




 本文介绍了机器学习中模型的保存与加载流程,包括fit()、transform()和fit_transform()方法的作用。fit()用于计算参数,transform()和fit_transform()则对数据进行标准化等处理。文章强调了保存模型以节省训练时间和提高效率的重要性,并给出了具体的API使用及完整代码示例。
本文介绍了机器学习中模型的保存与加载流程,包括fit()、transform()和fit_transform()方法的作用。fit()用于计算参数,transform()和fit_transform()则对数据进行标准化等处理。文章强调了保存模型以节省训练时间和提高效率的重要性,并给出了具体的API使用及完整代码示例。
知识点
fit()
Method calculates the parameters μ and σ and saves them as internal objects.
解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
transform()
Method using these calculated parameters apply the transformation to a particular dataset.
解释:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。
fit_transform()
joins the fit() and transform() method for transformation of dataset.
解释:fit_transform是fit和transform的组合,既包括了训练又包含了转换。
transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)
fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
目的
将训练好的模型保存下来,已备下次使用,节省训练时间,提高效率
API
from sklearn.externals import joblib
保存:
joblib.dump(rf,"test.pkl")
加载:
estimator = joblib.load("test.pkl")
流程
获取数据
boston = load_boston()
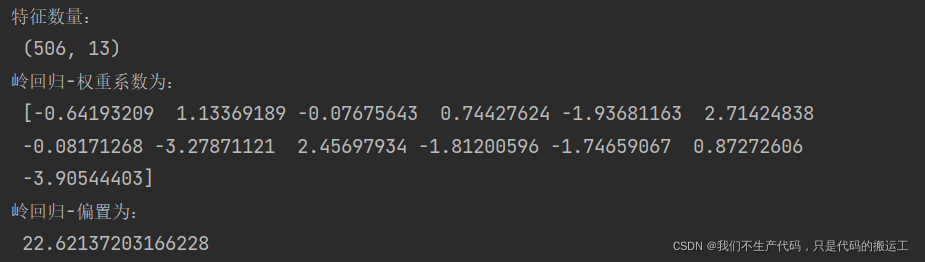
print("特征数量:\n", boston.data.shape)
划分数据集
x_train, x_test, y_train, y_test =
train_test_split(boston.data, boston.target,\
random_state=22)
标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
预估器
estimator = Ridge(alpha=0.5, max_iter=10000)
estimator.fit(x_train, y_train)
保存模型
joblib.dump(estimator, "test.pkl")
加载模型
estimator = joblib.load("test.pkl")
得出模型
print("岭回归-权重系数为:\n", estimator.coef_)
print("岭回归-偏置为:\n", estimator.intercept_)
模型评估
y_predict = estimator.predict(x_test)
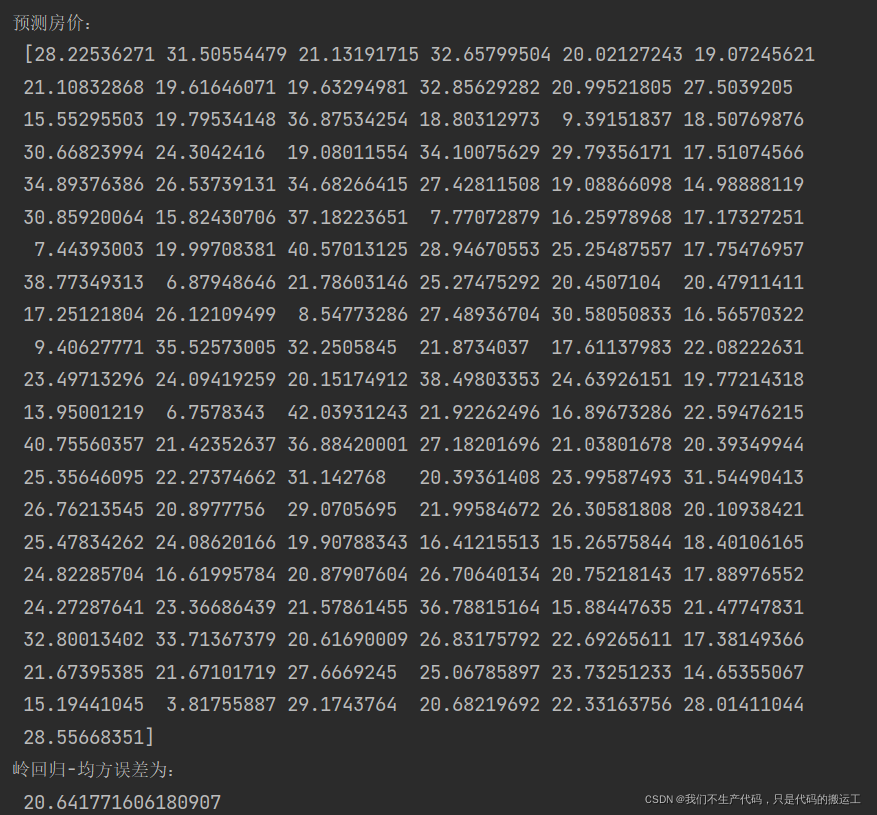
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("岭回归-均方误差为:\n", error)
整体代码
# -*- coding: UTF-8 -*-
'''
@Author :Jason
波士顿房价预测,将模型保存到
'''
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
import joblib
def model_save_fetch():
"""
岭回归对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
print("特征数量:\n", boston.data.shape)
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# # 4)预估器
estimator = Ridge(alpha=0.5, max_iter=10000)
estimator.fit(x_train, y_train)
#
# # 保存模型
joblib.dump(estimator, "test.pkl")
# 加载模型
estimator = joblib.load("test.pkl")
# 5)得出模型
print("岭回归-权重系数为:\n", estimator.coef_)
print("岭回归-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("岭回归-均方误差为:\n", error)
return None
if __name__ == "__main__":
model_save_fetch()

















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









