






目录
Hive
数据仓库基本概念
数据仓库(Data Warehouse)是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境,是OLAP的一种实现
这种面向分析、支持分析的系统称之为OLAP(联机分析处理)系统
有关OLAP和OLTP:OLAP、OLTP的介绍和比较_Darcy_zz的博客-优快云博客
数仓的主要特征
- 面向主题性:主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象;传统OLTP系统对数据的划分并不适用于决策分析。而基于主题组织的数据则不同,它们被划分为各自独立的领域,每个领域有各自的逻辑内涵但互不交叉,在抽象层次上对数据进行完整、一致和准确的描述
- 集成性:主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构;因此在数据进入数据仓库之前,必然要经过统一与综合,对数据进行抽取、清理、转换和汇总,这一步是数据仓库建设中最关键、最复杂的一步
- 非易失性、非异变性:数据仓库是分析数据的平台,而不是创造数据的平台。我们是通过数仓去分析数据中的规律,而不是去创造修改其中的规律。因此数据进入数据仓库后,它便稳定且不会改变;数据仓库的数据反映的是一段相当长的时间内历史数据的内容,数据仓库的用户对数据的操作大多是数据查询或比较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留
-
- 数据仓库中一般有大量的查询操作,但修改和删除操作很少
- 时变性:数据仓库的数据需要随着时间更新,以适应决策的需要
结构化数据
结构化数据:也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理;
非结构化数据:不适于由数据库二维表来表现,包括所有格式的办公文档、XML、HTML、各类报表、图片和音频、视频信息等
Hive基础知识
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行
hive和hadoop的关系
对于数据仓库软件来说,核心能力在于存储数据和分析数据,而Hive利用HDFS存储数据,利用MapReduce查询分析数据
数据文件到表的映射
Hive能将数据文件映射成为一张表,这种映射指的是文件和表之间的对应关系
映射信息也被称为元数据(metadata)信息;要把文件映射成表,需要记录的信息有:
- 表对应着哪个文件(位置信息)
- 表的列对应着文件哪一个字段(顺序信息)
- 文件字段之间的分隔符是什么
所以,Hive对数据的查询分析,就是在用户写完sql之后,hive根据记录的元数据信息分析sql的含义,据此制定执行计划,并将执行计划转化为MapReduce来执行;hive承担的职责就是将SQL语法编译成MapReduce程序
Hive整体架构
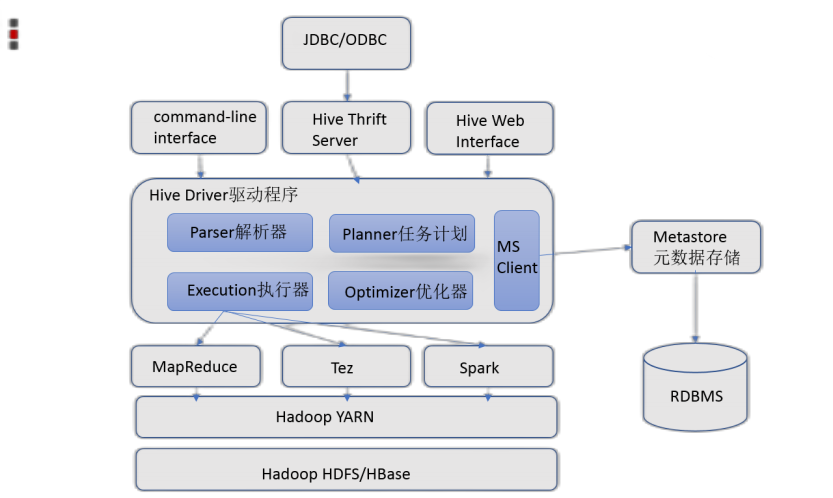
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive
- 元数据存储:通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
- Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行
- 执行引擎:Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎
Hive部署安装
元数据
元数据(Metadata),又称中介数据、中继数据,是描述数据的数据‘
主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能
Hive Metedata: Hive的元数据,包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息;元数据存储在关系型数据库中
Hive Metastore的配置
Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据
有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全
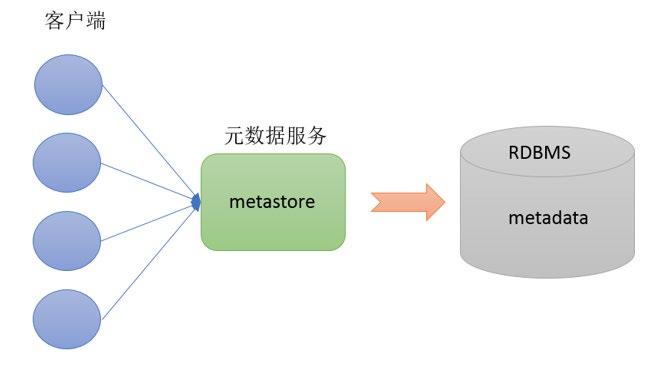
metestore就相当于是为客户端提供了操作元数据的接口;
采用远程模式配置metestore(其余配置模式还有内嵌模式和本地模式):
在远程模式下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性
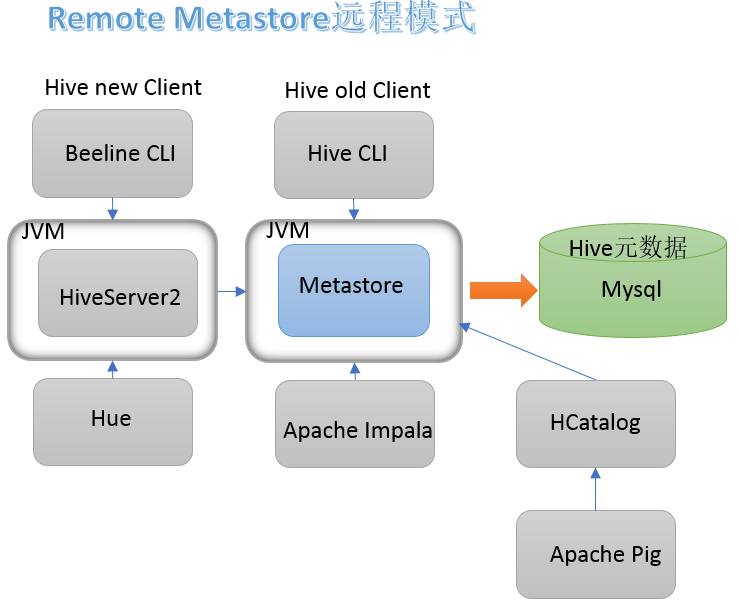
具体部署流程
1.安装好hadoop集群并在其中一台机器上安装好MySQL
2.配置代理权限:
在hadoop的core-site文件中添加(详见hadoop集群的配置):
<!--配置该superUser允许通过代理访问的主机节点-->
<property>
<name>hadoop.proxyuser.why.hosts</name>
<value>*</value>
</property>
<!--配置该superUser允许通过代理访问的用户组-->
<property>
<name>hadoop.proxyuser.why.groups</name>
<value>*</value>
</property>
<!--配置该superUser允许代理的用户-->
<property>
<name>hadoop.proxyuser.why.users</name>
<value>*</value>
</property>
原因:Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据,因此需要在Hadoop中添加相关配置属性,以满足Hive在Hadoop上运行;而由于hadoop的用户、用户组使用的是linux操作系统的用户、用户组,所以我们通过设置用户why允许代理其他所有的用户,访问所有的主机节点,各客户端操通过hive对hadoop进行操作就有权限了
3.上传解压hive安装包;格式如下:
tar zxvf apache-hive-3.1.2-bin.tar.gz
4.解决hive和hadoop中的guava版本差异:
①删除hive安装路径下lib/中guava的jar包
②找到hadoop安装路径下/share/hadoop/common/lib/中guava的jar包,将其复制到①中的hive路径
5.跳转到/conf路径下,配置hive-env.sh(环境变量):
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export HIVE_CONF_DIR=/opt/module/apache-hive-3.1.2-bin/conf
export HIVE_AUX_JARS_PATH=/opt/module/apache-hive-3.1.2-bin/lib
6.跳转到/conf路径下,新增hive-site.xml:
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 远程模式部署metastore metastore地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
</configuration>
需要注意的地方:
1.配置元数据数据库的时候,jdbc.url要写齐全,要不可能会报各种各样的错:
①useSSL的设置:MySQL在高版本需要指明是否进行SSL连接,而不建议在没有服务器身份验证的情况下建立SSL连接,所以为了避免出错,我们选择禁用SSL
参考:关于数据库连接中useSSL是否为true 或者 false的选择_useunicode=trueusessl_教练我写不出来的博客-优快云博客
2.有关spark的配置是使用了hive on spark,用MapReduce的话就删除这两条配置就行
7.添加驱动、初始化:
①上传MySQL JDBC驱动到Hive安装包lib路径下 mysql-connector-java-5.1.32.jar
②在hive安装路径下:bin/schematool -initSchema -dbType mysql -verbos,初始化hive的元数据,初始化成功后会在mysql中创建74张表
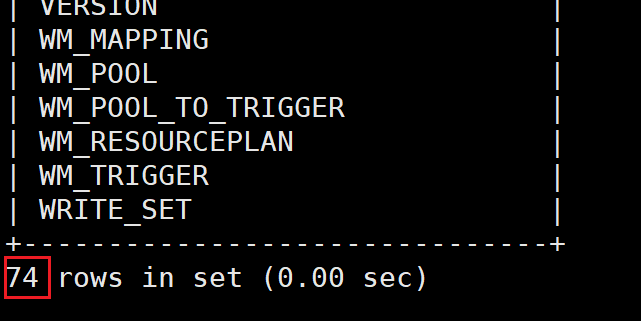
能查询到表数据,说明hive的元数据初始化成功;
8.metestore启动:
①前台启动:/opt/module/apache-hive-3.1.2-bin/bin/hive --service metastore
开启debug日志,获取详细信息:/opt/module/hive/bin/hive --service metastore -hiveconf hive.root.logger=DEBUG,console
②后台启动:nohup /opt/module/apache-hive-3.1.2-bin/bin/hive --service metastore &
nohup /opt/module/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
nohup 命令,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下
Hive客户端
第一代客户端:$HIVE_HOME/bin/hive,是一个 shellUtil,用于Hive相关服务的启动,比如metastore服务
第二代客户端:$HIVE_HOME/bin/beeline,是一个JDBC客户端,与第一代客户端相比,性能加强安全性提高
推荐使用第二代客户端
HiveServer2服务
远程模式下beeline通过 Thrift 连接到单独的HiveServer2服务上,HiveServer2支持多客户端的并发和身份认证,旨在为开放API客户端如JDBC、ODBC提供更好的支持;
而HiveServer2通过Metastore服务读写元数据。所以在远程模式下,启动HiveServer2之前必须先首先启动
metastore服务
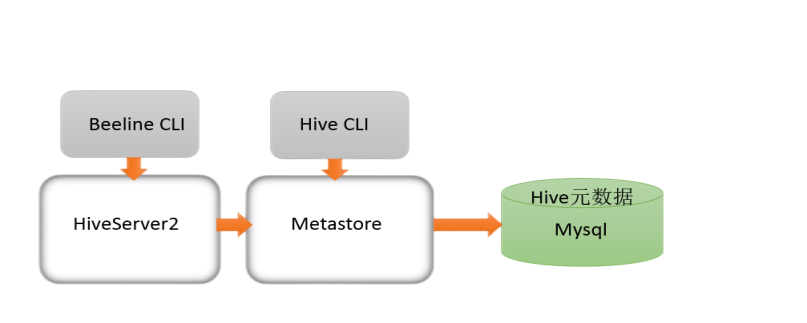
远程模式下,Beeline客户端只能通过HiveServer2服务访问Hive。而bin/hive是通过Metastore服务访问的
bin/beeline客户端使用
启动metastore服务:nohup /opt/module/apache-hive-3.1.2-bin/bin/hive --service metastore &
启动hiveserver2服务:nohup /opt/module/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
连接beeline客户端:
①方式1:/opt/module/apache-hive-3.1.2-bin/bin/beeline -u jdbc:hive2://hadoop102:10000 -n why
jdbc:hive2://hadoop102:10000中hadoop102是在hive-site中设置的“H2S运行绑定的host”
-n why中“why”是用户名
②方式2:首先启动beeline:/opt/module/apache-hive-3.1.2-bin/bin/beeline
输入! connect jdbc:hive2://hadoop102:10000
然后输入用户名,回车;输入密码(为空即可),回车;
Hive SQL语句
DDL
DDL核心语法由CREATE、ALTER与DROP三个所组成;DDL不涉及表内部数据的操作
1.创建数据库:create database
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
- COMMENT:数据库的注释说明语句
- LOCATION:指定数据库在HDFS存储位置,默认
/user/hive/warehouse/dbname.db
-
- 使用location指定路径的时候,最好指向的是一个新创建的空文件夹
- WITH DBPROPERTIES:用于指定一些数据库的属性配置
2.选择特定的数据库:use database,切换当前会话使用哪一个数据库进行操作
3.删除数据库:drop database
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
- 默认删除行为是RESTRICT,这样我们无法删除不为空(已经创建过表)的数据库;如果要删除不为空的数据库,需要制定删除行为为
CASCADE
建表语句
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name
(col_name data_type [COMMENT col_comment], ... )
[COMMENT table_comment]
[ROW FORMAT DELIMITED …]
- 数据类型:
-
- 原始类型:INT,STRING,DATE,TIMESTAMP
- 复杂类型:ARRAY,MAP(key-value,key必须为原始类型,value可以任意类型)
- 分隔符:
ROW FORMAT DELIMITED
-
- 字段之间分隔符:
FIELD TERMINATED BY char(最常用) - 集合元素之间分隔符:
COLLECTION ITEMS TERMINATED BY char - map映射kv之间分隔符:
MAP KEYS TERMINATED BY char - 行数据之间分隔符:
LINES TERMINATED BY char - 默认的分割符是 '\001' ,是一种特殊的字符,使用的是ASCII编码的值(在一些文本编辑器中显示为
SOH(由于使用默认的分隔符不用通过ROW FORMAT DELIMITED指定,所以在数据采集、清洗的时候可以优先考虑使用默认的分隔符)
- 字段之间分隔符:
- 表文件存储路径:
-
- 默认存储在
/user/hive/warehouse/db_name.db/路径下 - 文件夹的父路径由参数
hive.metastore.warehouse.dir设置
- 默认存储在
其他与表相关的常用操作:
显示表结构:desc table_name;
显示表定义的详细信息:desc formatted table_name;
显示建表语句:show create table table_name
DML
load加载数据
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename;
LOCAL:在本地文件系统中查找文件路径
-
- 使用
LOCAL关键字的情况下:从本次文件系统中加载数据,本地文件系统指的是HS2服务所在的机器的本地Linux文件系统; - 没有使用
LOCAL关键字的情况下:如果filepath指向的是一个完整的URI,会直接使用这个URI;如果没有指定schema,Hive会使用在hadoop配置文件中参数fs.default.name指定的;然后从HDFS加载数据,数据位于HDFS文件系统根目录下(相当于先将数据文件通过hadoop fs -put上传到了HDFS文件系统中)
- 使用
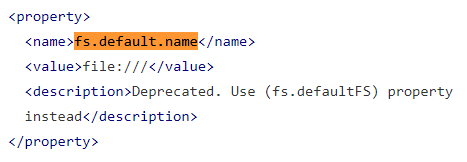
注意:fs.default.name已经不使用了,通过fs.defaultFS来配置默认文件系统的路径:
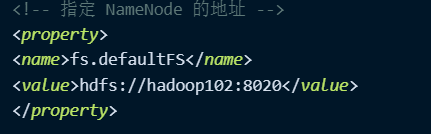
示例:LOAD DATA INPATH '/students.txt' INTO TABLE table;
数据文件的路径就是:hdfs://hadoop102:8020/student.txt;
insert插入数据
向表中加载数据通常都用load而不用insert,所以insert最常用的配合是把查询返回的结果插入到另一张表中:
INSERT INTO TABLE tablename select_statement1 FROM from_statement;
- 需要保证查询结果列的数目和需要插入数据表格的列数目一致
- 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL
select查询数据
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[LIMIT [offset,] rows];
操作与mysql基本一样:MySQL操作语句总结 - 掘金
- limit:第一个参数指定要返回的第一行的偏移量(从 Hive 2.0.0开始),第二个参数指定要返回的最大行数。当给出单个参数时,它代表最大行数,并且偏移量默认为0
示例:limit(2,3):从第1行开始,返回3行数据
Hive常用函数
显示hive中所有的内置函数:show functions;
查看函数的使用方式:describe function extended funcname;
内置函数
包括:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等
1.String Functions 字符串函数:
•字符串长度函数:length
•字符串反转函数:reverse
•字符串连接函数:concat
•带分隔符字符串连接函数:concat_ws:concat_ws(separator, [string | array(string)]+)
•字符串截取函数:substr,substring:substr(str, pos[, len]) 或者 substring(str, pos[, len])
2.Date Functions 日期函数:
--获取当前日期: current_date 格式:"2023-04-13"
select current_date();
--获取当前UNIX时间戳函数: unix_timestamp 格式:'1681367768'
select unix_timestamp();
--日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp("2011-12-07 13:01:03");
--指定格式日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');
--UNIX时间戳转日期函数: from_unixtime
select from_unixtime(1618238391);
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');
--日期比较函数: datediff 日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'
select datediff('2012-12-08','2012-05-09');
--日期增加函数: date_add
select date_add('2012-02-28',10);
--日期减少函数: date_sub
select date_sub('2012-01-1',10);
3.Mathematical Functions 数学函数
--取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
--指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926,4);
--取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);
4.Conditional Functions 条件函数
--if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1=2,100,200);
select if(sex ='男','M','W') from student limit 3;
--空值转换函数: nvl(T value, T default_value)
select nvl("allen","itcast");
select nvl(null,"itcast");
--条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when '男' then 'male' else 'female' end from student limit 3;
用户定义函数
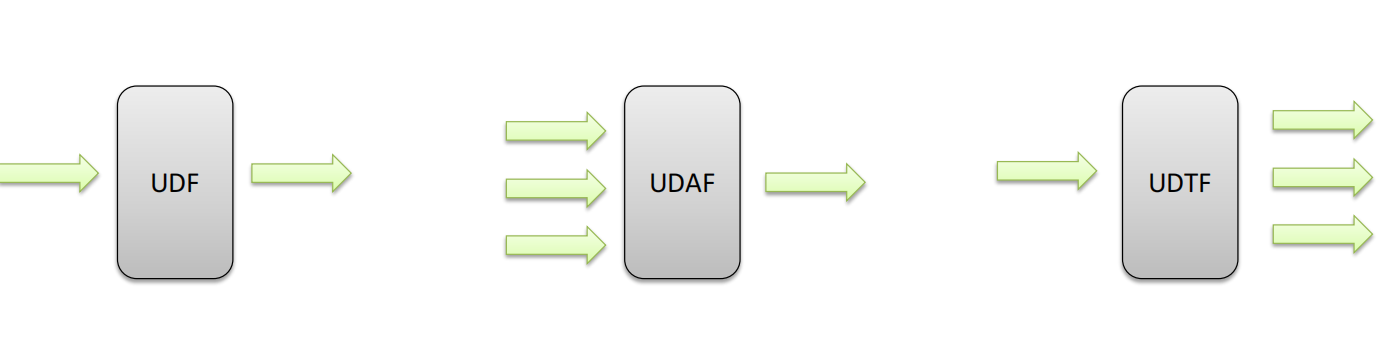
UDF(User-Defined-Function)普通函数,一进一出
UDAF(User-Defined Aggregation Function)聚合函数,多进一出
UDTF(User-Defined Table-Generating Functions)表生成函数,一进多出


















 5340
5340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











