




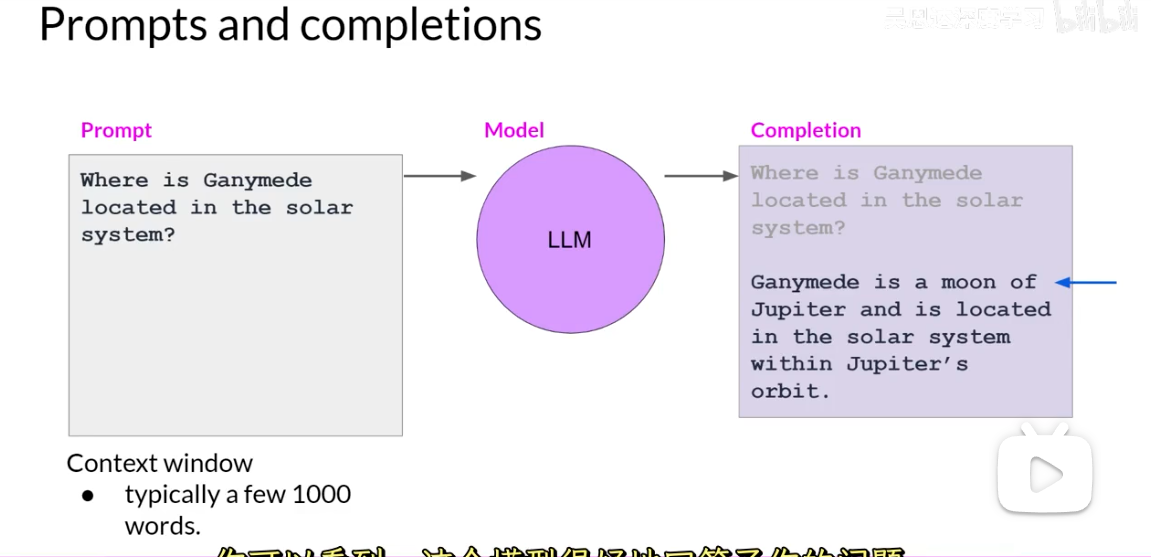
Prompt = 给模型的指令/上下文输入
transformer:
结构:
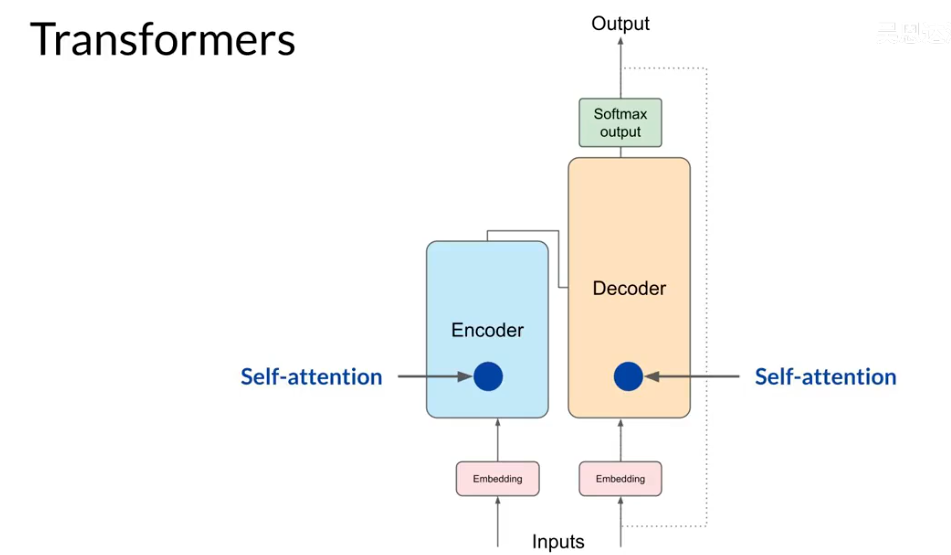
-
Encoder Input = 任务输入(源文本、文章、问题)。
-
Decoder Input = 目标输出的“已知部分”(训练时用真实前缀,推理时用模型自己生成的前缀)。
-
之所以有两个 Input,是因为 一个负责理解输入,一个负责生成输出。
-

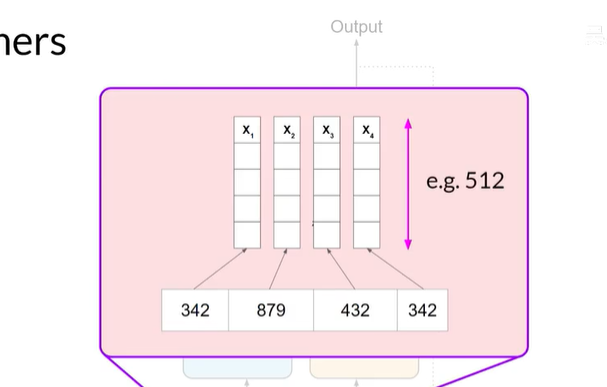
分词&分词器

词汇表中的每个 Token ID 都对应一个多维向量,这些向量可以学习编码输入序列中单个 Token 的含义和上下文。

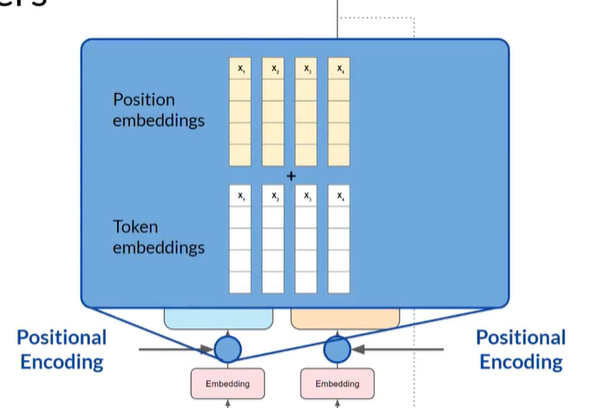
位置编码:

多头注意力机制:
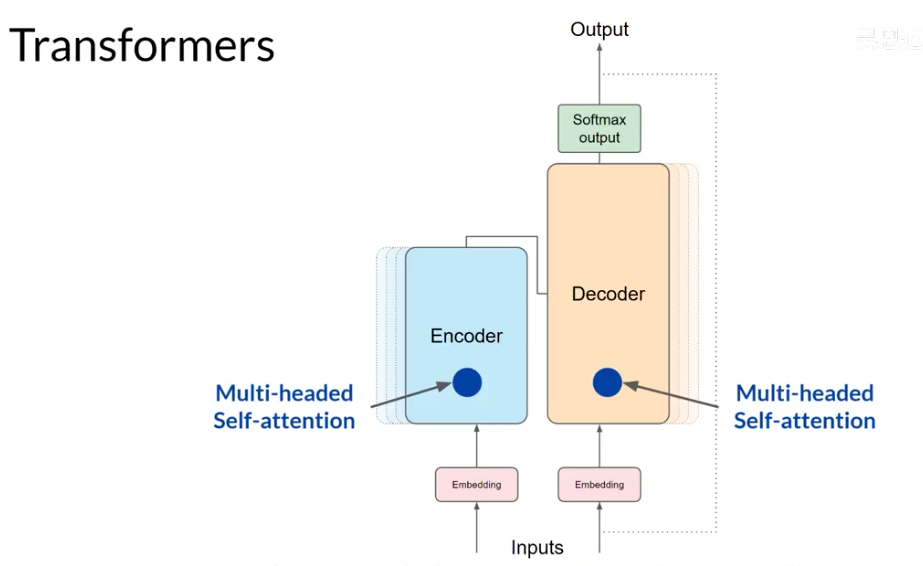
在 自注意力 (Self-Attention) 里,每个词都会和句子里所有词计算相关性,得到一个注意力分布。
多头注意力:
-
不只用一组注意力,而是同时用 多组(多个头)注意力 来学习不同的关系。
-
每个头(head)会用不同的参数,把输入投影到不同的子空间里,捕捉句子中不同的依赖特征。
-
最后把多个头的结果拼接起来,再做一次线性变换。
-
一个头可能关注句法关系(比如主谓关系),
-
另一个头可能关注语义关系(比如近义词)。
-
多头让模型能更全面地捕捉信息。

总结:transformers
1文本分词(Tokenizer) → token IDs
2Token IDs → Embedding 层 → token 向量
3加上 Positional Encoding → 带有位置信息的输入向量
4输入到 Encoder 的 Self-Attention 层


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









