这在我们使用 Python 交互的时候常常会用到

6、https://blog.youkuaiyun.com/qq_40210586/article/details/103874000:torch.max( )的用法 torch.max( )使用讲解




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











