




 本文介绍了MySQL数据库性能分析的关键工具和方法,包括使用SHOWSTATUS和SHOWPROFILE来监控系统状态和查询成本,通过开启慢查询日志来定位慢查询,理解EXPLAIN输出的执行计划,分析查询类型(type)、索引使用(key)和成本(key_len)等关键信息,以及使用optimizer_trace进行深入的查询优化分析。这些工具和概念对于优化SQL查询和提升数据库性能至关重要。
本文介绍了MySQL数据库性能分析的关键工具和方法,包括使用SHOWSTATUS和SHOWPROFILE来监控系统状态和查询成本,通过开启慢查询日志来定位慢查询,理解EXPLAIN输出的执行计划,分析查询类型(type)、索引使用(key)和成本(key_len)等关键信息,以及使用optimizer_trace进行深入的查询优化分析。这些工具和概念对于优化SQL查询和提升数据库性能至关重要。
第09章_性能分析工具的使用
在数据库调优中,我们的目标是 响应时间更快, 吞吐量更大 。利用宏观的监控工具和微观的日志分析可以帮我们快速找到调优的思路和方式。
1. 数据库服务器的优化步骤
当我们遇到数据库调优问题的时候,该如何思考呢?这里把思考的流程整理成下面这张图。
整个流程划分成了 观察(Show status) 和 行动(Action) 两个部分。字母 S 的部分代表观察(会使 用相应的分析工具),字母 A 代表的部分是行动(对应分析可以采取的行动)。
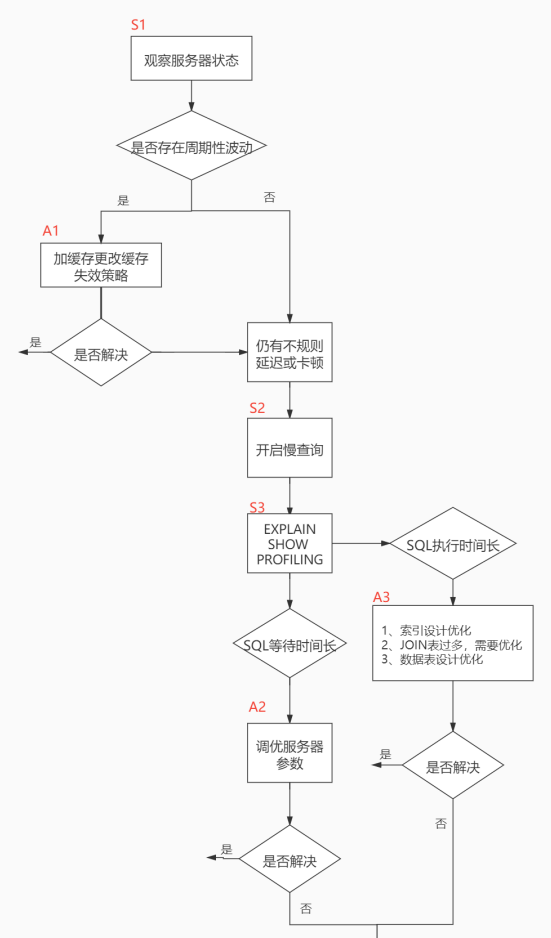
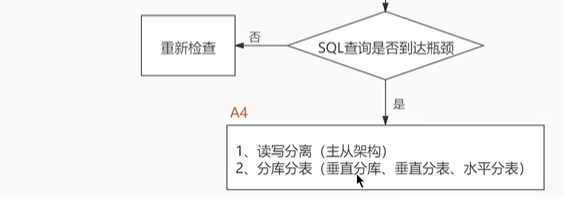
我们可以通过观察了解数据库整体的运行状态,通过性能分析工具可以让我们了解执行慢的SQL都有哪些,查看具体的SQL执行计划,甚至是SQL执行中的每一步的成本代价,这样才能定位问题所在,找到了问题,再采取相应的行动。
详细解释一下这张图:

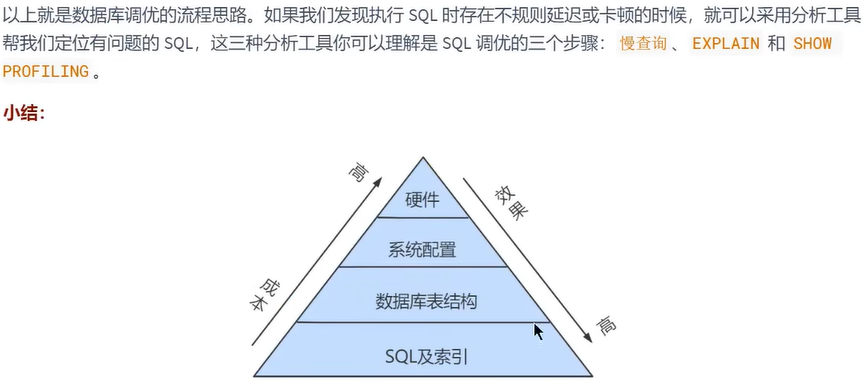
2. 查看系统性能参数
在MySQL中,可以使用 SHOW STATUS 语句查询一些MySQL数据库服务器的性能参数、执行频率。
SHOW STATUS语句语法如下:
SHOW [GLOBAL|SESSION] STATUS LIKE '参数';
一些常用的性能参数如下:
- Connections:连接MySQL服务器的次数。
- Uptime:MySQL服务器的上线时间。
- Slow_queries:慢查询的次数。
- Innodb_rows_read:Select查询返回的行数
- Innodb_rows_inserted:执行INSERT操作插入的行数
- Innodb_rows_updated:执行UPDATE操作更新的 行数
- Innodb_rows_deleted:执行DELETE操作删除的行数
- Com_select:查询操作的次数。
- Com_insert:插入操作的次数。对于批量插入的 INSERT 操作,只累加一次。
- Com_update:更新操作 的次数。
- Com_delete:删除操作的次数。
若查询MySQL服务器的连接次数,则可以执行如下语句:
SHOW STATUS LIKE 'Connections';
若查询服务器工作时间,则可以执行如下语句:
SHOW STATUS LIKE 'Uptime';
若查询MySQL服务器的慢查询次数,则可以执行如下语句:
SHOW STATUS LIKE 'Slow_queries';
慢查询次数参数可以结合慢查询日志找出慢查询语句,然后针对慢查询语句进行表结构优化或者查询语句优化。
再比如,如下的指令可以查看相关的指令情况:
SHOW STATUS LIKE 'Innodb_rows_%';
3. 统计SQL的查询成本: last_query_cost
一条SQL查询语句在执行前需要查询执行计划,如果存在多种执行计划的话,MySQL会计算每个执行计划所需要的成本,从中选择成本最小的一个作为最终执行的执行计划。
如果我们想要查看某条SQL语句的查询成本,可以在执行完这条SQL语句之后,通过查看当前会话中的last_query_cost变量值来得到当前查询的成本。它通常也是我们评价一个查询的执行效率的一个常用指标。这个查询成本对应的是SQL 语句所需要读取的读页的数量。
我们依然使用第8章的 student_info 表为例:
CREATE TABLE `student_info` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`student_id` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`course_id` INT NOT NULL ,
`class_id` INT(11) DEFAULT NULL,
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
如果我们想要查询 id=900001 的记录,然后看下查询成本,我们可以直接在聚簇索引上进行查找:
SELECT student_id, class_id, NAME, create_time FROM student_info WHERE id = 900001;
运行结果(1 条记录,运行时间为 0.042s )
然后再看下查询优化器的成本,实际上我们只需要检索一个页即可:
mysql> SHOW STATUS LIKE 'last_query_cost';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| Last_query_cost | 1.000000 |
+-----------------+----------+
如果我们想要查询 id 在 900001 到 9000100 之间的学生记录呢?
SELECT student_id, class_id, NAME, create_time
FROM student_info
WHERE id BETWEEN 900001 AND 900100;
运行结果(100 条记录,运行时间为 0.046s ):
然后再看下查询优化器的成本,这时我们大概需要进行 20 个页的查询。
mysql> SHOW STATUS LIKE 'last_query_cost';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| Last_query_cost | 21.134453 |
+-----------------+-----------+
你能看到页的数量是刚才的 20 倍,但是查询的效率并没有明显的变化,实际上这两个 SQL 查询的时间 基本上一样,就是因为采用了顺序读取的方式将页面一次性加载到缓冲池中,然后再进行查找。虽然 页 数量(last_query_cost)增加了不少 ,但是通过缓冲池的机制,并 没有增加多少查询时间 。
使用场景:它对于比较开销是非常有用的,特别是我们有好几种查询方式可选的时候。
SQL查询时一个动态的过程,从页加载的角度来看,我们可以得到以下两点结论:
位置决定效率。如果页就在数据库缓冲池中,那么效率是最高的,否则还需要从内存或者磁盘中进行读取,当然针对单个页的读取来说,如果页存在于内存中,会比在磁盘中读取效率高很多。批量决定效率。如果我们从磁盘中对单一页进行随机读,那么效率是很低的(差不多10ms),而采用顺序读取的方式,批量对页进行读取,平均一页的读取效率就会提升很多,甚至要快于单个页面在内存中的随机读取。所以说,遇到I/O并不用担心,方法找对了,效率还是很高的。我们首先要考虑数据存放的位置,如果是进程使用的数据就要尽量放到
缓冲池中,其次我们可以充分利用磁盘的吞吐能力,一次性批量读取数据,这样单个页的读取效率也就得到了提升。
4. 定位执行慢的 SQL:慢查询日志

4.1 开启慢查询日志参数
1. 开启 slow_query_log
在使用前,我们需要先查下慢查询是否已经开启,使用下面这条命令即可:
mysql > show variables like '%slow_query_log';
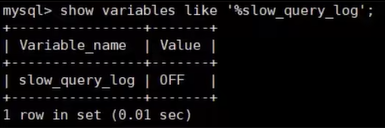
我们可以看到 slow_query_log=OFF,我们可以把慢查询日志打开,注意设置变量值的时候需要使用 global,否则会报错:
mysql > set global slow_query_log='ON';
然后我们再来查看下慢查询日志是否开启,以及慢查询日志文件的位置:
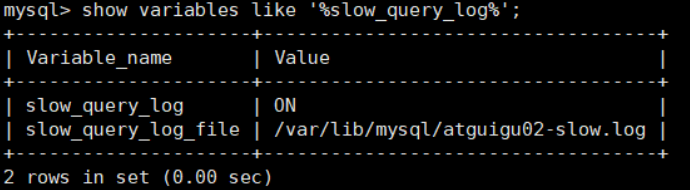
你能看到这时慢查询分析已经开启,同时文件保存在 /var/lib/mysql/atguigu02-slow.log 文件 中。
2. 修改 long_query_time 阈值
接下来我们来看下慢查询的时间阈值设置,使用如下命令:
mysql > show variables like '%long_query_time%';
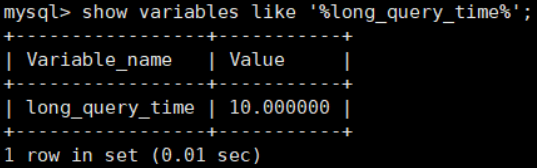
这里如果我们想把时间缩短,比如设置为 1 秒,可以这样设置:
#测试发现:设置global的方式对当前session的long_query_time失效。对新连接的客户端有效。所以可以一并
执行下述语句
mysql > set global long_query_time = 1;
mysql> show global variables like '%long_query_time%';
mysql> set long_query_time=1;
mysql> show variables like '%long_query_time%';
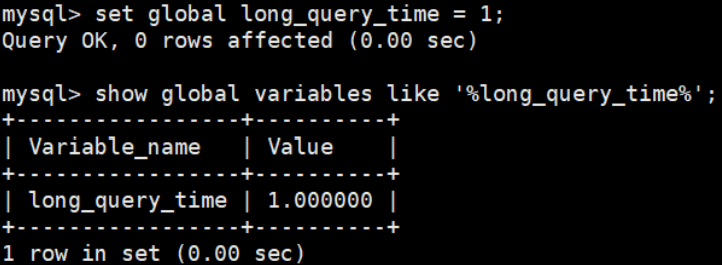
补充:配置文件中一并设置参数
如下的方式相较于前面的命令行方式,可以看做是永久设置的方式。
修改 my.cnf 文件,[mysqld] 下增加或修改参数 long_query_time、slow_query_log 和 slow_query_log_file 后,然后重启 MySQL 服务器。
[mysqld]
slow_query_log=ON # 开启慢查询日志开关
slow_query_log_file=/var/lib/mysql/atguigu-low.log # 慢查询日志的目录和文件名信息
long_query_time=3 # 设置慢查询的阈值为3秒,超出此设定值的SQL即被记录到慢查询日志
log_output=FILE
如果不指定存储路径,慢查询日志默认存储到MySQL数据库的数据文件夹下。如果不指定文件名,默认文件名为hostname_slow.log。
4.2 查看慢查询数目
查询当前系统中有多少条慢查询记录
SHOW GLOBAL STATUS LIKE '%Slow_queries%';
4.3 案例演示
步骤1. 建表
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
步骤2:设置参数 log_bin_trust_function_creators
创建函数,假如报错:
This function has none of DETERMINISTIC......
- 命令开启:允许创建函数设置:
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
步骤3:创建函数
随机产生字符串:(同上一章)
DELIMITER //
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
# 测试
SELECT rand_string(10);
产生随机数值:(同上一章)
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
#测试:
SELECT rand_num(10,100);
步骤4:创建存储过程
DELIMITER //
CREATE PROCEDURE insert_stu1( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, NAME ,age ,classId ) VALUES
((START+i),rand_string(6),rand_num(10,100),rand_num(10,1000));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
步骤5:调用存储过程
#调用刚刚写好的函数, 4000000条记录,从100001号开始
CALL insert_stu1(100001,4000000);
4.4 测试及分析
1. 测试
mysql> SELECT * FROM student WHERE stuno = 3455655;
+---------+---------+--------+------+---------+
| id | stuno | name | age | classId |
+---------+---------+--------+------+---------+
| 3523633 | 3455655 | oQmLUr | 19 | 39 |
+---------+---------+--------+------+---------+
1 row in set (2.09 sec)
mysql> SELECT * FROM student WHERE name = 'oQmLUr';
+---------+---------+--------+------+---------+
| id | stuno | name | age | classId |
+---------+---------+--------+------+---------+
| 1154002 | 1243200 | OQMlUR | 266 | 28 |
| 1405708 | 1437740 | OQMlUR | 245 | 439 |
| 1748070 | 1680092 | OQMlUR | 240 | 414 |
| 2119892 | 2051914 | oQmLUr | 17 | 32 |
| 2893154 | 2825176 | OQMlUR | 245 | 435 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











