




GNN-based Fraud Detectors 研究
背景知识
1.Multi-relation Graph
G
=
{
V
,
X
,
E
r
∣
r
=
1
R
,
Y
}
G=\{V,X,{E_r}|_{r=1}^R,Y\}
G={V,X,Er∣r=1R,Y}
V
V
V表示节点集
v
1
,
.
.
.
,
v
N
{v_1,...,v_N}
v1,...,vN,节点
v
i
v_i
vi具有
d
−
d-
d−维度的特征向量
x
i
x_i
xi,
X
=
x
1
,
.
.
.
,
x
n
X={x_1,...,x_n}
X=x1,...,xn表示节点特征集;
e
i
,
j
r
=
(
v
i
,
v
j
)
∈
E
r
e_{i,j}^r=(v_i,v_j)\in E_r
ei,jr=(vi,vj)∈Er表示节点
v
i
v_i
vi和
v
j
v_j
vj之间的带有关系
r
∈
1
,
.
.
.
,
R
r\in {1,...,R}
r∈1,...,R的边,
R
R
R表示关系的数量;
一条边可以具备多种关系。
Y
Y
Y表示节点集
V
V
V的标签集。
2.GNN-based Fraud Detection
邻居聚合过程:
h
v
(
l
)
=
σ
(
h
v
(
l
−
1
)
⊕
A
G
G
(
L
)
(
{
h
v
′
,
r
(
l
−
1
)
:
(
v
,
v
′
)
∈
E
r
(
l
)
∣
r
=
1
R
}
)
)
h_v^{(l)}=\sigma(h_v^{(l-1)}\oplus AGG^{(L)}(\{h_{v',r}^{(l-1)}:(v,v')\in E_r^{(l)}|_{r=1}^R\}))
hv(l)=σ(hv(l−1)⊕AGG(L)({hv′,r(l−1):(v,v′)∈Er(l)∣r=1R}))
对于中心节点
v
v
v:
h
v
(
l
)
h_v^{(l)}
hv(l)表示第
l
l
l层的隐藏嵌入,
h
v
(
0
)
=
x
i
h_v^{(0)}=x_i
hv(0)=xi表示输入特征;
E
r
(
l
)
E_r^{(l)}
Er(l)表示第
l
l
l层在关系
r
r
r下的边;
h
v
′
,
r
(
l
−
1
)
h_{v',r}^{(l-1)}
hv′,r(l−1)表示邻居节点
v
′
v'
v′在关系
r
r
r下的嵌入;
A
G
G
AGG
AGG表示将来自不同关系的邻域信息映射为向量的聚合函数;
⊕
\oplus
⊕表示将节点
v
v
v的信息与其邻域信息结合操作,如相加或拼接。
3. Graph Modeling
(1)MR-Graph-based Modeling
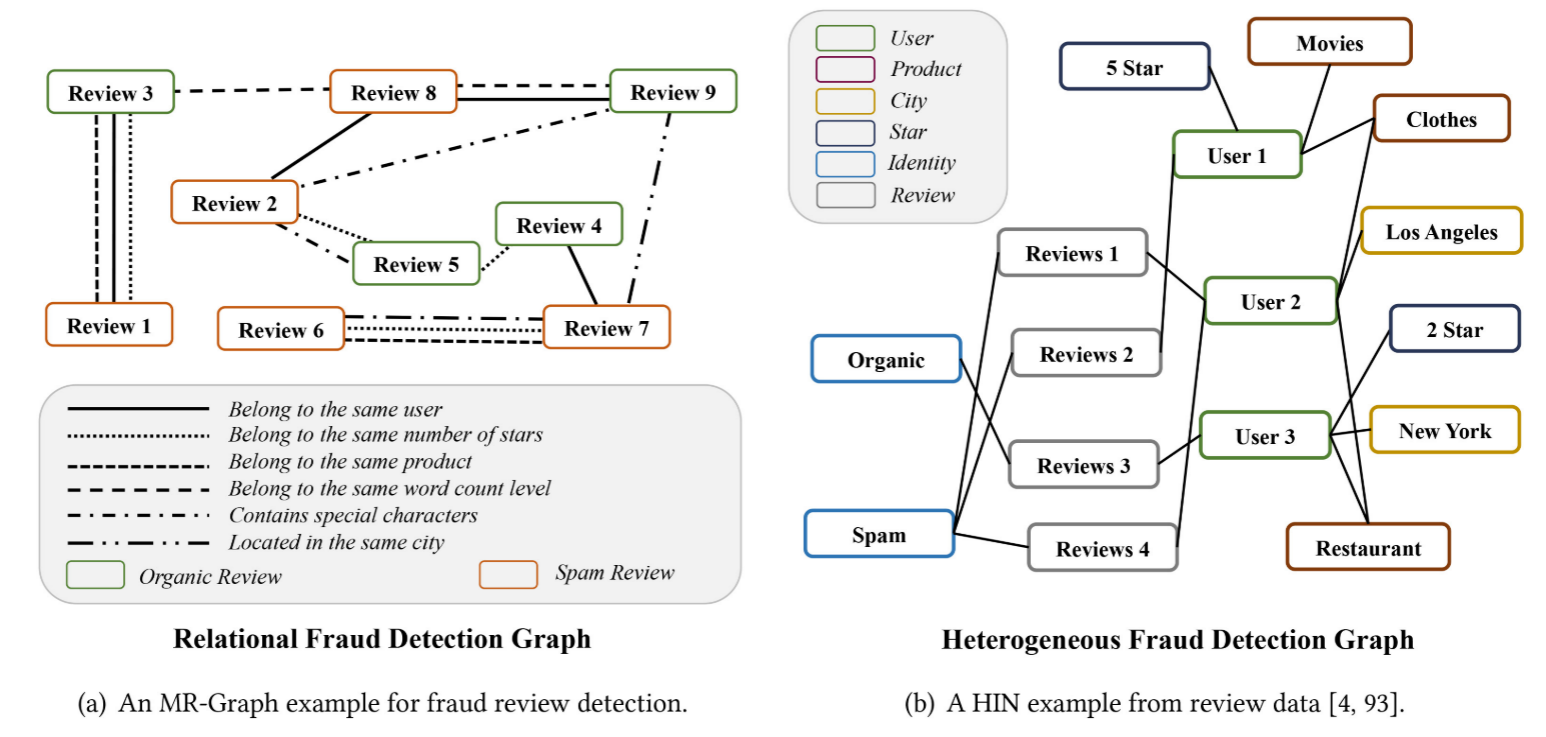
以垃圾评论检测(Spam Review Detection)为例,考虑不同标签的评论作为节点,不同的代表性交互行为作为不同类型的连接来构建多关系图,从而将该问题转化为二分类任务。如下图所示,MR-Graph描述了从电子商务评论数据中提取的正常评论、垃圾评论及其交互。提取了与欺诈行为密切相关的两条评论之间的代表性交互,将它们表示为不同类型的边:Belonging to the same user, Having the same star rating, Targeting the same product posted in the same month, Belonging to the same word count level, Containing special characters and Targeting products located in the same city。
(2)HIN-based modeling
作为替代方案,传统的基于HIN的建模更加关注结构化连接所描述的关系,侧重于不同属性或类型数据的关联与融合。
研究进展
GEM
文章名称:Heterogeneous Graph Neural Networks for Malicious Account Detection
标签:CIKM_A类_2018
一、问题
支付宝(Alipay)作为全球领先移动支付平台,日活用户超4亿,面临恶意账户(如虚假注册、洗钱账户)的威胁。大量被滥用的虚假账户被用来在电子邮件系统中发送数十亿封垃圾邮件。更严重的是,在支付宝这样的金融系统中,一旦大量的账户被一个或一群恶意用户接管,这些恶意用户就有可能套现并获得不义之财,这对整个金融系统的危害是巨大的。有效且准确地检测出恶意账号在此类系统中起着重要的作用,因此,如何准确地检测恶意账号成为一个亟待解决的问题。
目前,异构的账户-设备图中存在两个基本弱点,即设备聚合(device aggregation)和活动聚合(activity aggregation):
- 设备聚合:攻击者要付出计算资源的代价,一个攻击者或一组攻击者拥有的大多数账户只会频繁地在少量资源上注册或登录。
- 活动聚合:攻击者要受到时间资源的限制,攻击者需要在短期内实现特定的目标,由单个攻击者控制的恶意账户的行为可能在有限的时间内爆发。
许多现有的用来处理恶意账号的安全机制已经广泛地研究了攻击特征,这些攻击特征有望区分正常和恶意账户。为了利用这些特征,现有的研究主要分布在三个方向:
- 基于规则的方法:直接生成复杂的识别规则。
- 基于图的方法:通过考虑账户之间的流通性来重新表述问题,这是基于攻击者只能躲避而无法控制与正常账户交互的直觉。
- 基于机器学习的方法:通过利用大量的历史数据来学习统计模型。
现有的方法通常通过设置严格的限制来实现非常低的误报率,但可能会错过识别更多可疑账户的机会,即具有高误报率,其原因是大量的良性账户与少量的可疑账户交织在一起,导致信噪比低。由于噪声数据,正常账户与恶意账户共享相同的IP地址是很常见的。因此,重要的是要共同考虑设备聚合和活动聚合,在异构图的视图包括各种类型的设备,如电话号码、媒体访问控制地址、SIM号码等。
二、贡献
提出了一种基于异构账户-设备图拓扑结构的图神经网路模型,名为恶意账户的图嵌入(Graph Embedding for Malicious accounts,GEM):
- 第一个通过图神经网络解决的欺诈检测问题,建模了账户-设备异构图,并考虑了账户在该图的局部结构中活动的特性;
- 通过联合捕获攻击者的两个弱点来识别恶意账户,即异构图中的设备聚合和活动聚合;
- 作为一个真实系统部署在了支付宝上,每天可以检测成千上万的恶意账户,精度超98%。
三、方法
1.异构图构建
节点类型:账户节点(用户账户)和设备节点(6类设备,包括手机号、UMID、MAC等);
边定义:账户-设备登录关系(7天内数据);
特征工程:账户特征处理为168维度小时级行为统计+200维属性特征,设备特征处理为One-hot编码;
图分解:按照设备类型拆分为
G
a
G^a
Ga个子图(保留原始拓扑)。
2.自适应聚合
H
(
t
)
←
σ
(
X
⋅
W
+
1
∣
D
∣
∑
d
=
1
∣
D
∣
A
(
d
)
⋅
H
(
t
−
1
)
⋅
V
d
)
H^{(t)}\leftarrow \sigma(X\cdot W + \frac{1}{|D|}\sum_{d=1}^{|D|}A^{(d)}\cdot H^{(t-1)}\cdot V_d)
H(t)←σ(X⋅W+∣D∣1d=1∑∣D∣A(d)⋅H(t−1)⋅Vd)
其中,
X
⋅
W
X\cdot W
X⋅W表示残差连接,保留原始特征,防止过拟合,
∑
d
=
1
∣
D
∣
A
(
d
)
⋅
H
(
t
−
1
)
⋅
V
d
\sum_{d=1}^{|D|}A^{(d)}\cdot H^{(t-1)}\cdot V_d
∑d=1∣D∣A(d)⋅H(t−1)⋅Vd表示设备类型聚合,
A
(
d
)
⋅
H
(
t
−
1
)
⋅
V
d
A^{(d)}\cdot H^{(t-1)}\cdot V_d
A(d)⋅H(t−1)⋅Vd表示各子图独立卷积,
W
W
W表示特征变换矩阵,
V
d
V_d
Vd表示设备类型专属参数。
3.注意力机制
H
(
t
)
←
σ
(
X
⋅
W
+
∑
d
∈
D
s
o
f
t
m
a
x
(
α
d
)
⋅
A
(
d
)
⋅
H
(
t
−
1
)
⋅
V
d
)
H^{(t)}\leftarrow \sigma(X\cdot W + \sum_{d\in D}^{}softmax(\alpha_d)\cdot A^{(d)}\cdot H^{(t-1)}\cdot V_d)
H(t)←σ(X⋅W+d∈D∑softmax(αd)⋅A(d)⋅H(t−1)⋅Vd)
其中,
α
d
\alpha_d
αd表示动态权重,学习设备类型的重要性。
4.模型优化
损失函数为半监督交叉熵,训练策略为EM式迭代。
GeniePath
文章名称:GeniePath: Graph Neural Networks with Adaptive Receptive Paths
标签:AAAI_A类_2018
非官网源码:https://github.com/shuowang-ai/GeniePath-pytorch
参考:https://zhuanlan.zhihu.com/p/434606297,个人认为该文将motivation讲解的很清楚
一、问题
最初在解决图表征学习时,如DeepWalk、LINE等算法,会先在图数据上进行随机游走得到序列,节点序列相当于NLP中的文本数据,然后用NLP领域的算法例如Word2vec进行节点表征学习,但实际上,这样强行从图中拆分出序列会把很多存在依赖关系的节点拆分开。GCN算法的出现又重新给出了节点上下文的概念,即把节点的一跳邻居节点看成当前节点的上下文,然后GCN用一跳邻居节点对中心节点进行表征学习。而GAT模型则在GCN模型的基础上考虑一跳邻居对中心节点的影响权重,引入了Attention机制,进行有权聚合。如果一跳邻居可以作为上下文,那么二跳、三跳邻居是否可以作为上下文?
传统图神经网络(如GCN、GraphSAGE)存在两大瓶颈:
- 固定感受野:通过预定义的邻域聚合(如均值、最大化)或图拉普拉斯矩阵约束邻居权重,这会导致模型无法自适应选择重要邻居或过滤噪声;
- 深度敏感性:当堆叠多层时,信号传播过远导致噪声累积。
GeniePath模型为解决以上问题,定义了一个自适应Breadth和Depth的模型,Breadth指的是节点的一跳邻居,而Depth指的是节点的多跳邻居,GeniePath自适应地学习广度和深度信息来进行节点的表征学习。具体来说,GeniePath模型中的Adaptive Breadth Function可以自适应地有区别地选择一跳邻居节点进行聚合,而Adaptive Depth Function则可提取多跳邻居范围内的有用邻居和过滤噪声信息。通过自适应广度和深度函数可以学习到每个节点不同的合适的感受野。
二、方法
提出自适应路径层(Adaptive Path Layer),包含两个互补的组件:
1.自适应广度函数(Adaptive Breadth)
旨在动态筛选出重要的一跳邻居,基于注意力权重的邻居加权聚合机制:
h i ( t m p ) = t a n h ( W ( t ) T ∑ j ∈ N ( i ) ∪ { i } α ( h i ( t ) , h j ( t ) ) ⋅ h j ( t ) ) h_i^{(tmp)}=tanh(W^{(t)^{\mathsf{T}}}\sum_{j\in N(i)\cup \{i\}}^{}\alpha(h_i^{(t)},h_j^{(t)})\cdot h_j^{(t)}) hi(tmp)=tanh(W(t)Tj∈N(i)∪{i}∑α(hi(t),hj(t))⋅hj(t))
注意力权重 α \alpha α通过双线性变换计算:
α ( x , y ) = s o f t m a x y ( v T t a n h ( W s T x + W d T y ) ) \alpha(x,y)=softmax_y(v^{\mathsf{T}}tanh(W_s^{\mathsf{T}}x+W_d^{\mathsf{T}}y)) α(x,y)=softmaxy(vTtanh(WsTx+WdTy))
2.自适应深度函数(Adaptive Depth)
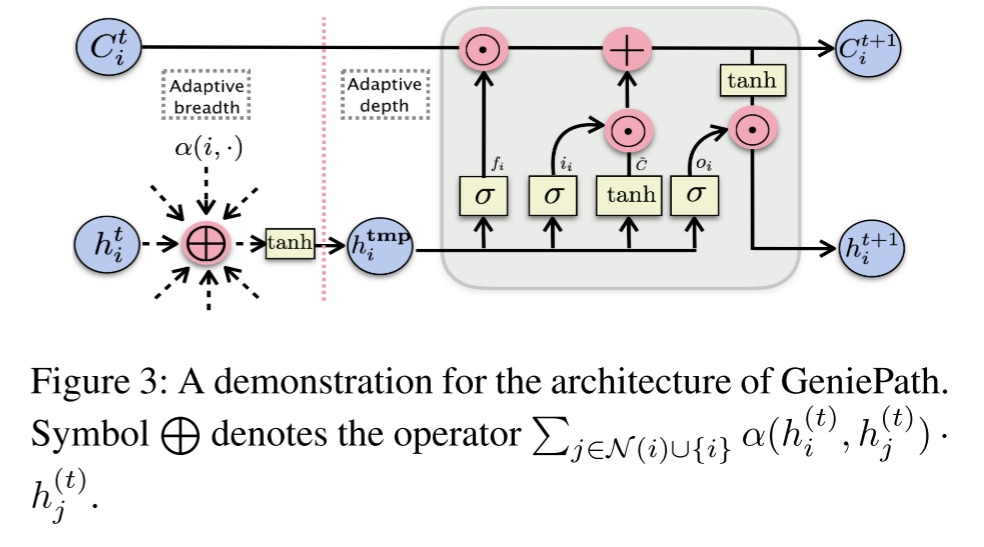
旨在控制多跳信号传播,过滤噪声,引入了LSTM的门控机制: - 输入门 i i i_i ii:控制新信号 C ∼ \overset{\sim}{C} C∼的摄入;
- 遗忘门 f i f_i fi:过滤历史记忆 C i ( t ) C_i^{(t)} Ci(t)中的噪声;
- 输出门 o i o_i oi:生成最终表示 h i ( t + 1 ) h_i^{(t+1)} hi(t+1)。
C i ( t + 1 ) = f i ⊙ C i ( t ) + i i ⊙ C ∼ h i ( t + 1 ) = o i ⊙ t a n h ( C i ( t + 1 ) ) \begin{array}{lcr} C_i^{(t+1)}=f_i\odot C_i^{(t)}+i_i\odot \overset{\sim}{C}\\ h_i^{(t+1)}=o_i\odot tanh(C_i^{(t+1)}) \end{array} Ci(t+1)=fi⊙Ci(t)+ii⊙C∼hi(t+1)=oi⊙tanh(Ci(t+1))
FdGars
文章名称:FdGars: Fraudster Detection via Graph Convolutional Networks in Online App Review System
标签:WWW_A类_2019
一、问题
现有的检测垃圾评论的方法已经取得了成功,但是它们通常针对电子商务和推荐系统。在不同的评论规则中,很少有研究发现多类欺诈者。例如,Yelp数据集中的欺诈者旨在通过撰写大量高质量的评论来影响消费者的决定,并总是像普通评论者一样进行伪装。相比之下,应用程序商店中的欺诈者,也称为垃圾邮件发送者,旨在发布广告(例如电话号码、微信、URL等)以提升应用程序的排名。简单来说,由于欺诈用户的行为是复杂的,并且在不同的评论平台上是变化的,现有的方法不适合在线app评论系统中的欺诈检测。
二、结构
率先分析了来自不同评论平台的欺诈用户的意图,并利用内容特征(相似性、特殊符号)和行为特征(时间戳、设备、登录状态)对它们进行了分类。在综合分析垃圾邮件活动以及正常用户和恶意用户之间关系的基础上,设计并提出了一个用于在在线app评论系统中进行欺诈检测的图卷积神经网络FdGars。
- 首先,分析评论日志,提取每个用户的内容和行为特征;
- 其次,构建了一个图结构来表示评论者的特征和评论者之间的关系;
- 然后,通过预定义的标签方法将评论者分为欺诈者和正常用户;
- 最后,基于有限的有标签的评论者,一个两层的GCN被用来从未标记的评论者中检测出更多的欺诈者。
根据欺诈者的动机意图(如传播虚假信息、促进产品排名和打广告),将其分为三种类型:
- Camouflage:欺诈者通过添加热门商品或名人的链接来假装自己是正常的评论者;
- Crowdturfing:欺诈者可以很容易地从众包平台雇用网络工作人员参与特定的垃圾邮件活动并获得金钱奖励;
- Spammer:欺诈者在公开评论系统中发布无关评论,以提高其产品的知名度(例如广告、产品信息)或进行一些非法活动(例如销售药物、敏感词)。
三、贡献
- 欺诈者分析:本文对在线评论系统中不同类型的欺诈者的检测进行了阐述,并总结了欺诈者生成虚假/垃圾评论的三种常见模式;
- FdGars实施:在一个大规模的在线app评论系统中,利用图卷积网络实现了一个高效的、可扩展的反垃圾邮件方法系统。在检测恶意账户方面,FdGars的性能优于其他最先进的方法;
- 部署和评估:通过将FdGars部署到腾讯的Beacon反欺诈平台上,在真实的单词数据集上验证了FdGars的性能,该方法具有较高的精确率(precision)和高召回率(recall)。
四、方法
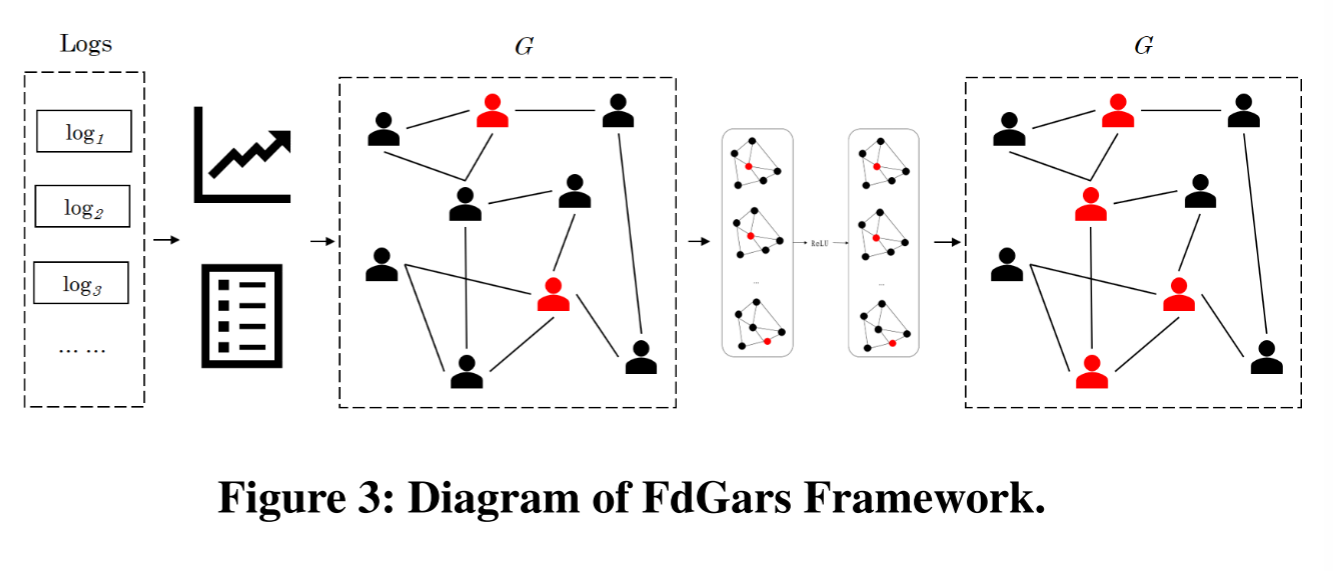
1.关系图谱构建
根据以下规则构造图结构
G
G
G:
- 将评论者表示为图 G G G中的节点;
- 如果两个节点的对应评论者评论了同一个应用,则构建连接两个节点的边。
因此,评论日志被转换为图结构,图
G
G
G表示为:
G
=
{
N
,
E
,
A
}
G=\{N,E,A\}
G={N,E,A}
其中,
N
=
n
1
,
n
2
,
n
3
,
.
.
N={n_1,n_2,n_3,..}
N=n1,n2,n3,..是评论者集合,
E
=
{
e
1
,
e
2
,
e
3
,
.
.
.
}
E=\{e_1,e_2,e_3,...\}
E={e1,e2,e3,...}是边集合,
A
=
α
1
,
α
2
,
α
3
,
.
.
.
A={\alpha_1,\alpha_2,\alpha_3,...}
A=α1,α2,α3,...是评论者属性集合。节点
n
i
n_i
ni和节点
n
j
n_j
nj之间的边表示评论者
n
i
n_i
ni和评论者
n
j
n_j
nj在相同的app上有评论,表示为:
e
i
j
=
E
d
g
e
(
n
i
,
n
j
)
=
(
n
i
,
α
i
,
n
j
,
α
j
)
e_{ij}=Edge(n_i,n_j)=(n_i,\alpha_i,n_j,\alpha_j)
eij=Edge(ni,nj)=(ni,αi,nj,αj)
构建后的图
G
G
G清晰地表达了评论者的特征和评论者之间的关系。
2.特征工程
(1)内容特征(content features)
使用内容特征对评论进行分类,下表显示了从每个评论中提取的特征。

- SRN:在指定时间段内类似评论的数量,采用SimHash算法计算;
- RSN:每个评论中特殊字符的数量,例如emoji标签和火星符号。一般来说,垃圾评论中含有50%以上的符号;
- RL:每个评论的长度;
- PRR:符号数与评论长度的比值;
- REB:垃圾邮件发送者发布的评论的正则表达式集合,其明显意图包括电话号码(∧1(3|4|5|7|8)\d{9}$)、模糊词([WwVv][Xx])和URL等等;
(2)行为特征(behavior features)
下表罗列了从每个评论中提取的行为特征。

- RQ:记录了在指定时间段评论者的评论数量;
- TDQ:评论者的评论在24小时内的分布;
- SQD:评论者的评级分布。
3.无监督预标注策略
利用两个行为属性对评论者进行分类,即连续天数(continuous days,CD)和登录设备的数量(the number of login device,DN):
- CD:评论者在指定时间段内发布评论的连续天数;
- DN:记录了同一时期内评论者使用的设备数量。
标注函数表示为:
L
a
b
e
l
(
n
)
=
{
1
,
i
f
C
D
>
θ
C
D
D
N
>
θ
D
N
,
0
,
o
t
h
e
r
w
i
s
e
Label(n)= \begin{cases} 1,&if CD>\theta_{CD}&DN>\theta_{DN},\\ 0,&otherwise \end{cases}
Label(n)={1,0,ifCD>θCDotherwiseDN>θDN,
其中,
θ
C
D
、
θ
D
N
\theta_{CD}、\theta_{DN}
θCD、θDN为阈值,如果评论者的
C
D
>
θ
C
D
CD>\theta_{CD}
CD>θCD或者
D
N
>
θ
D
N
DN>\theta_{DN}
DN>θDN,我们认为评论者是欺诈者;否则,评论者是正常用户。
通过多轮数据分析,我们认为
θ
C
D
=
7
\theta_{CD}=7
θCD=7和
θ
D
N
=
20
\theta_{DN}=20
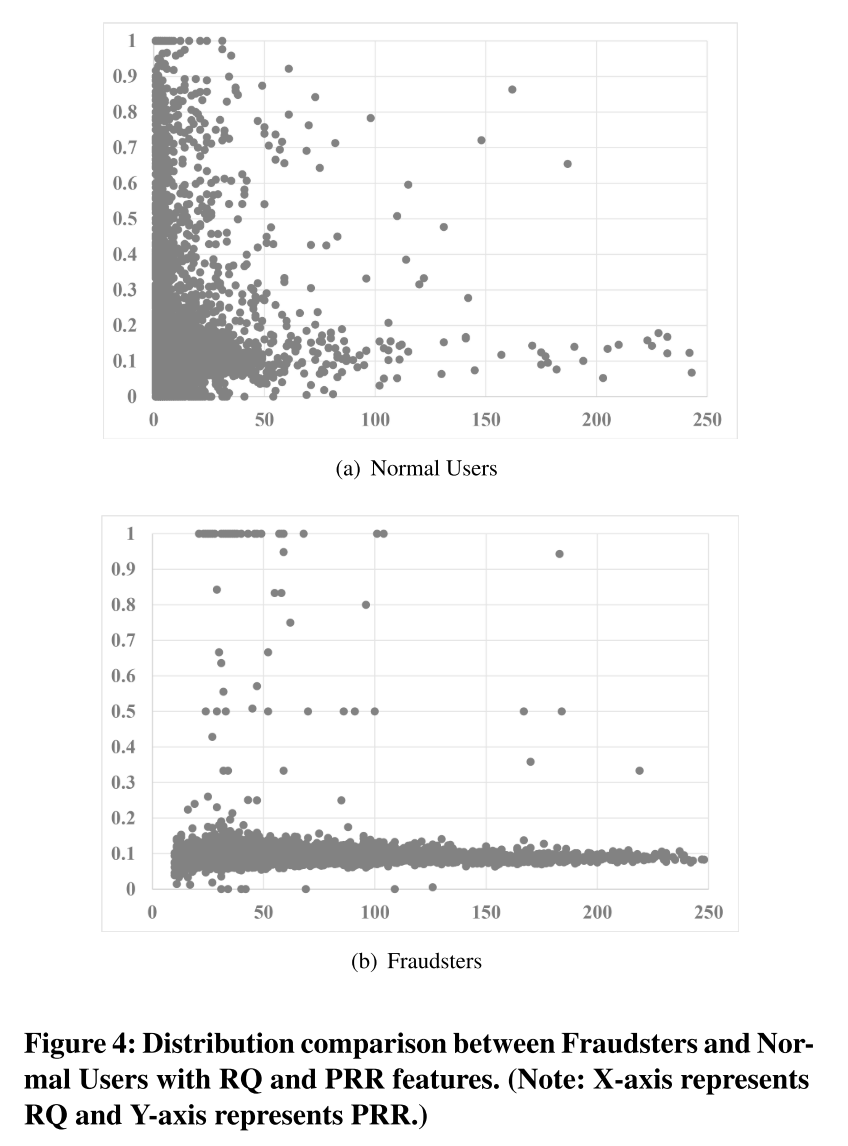
θDN=20可以识别在线app中的高度可疑欺诈者。通过该式标注欺诈者,下图显示了欺诈者和正常用户的RQ和PRR分布。显然,普通用户聚集在坐标的左下角。根据分析,大多数普通用户的RQ小于30。相比之下,欺诈者聚集在坐标的底部,大多数欺诈者的PRR小于0.2。(?没太理解这里的逻辑)
4.GCN欺诈检测模型
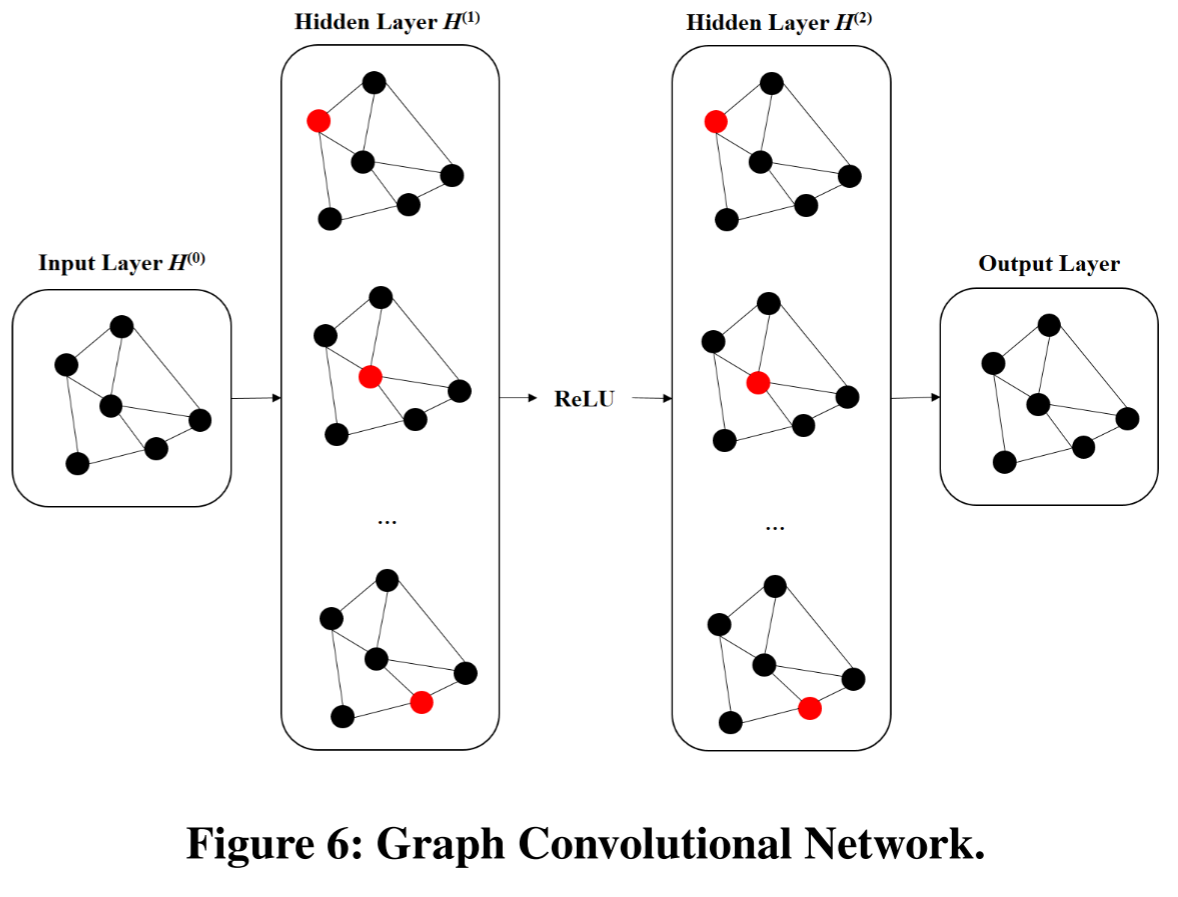
使用一个两层的GCN半监督欺诈检测。
GAS
文章名称:Spam Review Detection with Graph Convolutional Networks
标签:CIKM_A类_2019
一、问题
国内最大的二手交易app闲鱼,饱受垃圾评论的侵害。闲鱼中的评论不同于其他电子商务网站的评论,其评论通常发生在购买之前,通常是以垃圾广告的形式存在,以广告引流为主。垃圾广告检测(spam advertisements detection)的主要挑战是:
- 可扩展性:超过一千万用户发布的超过10亿二手商品的闲鱼大规模数据;
- 对抗活动:与大多数风险控制系统一样,反垃圾系统也会因为垃圾广告发送者采取的对抗行为而导致性能下降。
垃圾广告发送者通常采用以下两种对抗策略来绕过反垃圾系统:
- 伪装:用不同的表达方式表示相似的意思。比如,“打这个电话找兼职”、“想在业余时间多挣点钱吗?”、“联系我”都是垃圾广告,目的是引诱人们进行有风险的线下活动。
- 篡改评论:垃圾广告发送者故意用很少使用的中文字符或错别字替换评论中的一些关键字。例如,“添加我的vx”、“添加我的v”和“添加我的wx”都表示“添加我的微信号”。
与此同时,研究者注意到,通过引入评论的上下文,可以减轻对抗行为的影响。作者将上下文分为两种:局部上下文和全局上下文。局部上下文指的是来自发布者和相关条目的信息,而全局上下文指的是由所有评论的特征分布提供的信息。
二、贡献
提出了一种基于GCN的高度可扩展的反垃圾广告方法,称为GAS(GCN-based Anti-Spam method):
- 该算法在闲鱼的带边属性的二分图上工作,可以很容易地推广到基于元路径的异构GCN算法,用于各种异构图和app;
- 结合了两种图卷积网络,分别用于捕捉评论的局部上下文和全局上下文;
- 将提出的反垃圾模型与分布式Tensorflow框架一起部署,以处理闲鱼每天百万级的评论。通过离线实验和在线评测,我们的系统在满足效率要求的同时,显著地识别出了更多的垃圾评论,并消除了对抗性行为的影响。
三、方法
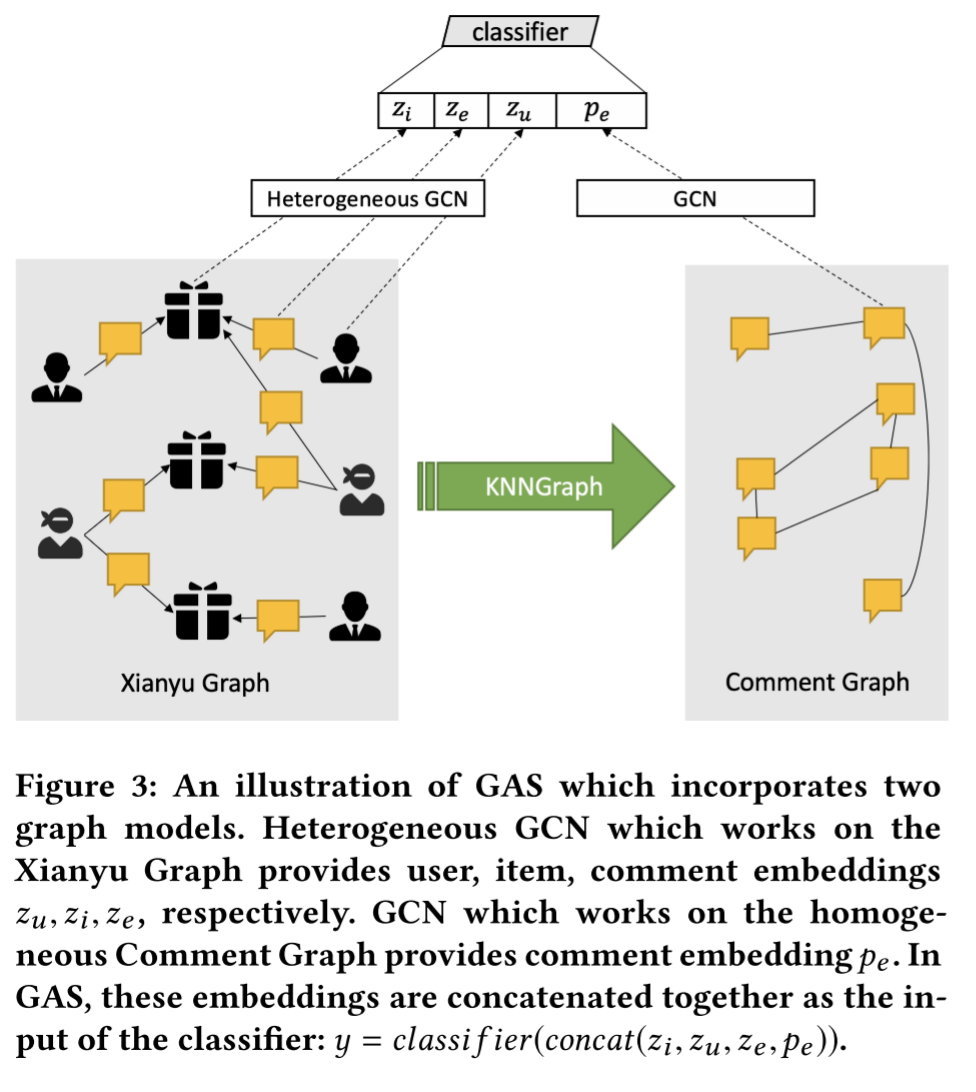
1.概述
GAS模型由两个核心部分组成,最终将两部分的结果融合进行分类,如上图所示:
- 异构图卷积网络:在一个包含用户、商品和评论的异构图上运行,捕捉局部上下文,即一个评论和其发布者、所述商品之间的紧密关系;
- 同构图卷积网络:在一个仅由评论组成的同构图上运行,捕捉全局上下文,即一个评论和全站其他评论之间的关系,用于对抗伪装和篡改评论行为。
最终,模型将从这两个图中学习到的多种嵌入向量拼接起来,输入到一个分类器,判断评论是否属于垃圾评论:
y
=
c
l
a
s
s
i
f
i
e
r
(
c
o
n
c
a
t
(
z
i
,
z
u
,
z
e
,
p
e
)
)
y=classifier(concat(z_i,z_u,z_e,p_e))
y=classifier(concat(zi,zu,ze,pe))
2.问题定义
将垃圾评论检测视为一个图上的边分类(edge classification)问题,
在闲鱼图的构建中,节点包括用户节点
U
U
U和商品节点
I
I
I,用户节点代表发布评论的用户,商品节点代表被评论的商品;
边包括评论边
E
E
E,代表一条评论,连接一个用户节点和一个商品节点;
这是一个典型的二部图,并且节点和边都带有自身的属性,因此是属性异构图。
3.异构图卷积网络
用于学习局部上下文,扩展了传统的GCN,以适应“用户-评论-商品”这种复杂的异构图结构,其传播过程分为**聚合(Aggregation)和组合(Combination)**两个子步骤。
(1)聚合子层(Aggregation Sub-layer)
为闲鱼图中的每个实体从其邻居那里收集信息。
1)评论边
e
e
e的聚合
一条评论
e
e
e的信息由三个部分组成:评论本身的内容+发布该评论的用户
U
(
e
)
U(e)
U(e)+被评论的商品
I
(
e
)
I(e)
I(e),它的聚合方式就是把上一轮迭代中这三者的嵌入向量拼接起来:
A
G
G
E
l
(
h
e
l
−
1
,
h
U
(
e
)
l
−
1
,
h
I
(
e
)
l
−
1
)
=
c
o
n
c
a
t
(
h
e
l
−
1
,
h
U
(
e
)
l
−
1
,
h
I
(
e
)
l
−
1
)
AGG_E^l(h_e^{l-1},h_{U(e)}^{l-1},h_{I(e)}^{l-1})=concat(h_e^{l-1},h_{U(e)}^{l-1},h_{I(e)}^{l-1})
AGGEl(hel−1,hU(e)l−1,hI(e)l−1)=concat(hel−1,hU(e)l−1,hI(e)l−1)
2)用户节点
u
u
u的聚合
一个用户
u
u
u的邻居是它评论过的所有商品以及它发布的所有评论,为了聚合这些信息,模型采用注意力机制;
将用户
u
u
u的所有邻居(评论边+商品节点)的嵌入向量,通过注意力加权求和,得到一个聚合后的向量
h
N
(
u
)
h_{N(u)}
hN(u)。
3)商品节点
i
i
i的聚合
一个商品
i
i
i的邻居是评论过它的所有用户和所有指向它的评论,同样采用注意力机制,通过注意力加权求和后,得到一个聚合后的向量
h
+
N
(
i
)
h+{N(i)}
h+N(i)。
(2)组合子层(Combination Sub-layer)
在聚合了邻居信息后,需要将这些信息与节点自身的旧信息结合,以更新节点的嵌入向量,模型采用了类似GraphSAGE的方法,即拼接(concat):
h
u
l
=
c
o
n
c
a
t
(
V
U
l
⋅
h
u
l
−
1
,
h
N
(
u
)
l
)
h
i
l
=
c
o
n
c
a
t
(
V
I
l
⋅
h
i
l
−
1
,
h
N
(
i
)
l
)
\begin{array}{lcr} h_u^l=concat(V_U^l\cdot h_u^{l-1},h_{N(u)}^l)\\ h_i^l=concat(V_I^l\cdot h_i^{l-1},h_{N(i)}^l) \end{array}
hul=concat(VUl⋅hul−1,hN(u)l)hil=concat(VIl⋅hil−1,hN(i)l)
其中,
V
U
l
V_U^l
VUl和
V
I
l
V_I^l
VIl表示用户节点和商品节点的可训练权重矩阵,用于对自身信息进行线性变换。
(3)时间相关的采样策略(Time-related sampling strategy)
由于闲鱼的数据量巨大(亿级别),无法对整个图进行全量训练。因此,必须采取小批量(mini-batch)训练。
传统的采样方法通常是随机采样邻居,本文提出了一种基于时间的采样策略。
从策略上来讲,当为一个节点采样邻居时,优先选择时间上最接近的邻居评论。
这是因为在垃圾评论场景下,用户的行为和商品的状态在时间上具有很强的局部性。一个评论是否是垃圾,与它前后不久出现的其他评论关系更大。
(4)融合文本分类模型(Incorporate Text Classification Model)
评论中的文本在与用户特征和商品特征合并前应该先转换为嵌入。
模型使用TextCNN来处理评论的原始文本,生成一个初始的文本嵌入向量:
h
e
0
=
T
e
x
t
C
N
N
(
w
0
,
w
1
,
w
2
,
.
.
.
,
w
n
)
h_e^0=TextCNN(w_0,w_1,w_2,...,w_n)
he0=TextCNN(w0,w1,w2,...,wn)
其中,
w
i
w_i
wi表示评论
e
e
e中第
i
i
i个词的词嵌入,
h
e
0
h_e^0
he0是评论
e
e
e最初的嵌入表示。
该TextCNN模型是与整个GCN模型一起进行端到端训练的,这意味文本表示与图结构表示可以相互优化,使得模型可以更好地理解文本在图上下文中的含义。
4.基于GCN的反垃圾评论模型
用于捕获全局上下文。
垃圾评论者为了躲避检测,会使用各种伪装和评论篡改(如同义词替换、插入特殊符号等),例如,“加我v”、“加v信”、“加wx”都指向同一个意思。这些评论在局部上下文中可能看不出问题(因为发布者和商品都不同),但在全局上看,它们的内容高度相似。
作者采用了一种快捷的方式来捕捉节点的全局上下文,更具体地说,我们通过连接具有相似内容的评论来构造一个名为评论图的同构图。通过这种方式,异构闲鱼图中的评论边成为了评论图中的顶点。
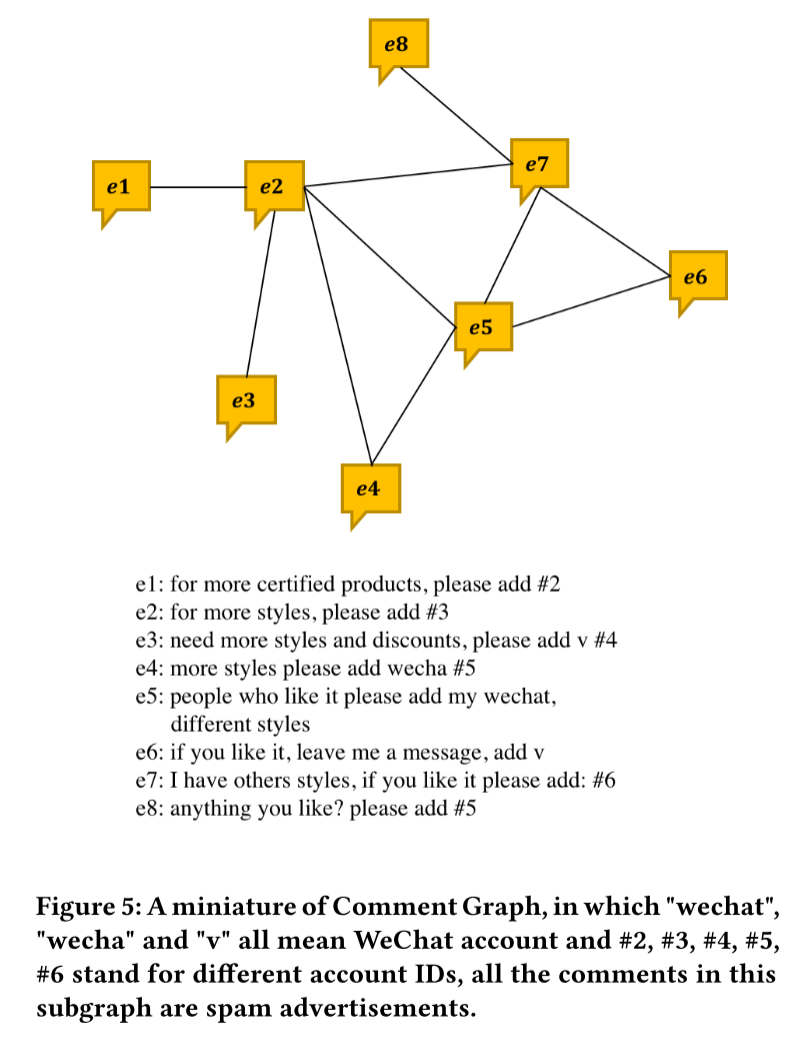
构建过程如下:
- 为所有评论生成文本嵌入向量;
- 使用近似k近邻(Approximate KNN)算法高效地为每个评论找到内容最相似的K个其他评论,并建立连接;
- 为了避免信息冗余,会移除那些由同一用户发布或指向同一商品的评论对,因为这部分信息已在异构图中被捕捉。
在同构评论图上运行一个标准的GCN,其效果是拉普拉斯平滑(Laplacian smoothing),一个评论节点的特征会与它邻居的特征变得更相似。如果一个看似正常的评论,在评论图上与大量已知的垃圾评论相连,那么它的嵌入向量就会被“污染”,变得更像垃圾评论,从而更容易被识别。
模型最终将异构GCN学习到的局部嵌入
(
z
e
,
z
u
,
z
i
)
(z_e,z_u,z_i)
(ze,zu,zi)与同构GCN学到的全局评论嵌入
p
e
p_e
pe拼接起来,送入分类器,得到最终的预测结果:
y
=
c
l
a
s
s
i
f
i
e
r
(
c
o
n
c
a
t
(
z
i
,
z
u
,
z
e
,
p
e
)
)
y=classifier(concat(z_i,z_u,z_e,p_e))
y=classifier(concat(zi,zu,ze,pe))
SemiGNN
文章名称:A Semi-supervised Graph Attentive Network for Financial Fraud Detection
标签:ICDM_A类_2019
一、问题
传统的欺诈检测方法主要是使用一些基于规则的方法或人工分散一些特征来进行预测。然而,在金融服务中,用户具有丰富的交互,他们本身总是显示多方面的信息。这些数据形成了一个大的多视图网络,这是没有充分利用传统的方法。此外,在网络中,只有很少的用户被标注,这也对仅利用有标签数据来实现欺诈检测提出了很大的挑战。而基于机器学习的欺诈模式自动挖掘方法很少考虑用户之间的交互。
考虑到现有方法的局限性,可以利用标注和未标注数据的**多视图数据(Multiview Data)**的欺诈检测方法亟需深入。
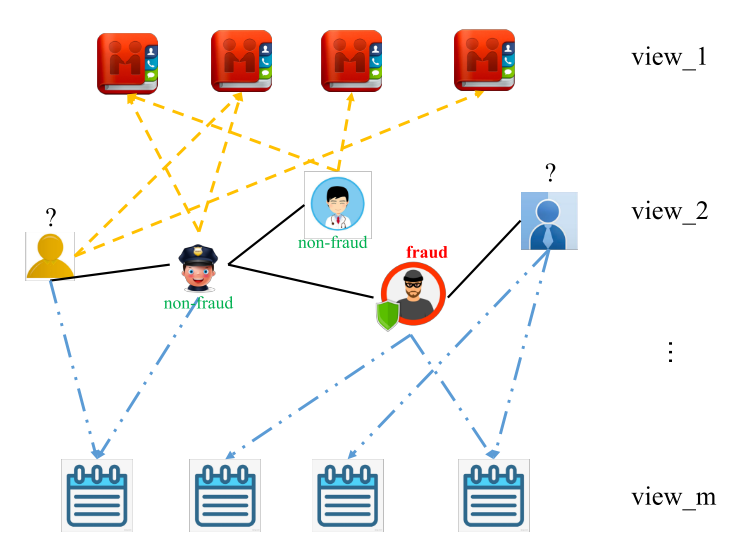
多视图图(Multiview Graph)不同于多关系图(Multi-relation Graph),前者是将实体不同维度的信息构建为多个独立子图,每个视图描述特定类型的关系或属性,视图间节点/边类型不同,本质上处理的是异构数据(不同类型的数据);后者在结构上是指同一图中不同类型边,本质上处理的是同构图中的多重边类型。
二、贡献
- 提出了一种面向多视图数据的半监督图注意力神经网络模型(Semi-supervised Graph Attentive Neural Model,Semi-GNN),充分利用标注数据和无标注数据的关系数据和属性数据来增强用户的表示。
- 提出了一个阶层式的注意力机制,以更好地关联不同的邻居和不同的视图,第一层节点级注意力机制(Node-level Attention)被设计为有效地关联用户的不同邻居或不同属性,第二层视图级注意力机制(View-level Attention)能够关注不同的数据视图。
- 受“欺诈行为总是发生在局部图”的启发,通过已标注用户的社交关系扩展了无标签用户集合,是一种解决无监督学习的方法。
三、方法
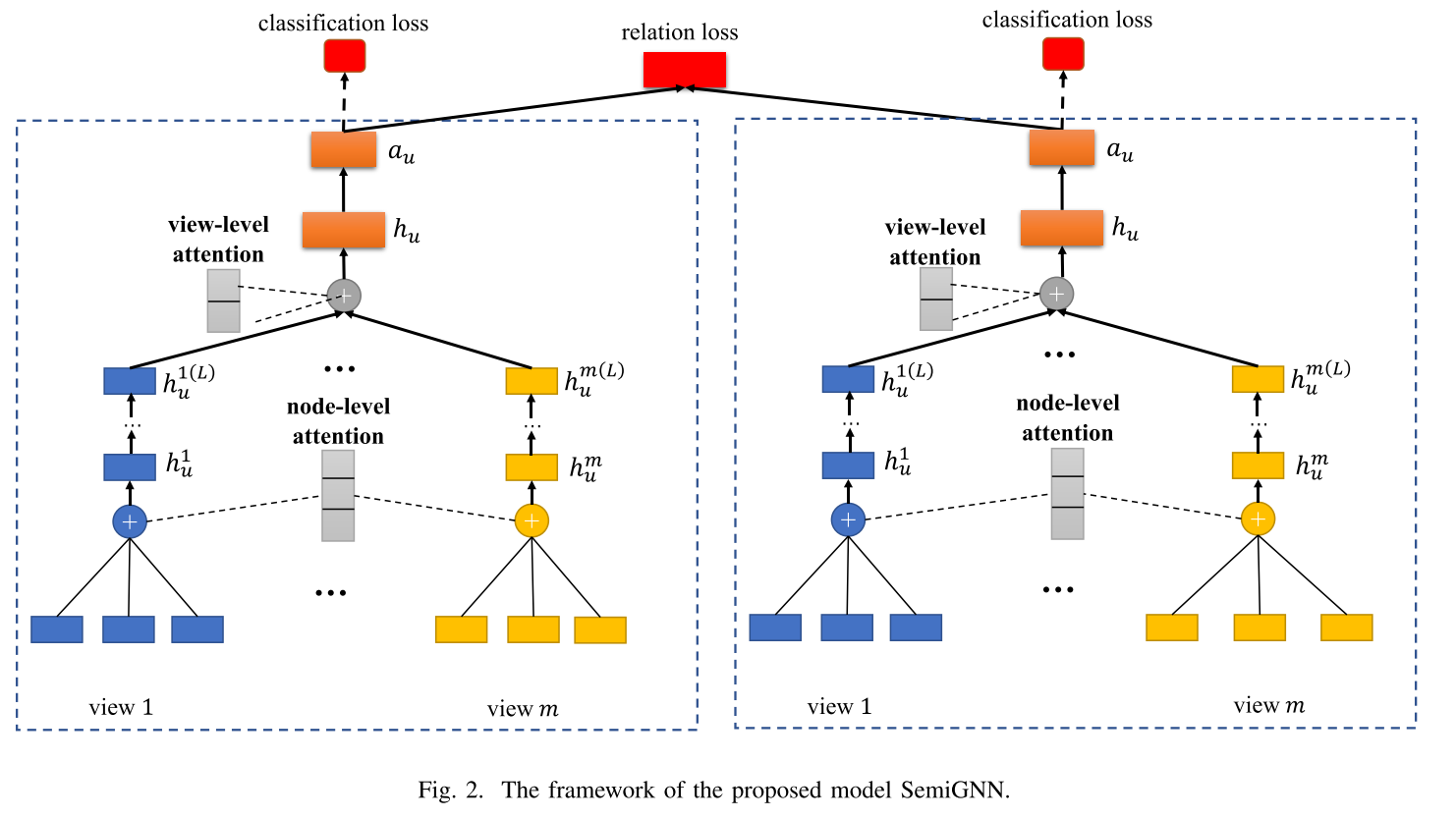
1.节点级注意力机制(node-level attention)
首先要分别对图的每个视图进行建模,为了对图结构进行建模,需要通过集成邻居的嵌入来获得用户的嵌入。可以注意到,每个用户的邻居扮演不同的角色,并对特定任务表现出不同的重要性。
节点级注意力机制用于学习每个视图中的用户的邻居权重,并找到一种最佳的方法来聚合邻居,以获得低级别的特定于视图的用户嵌入。
(1)节点嵌入矩阵
视图
v
v
v的所有节点嵌入表示为
M
v
∈
R
∣
n
v
∣
×
d
M^v\in R^{|n_v|×d}
Mv∈R∣nv∣×d,
d
d
d表示嵌入维度。
(2)加权嵌入计算
对邻居节点
i
∈
N
u
v
i\in N_u^v
i∈Nuv,计算加权嵌入:
e
u
i
v
=
w
u
i
v
⋅
M
i
v
e_{ui}^v=w_{ui}^v\cdot M_i^v
euiv=wuiv⋅Miv
其中
M
i
v
M_i^v
Miv是节点
i
i
i的嵌入向量。
(3)注意力权重计算
引入视图特定的注意力参数矩阵
H
v
H^v
Hv,计算用户
u
u
u与邻居
i
i
i的注意力得分:
s
c
o
r
e
u
i
v
=
e
u
i
v
⋅
H
u
i
v
score_{ui}^v=e_{ui}^v\cdot H_{ui}^v
scoreuiv=euiv⋅Huiv
通过Softmax函数归一化,得到注意力权重
α
u
i
v
\alpha_{ui}^v
αuiv:
α
u
i
v
=
e
x
p
(
s
c
o
r
e
u
i
v
)
∑
k
∈
N
u
v
e
x
p
(
s
c
o
r
e
u
i
v
)
\alpha_{ui}^v=\frac{exp(score_{ui}^v)}{\sum_{k\in N_u^v}^{}exp(score_{ui}^v)}
αuiv=∑k∈Nuvexp(scoreuiv)exp(scoreuiv)
该权重反映了邻居
i
i
i对用户
u
u
u在视图
v
v
v中的重要性。
(4)邻居聚合
使用注意力权重加权聚合邻居嵌入,生成用户
u
u
u在视图
v
v
v的低维表示:
h
u
v
=
∑
i
∈
N
u
v
α
u
i
v
e
u
i
v
h_u^v=\sum_{i\in N_u^v}^{}\alpha_{ui}^ve_{ui}^v
huv=i∈Nuv∑αuiveuiv
2.视图级注意力机制(node-level attention)
为了更全面地了解用户嵌入,我们应该融合信息的多个视图。然而,多视图数据的低维度表示位于异构域中,这使得难以在低维度空间中捕获多视图相关性。为了解决这个问题,我们使用单独的多层感知机MLP将低维度视图特定的用户嵌入投射到高维度空间,然后再聚合多视图数据。
(1)投影到高维度语义空间
对每个视图的低维度嵌入
h
u
v
h_u^v
huv应用MLP进行非线性变换,消除视图间的统计差异:
h
u
v
(
l
)
=
R
e
l
u
(
h
u
v
(
l
−
1
)
W
l
v
+
b
l
v
)
,
v
∈
2
,
.
.
.
,
m
h_u^{v(l)}=Relu(h_u^{v(l-1)}W_l^v+b_l^v),v\in{2,...,m}
huv(l)=Relu(huv(l−1)Wlv+blv),v∈2,...,m
(2)计算视图重要性权重
为每个用户和视图引入视图偏好向量(view preference vector)
ϕ
u
v
\phi_u^v
ϕuv,该向量随机初始化并随着训练过程不断学习,视图重要性通过点积学习:
α
u
v
=
e
x
p
(
h
u
v
(
L
)
⋅
ϕ
u
v
)
∑
k
=
1
m
e
x
p
(
h
u
k
(
L
)
⋅
ϕ
u
k
)
,
v
∈
1
,
.
.
.
,
m
\alpha_u^v=\frac{exp(h_u^{v(L)}\cdot \phi_u^v)}{\sum_{k=1}^{m}exp(h_u^{k(L)}\cdot \phi_u^k)},v\in {1,...,m}
αuv=∑k=1mexp(huk(L)⋅ϕuk)exp(huv(L)⋅ϕuv),v∈1,...,m
(3)加权结合多视图嵌入
使用视图重要性权重
α
u
v
\alpha_u^v
αuv加权聚合所有视图的高维度嵌入:
h
u
=
∣
∣
v
=
1
m
(
α
u
v
⋅
h
u
v
(
L
)
)
h_u=||_{v=1}^m(\alpha_u^v\cdot h_u^{v(L)})
hu=∣∣v=1m(αuv⋅huv(L))
其中,
∣
∣
||
∣∣表示向量拼接,输出
h
u
h_u
hu是联合用户嵌入(joint user embedding),融合了多视图语义。
后续
h
u
h_u
hu输入到一个单层感知机,得到最终嵌入
α
u
\alpha_u
αu用于分类任务。
3.损失函数设计及优化
SemiGNN设计了两种互补的损失函数,协同驱动模型学习。
(1)监督分类损失
L
s
u
p
L_{sup}
Lsup
对于有标签用户,对于嵌入层表示使用softmax来获得分类结果,定义分类损失为标准的多类交叉熵损失函数:
L
s
u
p
=
−
1
∣
U
L
∣
∑
u
∈
U
L
∑
i
=
1
k
I
(
y
u
=
i
)
l
o
g
e
x
p
(
a
u
⋅
θ
i
)
∑
j
=
1
k
e
x
p
(
a
u
⋅
θ
j
)
)
L_{sup} = - \frac{1}{|U_L|} ∑_{u ∈ U_L} ∑_{i=1}^k I(y_u = i) log \frac{exp(a_u · θ_i)} {∑_{j=1}^k exp(a_u · θ_j) )}
Lsup=−∣UL∣1u∈UL∑i=1∑kI(yu=i)log∑j=1kexp(au⋅θj))exp(au⋅θi)
(2)无监督损失
L
g
r
a
p
h
L_{graph}
Lgraph
受“欺诈行为常在局部社交圈内传播,通过社交关系扩展得到的无标签用户,其嵌入应与邻近的有/无标签用户相似”启发,可以利用无标签用户的社交关系图结构信息
G
(
U
)
G^{(U)}
G(U),约束模型学习到的用户嵌入表示
α
u
\alpha^u
αu,使得在关系上邻近的用户在嵌入空间中也更相似:
L
g
r
a
p
h
=
∑
u
∈
U
∑
v
∈
N
u
∪
N
e
g
u
−
l
o
g
(
σ
(
α
u
T
α
v
)
)
−
Q
⋅
E
q
∼
P
n
e
g
(
u
)
l
o
g
(
σ
(
α
u
T
α
q
)
)
L_{graph}=\sum_{u\in U}^{}\sum_{v\in N_u\cup Neg_u}^{}-log(\sigma(\alpha_u^T\alpha_v))-Q\cdot E_{q\sim P_{neg}(u)}log(\sigma(\alpha_u^T\alpha_q))
Lgraph=u∈U∑v∈Nu∪Negu∑−log(σ(αuTαv))−Q⋅Eq∼Pneg(u)log(σ(αuTαq))
其中,
U
=
U
L
∪
U
u
L
U=U_L\cup U_{uL}
U=UL∪UuL表示所有有标签和无标签用户的集合,
N
u
N_u
Nu表示用户
u
u
u在图
G
(
U
)
G^{(U)}
G(U)中的邻居集合(通过随机游走采样得到),
N
e
g
u
Neg_u
Negu表示用户
u
u
u的负样本集合(通常不直接相连或相距较远的节点),
P
n
e
g
(
u
)
∝
d
u
0.75
P_{neg}(u) ∝ d_u^{0.75}
Pneg(u)∝du0.75表示负样本分布,与节点度
d
u
d_u
du的0.75次方成正比,
Q
Q
Q表示每个正样本对应的负样本数量。
(3)联合损失函数
L
S
e
m
i
G
N
N
L_{SemiGNN}
LSemiGNN
L
S
e
m
i
G
N
N
=
α
⋅
L
s
u
p
+
(
1
−
α
)
⋅
L
g
r
a
p
h
+
λ
L
r
e
g
L_{SemiGNN}=\alpha \cdot L_{sup} + (1-\alpha)\cdot L_{graph} + \lambda L_{reg}
LSemiGNN=α⋅Lsup+(1−α)⋅Lgraph+λLreg
其中,
α
\alpha
α是监督损失和无监督损失之间的平衡参数,
L
r
e
g
L_{reg}
Lreg表示模型参数的
L
2
L2
L2正则化。
Player2Vec
文章名称:Key Player Identification in Underground Forums over Attributed Heterogeneous Information Network Embedding Framework
标签:CIKM_A类_2019
简介:该论文内容集中在了数据处理的创新上,检测模型上没有太大的改变。
一、结构
提出了一个自动分析地下论坛的关键玩家识别系统,名叫iDetective。在iDetective中:
- 引入一个属性异构信息网络(AHIN)来表示用户(users)、帖子(threads)、回复(replies)、评论(comments)和板块(sections) 之间的丰富关系;
- 使用基于元路径(meta-path)的方法来整合更高级别的语义来建立地下论坛中用户的相关性;
- 提出Player2Vec来有效学习节点表示(地下论坛用户),用于关键玩家识别。在Player2Vec中,首先将构造的AHIN映射到由 K K K个单视图属性图组成的多视图网络中,该多视图网络编码由 K K K个设计的元路径描述的用户之间相关性,然后使用图卷积网络GCN学习每个单视图属性图嵌入;
- 设计注意力机制以融合不同的单视图属性图学习到的不同嵌入以用于最终表示。
二、贡献
- 提出了一种新颖而自然的特征表示来描述地下论坛用户。在地下论坛关键玩家识别应用中,引入AHIN来表示用户和其他实体之间丰富的语义关系(即帖子、评论、回复和板块),然后提出了一种基于元路径的方法来表征用户之间的相关性;
- 提出了一种AHIN表示学习模型Player2Vec来学习AHIN中节点的低维表示。所提出的模型利用由AHIN表示的结构关系和附加在节点上的属性信息来学习节点的潜在表示;
- 开发了一种名为iDetective的自动系统,用于识别地下论坛中的关键参与者。根据从不同地下论坛收集的大规模数据(Hack Forums、Nulled)和预先标记的真实标签,进行全面的实验研究,以验证iDetective的有效性,所提出的方法和开发的系统可以很容易地扩展到其他社交平台。
三、方法
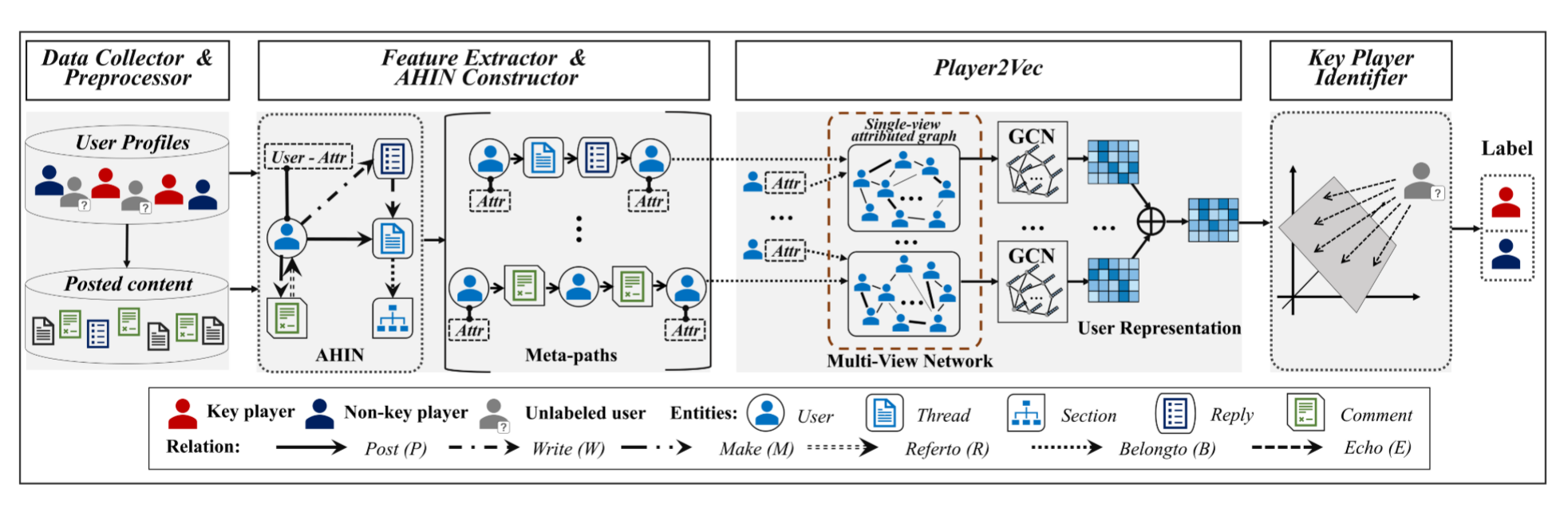
1.数据收集和预处理
收集来自Hack Forums和Nulled的数据,包括用户的个人资料(完全匿名)和发布的内容(即帖子、回复和评论)。对于用户发布的内容,将进一步删除所有的标点符号和停用词,然后使用Stanford CoreNLP进行词形化。
2.特征提取
为了全面地描述用户信息,综合考虑了用户属性信息和关系信息两部分内容。
(1)用户属性信息(User’s attributed information)
基本资料:如用户名(username)、联系方式(contact information)等,应用one-hot编码转化成二进制特征向量。
文本内容:用户发布的帖子、回复和评论的文本,使用doc2vec技术,将长短不一的文本转换成一个固定长度的数字向量,该向量可以捕捉文本的语义信息。
最后,将这些信息拼接起来,形成每个用户的初始“属性特征向量”。
(2)关系信息(Relation-based Features)
提取了6种基本关系,并使用矩阵进行表示:
| 关系名称 | 关系描述 | 矩阵表示 |
|---|---|---|
| user-post-thread,R1 | 用户i是否发布了帖子j | P |
| user-write-reply,R2 | 用户i是否写了回复j | W |
| user-make-comment,R3 | 用户i是否发表评论j | M |
| thread-belongto-section,R4 | 帖子i是否属于板块j的 | B |
| reply-echo-thread,R5 | 回复i是否是针对帖子j的 | E |
| comment-referto-user,R6 | 评论i是否是针对用户j的 | R |
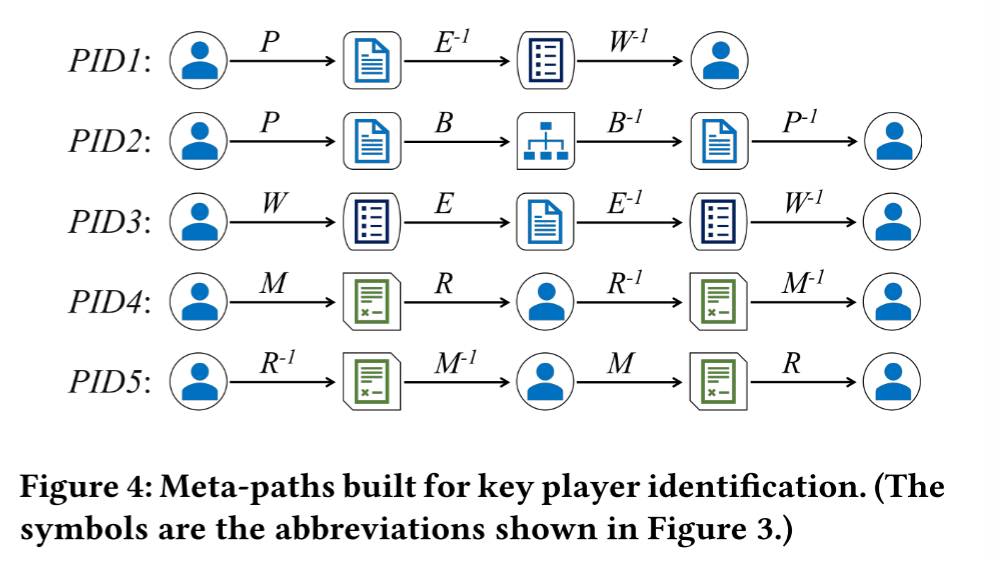
3.构建AHIN
五种实体类型(用户、帖子、回复、评论和板块)和它们之间的六种关系(R1-R6),为了表达AHIN中实体间的高阶关系,引入元路径(meta-path)
P
P
P的设计。
设计了五种元路径来表征地下论坛用户的相关性,不同的元路径描述了两个用户在不同视图之间的相关性。
4.Player2Vec
给定AHIN
G
=
(
V
,
E
,
A
)
G=(V,E,A)
G=(V,E,A)和
K
K
K条元路径,建立一个涵盖
K
K
K个单视图属性图的多视图网络。
(1)Single-View Attributed Graph Embedding with GCN
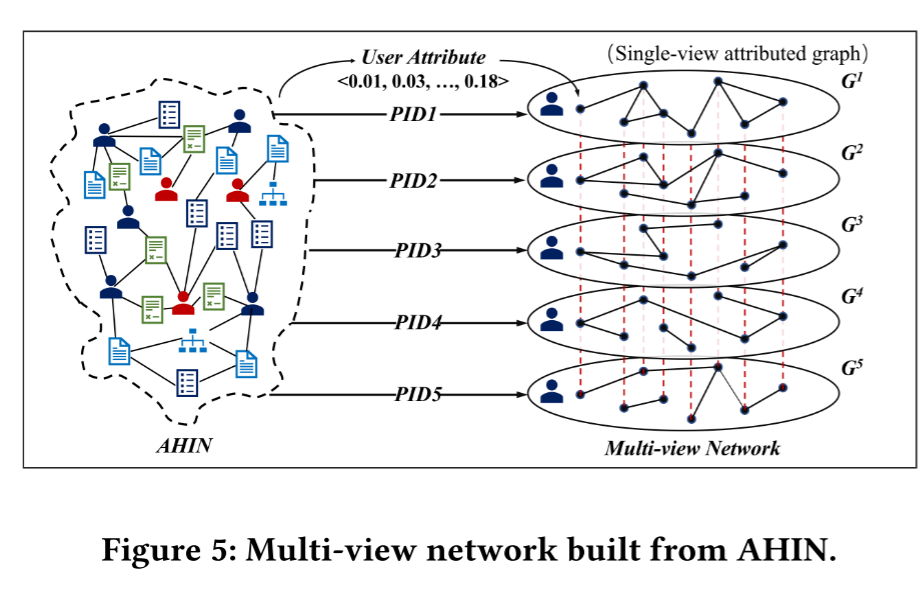
对5个只包含用户和用户间连边的简单图
G
k
=
(
V
k
,
E
k
)
G^k=(V^k,E^k)
Gk=(Vk,Ek),每个图附带了用户的初始属性特征,使用一个两层的GCN学习该视图下的用户嵌入
f
k
f^k
fk。
(2)Multi-View Network Embedding with Attention
一个用户现在有5个不同视图的嵌入向量,需要把它们融合成一个最终的向量。由于用户对从不同元路径生成的嵌入有不同的偏好,使用注意力机制自动学习不同视图的注意力权重。
具体地来说,使用softmax单元定义节点
i
i
i在视图
k
k
k下的注意力权重:
α
i
,
k
=
e
x
p
(
z
k
T
⋅
f
i
C
)
∑
k
′
∈
K
e
x
p
(
z
k
T
⋅
f
i
C
)
\alpha_{i,k}=\frac{exp(z^{k^T}\cdot f_i^C)}{\sum_{k'\in K}^{}exp(z^{k^T}\cdot f_i^C)}
αi,k=∑k′∈Kexp(zkT⋅fiC)exp(zkT⋅fiC)
其中,
z
k
z^k
zk表示视图
k
k
k的注意力向量,
f
i
C
f_i^C
fiC表示节点
i
i
i相对于所有视图的级联。
最终嵌入表示为:
e
i
=
∑
k
∈
K
α
i
,
k
⋅
f
i
k
e_i=\sum_{k\in K}^{}\alpha_{i,k}\cdot f_i^k
ei=k∈K∑αi,k⋅fik
其中,
f
i
k
f_i^k
fik是节点
i
i
i基于视图
k
k
k的嵌入。
CARE-GNN
文章名称:Enhancing Graph Neural Network-based Fraud Detectors against Camouflaged Fraudsters
标签:CIKM_B类_2020
开源地址:https://github.com/YingtongDou/CARE-GNN.
一、问题
互联网服务的蓬勃发展孕育了各种欺诈活动,欺诈者伪装成普通用户以绕过反欺诈系统并散布虚假信息或获取最终用户的隐私。为了检测这些欺诈活动,基于图的方法已经成为学术界和工业界的有效方法。基于图的方法将具有不同关系的实体连接起来,并在图的级别上揭示这些实体的可疑性。
现有的基于GNN的欺诈检测工作仅在狭隘的范围内应用GNN,忽视了欺诈者的伪装行为。欺诈者的伪装行为会影响基于GNN的欺诈检测器在聚合过程中的性能,即现有的GNN不具备应对特征伪装(feature camouflage)和关系伪装(relation camouflage)两种典型的伪装方式的能力,导致它们在欺诈检测问题中的性能很差。
二、贡献
提出了一种名为CARE-GNN的模型,通过三个独特的模块来增强GNN的聚合过程。
- 针对特征伪装,提出了一个标签感知的相似性度量(label-aware similarity measure),基于节点特征找到最相似的邻居节点;
- 针对关系伪装,设计了一个相似性感知的邻居选择器(similarity-aware neighbor selector) 来选择一个关系中中心节点的相似邻居,并利用强化学习沿着GNN训练的过程自适应地找到最佳的邻居选择阈值。
- 利用强化学习的邻居过滤阈值来制定一个关系感知的邻居聚合器(relation-aware neighbor aggregator),该聚合器结合了来自不同关系的邻居信息,并获得了最终的中心节点表示。
三、方法
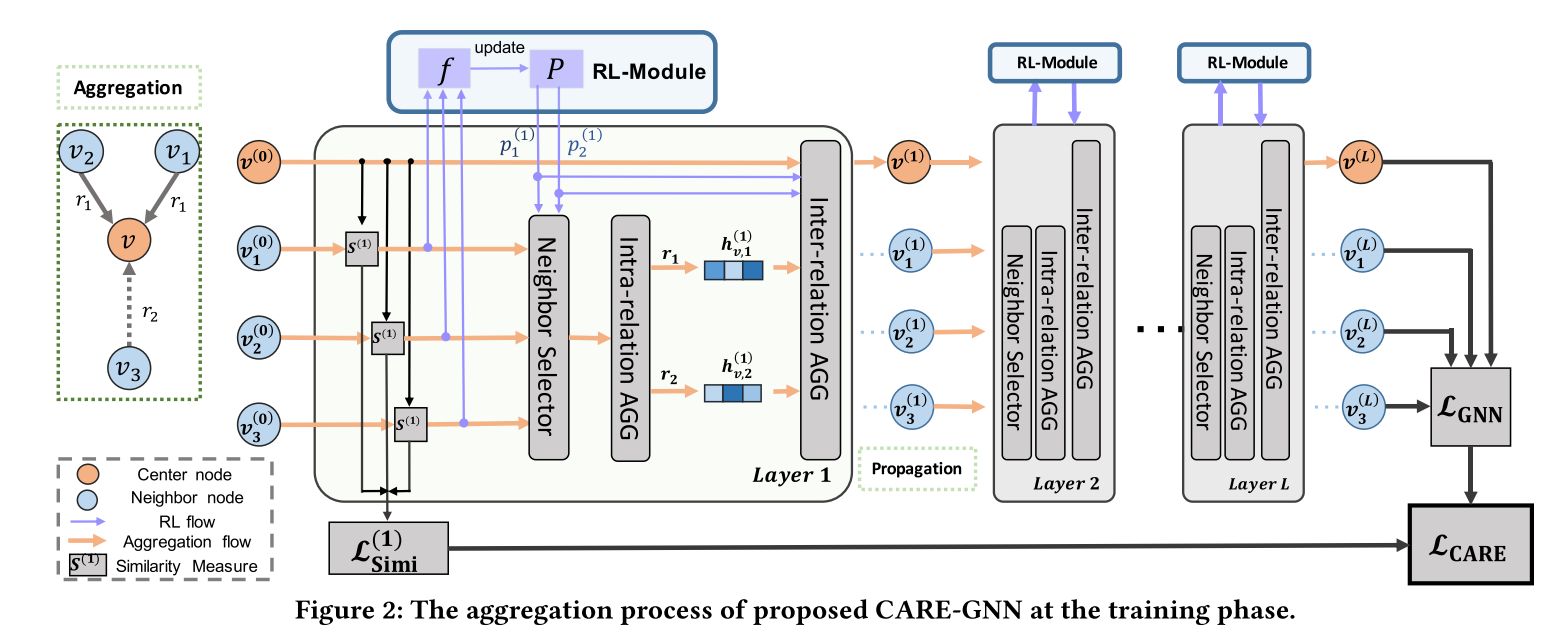
1.标签感知的相似性度量(label-aware similarity measure)
(1)label-aware similarity measure
a one-layer MLP 作为每一层的节点标签预测器 +
l
1
l_1
l1-distance:
D
(
l
)
(
v
,
v
′
)
=
∣
∣
σ
(
M
L
P
(
l
)
(
h
v
(
l
−
1
)
)
)
−
σ
(
M
L
P
(
l
)
(
h
v
′
(
l
−
1
)
)
)
∣
∣
1
D^{(l)}(v,v')=||\sigma(MLP^{(l)}(h_v^{(l-1)}))-\sigma(MLP^{(l)}(h_{v'}^{(l-1)}))||_1
D(l)(v,v′)=∣∣σ(MLP(l)(hv(l−1)))−σ(MLP(l)(hv′(l−1)))∣∣1
得相似性度量为:
S
(
l
)
(
v
,
v
′
)
=
1
−
D
(
l
)
(
v
,
v
′
)
S^{(l)}(v,v')=1-D^{(l)}(v,v')
S(l)(v,v′)=1−D(l)(v,v′)
(2)optimization
与GNN一起训练相似性度量,将MLP在
l
l
l层的交叉熵损失函数定义为:
L
S
i
m
i
(
l
)
=
∑
v
∈
V
−
l
o
g
(
y
v
⋅
σ
(
M
L
P
(
l
)
(
h
v
(
l
)
)
)
)
L_{Simi}^{(l)}=\sum_{v\in V}^{}-log(y_v\cdot \sigma(MLP^{(l)}(h_v^{(l)})))
LSimi(l)=v∈V∑−log(yv⋅σ(MLP(l)(hv(l))))
2.相似性感知的邻居选择器(similarity-aware neighbor selector)
(1)Top-p Sampling
针对关系
r
r
r在第
l
l
l层的过滤阈值表示为
p
r
(
l
)
∈
[
0
,
1
]
p_r^{(l)}\in [0,1]
pr(l)∈[0,1]。在训练阶段,针对关系
r
r
r下的当前批次中的节点
v
v
v,首先计算出其相似性度量
S
(
l
)
(
v
,
v
′
)
=
1
−
D
(
l
)
(
v
,
v
′
)
S^{(l)}(v,v')=1-D^{(l)}(v,v')
S(l)(v,v′)=1−D(l)(v,v′),然后根据相似性度量按照降序排列节点
v
v
v的邻居,取前
p
r
(
l
)
⋅
∣
S
(
l
)
(
v
,
v
′
)
=
1
−
D
(
l
)
(
v
,
v
′
)
∣
p_r^{(l)}\cdot |S^{(l)}(v,v')=1-D^{(l)}(v,v')|
pr(l)⋅∣S(l)(v,v′)=1−D(l)(v,v′)∣作为在第
l
l
l层所选择的邻居,所有其他节点在当前批处理中被丢弃,并且不参与聚合过程。
(2)Finding the Optimal Thresholds with RL
由于
p
r
(
l
)
p_r^{(l)}
pr(l)是一个不具备梯度的概率,因此我们不呢使用分类损失的反向传播来更新它。同时,给定
p
r
(
l
)
p_r^{(l)}
pr(l),仅基于当前批次下的相似性得分来估计所选邻居的质量是不可行的。
解决方案:应用强化学习(RL)框架来寻找最佳阈值,将RL过程表示为邻居选择器与GNN之间的Bernoulli Multiarmed Bandit(BMAB)
B
(
A
,
f
,
T
)
B(A,f,T)
B(A,f,T)。
3.关系感知的邻居聚合器(relation-aware neighbor aggregator)
并非直接聚合所有关系下的邻居,而是分离聚合过程为关系内聚合(intra-relation aggregation)和关系间聚合(inter-relation aggregation),前者聚合每个关系下的邻居嵌入,后者组合每个关系的嵌入。
在过滤每个关系下的邻居之后,下一步是聚合来自不同关系的邻居信息。为了保留关系的重要性信息的同时节省计算成本,直接使用RL过程学习的最佳过滤阈值
p
r
(
l
)
p_r^{(l)}
pr(l)作为**关系间聚合(inter-relation aggregation)**的权重。
关系内聚合:
h
v
,
r
(
l
)
=
R
e
L
U
(
A
G
G
r
(
l
)
(
{
h
v
′
(
l
−
1
)
:
(
v
,
v
′
)
∈
E
r
(
l
)
}
)
)
h_{v,r}^{(l)}=ReLU(AGG_r^{(l)}(\{h_{v'}^{(l-1)}:(v,v')\in E_r^{(l)}\}))
hv,r(l)=ReLU(AGGr(l)({hv′(l−1):(v,v′)∈Er(l)}))
关系间聚合:
h
v
,
r
(
l
)
=
R
e
L
U
(
A
G
G
a
l
l
(
l
)
(
{
h
v
(
l
−
1
)
⊕
{
p
r
(
l
)
⋅
h
v
,
r
(
l
)
}
∣
r
=
1
R
)
)
h_{v,r}^{(l)}=ReLU(AGG_{all}^{(l)}(\{h_{v}^{(l-1)}\oplus \{p_r^{(l)}\cdot h_{v,r}^{(l)}\}|_{r=1}^R))
hv,r(l)=ReLU(AGGall(l)({hv(l−1)⊕{pr(l)⋅hv,r(l)}∣r=1R))
4.损失函数
对于每一个节点
v
v
v,它的最终嵌入是GNN在最后一层的输出
z
v
=
h
v
(
L
)
z_v=h_v^{(L)}
zv=hv(L)。我们可以GNN的损失函数为交叉熵损失函数:
L
G
N
N
=
∑
v
∈
V
−
l
o
g
(
y
v
⋅
σ
(
M
L
P
(
z
v
)
)
)
L_{GNN}=\sum_{v\in V}^{}-log(y_v\cdot \sigma(MLP(z_v)))
LGNN=v∈V∑−log(yv⋅σ(MLP(zv)))
CARE-GNN的损失函数为:
L
C
A
R
E
=
L
G
N
N
+
λ
1
L
S
i
m
i
(
l
)
+
λ
2
∣
∣
θ
∣
∣
2
L_{CARE}=L_{GNN}+\lambda_1L_{Simi}^{(l)}+\lambda_2||\theta||_2
LCARE=LGNN+λ1LSimi(l)+λ2∣∣θ∣∣2
GraphConsis
文章名称:Alleviating the Inconsistency Problem of Applying Graph Neural Network to Fraud Detection
标签:SIGIR_A类_2020
开源地址:https://github.com/safe-graph/DGFraud
1.问题
基于图的欺诈检测器通过聚合邻域信息来学习节点的嵌入,聚合依赖于邻居共享相似性的上下文、特征和关系。也就是说,聚合机制基于邻居共享相似特征和标签的假设,当假设不成立时,我们就不能再聚合邻域信息来学习节点嵌入。然而,传统的GNN直接聚合邻居信息会混淆欺诈特征。欺诈者所引起的不一致性问题来自三个方面:
(1)上下文不一致性(context inconsistency):欺诈者伪装成正常用户,与大量正常节点连接。例如,在图1(左)中,欺诈者
v
1
v_1
v1在关系II下连接到3个良性实体。
(2)特征不一致性(feature inconsistency):同一节点在不同场景下的行为特征差异大。例如,在图1(左)中,节点
v
2
v_2
v2和节点
v
3
v_3
v3与
v
1
v_1
v1之间具有相同的关系,但是它们的特征可能会有很大差异,直接聚合会使得GNN难以区分节点的独特语义特征,最终影响其检测欺诈节点的能力。
(3)关系不一致性(relation inconsistency):不同关系对欺诈检测的贡献度不同。例如,在图1(左)中,我们发现在关系I下,欺诈者
v
1
v_1
v1与另外两个欺诈者相关联,然而,在关系II下,欺诈者只与一个欺诈者有联系,与三个良性实体有联系。
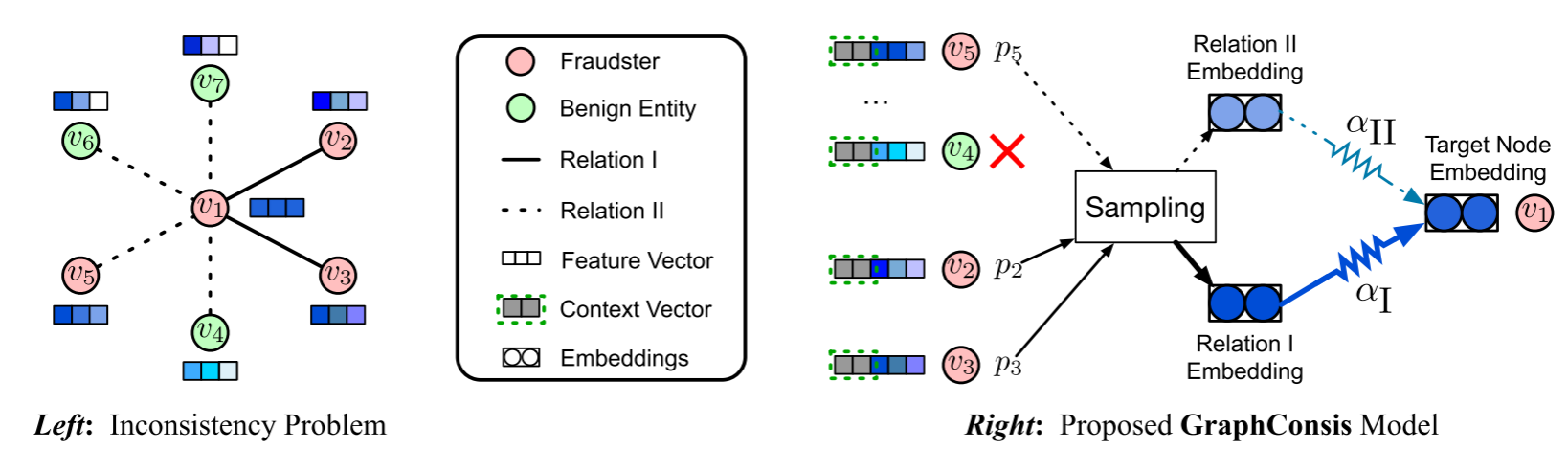
2.贡献
设计了一个新的GNN框架,名为GraphConsis。GraphConsis构建在具有多个关系的异构图上,设计了三种技术来同时解决三个不一致性问题,而不是直接聚合领域嵌入:
- 第一个解决GNN模型中不一致性问题的工作;
- 结合了上下文嵌入、邻域信息度量和关系注意力机制。
3.方法
(1)Context Embedding
为节点
v
v
v引入了可训练的上下文嵌入
c
v
c_v
cv,而不是仅使用其特征向量
x
v
x_v
xv。聚合器的第一层变为:
h
v
(
1
)
=
{
x
v
∣
∣
c
v
}
⊕
A
G
G
(
1
)
(
{
x
v
′
∣
∣
c
v
′
:
v
′
∈
N
v
}
)
h_v^{(1)}=\{x_v||c_v\}\oplus AGG^{(1)}(\{x_{v'}||c_{v'}:v'\in N_v\})
hv(1)={xv∣∣cv}⊕AGG(1)({xv′∣∣cv′:v′∈Nv})
其中,||表示级联操作。训练上下文嵌入来表示节点的局部结构,这可以帮助区分欺诈。
(2)Neighbor Sampling
由于存在特征不一致的问题,我们应该对相关的邻居进行采样,而不是为它们分配相等的概率。因此,我们计算嵌入之间的一致性得分:
s
(
l
)
(
u
,
v
)
=
e
x
p
(
−
∣
∣
h
u
(
l
)
−
h
v
(
l
)
∣
∣
2
2
)
s^{(l)}(u,v)=exp(-||h_u^{(l)}-h_v^{(l)}||_2^2)
s(l)(u,v)=exp(−∣∣hu(l)−hv(l)∣∣22)
其中,
s
(
l
)
(
⋅
,
⋅
)
s^{(l)}(\cdot,\cdot)
s(l)(⋅,⋅)表示第
l
l
l层的两个节点的一致性得分,
∣
∣
⋅
∣
∣
2
||\cdot||_2
∣∣⋅∣∣2表示向量的
l
2
l_2
l2范数。我们使用一个阈值
ϵ
\epsilon
ϵ过滤远离一致性的邻居。然后,我们将每个节点
u
u
u分配给节点
v
v
v的过滤后的邻居
N
∼
v
\overset{\sim}{N}_v
N∼v,并通过归一化其一致性得分来确定采样概率:
p
(
l
)
(
u
;
v
)
=
s
(
l
)
(
u
,
v
)
/
∑
u
∈
N
∼
v
s
(
l
)
(
u
,
v
)
p^{(l)}(u;v)=s^{(l)}(u,v)/\sum_{u\in \overset{\sim}{N}_v}^{}s^{(l)}(u,v)
p(l)(u;v)=s(l)(u,v)/u∈N∼v∑s(l)(u,v)
该概率会在
A
G
G
(
l
)
AGG^{(l)}
AGG(l)的每一层进行计算。
(3)Relation Attention
图中有
R
R
R个不同的关系,在聚合过程中应该包括关系信息,以解决关系不一致的问题。因此,对于每个关系
r
r
r,我们训练关系向量
t
r
t_r
tr,其中
r
=
1
,
2
,
.
.
.
,
R
r={1,2,...,R}
r=1,2,...,R,以表示应该被合并的关系信息。由于关系信息应该与中心节点
v
v
v的邻居一起聚合,因此,我们采用自注意力机制为
Q
Q
Q个采样的邻居节点分配权重:
α
q
(
l
)
=
e
x
p
(
σ
(
{
h
q
(
l
)
∣
∣
t
r
q
}
a
T
)
)
/
∑
q
=
1
Q
e
x
p
(
σ
(
{
h
q
(
l
)
∣
∣
t
r
q
}
a
T
)
)
\alpha_q^{(l)}=exp(\sigma(\{h_q^{(l)}||t_{r_q}\}a^\mathrm{T}))/\sum_{q=1}^{Q}exp(\sigma(\{h_q^{(l)}||t_{r_q}\}a^\mathrm{T}))
αq(l)=exp(σ({hq(l)∣∣trq}aT))/q=1∑Qexp(σ({hq(l)∣∣trq}aT))
其中,
r
q
r_q
rq表示第
q
q
q个样本与节点
v
v
v的关系,
σ
\sigma
σ表示激活函数,
a
a
a表示所有注意力层共享的注意力权重。最终的
A
G
G
(
l
)
AGG^{(l)}
AGG(l)为:
A
G
G
(
l
)
(
{
h
q
(
l
−
1
)
}
∣
q
=
1
Q
)
=
∑
q
=
1
Q
α
q
(
l
)
h
q
(
l
)
AGG^{(l)}(\{h_q^{(l-1)}\}|_{q=1}^Q)=\sum_{q=1}^{Q}\alpha_q^{(l)}h_q^{(l)}
AGG(l)({hq(l−1)}∣q=1Q)=q=1∑Qαq(l)hq(l)
RIOGNN
文章名称:Reinforced Neighborhood Selection Guided Multi-Relational Graph Neural Networks
标签:TOIS_A类_2021
开源地址:https://github.com/safe-graph/RioGNN
一、问题
将专门用于对抗伪装欺诈者的欺诈检测器CARE-GNN的工作扩展为一个适用于更加广泛任务的通用架构,CARE-GNN使用了Bernoulli Multi-armed Bandit方法,结合固定策略来加强对过滤阈值的学习。然而,这种方法实质上受到状态的观测范围和手动指定的策略的限制,因此,过滤阈值的最终收敛结果趋于局部最优。此外,为了保持预测精度,面对大规模数据集时,必须减小过滤阈值的调整步长或采用连续的动作空间,这一过程无疑会扩大动作(action)空间,导致收敛周期数的增加和计算量的巨大增长,可能会损失精度。这个问题需要一个自动且高效的强化学习框架来解决。
二、贡献
相对于CARE-GNN的工作来说
- 第一个基于多关系图的任务驱动的GNN框架,充分利用关系采样、消息传递、度量学习和强化学习来指导不同关系内和关系间的邻居选择,给出了不同实际任务下多关系图神经网络的完整定义、动机和目标;
- 一个灵活的领域选择框架,采用了一个增强的关系感知的邻居选择器与标签感知的神经相似性邻居度量,将标签感知的相似性邻居度量从一层扩展到多层;
- 一个递归和可扩展的强化学习框架(Recursive and Scalable Reinforcement Learning,RSRL),通过不同规模的图或任务的可估计深度和宽度来学习优化每个关系内的过滤阈值,取代了CARE-GNN中的Bernoulli Multi-armed Bandit方法,并利用离散和连续策略来找到在强化学习框架下要选择的不同关系的最佳邻居;
- 第一次从不同关系的重要性角度研究多关系GNN的可解释性,在三个代表性和通用数据集上进行广泛的实验,不限于欺诈检测场景。
三、方法
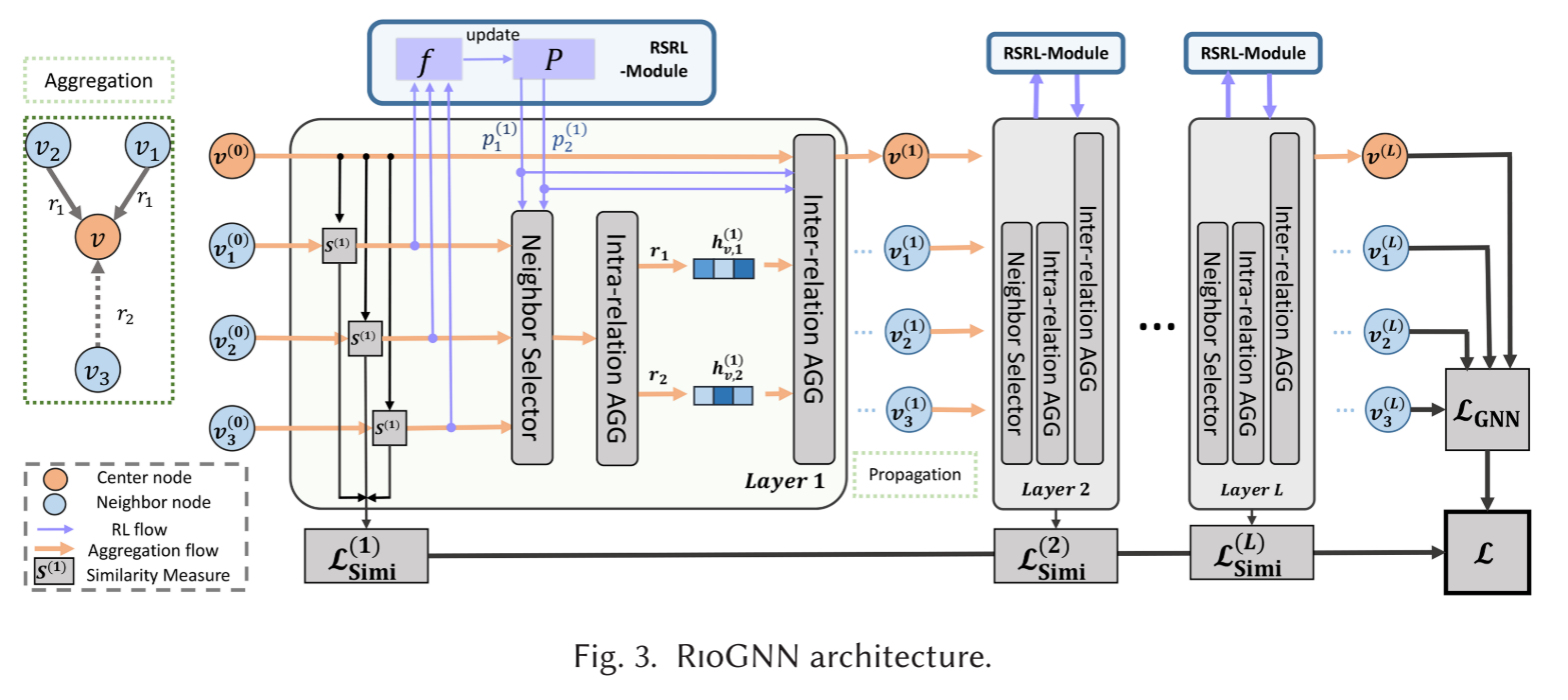
1.标签感知的神经相似性度量(label-aware neural similarity measure)
an FCN(Fully-Connected Network) as the node label predictor at each layer of RIOGNN +
l
1
l_1
l1-distance:
D
(
l
)
(
v
,
v
′
)
=
∣
∣
σ
(
F
C
N
(
l
)
(
h
v
(
l
−
1
)
)
)
−
σ
(
F
C
N
(
l
)
(
h
v
′
(
l
−
1
)
)
)
∣
∣
1
D^{(l)}(v,v')=||\sigma(FCN^{(l)}(h_v^{(l-1)}))-\sigma(FCN^{(l)}(h_{v'}^{(l-1)}))||_1
D(l)(v,v′)=∣∣σ(FCN(l)(hv(l−1)))−σ(FCN(l)(hv′(l−1)))∣∣1
得两个节点之间的相似性:
S
(
l
)
(
v
,
v
′
)
=
1
−
D
(
l
)
(
v
,
v
′
)
S^{(l)}(v,v')=1-D^{(l)}(v,v')
S(l)(v,v′)=1−D(l)(v,v′)
为了使用来自标签的直接监督信号训练相似性度量,将第
l
l
l层中FCN的交叉熵损失函数定义为:
L
S
i
m
i
(
l
)
=
∑
v
∈
V
−
l
o
g
(
y
v
⋅
σ
(
F
C
N
(
l
)
(
h
v
(
l
)
)
)
)
L_{Simi}^{(l)}=\sum_{v\in V}^{}-log(y_v\cdot \sigma(FCN^{(l)}(h_v^{(l)})))
LSimi(l)=v∈V∑−log(yv⋅σ(FCN(l)(hv(l))))
进一步地,将整个网络的标签感知的相似性度量的交叉熵损失函数定义为:
L
S
i
m
i
=
∑
l
=
1
L
L
S
i
m
i
(
l
)
L_{Simi}=\sum_{l=1}^{L}L_{Simi}^{(l)}
LSimi=l=1∑LLSimi(l)
2.相似度感知的自适应邻居选择器(similarity-aware adaptive neighbor selector)
(1)Top-p Sampling
与CARE-GNN一样的方法,同样需要找到过滤阈值
p
r
l
∈
[
0
,
1
]
p_r^l\in [0,1]
prl∈[0,1]。
(2)RSRL 框架
将RSRL形式化为一个
L
L
L-layer Reinforcement Learning(RL)Forest,将第
l
l
l层的forest定义为:
R
L
F
(
l
)
=
{
R
L
T
r
(
l
)
}
∣
r
=
1
R
=
{
R
L
r
(
l
)
(
d
)
∣
d
=
1
D
r
(
l
)
}
∣
r
=
1
R
RLF^{(l)}=\{RLT_r^{(l)}\}|_{r=1}^R=\{{RL_r^{(l)(d)}}|_{d=1}^{D_r^{(l)}}\}|_{r=1}^R
RLF(l)={RLTr(l)}∣r=1R={RLr(l)(d)∣d=1Dr(l)}∣r=1R,
R
L
F
(
l
)
RLF^{(l)}
RLF(l)实际上表示在第
l
l
l层获得最佳关系过滤阈值组合的过程,每个关系使用一个自适应深度
D
r
(
l
)
=
⌜
l
o
g
α
k
r
⌝
D_r^{(l)}=\ulcorner log_\alpha ^{k_r} \urcorner
Dr(l)=┌logαkr┐和一个宽度
W
r
(
l
)
(
d
)
=
1
α
d
W_r^{(l)(d)}=\frac{1}{\alpha^d}
Wr(l)(d)=αd1独立地构建一个RL Tree
R
L
T
r
(
l
)
RLT_r^{(l)}
RLTr(l),
α
\alpha
α是深度优先和宽度优先的权重参数,
k
r
k_r
kr是包含在关系
r
r
r中的节点中的邻居的最大数目。
R
L
T
r
(
l
)
RLT_r^{(l)}
RLTr(l)递归过程表示为:
p
r
(
l
)
(
d
)
←
R
L
r
(
l
)
(
d
)
{
p
r
(
l
)
(
d
)
−
W
r
(
l
)
(
d
)
2
,
p
r
(
l
)
(
d
)
+
W
r
(
l
)
(
d
)
2
}
p_r^{(l)(d)}\xleftarrow{RL_r^{(l)(d)}} \{p_r^{(l)(d)}-\frac{W_r^{(l)(d)}}{2},p_r^{(l)(d)}+\frac{W_r^{(l)(d)}}{2}\}
pr(l)(d)RLr(l)(d){pr(l)(d)−2Wr(l)(d),pr(l)(d)+2Wr(l)(d)},
将RL模块表示为马尔可夫过程MDP<
A
,
S
,
R
,
F
A,S,R,F
A,S,R,F>,为了更好地处理不同大小和不同场景的数据集,将解决方案分为两个不同的类别:Discrete Reinforcement Learning(D-RL)和Continuous Reinforcement Learning(C-RL)。
3.关系感知的权重邻居聚合器(relation-aware weighted neighbor aggregator)
关系内聚合:
h
v
,
r
(
l
)
=
R
e
L
U
(
A
G
G
r
(
l
)
(
{
⊕
h
v
′
(
l
−
1
)
:
v
′
∈
N
r
(
l
)
(
v
)
}
)
)
h_{v,r}^{(l)}=ReLU(AGG_r^{(l)}(\{\oplus h_{v'}^{(l-1)}:v'\in N_r^{(l)}(v)\}))
hv,r(l)=ReLU(AGGr(l)({⊕hv′(l−1):v′∈Nr(l)(v)}))
关系间聚合:
h
v
(
l
)
=
R
e
L
U
(
h
v
(
l
−
1
)
⊕
A
G
G
(
l
)
(
{
⊕
(
p
r
(
l
)
⋅
h
v
,
r
(
l
)
)
}
∣
r
=
1
R
)
)
h_v^{(l)}=ReLU(h_v^{(l-1)}\oplus AGG^{(l)}(\{\oplus (p_r^{(l)}\cdot h_{v,r}^{(l)})\}|_{r=1}^R))
hv(l)=ReLU(hv(l−1)⊕AGG(l)({⊕(pr(l)⋅hv,r(l))}∣r=1R))
4.损失函数
将节点
v
v
v的最终嵌入表示为
z
v
=
h
v
(
L
)
z_v=h_v^{(L)}
zv=hv(L),并将GNN在节点分类任务上的交叉熵损失函数表示为:
L
G
N
N
=
∑
v
∈
V
−
l
o
g
(
y
v
⋅
σ
(
M
L
P
(
l
)
(
z
v
)
)
)
L_{GNN}=\sum_{v\in V}^{}-log(y_v\cdot \sigma(MLP^{(l)}(z_v)))
LGNN=v∈V∑−log(yv⋅σ(MLP(l)(zv))),
RIOGNN最终的损失函数表示为:
L
R
I
O
G
N
N
=
L
G
N
N
+
λ
l
∑
l
=
1
L
L
S
i
m
i
(
l
)
+
λ
∗
∣
∣
Θ
∣
∣
2
L_{RIOGNN}=L_{GNN}+\lambda_l\sum_{l=1}^{L}L_{Simi}^{(l)}+\lambda_*||\Theta||_2
LRIOGNN=LGNN+λll=1∑LLSimi(l)+λ∗∣∣Θ∣∣2
GTAN
文章名称:Semi-supervised Credit Card Fraud Detection via Attribute-Driven Graph Representation
标签:AAAI_A类_2023
开源地址:https://github.com/finint/antifraud
一、问题
**信用卡欺诈(credit card fraud)**给持卡人和发卡银行都带来了相当大的损失。现代方法应用基于机器学习的分类器从标记的交易记录中检测欺诈行为。但是由于昂贵的标记成本,标记数据通常只占数十亿真实的交易的一小部分,这意味着它们不能很好地利用未标记数据的许多自然特征。
最新的欺诈检测技术(如CARE-GNN)可以很好地捕获交易的时态或基于图的模式,并显著提高信用卡欺诈检测的性能。然而,这些方法至少有以下三个主要限制之一:
(1)忽略包含丰富的欺诈模式信息的未标记数据;
(2)忽略在真实的生产环境中普遍存在的离散属性(categorical attributes);
(3)需要太多时间进行特征工程,特别是离散特征。
二、贡献
- 将信用卡行为建模为时序交易图,并将信用卡欺诈检测问题制定为半监督节点分类任务;
- 提出了一种新的用于信用卡欺诈检测的属性驱动的时序图神经网络。具体来说,提出了一种门控时序注意力网络(gated temporal attention network,GTAN)来提取时序和属性信息。在时序交易图上利用有标签数据和无标签数据来传递属性信息和风险信息(risk information)。
三、方法
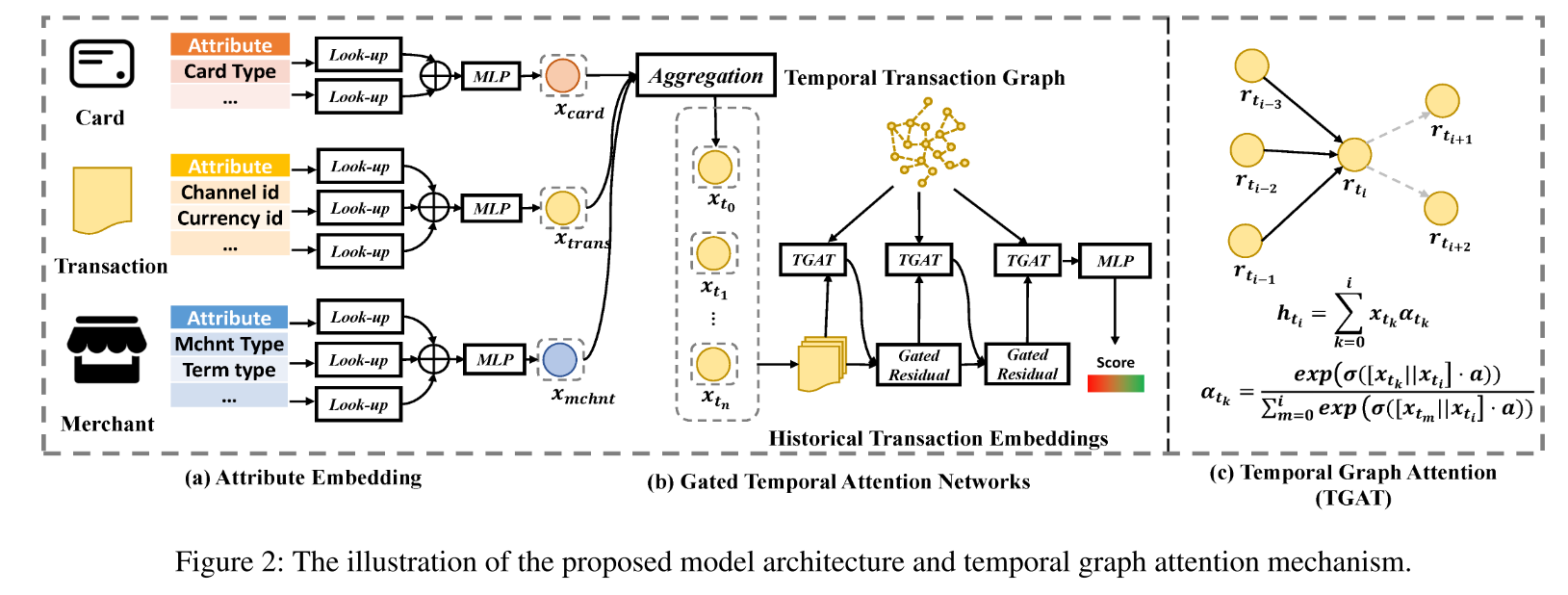
1.模型架构
交易记录的原始属性首先由属性嵌入查找(attribute embedding look-up)和特征学习层学习,该层包括具有多层感知(MLP)的特征聚合。具体实现中,**卡片属性(the attributes of card)**包括卡片类型(card type)、持卡人类型(cardholder type)、卡片额度(card limit)、剩余额度(remaining limit)等等;**交易属性(the attributes of transaction)**包括渠道ID(channel ID)、币种ID(currency ID)、交易金额(transaction amount)等等;**商户属性(the attributes of merchant)**包括商户类型(merchant type)、终端类型(terminal type)、商户位置(merchant location)、扇区(sector)、收费比例(charge ratio)等等。
然后,作者设计了一个门控时序注意力网络来聚合和学习历史交易嵌入的重要性。之后,利用两层的MLP来从这些表示中学习欺诈概率。整个模型可以在一个端到端的机制中,结合现有的随机梯度下降算法(SGD)进行优化。
2.属性嵌入和特征学习(Attribute Embedding and Feature Learning)
(1)交易记录集 r = ( r 1 , r 2 , . . . , r N ) r=(r_1,r_2,...,r_N) r=(r1,r2,...,rN), r i = f c i , f r i , f m i r_i=f_c^i,f_r^i,f_m^i ri=fci,fri,fmi由卡片属性 f c i f_c^i fci、交易属性 f r i f_r^i fri和商户属性 f m i f_m^i fmi构成;
(2)交易记录的数值属性(numerical attributes)构造为张量格式 X n u m X_{num} Xnum;
(3)使用属性嵌入层(Look-up + MLP)各自提取卡片、交易和商户的离散属性(categorical attributes)为 X c a t X_{cat} Xcat;
(4)通过adding-pool聚合三个属性的离散嵌入向量 x c a t ( u ) = ∑ i x c a t ( u ) , i ∈ c a r d , t r a n s , m c h n t x_{cat}^{(u)}=\sum_{i}^{}x_{cat}^{(u)},i\in {card,trans,mchnt} xcat(u)=∑ixcat(u),i∈card,trans,mchnt。
为了解决离散属性的异构性,提出特征学习层对所有离散属性进行建模,并将它们投影到统一的空间维度上。
3.门控时序注意力网络(Gated Temporal Attention Networks)
在时序交易图(temporal transaction graph)上通过时序图注意力机制(Temporal Graph Attention)聚合信息以更新每个交易的嵌入,有向时间边是以先前交易为源、当前交易为目标生成的,每个节点生成的时序边的数量是一个超参数。
(1)时序图注意力(Temporal Graph Attention)机制
输入:将离散属性和数值属性结合为GTAN网络的输入,利用一系列交易嵌入 X = x t 0 , x t 1 , . . . , x t n , x t i = x n u m t i + x c a t t i X={x_{t_0},x_{t_1},...,x_{t_n}},x_{t_i}=x_{num}^{t_i}+x_{cat}^{t_i} X=xt0,xt1,...,xtn,xti=xnumti+xcatti来学习每个交易记录的时序嵌入,将 H 0 = X H_0=X H0=X作为第一个TGAT层的输入嵌入矩阵;
多头注意力(multi-head attention): H e a d Head Head计算邻居重要性;
聚合:多头输出拼接后线性变换 H = C o n c a t ( H e a d 1 , . . . , H e a d h a t t r ) W 0 H=Concat(Head_1,...,Head_{h_{attr}})W_0 H=Concat(Head1,...,Headhattr)W0,输出 H = h t 0 , h t 1 , . . . , h t n H={h_{t_0},h_{t_1},...,h_{t_n}} H=ht0,ht1,...,htn。
(2)属性驱动的门控残差(Attribute-driven Gated Residual)
获得聚合嵌入后,利用聚合嵌入和原始属性来推断TGAT每层后聚合嵌入和原始属性的重要性 z t i = g a t e t i ⋅ h t i + ( 1 − g a t e t i ) ⋅ x t i z_{t_i}=gate_{t_i}\cdot h_{t_i}+(1-gate_{t_i})\cdot x_{t_i} zti=gateti⋅hti+(1−gateti)⋅xti, g a t e t i ∈ [ 0 , 1 ] gate_{t_i}\in [0,1] gateti∈[0,1]表示第 t i t_i ti次交易的门控变量, z t i z_{t_i} zti表示每个TGAT层的输出变量,被投喂到下一层作为输入。
4.风险嵌入和传播(Risk Embedding and Propagation)
受标签传播与特征传播统一的启发,作者提出将人工标注的标签作为交易的离散属性之一,并得到该离散属性的嵌入,称之为风险嵌入(risk embedding)。具体来说,将人工标注的标签作为每笔交易的风险特征,其中未标注数据的类别为“unlabeled”,其余数据的类别为“fraud”或“legitimate”。然后,将该特征添加到交易数据中,作为输入离散属性之一。由于担心标签泄露的问题,此属性尚未在以前的欺诈检测方法中使用。
作者提倡将部分观察到的风险属性嵌入到与其他节点特征相同的空间中,这些特征由标记节点的风险嵌入向量和未标记节点的零嵌入向量组成。然后,将节点特征和风险嵌入相加作为输入节点特征:
x t i = x n u m ( t i ) + x c a t ( t i ) + y ∼ ( t 1 ) W r x_{t_i}=x_{num}^{(t_i)}+x_{cat}^{(t_i)}+\overset{\thicksim}{y}^{(t_1)}W_r xti=xnum(ti)+xcat(ti)+y∼(t1)Wr
已有研究证明,通过将部分标签 Y ^ \hat Y Y^和节点特征 X X X映射到同一空间中并将它们相加,可以同时实现图神经网络中的属性传播和标签传播。
5.欺诈风险预测(Fraud Risk Prediction)
利用两层MLP基于聚合嵌入预测欺诈概率:
y
^
=
σ
(
P
R
e
L
U
(
H
W
0
+
b
0
)
W
1
+
b
1
)
\hat y = \sigma(PReLU(HW_0+b_0)W_1+b_1)
y^=σ(PReLU(HW0+b0)W1+b1)
采用二元交叉熵损失函数,并使用随机梯度下降算法SGD进行优化。
6.掩码避免标签泄露(Masking to Avoid Label Leakage)
以往的研究只是将风险信息作为优化目标来监督欺诈检测模型的训练。与之前的信用卡欺诈检测解决方案不同,我们通过在已标记和未标记的交易中传播交易属性和风险嵌入来半监督我们的模型。在GTAN使用未掩蔽的目标将导致训练过程中的标签泄露。
在训练时,随机采样中心节点并掩码其风险嵌入(设为0),仅用邻居信息预测。具体来说,将部分观察到的标签
Y
^
\hat Y
Y^转换为
Y
∼
\overset{\thicksim}{Y}
Y∼。之后,我们的目标函数是用给定的
X
,
Y
∼
,
A
X,\overset{\thicksim}{Y},A
X,Y∼,A来预测
Y
^
\hat Y
Y^。
SCN_GNN
文章名称:SCN_GNN: A GNN-based fraud detection algorithm combining strong node and graph topology information
标签:ESWA_C类_2024
RIOGNN工作的延续
一、问题
(1)欺诈检测分类
欺诈检测可以被广泛地分类为社交网络中的欺诈检测、金融领域中的欺诈检测以及其他形式的欺诈检测。社交网络中的欺诈检测包括意见审查欺诈检测(opinion censorship fraud detection)、谣言检测(rumor detection)和虚假账户检测(fake account detection)。金融领域中的欺诈检测包括交易欺诈检测(transaction fraud detection)、恶意账户检测(malicious account detection)等等。其他形式的欺诈检测包括电子商务欺诈检测(e-commerce fraud detection)、虚假点击欺诈检测(false click fraud detection)和搜索排名欺诈检测(search ranking fraud detection)。
(2)欺诈检测难点
- 在真实的数据集中存在较少的欺诈用户和大量的良性用户,节点间受限的互连性导致了信息数据的稀缺性,这会导致损失函数在梯度下降过程中很容易被大多数良性用户所支配,而未被检测到的欺诈用户将导致错误的梯度下降方向,从而稀释欺诈者特征并污染决策边界;
- 大多数基于过滤机制的检测算法在检测期间从而容易受到原始信息的影响;
- 现有的单关系算法往往难以识别欺诈节点在多关系图中的欺诈行为,从而限制了它们的整体检测性能。
(3)现有GNN模型的局限
- 经典的基于GNN的算法,如GCN、GAT、GraphSAGE和GIN,在同构图(homogeneous graphs)上执行的检测算法不适用于多关系异构图(multi-relationship heterogeneous graphs)上的欺诈检测任务,这是因为它们在处理实际图中的边和节点之间的复杂性和多样性方面存在局限性。
- CARE-GNN算法考虑到不同关系的重要性来聚合邻居信息,PC_GNN、RLC-GNN、Rio_GNN等算法进一步改进了CARE-GNN算法。然而,除了RLC-GNN外,其他算法都存在如下局限性:每个节点仅能聚合一次邻居信息,不能处理多个节点类型;所有这些算法都是基于过滤机制的欺诈检测算法,在过滤它们的邻居时很容易被原始特征误导。
- AO-GNN算法通过关注AUC最大化的损失函数解决了GNN中的标签不平衡问题。虽然它在提高性能方面很有效,但可能需要额外的计算,并且可能无法很好地推广到不同的数据集。
- DA_GNN算法设计了一个由差异性增强(disparity augment,DA)路径和相似性增强(similarity augment,SA)路径组成的双路径欺诈检测框架,在两个真实数据集上取得了良好的效果,但模型中复杂的异构信息聚合和图视差卷积导致其可解释性较差。
- HAGNN提出了一种通过合并多个关系的加权邻接矩阵来度量两个节点之间的连接强度的方法,用于通过两种注意力机制进行欺诈检测。然而,HAGNN算法融合了三种注意力机制,算法的速度受到限制。HAGNN算法和AO-GNN算法的成功验证了通过参数和拓扑结构综合优化的优越性。
二、贡献
提出了一种新的基于GNN的欺诈检测算法,命名为SCN_GNN:
- 创造性地提出了结构相似性感知模块(structural similarity-aware module,SSAM),该模块执行上采样以有效地处理不平衡数据集并实现更好的训练输出;
- 提出了一种强节点模块(strong node module,SNM),它包含了额外的信息,并采用欠采样策略来减轻噪声的影响;
- 在RioGNN中的RSRL强化学习模块的基础上,修改了强化学习中的状态函数,最大化欺诈节点和正常节点之间的区分度,最小化类内差距,并净化决策边界以获得更好的算法性能。
三、方法
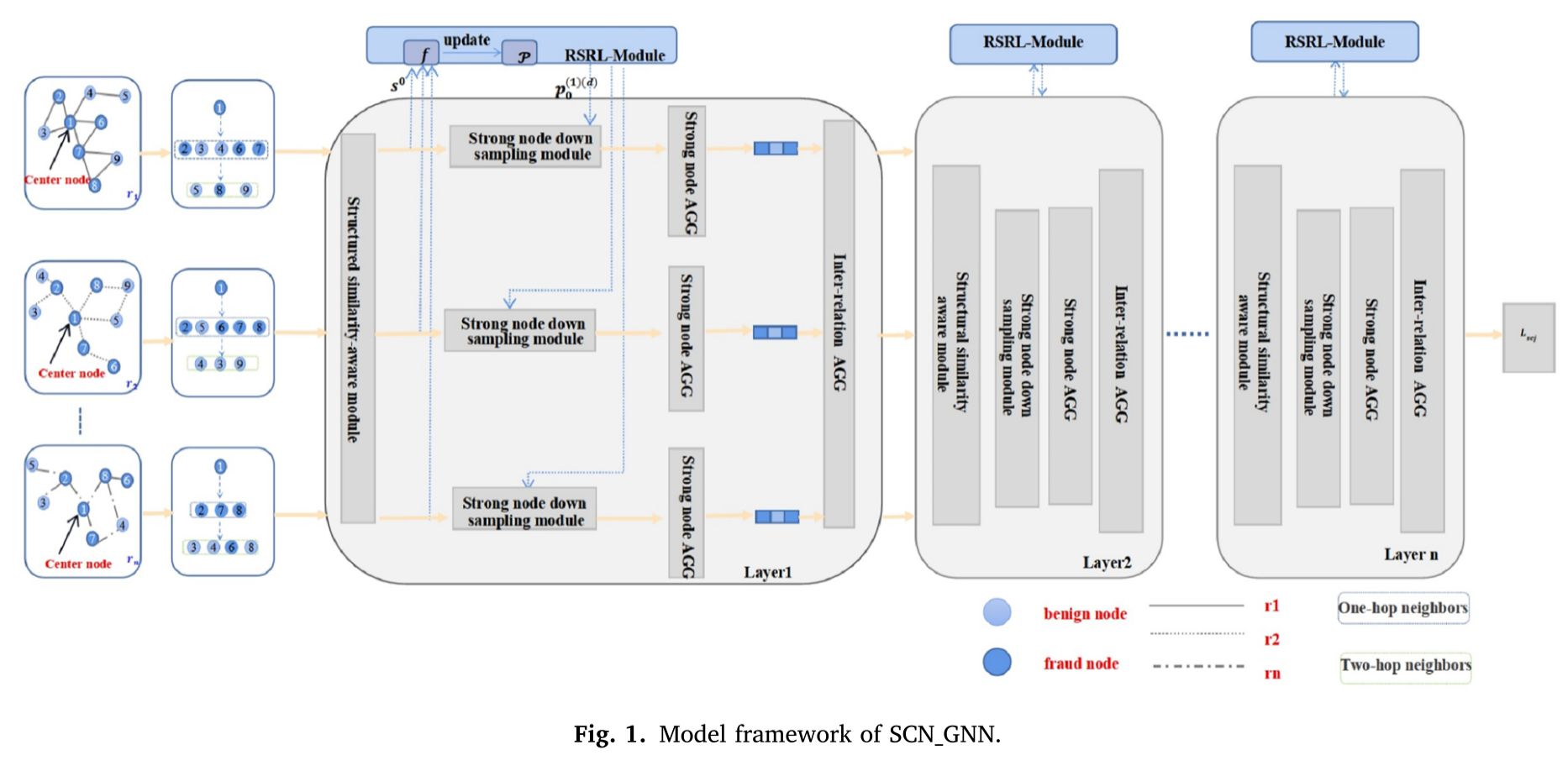
(1)overview
对于异构图中的每一个节点,其属性可以由其原始特征,以及其相邻节点的特征和其多重关系的语义信息共同确定。因此,在判断中心节点的属性类别时,主要受两个因素的影响:中心节点本身的原始特征和多关系下相邻节点的可靠性。为了避免欺诈检测过程受到中心节点的原始特征的过度影响,算法主要关注于通过引入关于强节点的附加信息以及未连接的两跳邻居与中心邻居之间的Jaccard相似性来提高拓扑级别。
SCN_GNN模型建立在RioGNN算法的框架之上,包括三个主要组件:结构相似性感知模块(structural similarity-aware module)、强节点模块(strong node module)和关系内聚合模块(intra-relational aggregation module)。同时,在该框架中,RSRL模块得到了细化,并保留了关系间聚合模块(inter-relational aggregation module)。结构相似性感知模块将核心节点周围的未连接但重要的节点添加到邻接矩阵中,而强节点模块选择与中心节点更相似的相邻节点。最后,通过增加类间距离和减少类内距离来解决数据集不平衡的问题。
(2)结构相似性感知模块(structured similarity-aware module,SSAM)
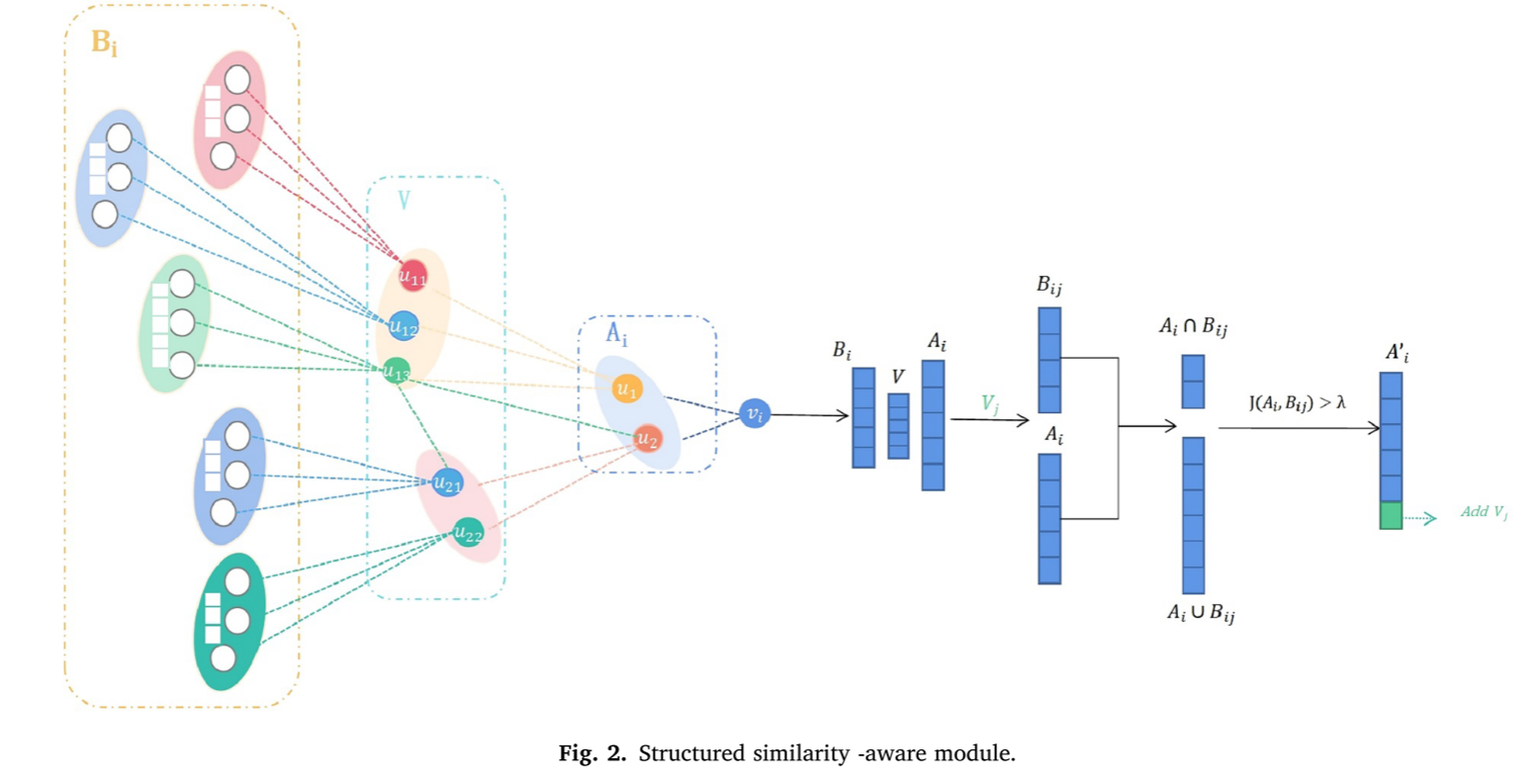
首先,计算中心节点
v
i
v_i
vi的第一跳邻居节点集
A
i
A_i
Ai和第二跳邻居节点集
V
i
V_i
Vi;
其次,计算每个第二跳邻居节点
v
i
,
j
v_{i,j}
vi,j的第一跳邻居节点集
B
i
,
j
B_{i,j}
Bi,j;
然后,计算集合
A
i
A_i
Ai和集合
B
i
,
j
B_{i,j}
Bi,j之间的Jaccard相似度,以确定中心节点
v
i
v_i
vi及其第二跳邻居
v
j
v_j
vj的相关性:
J
(
A
i
,
B
i
,
j
)
=
∣
A
i
∩
B
i
,
j
∣
∣
A
i
∪
B
i
,
j
∣
=
∣
A
i
∩
B
i
,
j
∣
∣
A
i
∣
+
∣
B
i
,
j
∣
−
∣
A
i
∩
B
i
,
j
∣
J(A_i,B_{i,j})=\frac{|A_i\cap B_{i,j}|}{|A_i\cup B_{i,j}|}=\frac{|A_i\cap B_{i,j}|}{|A_i| + |B_{i,j}| - |A_i\cap B_{i,j}|}
J(Ai,Bi,j)=∣Ai∪Bi,j∣∣Ai∩Bi,j∣=∣Ai∣+∣Bi,j∣−∣Ai∩Bi,j∣∣Ai∩Bi,j∣
Jaccard相似性位于区间[0,1],越接近1,两个集合越相似。
最后,设置超参数
λ
\lambda
λ,当
J
(
A
i
,
B
i
,
j
)
>
λ
J(A_i,B_{i,j})>\lambda
J(Ai,Bi,j)>λ时,将边
e
i
,
j
e_{i,j}
ei,j设置为1。然后将得到的节点放入邻居集合中,并将该邻居节点的得分设为
s
c
o
r
e
score
score。其中,
s
c
o
r
e
score
score是节点的原始特征。
通过该模块,我们可以选择一些在拓扑结构上与中心节点紧密相连的两跳邻居,并设置参数来加权该模块勾选的邻居节点的原始特征。接下来,我们将这些邻居节点与中心节点的一跳邻居节点进行结合,并一起发送到强节点模块进行进一步过滤,最终选出与中心节点在拓扑结构和原始特征上相似的邻居节点。
(3)强节点模块(strong node module,SNM)
在该模块中,从跨越多个关系的邻接矩阵中提取强节点信息,并使用它来度量中心节点与其相邻节点之间的相似性。以这种方式,我们可以随后通过强节点下采样过程选择与中心节点表现出更大相似性和相关性的邻居子集。该操作有效地选择了由欺诈者邻居引入的噪声,增强了检测算法的整体性能。该模块由数据集预处理模块(dataset pre-processing module)、**强节点欠采样模块(strong node under-sampling module)和强节点嵌入聚合模块(strong node embedding aggregation module)**组成。
1)数据集预处理模块
该模块旨在对数据进行预处理,提取各种强节点信息,提高训练速度。如果在由邻接矩阵构造的图中存在
n
n
n个关系,则该模块可以将所有节点划分为
C
n
2
C_n^2
Cn2种类型。
以amazon数据集为例,单个关系下的邻居节点可以分为三种邻居节点:three strong nodes(通过所有三个关系连接的节点)、two strong nodes(通过两个关系连接的节点)和ordinary nodes。
2)强节点欠采样模块
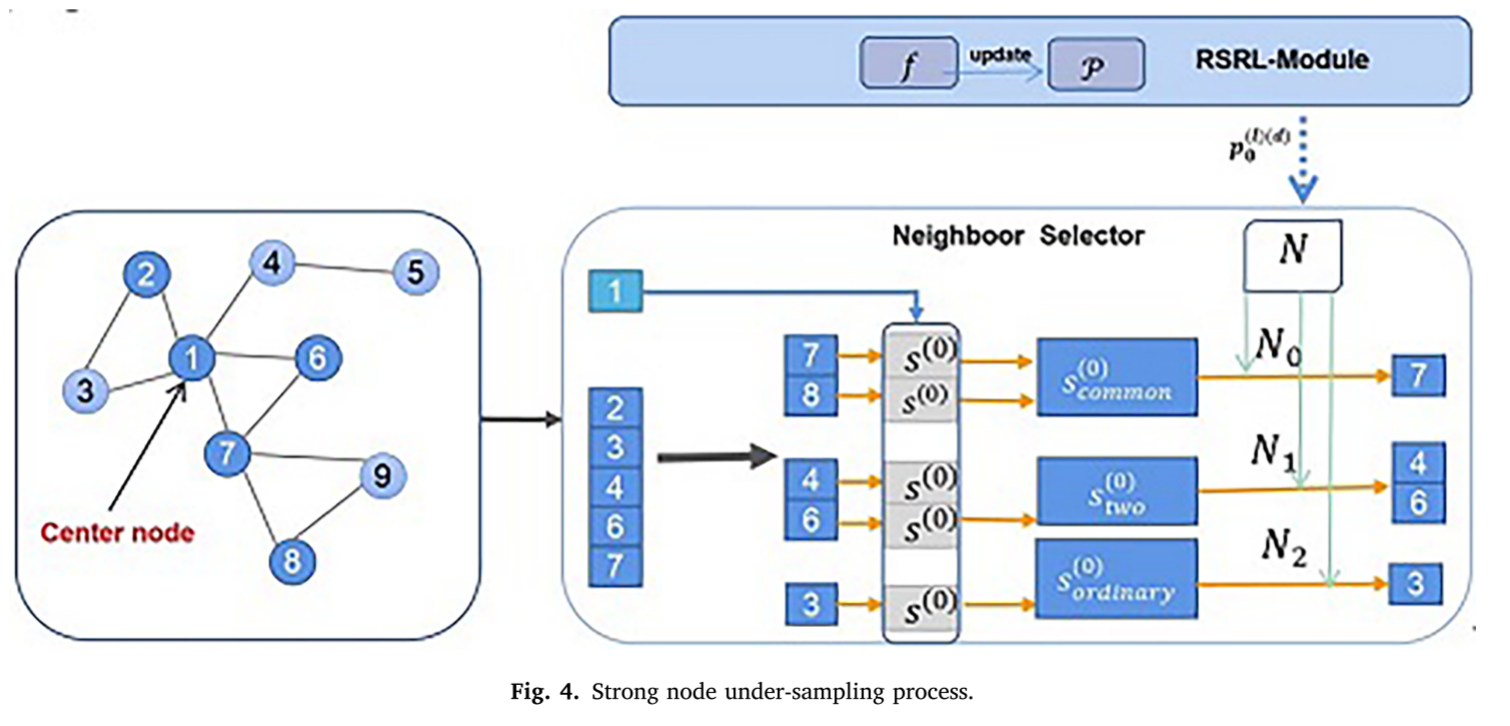
该模块在参考原有Top-K采样操作的基础上,通过添加多关系邻接矩阵中的强节点信息进行下采样操作。我们选择离中心节点较近的邻居节点,使用
L
1
L1
L1距离衡量中心节点与邻居的相似性:
D
(
l
)
(
v
,
v
′
)
=
∣
∣
t
a
n
h
(
F
C
N
(
h
v
(
l
−
1
)
)
)
−
t
a
n
h
(
F
C
N
(
h
v
′
(
l
−
1
)
)
)
∣
∣
1
D^{(l)}(v,v')=||tanh(FCN(h_v^{(l-1)}))-tanh(FCN(h_{v'}^{(l-1)}))||_1
D(l)(v,v′)=∣∣tanh(FCN(hv(l−1)))−tanh(FCN(hv′(l−1)))∣∣1
按类别加权采样,保留高相似邻居:
N
i
,
c
=
p
r
l
⋅
N
r
l
d
ˉ
c
∑
c
=
1
C
1
d
ˉ
c
N_{i,c}=\frac{p_r^l\cdot N_r^l}{\bar d_c \sum_{c=1}^{C}\frac{1}{\bar d_c}}
Ni,c=dˉc∑c=1Cdˉc1prl⋅Nrl
随后,我们按照单个关系中不同类型节点的平均
L
1
L1
L1距离
d
ˉ
c
\bar d_c
dˉc的顺序选择
N
i
,
c
N_{i,c}
Ni,c个邻居节点。最后,完成下采样过程,并对节点及其得分进行融合。
3)强节点嵌入聚合模块
该模块自适应学习参数,通过关系内聚合来确定最终的节点嵌入。我们设置可学习参数
W
=
[
w
1
,
w
2
,
.
.
.
,
w
c
]
W=[w_1,w_2,...,w_c]
W=[w1,w2,...,wc]来聚合第
l
l
l层中的关系
r
r
r下的各种类型的节点的信息。对于中心节点
v
v
v,在第
l
l
l层中的关系
r
r
r下,强节点嵌入聚合可以定义为如下:
h
v
,
r
(
l
)
=
R
e
l
u
(
A
G
G
r
(
l
)
(
w
c
∗
{
h
v
′
,
r
c
(
l
−
1
)
:
v
′
∈
N
r
,
c
(
l
)
}
∣
c
=
1
C
)
)
h_{v,r}^{(l)}=Relu(AGG_r^{(l)}(w_c^*\{h_{v',r_c}^{(l-1)}:v'\in N_{r,c}^{(l)}\}|_{c=1}^C))
hv,r(l)=Relu(AGGr(l)(wc∗{hv′,rc(l−1):v′∈Nr,c(l)}∣c=1C))
最后,通过关系间聚合函数将中心节点的原始特征与强节点关系内聚合模块的输出嵌入进行聚合:
h
v
,
r
(
l
)
=
R
e
l
u
(
A
G
G
r
(
l
)
(
h
v
(
l
−
1
)
⊕
p
r
l
∗
h
v
,
r
(
l
)
∣
r
=
1
R
)
)
h_{v,r}^{(l)}=Relu(AGG_r^{(l)}(h_v^{(l-1)}\oplus {p_r^l*h_{v,r}^{(l)}}|_{r=1}^R))
hv,r(l)=Relu(AGGr(l)(hv(l−1)⊕prl∗hv,r(l)∣r=1R))
其中,
p
r
l
p_r^l
prl是通过强化学习模块RSL学习到的过滤阈值。
(4)重构强化学习模块(RSRL)
旨在优化决策边界,解决类别不平衡。
状态函数结合了类间距离最大化和类内距离最小化:
s
r
(
l
)
(
d
)
(
e
)
=
w
1
⋅
s
r
,
1
(
l
)
(
d
)
(
e
)
+
w
2
⋅
s
r
,
2
(
l
)
(
d
)
(
e
)
s_r^{(l)(d)(e)}=w_1\cdot s_{r,1}^{(l)(d)(e)}+w_2\cdot s_{r,2}^{(l)(d)(e)}
sr(l)(d)(e)=w1⋅sr,1(l)(d)(e)+w2⋅sr,2(l)(d)(e)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











